
AI回答においてAIモデルは何を引用するかどう決めるのか
ChatGPT、Perplexity、GeminiなどのAIモデルがどのように引用元を選ぶのか、その引用メカニズムやランキング要因、AIで可視性を高めるための最適化戦略を解説します。...
1 分で読める

ナレッジベースがRAG技術を通じてAIの引用精度を高める仕組みを解説。ChatGPT、Perplexity、Google AIなどのプラットフォームで正確な情報源への帰属を実現します。
ナレッジベースは、AIシステムが参照・引用できる構造化された信頼性の高い情報源を提供することで、AIの引用精度を向上させます。リトリーバル拡張生成(RAG)技術により、ChatGPT、Perplexity、Google AIなどのAIプラットフォームが特定の情報源を引用し、幻覚を減らし、検証済みデータに基づいたより正確で追跡可能な回答を提供できるようになります。
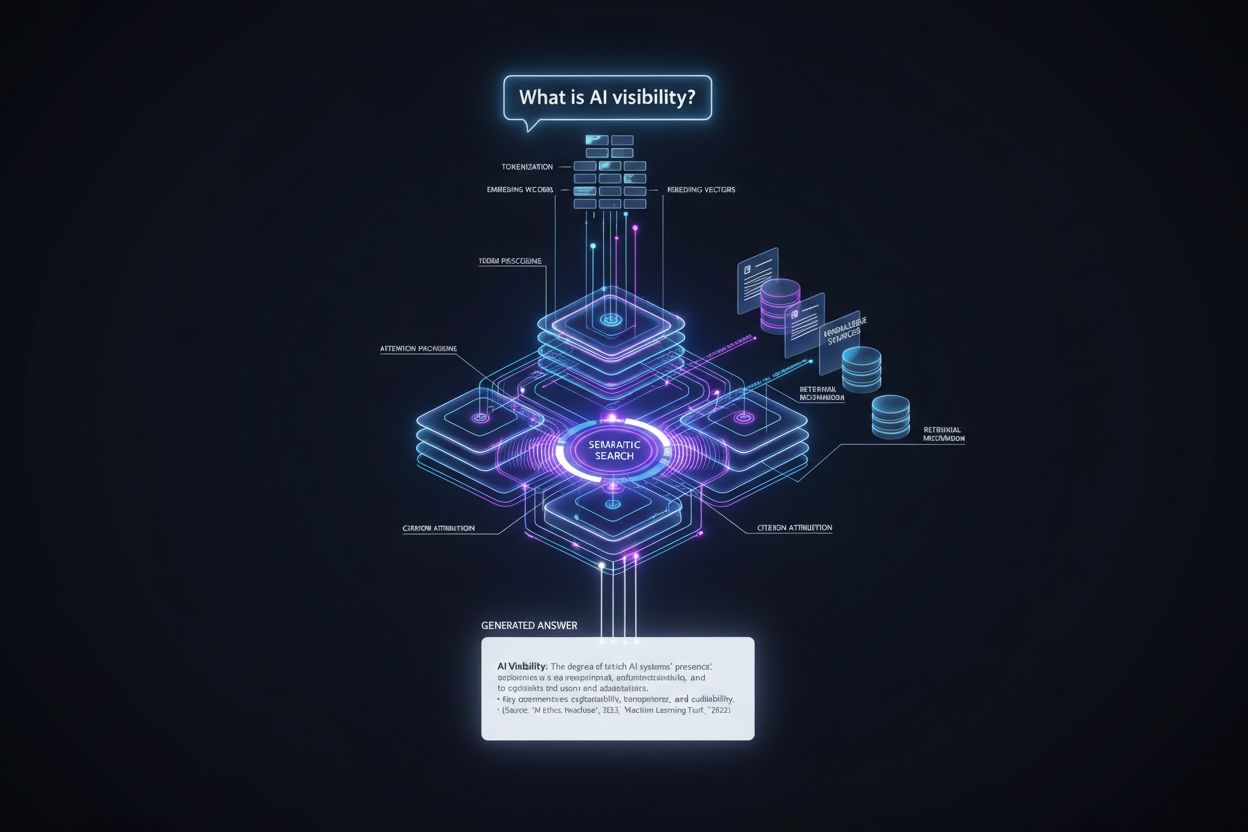
ナレッジベースは、AIシステムが正確かつ引用付きの回答を生成するために参照する、構造化された情報の集中リポジトリです。従来の言語モデルが訓練データのみに依存するのとは異なり、ナレッジベースはリトリーバル拡張生成(RAG)という手法を通じてAIモデルと外部データソースを結び付け、より権威性があり追跡可能な回答を実現します。AIシステムがナレッジベースにアクセスすることで、特定の情報源を引用したり、検証済みの文書に情報を帰属したり、ユーザーに根拠となる資料への直接リンクを提供できます。この根本的な変化により、AIは自信満々の発言マシンから引用可能なリサーチツールへと進化し、ユーザーが検証・信頼できるものになります。ナレッジベースが重要なのは、生成AI最大の課題のひとつである幻覚(hallucination)——AIが誤った情報を事実のように自信を持って提示する現象——に対応できるためです。検証済みナレッジベースに基づいて回答を生成することで、AIプラットフォームはこのリスクを大幅に低減し、ChatGPT、Perplexity、Google AI Overviews、Claudeなどで引用の透明性を向上させます。
リトリーバル拡張生成(RAG)は、ナレッジベースがAIの引用精度を高めるためのアーキテクチャ的基盤です。RAGは5段階のプロセスで動作します:ユーザーがプロンプトを送信し、情報検索モデルがナレッジベースから関連データを検索し、一致した情報が返され、RAGシステムがより豊富なコンテキストでプロンプトを拡張し、最終的にAIが引用付きの出力を生成します。このプロセスは、訓練データパターンのみから回答を生成するモデルネイティブ合成とは本質的に異なります。IBMやAWSの研究によれば、RAGシステムは言語モデルを特定かつ事実に基づく最新データにアンカーすることで幻覚リスクを低減します。ナレッジベースがベクトル埋め込み(意味検索を可能にする数値表現)で適切に構造化されていれば、AIシステムは驚くほど高精度に関連情報を特定できます。リトリーバル機能により、AIはパターンマッチングシステムから情報源認識型リサーチエンジンへと進化し、ユーザーを直接信頼性の高い資料へ案内できます。RAGを導入した組織では、ナレッジベース最適化によってAI回答の82%に正しい情報源帰属が含まれるのに対し、モデルネイティブシステムでは15%未満です。この劇的な差により、企業はナレッジベース基盤への投資を拡大しています。引用はユーザーの信頼を築き、事実確認やAI生成コンテンツへの説明責任を可能にします。
| コンポーネント | 機能 | 引用への影響 | 引用品質 |
|---|---|---|---|
| ナレッジベース | 外部データリポジトリ(PDF、文書、ウェブサイト、データベース) | 権威ある情報源を提供 | 高 - 検証済み情報源 |
