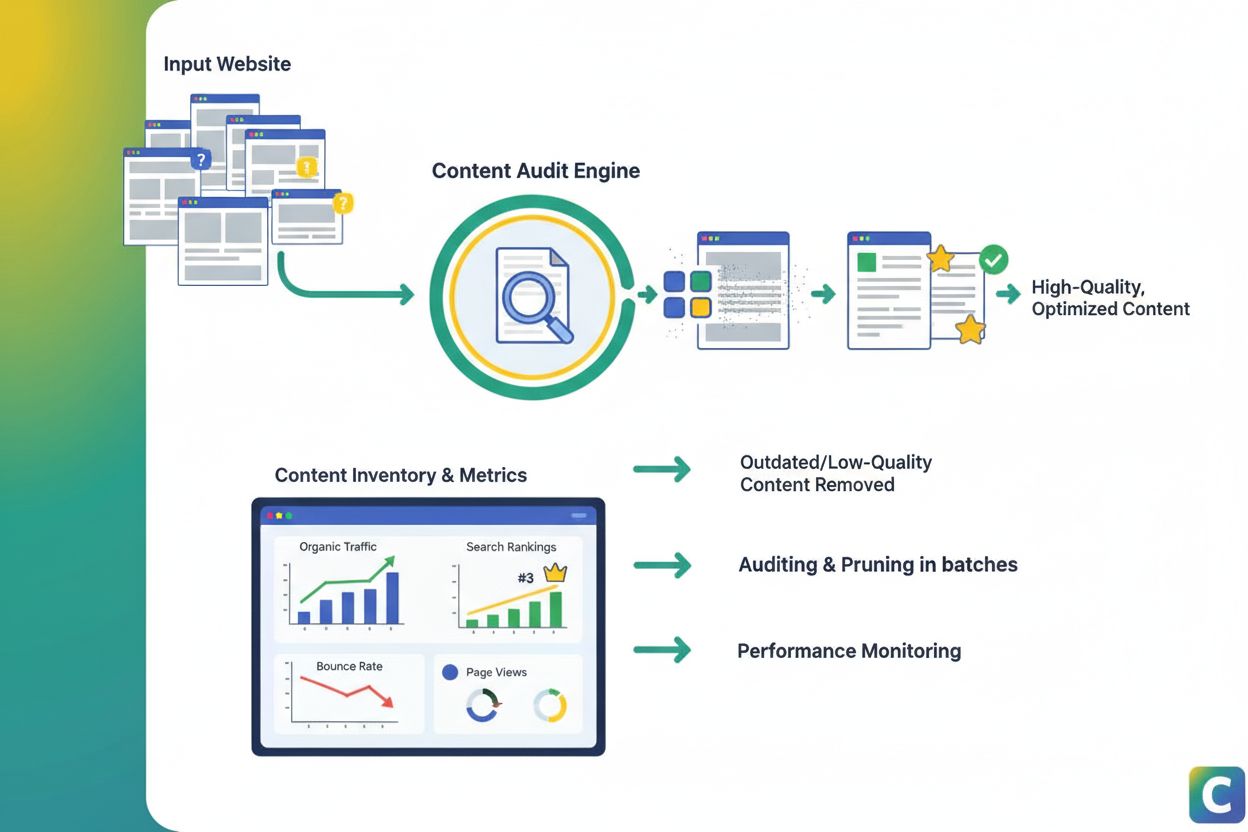
コンテンツ・プルーニング
コンテンツ・プルーニングは、SEO、ユーザー体験、検索可視性を向上させるためにパフォーマンスが低いコンテンツを戦略的に削除または更新することです。質の低いページを効果的に特定し、プルーニングする方法を学びましょう。...
