
AI応答の不正確な情報に異議を唱え、修正する方法
不正確なAI情報への異議申し立て方法、ChatGPTやPerplexityへの誤りの報告手順、ブランドがAI生成回答で正確に表現されるための戦略について解説します。...
1 分で読める

ChatGPT、Perplexity、その他のAIシステムによる不正確な情報を特定・検証し、修正するための効果的な方法を学びましょう。
AIの回答に含まれる誤情報は、ラテラルリーディングを用いて権威ある情報源と主張を照合し、情報を具体的な主張に分解し、AIプラットフォームにエラーを報告することで修正できます。学術データベースや政府機関のウェブサイト、公的なニュース媒体を通じて事実を検証し、AIが生成した内容が正確かどうかを確認しましょう。
AIの回答における誤情報は、人工知能システムがユーザーにとって信頼できそうに見える不正確・古い・誤解を招く情報を生成した場合に発生します。これは、**大規模言語モデル(LLM)がインターネット上の膨大なデータを学習しているためであり、その中には偏ったり、不完全、あるいは虚偽の情報も含まれていることがあります。特に問題となるのがAIのハルシネーション(幻覚)**と呼ばれる現象です。これは、AIモデルが実際には存在しないパターンを見出し、まるで事実であるかのように根拠のない回答を自信満々に生成する場合を指します。例えば、AIが架空の教授の名前を作ったり、実在の人物に誤った情報を帰属させたりすることがあります。こうした限界を理解することは、AIをリサーチやビジネス判断、コンテンツ制作に利用するすべての人にとって極めて重要です。
AIの回答に含まれる誤情報の問題は、単なる事実誤認にとどまりません。AIは憶測を事実として提示したり、訓練データの制約からデータを誤解釈したり、現実にそぐわない古い情報源から情報を引き出したりする場合があります。さらに、AIモデルは事実と意見の区別が苦手であり、主観的な信念を客観的な真実として扱う場合もあります。このように、AIがすべての情報を同じ自信と権威をもって提示する結果、ユーザーは正しい情報と虚偽の主張を見分けるための批判的評価能力を身につける必要があります。
ラテラルリーディングは、AIの回答の誤情報を特定・修正するために最も効果的な手法です。この方法は、AIの出力から離れて複数の外部情報源を参照し、具体的な主張ごとに正確性を評価することを意味します。AIの回答を上から下に「垂直」に読むのではなく、複数のタブを開いて権威ある情報源から証拠を探す「水平的」な調査が求められます。これは、AIの出力が複数の識別不能な情報源を合成したものであるためで、出力そのものの信頼性を調べることができないからです。そのため、主張そのものを独立して検証する必要があります。
ラテラルリーディングの最初のステップは**細分化(フラクショネーション)**です。つまり、AIの回答を小さく具体的で検索可能な主張に分解します。1つの段落全体を一度に検証しようとせず、独立して確認できる個々の文やフレーズごとに分けます。例えば、ある人物が特定の大学に通い、特定の教授の下で学んだとAIが主張した場合、それぞれ3つの独立した主張として検証します。主張を特定したら、新しいブラウザタブでGoogle Scholar、学術データベース、政府機関ウェブサイト、または公的なニュース媒体など信頼できる情報源を使って証拠を探します。この方法の最大の利点は、プロンプトとAIの回答の両方に内在する前提を明確にし、どこで誤りが生じたのかを特定できる点です。
AIが生成した情報を検証するには、高水準の正確性と信頼性を維持する複数の権威ある情報源を参照する必要があります。政府機関のウェブサイト、査読済みの学術誌、確立された報道機関、専門分野のデータベースなどが最も信頼できる検証手段です。AIの回答を事実確認する際は、次のような特徴を持つ情報源を優先しましょう:研究内容はJSTOR、PubMed、Google Scholarなどの学術データベース、公式統計や政策は政府機関のウェブサイト、時事や最新情報は編集体制のあるニュース媒体です。これらの情報源には編集プロセスや事実確認手順、責任体制が備わっていますが、AIシステムにはありません。
