
AIソース選択
AIシステムが引用するソースをどのように選択・順位付けしているかを学びましょう。ChatGPT、Perplexity、Google AI Overviews などのAIプラットフォームが、どのウェブサイトを回答で引用するかを決定するアルゴリズム、シグナル、要素を解説します。...
1 分で読める

AIにおけるソース選択バイアスについて、その仕組みや機械学習モデルへの影響、実例、検出と緩和のための戦略を学びましょう。
ソース選択バイアスは、トレーニングデータが全体の母集団や現実世界の分布を適切に代表していない場合に発生し、AIモデルが過小評価されたグループやシナリオに対して不正確な予測を行う原因となります。
ソース選択バイアスは、機械学習モデルのトレーニングに使用されるデータが、実際にサービスを提供すべき現実世界の母集団や分布を適切に代表していない場合に発生する、人工知能における根本的な問題です。このバイアスは、特定のグループやシナリオ、特性が体系的に除外されたり過小評価されたりする方法でデータセットが選ばれるときに生じます。その結果、AIモデルは不完全または偏ったデータからパターンを学習し、過小評価された集団に対して不正確、不公平、または差別的な予測を行うようになります。このバイアスを理解することは、AIシステムを開発・運用・利用するすべての人にとって極めて重要であり、業界全体における自動化された意思決定の公平性・正確性・信頼性に直結します。
ソース選択バイアスは、他のバイアスとは異なり、データ収集段階そのものから生じます。アルゴリズム上の選択やモデル開発時の人間の仮定から生じるのではなく、バイアスがトレーニングデータセットの基盤に組み込まれています。そのため、どれほど高度なアルゴリズムを用いても、バイアスのあるソースデータでトレーニングされたモデルは、そのバイアスを予測において再生・増幅してしまいます。医療・金融・刑事司法・採用などの重要な領域でAIシステムが導入されると、この問題の深刻さはさらに増します。バイアスのある予測は、個人やコミュニティに重大な影響を及ぼす可能性があります。
ソース選択バイアスは、データ収集やキュレーションの過程でいくつかの異なる仕組みによって発生します。最も一般的な経路はカバレッジバイアスで、特定の集団やシナリオがトレーニングデータセットから体系的に除外される場合に起こります。たとえば、顔認識システムが主に明るい肌色の人物画像でトレーニングされている場合、より暗い肌色の顔についてのカバレッジが不十分となり、その集団に対する誤認識率が高くなります。これは、データ収集者が多様な集団へのアクセスが限られていたり、無意識に特定のグループを優先してデータ収集を行うことで発生します。
もう一つの重要な仕組みは無回答バイアス(参加バイアスとも呼ばれる)で、特定のグループがデータ収集プロセスに参加しにくい場合に生じます。たとえば、消費者の好みを予測するための調査ベースのデータセットにおいて、特定の人口集団が調査に回答しにくい場合、そのグループの好みはトレーニングデータで過小評価されます。これにより、一見バランスが取れているようで、実際には参加パターンを反映したデータセットとなり、真の母集団特性を表していません。医療分野では、臨床試験データの多くが都市部の高度な医療機関から得られている場合、AIモデルが農村部や医療過疎地域に一般化できなくなります。
サンプリングバイアスは三つ目の仕組みで、データ収集時に適切なランダム化が行われていない場合に発生します。データ収集者がランダムにデータポイントを選ぶのではなく、最初に入手可能なサンプルや利便性サンプリングを用いることで、選ばれたサンプルが広範な母集団を代表しなくなります。たとえば、ローン返済の予測AIモデルが特定の地域や時期のデータのみでトレーニングされている場合、他の地域や異なる経済状況では精度が低下する可能性があります。
| バイアスの種類 | 仕組み | 実例 |
|---|---|---|
| カバレッジバイアス | 集団の体系的な除外 | 明るい肌色の顔のみでトレーニングされた顔認識 |
| 無回答バイアス | データ収集時の参加ギャップ | 都市部人口のみでトレーニングされた医療モデル |
| サンプリングバイアス | 選択時のランダム化不足 | 単一地域のデータでトレーニングされたローン予測モデル |
| 時系列バイアス | 特定時期のデータ利用 | パンデミック前のデータでトレーニングし、以後に適用されたモデル |
| ソース多様性バイアス | ソースの限定 | 単一の病院システムの医用画像データセット |