1 分で読める

AIのコンテンツプルーニングとは何か、その仕組みやさまざまなプルーニング手法、エッジデバイスやリソース制限のある環境で効率的なAIモデルを展開するために不可欠な理由について解説します。
AIにおけるコンテンツプルーニングとは、AIモデルから冗長または重要度の低いパラメータ、重み、トークンなどを選択的に削除して、モデルのサイズを縮小し、推論速度を向上させ、メモリ消費を抑えつつ、パフォーマンスの質を維持する技術です。
AIにおけるコンテンツプルーニングは、人工知能モデルの計算複雑性やメモリ使用量を大幅に削減しつつ、パフォーマンスを大きく損なわないようにするための基本的な最適化技術です。このプロセスでは、ニューラルネットワークから冗長または重要度の低い構成要素(個々の重み、ニューロン全体、フィルタ、言語モデルのトークンなど)を体系的に見極めて除去します。主な目的は、よりスリムで高速かつ効率的なモデルを実現し、スマートフォンやエッジコンピューティング、IoTデバイスなどリソース制約のある環境でも効果的に展開できるようにすることです。
プルーニングの概念は生物学的システム、特に人間の脳で発生するシナプスプルーニング(不要な神経接続が発達の過程で取り除かれる現象)に着想を得ています。同様に、AIのプルーニングは訓練済みニューラルネットワークにしばしば最終出力にほとんど寄与しない多数のパラメータが含まれることに着目します。これらの冗長な構成要素を除去することで、精度を維持または向上させつつモデルサイズを大幅に縮小することが、微調整を通じて実現できます。
コンテンツプルーニングは、ニューラルネットワーク内のすべてのパラメータが予測に等しく重要であるわけではないという原則に基づいています。学習過程では複雑な結合関係が形成されますが、その多くは冗長となったりモデルの意思決定にほとんど寄与しなくなったりします。プルーニングはこうした重要度の低い構成要素を特定して除去し、より疎なネットワーク構造を実現することで、必要な計算資源を削減します。
プルーニングの効果は、採用する手法、プルーニング戦略の積極度、そしてその後の微調整プロセスなど複数の要因に依存します。プルーニング手法によって焦点をあてる対象も異なり、個々の重み(アンストラクチャードプルーニング)を対象とするものや、ニューロン、フィルタ、チャネル全体(ストラクチャードプルーニング)を対象とするものもあります。手法の選択は、得られるモデル効率や最新ハードウェアアクセラレータとの互換性に大きく影響します。
| プルーニング種別 | 対象 | 利点 | 課題 |
|---|---|---|---|
| 重みプルーニング | 個々の結合/重み | 最大の圧縮率、疎なネットワーク | ハードウェア実行が加速しない場合あり |
| ストラクチャードプルーニング | ニューロン、フィルタ、チャネル | ハードウェアに適合、推論高速化 | アンストラクチャードより圧縮率が低い |
| ダイナミックプルーニング | 文脈依存パラメータ | 適応的効率化、リアルタイム調整 | 実装が複雑、オーバーヘッド増大 |
| レイヤープルーニング | レイヤーやブロック全体 | 大幅なサイズ削減 | 精度低下リスク、慎重な検証が必要 |
アンストラクチャードプルーニング(重みプルーニングとも呼ばれる)は、ネットワークの重み行列から個別の重みを除去するきめ細かな手法です。この手法では通常、値がゼロに近い重みを重要度が低いとみなし除去します。結果としてネットワークは疎な構造となり、推論時に元の結合のごく一部のみが活性化します。アンストラクチャードプルーニングはパラメータ数を90%以上削減できる場合もありますが、標準ハードウェアで比例した速度向上を得るには特化した疎行列計算のサポートが必要になる場合もあります。
ストラクチャードプルーニングは、畳み込み層のフィルタ全体や全結合層のニューロン、チャネルなど、パラメータのグループ単位でまとめて削除する手法です。この方法は、生成されたモデルがGPUやTPUなどの最新ハードウェアで自然に高速実行できるため、実運用にとても有用です。畳み込み層からフィルタ全体を削除すれば、特別な疎行列演算を必要とせず即座に計算コストを削減できます。ストラクチャードプルーニングは、モデルサイズを50~90%削減しつつ、元のモデルと同等の精度を維持できることが研究で示されています。