| 情報源の種類 | 適した用途 | 例 |
|---|---|---|
| 学術データベース | 研究内容、歴史的事実、技術情報 | JSTOR、PubMed、Google Scholar、WorldCat |
| 政府機関ウェブサイト | 公式統計、政策、規制 | .govドメイン、公式機関サイト |
| 報道機関 | 時事、最新動向、速報 | 主要新聞、編集体制のある通信社 |
| 専門データベース | 業界特化情報、技術詳細 | 業界団体、専門組織 |
| 非営利団体 | 検証済み情報、調査レポート | 資金源が透明な.orgドメイン |
AIの回答をクロスチェックする際は、複数の独立した情報源が同じ情報を裏付けているかを確認し、1つの情報源だけに頼るのは避けましょう。情報源間で食い違いがある場合は、なぜその違いが生じているのかをさらに調べてください。AIの回答には正しい情報が誤った文脈で使われていることもあり、例えば、ある事実を別の組織に帰属させたり、正しい情報を誤った時代背景で提示したりすることがあります。このようなエラーは、一見検証可能な事実でも、それらの組み合わせによって誤情報を生み出すため特に注意が必要です。
誤情報を効果的に修正するには、AIの回答を体系的に分析するアプローチが求められます。まず、回答の中に含まれる具体的な事実の主張を特定し、それぞれを独立して評価します。その際、自分のプロンプトに基づいてAIがどんな前提を置いているか、どんな観点や意図が情報に影響しているか、独自のリサーチで発見した事実と主張が一致しているかを批判的に問いかけます。各主張について、完全に正確か、一部誤解を招くものか、あるいは事実誤認なのかを記録しましょう。
AIの回答を分析する際は、自信の指標やAIの情報提示の仕方にも注目してください。AIは不確かな情報や推測も確立された事実と同じ自信をもって提示することが多く、ユーザーが検証済みの事実と憶測を区別しにくくなります。また、引用や出典の有無も確認しましょう。AIによっては情報源を引用することもありますが、その引用が不正確だったり、実際にはその情報を含まない場合もあります。AIが情報源を挙げている場合には、その情報源が実在し、引用内容が正確に一致しているかを必ず確認してください。
主要なAIプラットフォームの多くは、ユーザーが不正確または誤解を招く回答を報告できる仕組みを提供しています。例えばPerplexityでは、専用のフィードバックシステムやサポートチケットの作成を通じて誤った回答を報告できます。ChatGPTや他のAIシステムでも同様に、フィードバック機能があり、開発者が問題のある回答を特定・修正できます。誤情報を報告する際は、どの情報が不正確だったか、正しい情報は何か、可能であればそれを裏付ける権威ある情報源のリンクも添えて具体的に伝えましょう。こうしたフィードバックはAIシステムの訓練の改善に役立ち、他のユーザーへの同じエラーの再発防止にもつながります。
エラーを報告することは、個々の回答の修正以上の意味を持ちます。開発者にフィードバックのループを作り出し、AIシステムが苦手とする典型的な失敗パターンや改善点を特定する助けになります。こうしたユーザーの集合的なフィードバックは、長期的にAIシステムの正確性と信頼性の向上に寄与します。ただし、AIプラットフォームへの報告だけでは不十分であり、自分自身での事実確認が不可欠であることも忘れないでください。AIが誤情報を修正する前に自分がそれに遭遇する可能性もあるため、個人による検証が常に重要です。
AIのハルシネーションは、最も厄介な誤情報の一種であり、非常に自信をもってもっともらしく生成されるため見抜きにくいものです。これは、AIモデルが実際には根拠のない情報を、あたかも実在するかのように作り出す現象です。よくある例としては、架空の人物や論文、書籍の引用を作成したり、実在人物に虚偽の業績を帰属させたりすることが挙げられます。研究によれば、あるAIモデルは真実の識別には約90%の精度を持つ一方で、虚偽の識別は50%未満と、ランダムよりも悪い結果を示しています。