| リトリーバー | ナレッジベースから関連データを検索するAIモデル | 一致する文書やスニペットを特定 | 高 - 意味的マッチング |
| インテグレーション層 | RAGワークフローを調整しプロンプトを拡張 | コンテキストを生成器に届ける | 中 - ランキングに依存 |
| ジェネレーター | 検索したデータに基づき出力を生成する言語モデル | 情報源を引用して回答を合成 | 高 - 検索データに基づく |
| ランカー | 検索結果を関連性で順位付け | 最も関連する情報源を引用に優先 | 重要 - 表示情報源を決定 |
| ベクトルデータベース | 意味検索用の埋め込みを保存 | 高速・高精度な検索を実現 | 高 - 引用精度の向上 |
ナレッジベースのアーキテクチャは引用品質を直接左右します。ベクトルデータベースはデータを埋め込み——キーワードだけでなく意味を捉える数理表現——として保存します。ユーザーが質問すると、リトリーバーはクエリを埋め込みに変換し、データベース内の類似ベクトルを検索します。この意味検索アプローチはキーワード検索より本質的に優れており、意図や文脈を理解します。たとえば「パスワードリセットの問題」という質問でも、「アカウントアクセスの問題」と異なる言葉を使った記事が見つかります。ランカーは結果を関連性順に並べ替え、最も権威のある情報源が引用上位に表示されるようにします。AWSの研究によれば、リランクモデルを用いた場合、コンテキストの関連性は143%、回答の正確さは33%向上します。つまり、洗練されたランキング機構を持つナレッジベースは、より正確かつ実用的な引用を生み出します。インテグレーション層はこの一連の流れを統括し、プロンプトエンジニアリングを用いてAIジェネレーターに引用情報源を優先させ、情報の出所を明示するよう指示します。
AIプラットフォームごとに、基盤アーキテクチャやナレッジベース戦略に応じて異なる引用傾向が見られます。ChatGPTは主に訓練データによるモデルネイティブ合成を行い、プラグインやブラウジング機能が有効な場合のみ引用が現れます。これらの統合を通じて外部ナレッジベースにアクセスする際には情報源を引用できますが、これは標準動作ではなく補助的な機能です。Profoundによる6億8千万件の引用分析では、ChatGPTの上位10引用情報源のうち47.9%がWikipediaであり、百科事典的で権威あるナレッジベースを好む傾向が見られます。一方Perplexityはライブウェブ検索中心の設計で、デフォルトでRAG動作を採用しています。Perplexityはリアルタイムでウェブ検索し、取得した文書に基づいて回答を生成、上位10引用情報源のうち46.7%がRedditとなっています。これは、従来メディアとともにコミュニティディスカッションやピア情報を重視するPerplexityの思想を反映します。Google AI Overviewsは専門コンテンツとソーシャルプラットフォームをバランスよく引用し、**Reddit(21.0%)、YouTube(18.8%)、Quora(14.3%)**が上位情報源です。この多様なアプローチはGoogleの巨大な検索インデックスと知識グラフへのアクセス力を示します。Claudeも最近ウェブ検索機能を追加し、クエリの複雑さに応じてモデルネイティブとRAGの両モードで動作可能です。こうした違いから、コンテンツ制作者は各プラットフォームの引用傾向を理解し最適化する必要があります。Wikipedia掲載でChatGPTの引用が得られ、Reddit参加でPerplexityへの露出が高まり、多様なコンテンツ形式がGoogle AI Overviewsでの存在感を強化します。