AIシステムにおけるソース選択バイアスの影響は深刻かつ広範であり、個人・組織の双方に影響します。医療分野では、ソース選択バイアスにより、特定の患者集団に対して著しく精度の低い診断システムが誕生しています。皮膚がん診断用AIアルゴリズムは、暗い肌色の患者に対して明るい肌色の患者の半分程度しか診断精度が出ない例も報告されています。この格差は、診断の遅れ、不適切な治療提案、健康格差の拡大に直結します。特定の集団の患者データが主に使われている場合、モデルはその集団特有のパターンしか学習できず、他に一般化できません。
金融サービスでは、クレジットスコアや融資アルゴリズムにおけるソース選択バイアスが歴史的な差別を再生産しています。過去の差別的な融資実績データでトレーニングされたモデルは、新たな融資判断においても同じバイアスを再現します。歴史的に特定のグループがクレジットを拒否されてきた場合、そのデータでAIモデルをトレーニングすると、将来も同じグループへの融資を拒否するよう学習してしまいます。これにより、歴史的な不平等がアルゴリズム決定に埋め込まれ、資本や経済機会へのアクセスが阻害されます。
採用・リクルートでも、ソース選択バイアスは大きな害をもたらします。履歴書選別に使われるAIツールは、人種や性別に基づくバイアスを示すことがあり、あるシステムでは白人系の名前が85%の確率で優遇されたという研究もあります。過去の採用記録が差別的または同質的なパターンを反映している場合、モデルはそれを再現します。結果として、採用データのソース選択バイアスが職場の差別を拡大し、多様性を損ないます。
刑事司法分野では、予測的ポリシングシステムのソース選択バイアスにより、特定コミュニティが過剰に標的とされる事例があります。過去の逮捕記録がすでにマイノリティ集団にバイアスがかかっている場合、そのデータでトレーニングされたモデルは、これらのコミュニティで高い犯罪率を予測し、結果的にその地域への警察活動が強化され、さらに偏った逮捕データが生まれ、バイアスが強化されるという悪循環が生まれます。
ソース選択バイアスを検出するには、定量分析・定性評価・継続的なモニタリングを組み合わせた体系的なアプローチが必要です。まずは包括的なデータ監査を行い、トレーニングデータのソース・収集方法・代表性を検証します。データがどこから来たのか、どのように収集されたのか、特定の集団やシナリオが体系的に除外されていないかを記録します。すべての関連人口集団が収集過程で代表されたか?参加障壁はなかったか?収集期間や地域が代表性を損なっていないか?など、重要な質問を投げかけます。
人口統計的パリティ分析は、ソース選択バイアス検出のための定量的手法です。トレーニングデータの主要特性分布と、モデルがサービスを提供する実世界の分布を比較します。特定の人口集団・年齢層・地域などがトレーニングデータで大きく過小評価されている場合、明らかなソース選択バイアスがあります。たとえば、トレーニングデータの女性比率が5%しかないのに、実際のターゲットは50%である場合、深刻なカバレッジバイアスがあり、女性に対するモデル精度が著しく低下する恐れがあります。
パフォーマンススライス分析は、異なる人口集団やサブグループごとにモデルのパフォーマンスを個別に評価する重要な検出手法です。全体精度が高く見えても、グループごとの精度に大きな差が出ている場合があります。たとえば、全体で95%の精度でも、ある集団では70%しか出ていない場合、トレーニングデータのソース選択バイアスが影響している可能性が高いです。この分析は、単なる精度だけでなく、イコライゼドオッズや差別的影響などの公正性指標でも行うべきです。
アドバーサリアルテストは、潜在バイアスを露呈させることを目的に、意図的に多様なテストケースを作成する方法です。過小評価された集団やエッジケース、トレーニングデータで十分にカバーされていないシナリオでモデルをテストします。例えば、都市部データでトレーニングしたモデルを農村部データで徹底的にテストして精度低下を確認したり、特定の時期のデータで学習したモデルを異なる時期のデータでテストして時系列バイアスを検出したりします。
ソース選択バイアスの緩和には、AI開発ライフサイクルの複数段階での介入が必要です。最も有効なのはデータ中心のバイアス緩和で、トレーニングデータの質と代表性を高めることでバイアスの根源にアプローチします。まずは多様なデータ収集を実施し、過小評価されている集団やシナリオを意識的にデータセットに加えます。利便性サンプリングや既存データセットに頼るのではなく、すべての関連人口集団やユースケースを適切にカバーするためのターゲットデータ収集を行うべきです。
