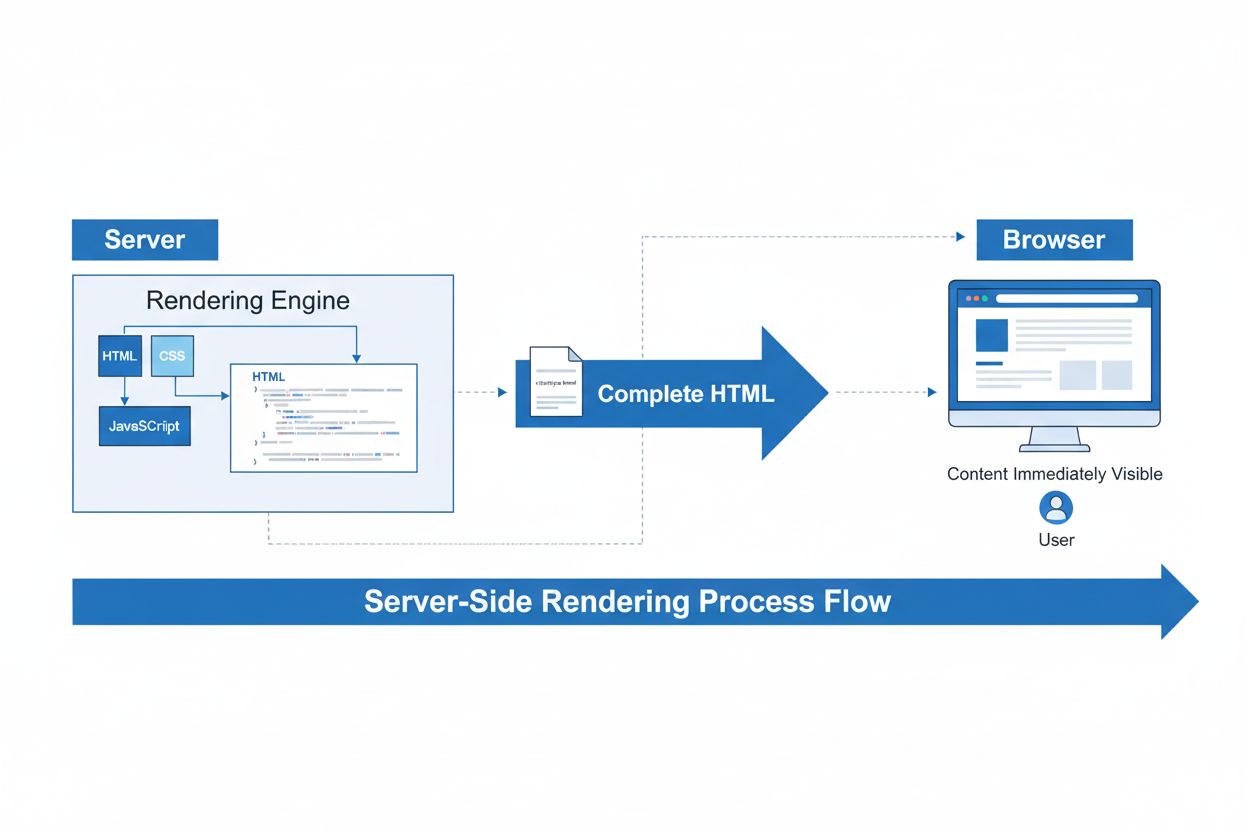
サーバーサイドレンダリング(SSR)
サーバーサイドレンダリング(SSR)は、サーバーがHTMLページ全体をレンダリングし、ブラウザに送信するWeb技術です。SSRがSEO、ページ速度、AIインデックス化を改善し、コンテンツの可視性を高める仕組みを解説します。...