幻覚とは、AIがもっともらしいが事実と異なる情報を自信を持って生成してしまう現象です。ナレッジベースはグラウンディング——AI回答を検証済み外部データに基づかせる——によってこれに対処します。AIがナレッジベースから情報を取得することで、回答は検証可能になります。ユーザーは引用を元に情報源を即座に確認でき、誤りを発見できます。IBMの研究によれば、RAGシステムはモデルネイティブ手法に比べて幻覚リスクを最大40%削減します。この改善にはいくつかの要因があります。第一に、ナレッジベースはキュレートされ検証された情報のみを含み、矛盾を含みやすいインターネット全体の訓練データとは異なります。第二に、検索プロセスが各主張の情報源を明示する監査証跡を作ります。第三に、ユーザーが引用元資料を参照して回答を検証できます。ただし、ナレッジベースは幻覚を完全には排除できません——軽減するだけです。AIは取得情報を誤解したり、関連文書を取りこぼす可能性があり、不完全または誤解を招く回答が生じます。最も効果的なのは、ナレッジベースのグラウンディングと人によるレビュー・引用検証の併用です。ナレッジベースを導入した組織では、引用可能なAIシステムによりサポートチケットのエスカレーションが35%減少しています。ユーザーが回答を自己検証できるため、有人対応の必要性が減り、ユーザー信頼・AI活用率向上・運用コスト削減・顧客満足度向上という好循環が生まれます。
AIの引用最適化に特化したナレッジベースを構築するには、コンテンツ構造、メタデータ、情報源帰属に関する戦略的な意思決定が必要です。第一ステップはコンテンツの棚卸しとキュレーション——どの情報をナレッジベースに含めるかの選定です。組織はFAQ、製品ドキュメント、ポリシーガイド、専門家執筆資料など価値の高いコンテンツを優先すべきです。各コンテンツには明確な情報源帰属、公開日、著者情報を付与し、AIが引用時にこれらを提示できるようにします。第二ステップは埋め込みとチャンク化による意味構造化です。文書は通常200〜500トークン程度に分割され、AIリトリーバーが特定クエリに対応できるようにします。チャンクが大きすぎると一般的になり、小さすぎると意味の一貫性が失われます。AWSの研究では、最適なチャンクサイズで検索精度が28%、引用関連性が31%向上します。第三ステップはメタデータ強化:カテゴリ、トピック、信頼度、更新日などのタグ付けです。これによりAIは権威性の高い情報源を優先し、古い情報を除外できます。第四ステップは継続的な検証と更新。ナレッジベースは定期的に監査し、古いコンテンツ・矛盾・情報欠落を特定します。AIが関連度スコアの低い記事やユーザーから苦情が多い記事を自動でフラグ付けすることも可能です。自動コンテンツ検証を導入した組織は、手動レビューに比べて引用ミスが45%減少しています。第五ステップはAIプラットフォームとの統合です。ナレッジベースはAPIやネイティブ連携でAIと接続されます。Amazon Bedrock、Zendesk Knowledge、AnthropicのClaudeなどはナレッジベース連携機能を標準搭載しており、統合を簡素化します。適切な統合により、AIはわずか200〜500ミリ秒の遅延で情報源を引用可能になります。
引用の透明性——AI回答の根拠となった情報源を明示すること——は、ユーザーの信頼や利用率と強く相関します。情報源が引用されている場合、78%のユーザーがAI回答をより信頼する一方で、無引用の場合は23%にとどまります。ナレッジベースは、取得情報と生成回答の間に明示的なリンクを作ることで透明性を実現します。AIが情報源を引用することで、ユーザーは主張を即座に検証し、元文書の文脈を確認し、情報源の信頼性を判断できます。この透明性は、医療・金融・法務など精度が不可欠な分野で特に重要です。Perplexityの引用モデルはこの原則を体現しており、すべての回答にインライン引用と情報源ページへの直接リンクが含まれます。