リサンプリング・重み付け手法は、既存データセットの不均衡に対処する実践的な方法です。ランダムオーバーサンプリングは過小評価グループのサンプルを複製し、ランダムアンダーサンプリングは過大評価グループのサンプルを減らします。層化サンプリングは複数次元での比率維持を可能にします。重み付けは、トレーニング時に過小評価サンプルの重要度を高め、マイノリティパターンの学習を促します。これら手法は、できる限り多様な新規データ収集と組み合わせて活用するのが効果的です。
合成データ生成も、特に実データ収集が困難・高コストな場合の有効なバイアス対策です。GAN(敵対的生成ネットワーク)やVAE(変分オートエンコーダー)などにより、過小評価グループ向けのリアルな合成サンプルを作成できます。SMOTEのような手法では、既存のマイノリティ事例を補間して新たな合成サンプルを作成します。ただし、合成データは新たなバイアスを生むリスクもあるため、慎重な検証が必要です。
公正性を考慮したアルゴリズムも、モデル学習段階でのバイアス緩和策となります。これらアルゴリズムは、全人口集団での均等なパフォーマンスを保証するため、学習プロセスに公正性制約を明示的に組み込みます。アドバーサリアルデバイアシングでは、モデル予測から人種や性別など保護特性の推定ができないよう敵対的ネットワークを用いて制約をかけます。公正性正則化では、損失関数に差別的行動を抑制するペナルティ項目を追加します。これらの手法により、全体精度と公平性のトレードオフを明確に調整できます。
継続的なモニタリングと再学習も重要です。最初のトレーニングデータが代表的でも、現実世界の母集団分布は人口動態や経済変化などで変化します。グループごとのモデル精度を継続的に監視し、バイアスが発生した場合は最新データで再学習し、公平性を回復します。バイアス緩和は一度きりの作業ではなく、継続的な責務であることを認識しましょう。
AI回答モニタリングやブランド露出監視の文脈で、ソース選択バイアスの理解はますます重要になります。ChatGPTやPerplexityなどAI回答生成システムが主要な情報源となる中、これらが引用・提示する情報はトレーニングデータによって形作られます。もしトレーニングデータにソース選択バイアスが存在すれば、AIが生成する回答にもそのバイアスが反映されます。たとえば、特定のウェブサイトや出版物、視点が過大評価され、他が過小評価されている場合、AIは過大評価されたソースの情報を優先的に引用しやすくなります。
これはブランドモニタリングやコンテンツ可視性に直結します。主要AIシステムのトレーニングデータに自社ブランドやドメイン、URLが十分に含まれていない場合、AI生成回答から組織の情報が体系的に除外・過小評価される恐れがあります。逆に競合ブランドや誤情報ソースが過大評価されていれば、AI回答でそれらの可視性が不釣り合いに高まります。AIプラットフォームごとに自社ブランドがどのように表示されているかを監視することで、ソース選択バイアスによる可視性や評判への影響を把握できます。引用ソースや出現頻度、情報の正確性を追跡することで、AIが業界やブランドをどのように表現しているかのバイアスを特定できます。
AIにおけるソース選択バイアスは、データ収集段階に端を発し、機械学習モデルのあらゆる応用に波及する重大な公平性問題です。トレーニングデータが特定の集団・シナリオ・特性を体系的に除外・過小評価することで、過小評価グループに対して不正確または不公平なモデル予測が生じます。その結果は深刻かつ広範であり、医療・金融・雇用・刑事司法など多くの分野において人々の機会や健康・生活に悪影響を及ぼします。ソース選択バイアスの検出には、包括的なデータ監査・人口統計的パリティ分析・パフォーマンススライス分析・アドバーサリアルテストが必要です。緩和には、多様なデータ収集・リサンプリングと重み付け・合成データ生成・公正性アルゴリズム・継続的なモニタリングの多面的アプローチが求められます。組織は、ソース選択バイアスへの対応を「選択肢」ではなく、あらゆる集団や用途において公平・正確・信頼できるAIシステムを構築するための「必須事項」として認識する必要があります。
AIシステムが引用するソースをどのように選択・順位付けしているかを学びましょう。ChatGPT、Perplexity、Google AI Overviews などのAIプラットフォームが、どのウェブサイトを回答で引用するかを決定するアルゴリズム、シグナル、要素を解説します。...