ハルシネーションの可能性を見抜くには、AIの回答の中に要注意サインがないかを探しましょう。どの情報源を調べても確認できない人物や出来事、存在しない論文や書籍への引用、またはプロンプトに都合よく完全に一致するような情報などです。AIの回答に具体的な名前や日付、引用が含まれている場合は、優先的に検証しましょう。複数の情報源で確認できない主張は、ハルシネーションの可能性が高いと考えられます。また、出典がないままニッチな話題について非常に詳細な情報を提示している場合、その情報が作り話である可能性が高い点にも注意してください。
AIシステムには知識のカットオフ日があり、それ以降に公開された情報にはアクセスできません。そのため、ユーザーが最近の出来事や最新統計、新しい研究などを尋ねた場合、大きな誤情報の原因となります。例えば、現在の市場動向や政策変更、速報ニュースに関するAIの回答が完全に不正確な場合は、AIの訓練データがそれらの最新情報以前で止まっているためです。最近の出来事や最新データが必要な場合は、AIの回答が本当に最新情報を反映しているか必ず確認してください。
古い情報への対応策としては、ファクトチェック時に情報源の公開日を必ず確認し、AIの回答日と比較します。AIの回答が数年前の統計や情報を「現在のもの」として提示していれば、それは明らかに古い情報です。技術・医療・法律・経済など情報が頻繁に変化する分野では、AIの回答に加えて最新の情報源で必ず補完しましょう。リアルタイム情報にアクセスできるAIや、知識のカットオフ日を明示するAIを活用することで、回答の限界を理解しやすくなります。
インターネット上のデータで訓練されたAIシステムは、そのデータに内在するバイアスを引き継ぎます。その結果、ある特定の視点を優遇し、他の視点を排除するかたちで誤情報が生じることもあります。AIの回答を評価する際は、議論の分かれる話題や複雑なテーマで複数の視点が示されているか、あるいは一つの見解が事実として示されていないかを確認しましょう。主観的意見や文化的な特殊性が普遍的な真実として提示されると、誤情報が発生しやすくなります。また、専門家の間で見解が分かれている場合、AIの回答がその不確実性や意見の対立を認めているかも重要なポイントです。
バイアスに関連した誤情報を見抜くには、権威ある複数の情報源が同じ話題をどのように扱っているかを調べましょう。信頼できる情報源間で大きな見解の相違がある場合、AIの回答が不完全または偏ったものになっている可能性があります。AIが限界点、反論、代替的な解釈を提示しているかどうかも確認しましょう。情報が実際よりも確実であるかのように提示されたり、重要な文脈や他の見解が省略されたりしている場合、個々の事実が正しくても全体として誤解を招くことがあります。
人によるファクトチェックは不可欠ですが、専門的なファクトチェックツールやリソースを活用すると、AIが生成した情報の検証を支援できます。Snopes、FactCheck.org、PolitiFactなどのファクトチェック専用サイトは、検証済み・否定済みの主張データベースを提供しており、虚偽の主張をすばやく見抜くのに役立ちます。また、他のAIシステムが虚偽の予測に対して過剰な自信を示す場合、それを検出する専用のAIも開発されています。こうしたツールは**信頼度の調整(コンフィデンスキャリブレーション)**などの技術を用いており、AIが高い自信で誤った回答をしている場合も見抜けるよう支援します。
学術・研究機関もAI生成コンテンツを評価するためのリソースを増やしています。大学図書館や研究センター、教育機関では、ラテラルリーディングやAIコンテンツの批判的評価、ファクトチェック技術に関するガイドを提供しています。これらのリソースには、AIの回答を分解する手順、主張の特定、体系的な情報検証の方法など、具体的な手順が含まれています。こうした教育リソースを活用することで、AIの回答に含まれる誤情報を特定・修正する力を大きく高めることができます。
不正確なAI情報への異議申し立て方法、ChatGPTやPerplexityへの誤りの報告手順、ブランドがAI生成回答で正確に表現されるための戦略について解説します。...