ダイナミックプルーニングは、推論時に入力データに応じて動的にプルーニングを適用する高度な手法です。この技術では、話者埋め込みやイベントキュー、言語情報など外部コンテキストを利用して、どのパラメータを活性化させるかを柔軟に調整します。検索拡張生成(RAG)システムでは、ダイナミックプルーニングによりコンテキストサイズを約80%削減しつつ、無関係な情報をフィルタリングして回答精度も向上させることができます。多様な入力タイプの効率的処理が求められるマルチモーダルAIシステムで特に有用です。
反復的プルーニングと微調整は、実際によく用いられるアプローチです。ネットワークの一部をプルーニングし、残りのパラメータを微調整して精度を回復し、パフォーマンスを評価、さらに繰り返すというサイクルを実行します。この反復的な方法により、圧縮率とパフォーマンス維持のバランスを慎重に取ることができます。一度にすべての不要パラメータを除去するとモデル性能が大きく損なわれる恐れがあるため、徐々に複雑さを減らしながら、残されたパラメータの重要性をモデルが学習できるようにします。
ワンショットプルーニングは、訓練後に一度のステップで全体のプルーニング操作を実施し、続けて微調整を行うという高速な手法です。反復的手法より計算効率は高いものの、同時に多くのパラメータを除去しすぎると精度低下のリスクが高まります。計算資源が限られる場合には有用ですが、パフォーマンス回復のためにより多くの微調整を必要とすることが一般的です。
感度分析ベースのプルーニングは、特定の重みやニューロンを除去したときに損失関数がどれだけ増加するかを測定し、より洗練されたランキングでプルーニング対象を決定します。損失関数への影響が小さいパラメータを安全に除去可能な候補とみなすこのデータ駆動型アプローチは、単純な大きさベースの手法と比べて同等の圧縮率でも精度維持がしやすいのが特長です。
ロッタリーチケット仮説は、大規模ニューラルネットワーク内に、元のネットワークと同等の精度を初期化状態から達成できる小さく疎な「当たりくじ」サブネットワークが潜在するという理論的枠組みを提示します。この仮説はネットワーク冗長性の理解を深め、効率的なサブネットワークを見出す新たなプルーニング手法の着想源となっています。
コンテンツプルーニングは、計算効率が最重要となる多様なAIアプリケーションで今や不可欠な存在となっています。モバイルや組み込みデバイスへの展開はその代表的な用途で、プルーニングされたモデルにより、処理能力やバッテリー容量の限られたスマートフォンやIoTデバイスでも高度なAI機能の実装が可能になります。画像認識、音声アシスタント、リアルタイム翻訳などがその恩恵を受けており、精度を維持したまま最小限のリソースで動作します。
自律システム(自動運転車やドローンなど)では、待ち時間を最小限に抑えたリアルタイムな意思決定が要求されます。プルーニングされたニューラルネットワークは、センサーデータの処理や重要な判断を厳しい時間制約下で実現し、計算負荷の低減が直接的な応答速度向上につながります。これは安全性が重要な用途にとって不可欠です。
クラウドやエッジコンピューティング環境でも、プルーニングは大規模モデルの展開における計算コストやストレージ要件を削減します。これにより、同じインフラでより多くのユーザーにサービスを提供したり、計算コストを大幅に削減したりすることが可能です。特にエッジコンピューティングでは、データセンターから離れたデバイス上で高度なAI処理を実現するため、プルーニングによる効率化が大きな価値を持ちます。
プルーニングの効果を評価するには、パラメータ数の削減だけでなく複数の指標を慎重に考慮する必要があります。推論レイテンシ(入力から出力までの所要時間)は、リアルタイムアプリケーションのユーザー体験に直結する重要な指標です。効果的なプルーニングは推論レイテンシを大幅に短縮し、ユーザーへの応答速度を向上させます。
モデル精度やF1スコアもプルーニングの過程で維持されなければなりません。大きな課題は、予測精度を犠牲にせずに十分な圧縮を達成することです。よく設計されたプルーニング戦略では、パラメータ数を50~90%削減しつつ、元のモデル比で1~5%以内の精度低下に抑えることが可能です。メモリフットプリントの削減も同様に重要で、これによりリソース制約のあるデバイスへの展開が現実的となります。
大規模疎モデル(多くのパラメータを削除した大規模ネットワーク)と、小規模密モデル(最初から小さく設計されたネットワーク)を比較した研究では、同じメモリフットプリントであれば大規模疎モデルの方が常に優れたパフォーマンスを示すことが分かっています。これは、大きなネットワークを訓練してから戦略的にプルーニングすることの価値を強調しています。