1 分で読める

サーバーサイドレンダリングが効率的なAI処理、モデルのデプロイ、リアルタイム推論をAI搭載アプリケーションやLLMワークロード向けにどのように実現するか学びましょう。
AIのためのサーバーサイドレンダリングとは、人工知能モデルや推論処理がクライアント端末ではなくサーバー上で実行されるアーキテクチャ手法です。これにより計算負荷の高いAIタスクを効率的に処理し、すべてのユーザーに一貫したパフォーマンスを提供し、モデルの展開や更新も容易になります。
AIのためのサーバーサイドレンダリングとは、人工知能モデル、推論処理、計算タスクがブラウザやスマートフォンのようなクライアント端末ではなく、バックエンドサーバー上で実行されるアーキテクチャパターンを指します。この手法は従来のクライアントサイドレンダリング、すなわちユーザーのブラウザでJavaScriptが実行されてコンテンツを生成する方式とは根本的に異なります。AIアプリケーションにおけるサーバーサイドレンダリングとは、大規模言語モデル(LLM)や機械学習推論、AIによるコンテンツ生成が強力なサーバーインフラ上で一元的に行われ、その結果がユーザーに送信されることを意味します。AIの能力が飛躍的に向上し、計算負荷が増大した現代のウェブアプリケーションにおいて、このアーキテクチャの重要性はますます高まっています。
この概念は、現代のAIアプリケーションが必要とするものと、クライアント端末が現実的に提供できるものとの間に大きなギャップがあることに気づいたことから生まれました。ReactやAngular、Vue.jsといった従来のウェブ開発フレームワークは2010年代を通じてクライアントサイドレンダリングを普及させましたが、AI負荷の高いワークロードにこの方式を適用すると大きな課題が生じます。**AIのためのサーバーサイドレンダリングは、クライアント端末では実現できない専用ハードウェア、集中的なモデル管理、最適化インフラを活用することで、これらの課題を解決します。**これはAI搭載アプリケーションの設計における根本的なパラダイムシフトです。
現代AIシステムの計算要件は、サーバーサイドレンダリングを単に有益なだけでなく、しばしば必須のものとしています。特にスマートフォンや低価格ノートPCなどのクライアント端末は、リアルタイムのAI推論を効率的に処理できる十分な処理能力を持ちません。 クライアント端末でAIモデルを実行すると、ユーザーは明らかな遅延やバッテリーの急速な消耗、また端末性能によって異なる不安定なパフォーマンスを経験します。サーバーサイドレンダリングはこれらの問題を解消し、GPUやTPU、AI専用アクセラレータを備えたインフラ上にAI処理を集中させることで、一般消費者端末とは桁違いのパフォーマンスを実現します。
単なるパフォーマンスだけでなく、サーバーサイドレンダリングはモデル管理・セキュリティ・一貫性の面でも大きな利点をもたらします。AIモデルがサーバー上で稼働することで、開発者はユーザーにアップデートをダウンロードさせたり、各端末で異なるモデルバージョンを管理する必要なく、即座に新しいモデルの展開や微調整が可能です。これは進化の激しい大規模言語モデルや機械学習システムで特に重要であり、頻繁な改良やセキュリティパッチにも柔軟に対応できます。また、AIモデルをサーバー上に置くことで、クライアント端末配布時に生じる不正アクセスやモデル抽出、知的財産の盗難を防ぐことができます。
| 項目 | クライアントサイドAI | サーバーサイドAI |
|---|---|---|
| 処理場所 | ユーザーのブラウザや端末 | バックエンドサーバー |
| ハードウェア要件 | 端末の能力に依存 | 専用GPU、TPU、AIアクセラレータ |
| パフォーマンス | 端末依存で不安定 | 一貫して最適化 |
| モデルアップデート | ユーザーによるダウンロードが必要 | 即時反映可能 |
| セキュリティ | モデル抽出のリスクあり | サーバー上で保護 |
| レイテンシ | 端末性能に依存 | 最適化インフラで低遅延 |
| スケーラビリティ | 端末ごとに制限 | 複数ユーザーで高い拡張性 |
| 開発の複雑さ | 高い(端末の断片化) | 低い(一元管理) |
ネットワーク負荷とレイテンシはAIアプリケーションにおける大きな課題です。最新のAIシステムは、モデルのアップデートや学習データの取得、ハイブリッド処理のためにサーバーとの継続的な通信を必要とします。皮肉なことに、クライアントサイドレンダリングは従来のアプリケーションよりネットワークリクエストを増やし、期待されたパフォーマンス向上を損なうことがあります。サーバーサイドレンダリングでは通信を一元化し、往復遅延を減らして、ライブ翻訳やコンテンツ生成、コンピュータビジョン処理などのリアルタイムAI機能をクライアント推論より滑らかに実現します。
同期の複雑さは、複数のAIサービスで状態の一貫性を保つ必要がある場合に発生します。現代のアプリケーションはしばしば埋め込みサービス、補完モデル、ファインチューニング済みモデル、専用推論エンジンなどを同時に利用し、相互に調整しなければなりません。クライアント端末でこの分散状態を管理するのは非常に複雑で、特にリアルタイム共同AI機能ではデータの不整合が生じやすくなります。サーバーサイドレンダリングでは状態管理を中央集約し、すべてのユーザーに一貫した結果を保証するとともに、複雑なクライアントサイド同期の技術的負担を排除します。
端末の断片化はクライアントサイドAI開発の大きな課題です。各端末はニューラルプロセッシングユニット(NPU)、GPUアクセラレーション、WebGLサポート、メモリ制限などAI能力が異なります。この多様な環境下で一貫したAI体験を実現するには莫大な開発工数や段階的な機能縮小、端末ごとの複数コードパスが必要です。サーバーサイドレンダリングでは、ユーザーがどの端末を使っていても同じ最適化AI処理基盤にアクセスできるため、この断片化を完全に排除します。