AIによるブランドに関する誤情報の特定、防止、修正方法を学びましょう。AI検索結果で評判を守るための7つの実証済み戦略とツールをご紹介します。...
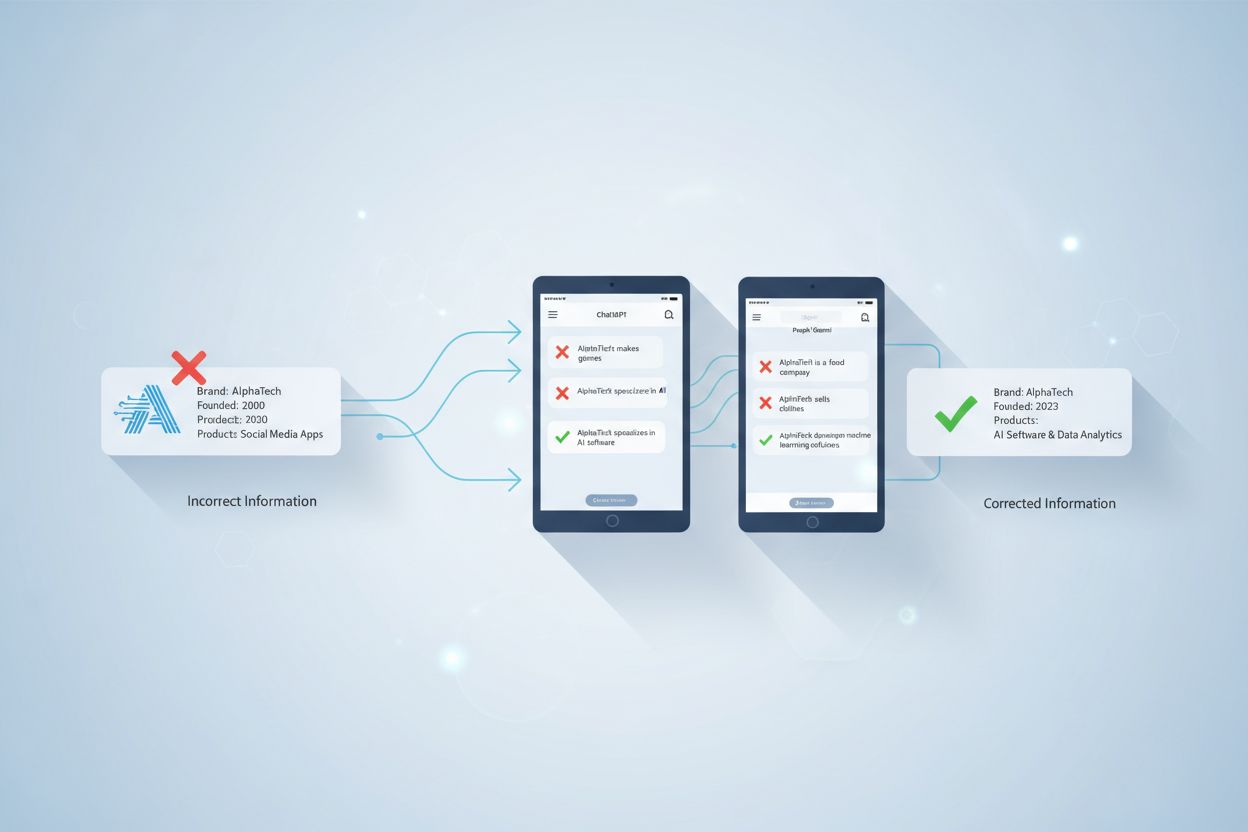
ChatGPT、Gemini、PerplexityなどのAIシステムにおける誤ったブランド情報を特定・訂正する方法を学びます。監視ツール、ソースレベルの訂正戦略、予防方法を紹介し、ブランドの正確性と信頼性を維持します。...
クッキーの同意
閲覧体験を向上させ、トラフィックを分析するためにクッキーを使用します。 See our privacy policy.