AIシステムのソース選択バイアスについてのコミュニティディスカッション。マーケターや研究者による、AIの引用パターンの理解と対策に関する実体験が集まっています。...
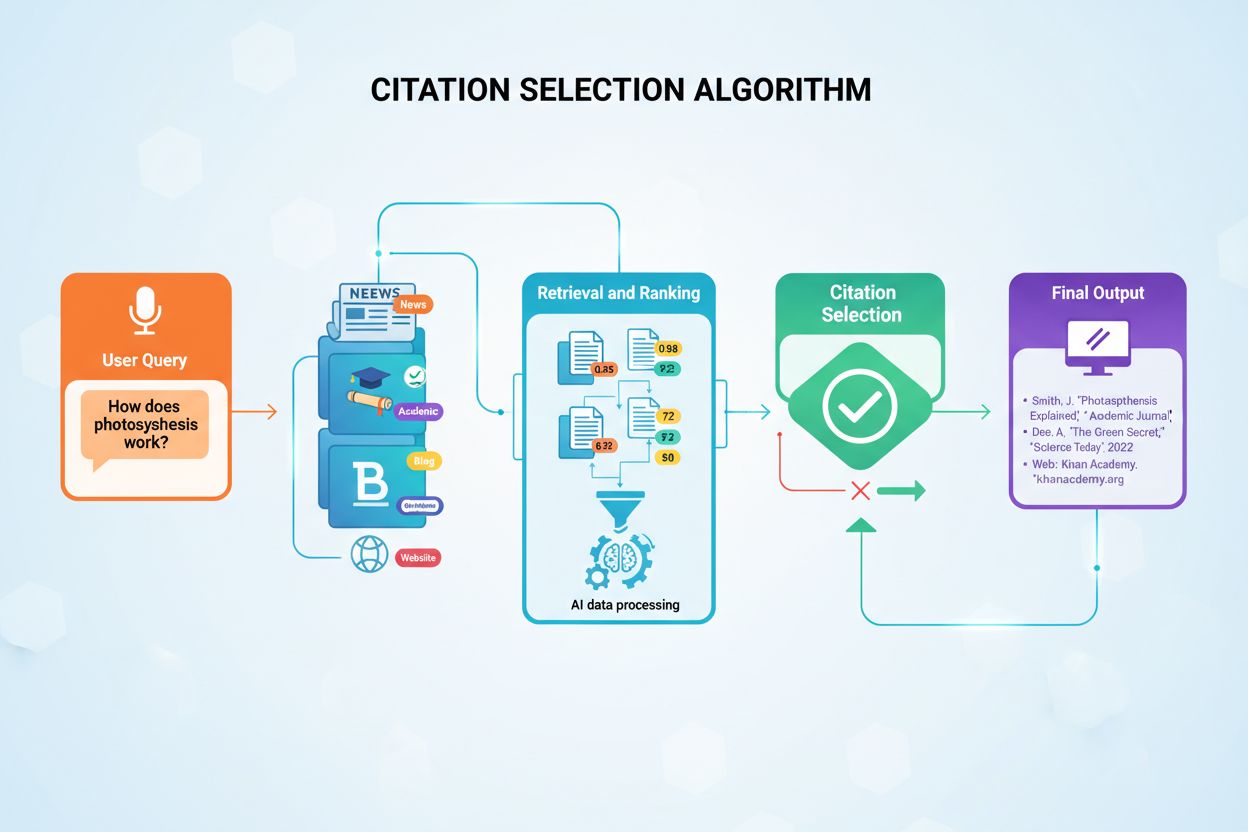
AIシステムがどの情報源を引用し、どれを要約・言い換えるかを選ぶ仕組みを解説。引用選択アルゴリズム、バイアスパターン、AI生成応答におけるコンテンツ可視性向上の戦略を理解しよう。...