サーバーサイドレンダリングはAIアプリケーションアーキテクチャをシンプルかつ保守しやすい形に進化させます。数千、数万のクライアント端末にAIモデルや推論ロジックを分散配布するのではなく、サーバー上の単一で最適化された実装を管理し、一元化します。これによりデプロイサイクルの高速化、デバッグの容易さ、パフォーマンス最適化の単純化など、即時の利点が得られます。AIモデルの改良やバグ修正も、サーバー側を一度直すだけでよく、端末ごとに異なるアップデート展開や採用率の差を心配する必要がありません。
リソース効率もサーバーサイドレンダリングで劇的に向上します。サーバーインフラは全ユーザー間でリソース共有が可能で、コネクションプールやキャッシュ戦略、ロードバランシングによりハードウェア活用率を最大化します。サーバー上の1つのGPUで何千人ものユーザーの推論リクエストを順次処理できるのに対し、同じ能力をクライアント端末に分散するには何百万ものGPUが必要です。この効率化は運用コストの削減、環境負荷の低減、アプリ拡大時の高いスケーラビリティにもつながります。
セキュリティと知的財産保護もサーバーサイドレンダリングで大幅に容易になります。AIモデルは研究や学習データ、計算資源への多大な投資の結晶です。モデルをサーバー上に保持することで、モデル抽出攻撃、不正アクセス、知的財産の盗難といったクライアント配布時に生じるリスクを防ぐことができます。さらにサーバー側処理なら、きめ細やかなアクセス制御、監査ログ、コンプライアンス監視も実現でき、分散したクライアント端末では不可能な管理が可能です。
現代のフレームワークはAIワークロード向けのサーバーサイドレンダリングを効果的にサポートするよう進化しています。Next.jsはその先頭を走り、Server Actionsによりサーバーコンポーネントから直接AI処理をシームレスに実行できます。開発者はAI APIコールや大規模言語モデルの処理、レスポンスのストリーミングを最小限のボイラープレートで実装できます。フレームワークがサーバー・クライアント間通信の複雑さを吸収し、開発者はAIロジックに集中できます。
SvelteKitはサーバーで事前処理されるload関数により、AIレンダリングをパフォーマンス重視で実現します。これによりAIデータの事前処理、レコメンデーション生成、AI強化コンテンツの下準備をHTML送信前に行えます。その結果、アプリケーションはJavaScriptフットプリントを最小限に抑えつつ、AI機能を維持し、極めて高速なユーザー体験を実現します。
Vercel AI SDKのような専用ツールは、AIレスポンスのストリーミングやトークンカウント、各種AIプロバイダAPIの管理といった複雑さを抽象化します。これにより開発者はインフラ知識がなくても高度なAIアプリケーションを構築できます。Vercel Edge FunctionsやCloudflare Workers、AWS Lambdaなどのインフラオプションは、グローバルに分散されたサーバーサイドAI処理を提供し、モデル管理を一元化したまま、ユーザーの近くでリクエストを処理してレイテンシを低減します。
効果的なサーバーサイドAIレンダリングには、計算コストとレイテンシを管理する高度なキャッシュ戦略が不可欠です。Redisキャッシュは、頻繁に要求されるAIレスポンスやユーザーセッションを保存し、類似クエリの再処理を排除します。CDNキャッシュはAI生成の静的コンテンツをグローバルに配信し、ユーザーが地理的に近いサーバーから応答を受け取れるようにします。エッジキャッシュ戦略はAI処理済みコンテンツをエッジネットワークに分散し、モデル管理を一元化しつつ超低レイテンシのレスポンスを実現します。
これらのキャッシュ手法を組み合わせることで、利用者が数百万規模に増えても計算コストが比例して増加しない効率的なAIシステムを構築できます。AIレスポンスを複数階層でキャッシュすることで、ほとんどのリクエストはキャッシュから即時提供され、本当に新しい問い合わせだけが再計算されます。これによりインフラコストを劇的に削減し、レスポンス速度の向上でユーザー体験も改善されます。
サーバーサイドレンダリングへの進化は、AI要件に対応したウェブ開発手法の成熟を象徴しています。AIがウェブアプリケーションの中核となるにつれ、計算現実はサーバー中心のアーキテクチャを要求します。今後はコンテンツ種別・端末能力・ネットワーク状況・AI処理要件に応じて自動でレンダリング場所を判断する高度なハイブリッドアプローチが主流になります。フレームワークはAI機能でアプリを強化しつつ、コア機能は普遍的に動作させる進化を続けるでしょう。
このパラダイムシフトは、シングルページアプリケーション時代の教訓を活かしつつ、AIネイティブアプリケーションの課題を解決します。ツールやフレームワークは既にAI時代のサーバーサイドレンダリング活用を可能にしており、次世代の賢く、応答性が高く、効率的なウェブアプリケーション実現への道を切り開いています。
ChatGPT、Perplexity、その他AI検索エンジンであなたのドメインやブランドがAI生成の回答にどのように表示されているか追跡しましょう。AIでの可視性をリアルタイムで把握できます。
サーバーサイドレンダリング(SSR)は、サーバーがHTMLページ全体をレンダリングし、ブラウザに送信するWeb技術です。SSRがSEO、ページ速度、AIインデックス化を改善し、コンテンツの可視性を高める仕組みを解説します。...