精度低下は、コンテンツプルーニングにおける最大の課題です。過度なプルーニングはモデル性能を著しく損なうため、プルーニング強度の慎重な調整が必要です。どこまで圧縮しても許容できる精度低下に収まるか、その最適なバランスポイントは用途やモデル構造、要求される性能閾値によって異なります。
ハードウェア互換性の問題も、実際のメリットを制約することがあります。アンストラクチャードプルーニングで疎なネットワークを作成しても、現代のハードウェアは密な行列演算に最適化されているため、特化した疎行列計算ライブラリやハードウェアサポートがなければ実行速度が思うほど向上しないことがあります。ストラクチャードプルーニングは密な計算パターンを維持できるためこの問題を回避できますが、圧縮率はやや低くなります。
プルーニング手法自体の計算コストも無視できません。反復的プルーニングや感度分析ベースの手法は、複数回の学習や評価を必要とし、多大な計算資源を消費します。開発者はプルーニングに要する一時的コストと、展開後の効率化による継続的な恩恵を慎重に比較検討する必要があります。
汎化性能の懸念も、過度なプルーニングで生じます。トレーニングやバリデーションデータでは良好な性能を示しても、未知のデータには対応できない場合があるため、十分な検証や多様なデータセットでのテストが不可欠です。
成功するコンテンツプルーニングには、研究と実践で蓄積されたベストプラクティスに基づいた体系的なアプローチが必要です。最初から小さなネットワークを設計するのではなく、より大きくよく訓練されたネットワークから始めるのが有効です。大きなネットワークの方が冗長性や柔軟性が高く、プルーニング対象となる部分が多いため、最終的なパフォーマンスも高くなります。
反復的プルーニングと慎重な微調整で少しずつ複雑さを下げつつ、性能維持を図るのが推奨されます。この方法により、精度と効率のトレードオフをきめ細かく制御でき、モデルがパラメータ削減に適応できます。実運用ではハードウェアアクセラレーションとの相性を重視し、ストラクチャードプルーニングを活用することで、特別な疎行列演算を必要とせず標準ハードウェア上で効率的に実行できます。
多様なデータセットで広範に検証し、トレーニングデータ以外への汎化性能も確認しましょう。精度、推論レイテンシ、メモリ使用量、消費電力など複数の指標を継続的に監視し、プルーニングの効果を総合的に評価することが重要です。ターゲットとなる展開環境を考慮して戦略を選択し、デバイスやプラットフォームごとの最適化特性に合わせましょう。
コンテンツプルーニングの分野は、新たな技術や手法の登場によって進化を続けています。**文脈適応型トークンプルーニング(CATP)**は、意味的な整合性や特徴の多様性に基づき、言語モデル内で最も関連性の高いトークンのみを選択的に維持する最先端アプローチです。これは大規模言語モデルやマルチモーダルシステムでコンテキスト管理が重要となる場面に特に有効です。
PineconeやWeaviateのようなベクトルデータベースとの統合により、意味的類似度や関連度スコアに基づいたより高度なコンテキストプルーニング戦略が実現可能となります。これらの統合は効率化と精度向上の両立をサポートします。
量子化や知識蒸留など他の圧縮技術との組み合わせも相乗効果をもたらし、より攻めたモデル圧縮が可能になります。プルーニング・量子化・蒸留を同時に適用したモデルは、100倍以上の圧縮率を達成しつつ許容可能なパフォーマンスを維持できます。
AIモデルの複雑さが増し、展開シナリオも多様化する中で、コンテンツプルーニングは今後も、強力なデータセンターからリソース制約の厳しいエッジデバイスに至るまで、先端AIを誰もが使えるものにするための重要な技術としてあり続けるでしょう。
コンテンツ・プルーニングは、SEO、ユーザー体験、検索可視性を向上させるためにパフォーマンスが低いコンテンツを戦略的に削除または更新することです。質の低いページを効果的に特定し、プルーニングする方法を学びましょう。...

ChatGPT、Perplexity、Google AI OverviewsなどのAIシステム向けにサポートコンテンツを最適化するための重要な戦略を学びましょう。明確さ、構造、可視性のベストプラクティスを発見できます。...
AIモデルがどのようにコンテンツを処理するかに関するコミュニティディスカッション。トークナイゼーション、埋め込み、トランスフォーマーアーキテクチャを理解するテクニカルマーケターたちの実体験。...
クッキーの同意
閲覧体験を向上させ、トラフィックを分析するためにクッキーを使用します。 See our privacy policy.