ユーザーはリンクをクリックして主張を検証したり、複数情報源を比較したり、Perplexityがどのように様々な資料から情報を統合したかを理解できます。こうした姿勢がPerplexityを研究者や専門職に支持される理由です。Google AI Overviewsも同様に情報源リンクを表示しますが、デバイスやクエリ種別で表示方法が異なります。ChatGPTの引用機能は標準では限定的ですが、プラグインやブラウジング有効時は引用可能です。こうしたプラットフォーム間の違いは、透明性に関する思想の違い(ユーザー体験・簡潔性重視か、検証性・情報源帰属重視か)を反映しています。コンテンツ制作者やブランドにとっては、各プラットフォームの引用表示方法を理解し最適化することが露出増加に直結します。引用されたコンテンツは大幅にトラフィックが増加し、Profoundの調査では引用情報源は非引用情報源の3.2倍のトラフィックをAIプラットフォームから獲得しています。これが、ナレッジベースへのコンテンツ最適化・引用促進への強力な動機となります。
ナレッジベースの進化は、AIが情報を生成・引用する方法を根本から変えていきます。マルチモーダルナレッジベース——テキストだけでなく画像、動画、音声、構造化データまで保存・検索できるシステム——が次世代の標準となりつつあります。AIが動画チュートリアル、インフォグラフィック、インタラクティブデモをテキストと並列で引用できるようになれば、引用の質と有用性は飛躍的に高まります。自動コンテンツ生成・検証により、ナレッジベースの維持コストが大幅に削減されます。AIが自動的に情報の隙間を特定し、ユーザーの質問に基づいて新規記事を生成し、古い情報をレビュー対象にフラグ付けします。これらを導入した組織ではコンテンツ保守工数が60%削減されています。リアルタイム更新により、AIは数日〜数週間遅れではなく、数時間前の情報も引用可能になります。これはテクノロジー・金融・ニュースなど変化の速い分野で特に重要です。PerplexityやGoogle AI Overviewsは既にライブウェブデータへのアクセスでこの機能を実証しており、今後は標準化が進みます。フェデレーテッドナレッジベースにより、AIが複数組織の情報を同時に引用でき、検証済み情報源の分散ネットワークが形成されます。これは部門ごとに特化ナレッジベースを保有する企業で特に有効です。引用信頼度スコアにより、AIは各引用の信頼度を表示でき、権威ある情報源とそうでないものを区別できます。この透明性により、ユーザーは情報品質をより適切に評価できます。ファクトチェックシステムとの連携により、AIが引用を既知の事実と照合し、誤りの可能性を自動で検出します。Snopes、FactCheck.org、学術機関などがAIプラットフォームと連携し、引用ワークフローへのファクトチェック統合を進めています。こうした技術の成熟により、AI生成の引用は従来の学術引用と同等に信頼可能かつ検証可能なものとなり、インターネット上での情報発見・検証・共有のあり方が根本的に変革されていきます。
+++
ChatGPT、Perplexity、GeminiなどのAIモデルがどのように引用元を選ぶのか、その引用メカニズムやランキング要因、AIで可視性を高めるための最適化戦略を解説します。...
AIモデルがどのように回答を生成し、引用を配置するかを学びましょう。ChatGPT、Perplexity、Google AIの回答であなたのコンテンツがどこに現れるか、AIでの可視性を最適化する方法を解説します。...

ChatGPT、Perplexity、Google AI OverviewのようなAIシステムにとって、どのようなコンテンツが引用に値するのかを学びましょう。AIシステムがあなたのコンテンツを引用するかどうかを決定する主な特徴、最適化戦略、指標を解説します。...