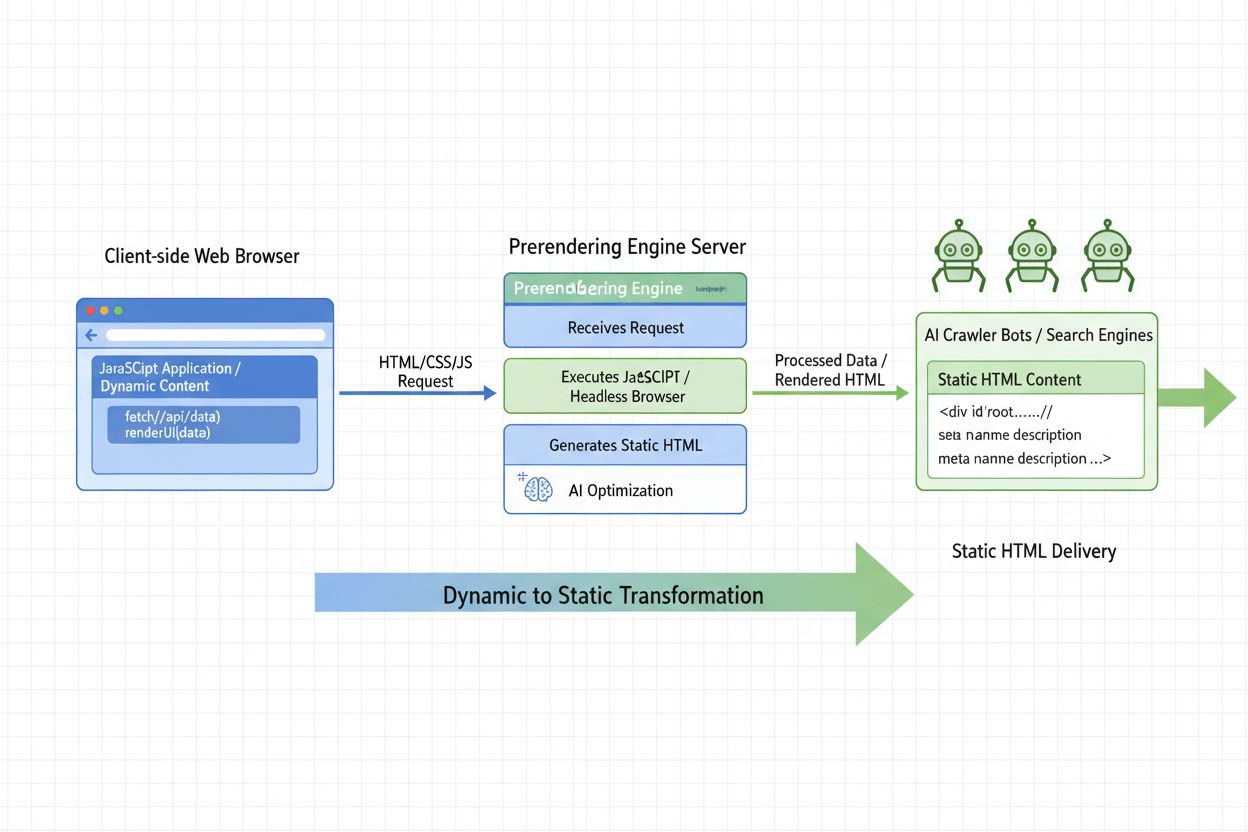
AIプリレンダリングとは何か、そしてサーバーサイドレンダリング戦略がどのようにAIクローラーの可視性を最適化するのかを学びましょう。ChatGPT、Perplexity、その他のAIシステム向けの実装戦略もご紹介します。...

プリレンダリングがChatGPT、Perplexity、ClaudeなどのAI検索結果にあなたのウェブサイトを表示させる仕組みと、AI向け可視性の技術的実装や利点について解説します。...
クッキーの同意
閲覧体験を向上させ、トラフィックを分析するためにクッキーを使用します。 See our privacy policy.