AI検索テックスタックを構築するために必要なコンポーネントは何ですか?
現代のAI検索テックスタックを構築するために必要な主要コンポーネント、フレームワーク、ツールについて学びましょう。検索システム、ベクトルデータベース、埋め込みモデル、デプロイ戦略を紹介します。...
1 分で読める
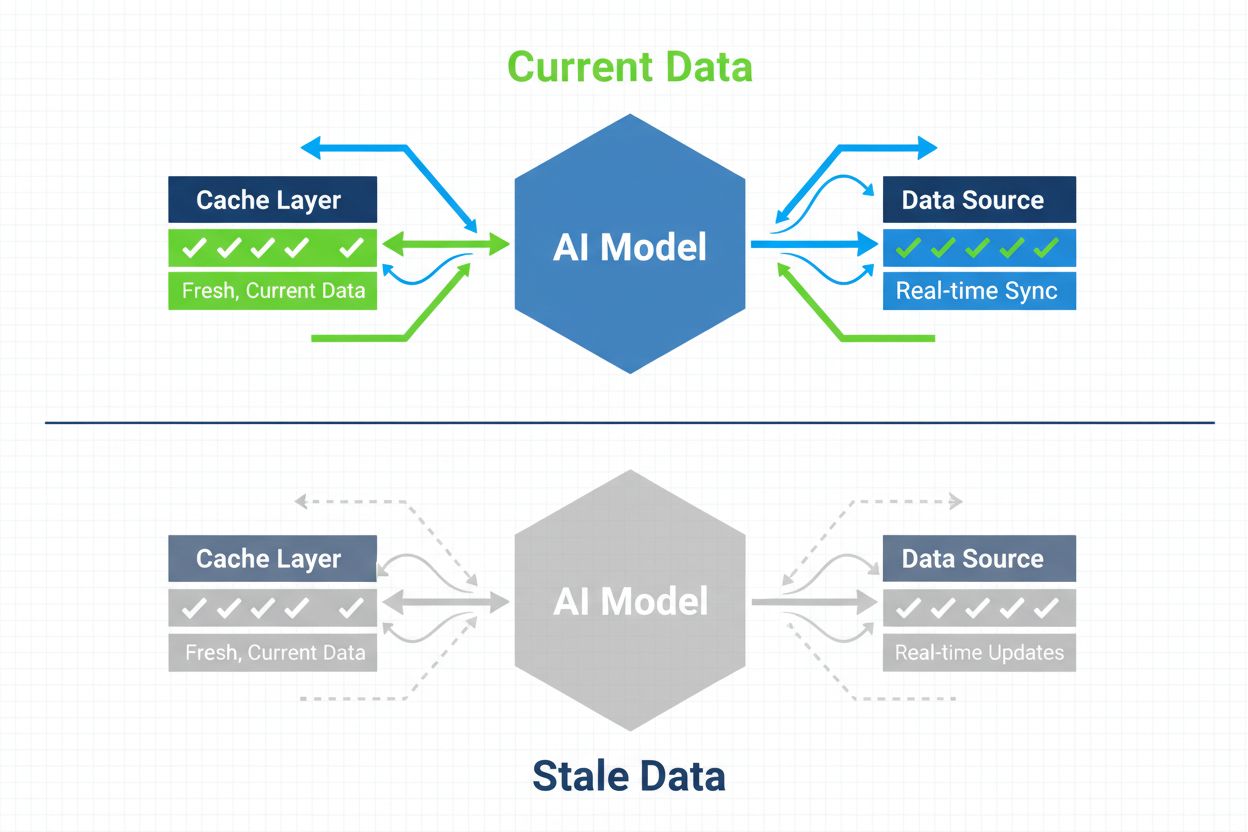
AIシステムが最新のコンテンツへアクセスできるようにするための戦略。キャッシュ管理は、キャッシュによるパフォーマンス向上と、古くなった情報を提供してしまうリスクのバランスをとります。無効化戦略や監視によりデータの新鮮さを保ちつつ、レイテンシーやコストを削減します。
AIシステムが最新のコンテンツへアクセスできるようにするための戦略。キャッシュ管理は、キャッシュによるパフォーマンス向上と、古くなった情報を提供してしまうリスクのバランスをとります。無効化戦略や監視によりデータの新鮮さを保ちつつ、レイテンシーやコストを削減します。
AIキャッシュ管理とは、AIシステムにおいて、以前に計算された結果・モデル出力・APIレスポンスなどを体系的に保存・再利用し、無駄な再処理を避けてレイテンシーを削減する手法です。最大の課題は、キャッシュによるパフォーマンス向上と、キャッシュされた古い情報が現在のシステム状態やユーザー要件を反映しないリスクとのバランスを取ることにあります。特に大規模言語モデル(LLM)やAIアプリケーションでは、推論コストが高く、応答速度がユーザー体験に直結するため、この課題は極めて重要です。キャッシュ管理システムは、キャッシュ済みの結果がいつまで有効か、いつ新たな計算が必要かをインテリジェントに判断する必要があり、プロダクションAI導入における根幹的な設計要素となっています。
効果的なキャッシュ管理は、AIシステムのパフォーマンスに多角的かつ大きな効果をもたらします。キャッシュ戦略を導入することで、繰り返しクエリ時の応答レイテンシーを80~90%削減し、APIコストもキャッシュヒット率やシステム構成により50~90%削減可能です。パフォーマンス指標だけでなく、キャッシュの適切な無効化により常に最新の情報が提供されるため、精度の一貫性やシステム信頼性にも直接影響します。これらの改善は、AIシステムが数百万リクエストを処理するスケールに達するほど重要性を増し、キャッシュ効率の累積的な効果がインフラコストやユーザー満足度を左右します。
| 項目 | キャッシュあり | キャッシュなし |
|---|---|---|
| 応答時間 | 80~90%高速 | 基準値 |
| APIコスト | 50~90%削減 | 全額負担 |
| 精度 | 一貫性あり | 変動あり |
| スケーラビリティ | 高い | 限定的 |
キャッシュ無効化戦略は、キャッシュデータをいつ・どのようにリフレッシュまたは削除するかを決定するもので、キャッシュ設計における最重要ポイントです。無効化アプローチごとにデータの新鮮さとパフォーマンスのトレードオフが異なります。
どの戦略を選ぶかはアプリケーション要件次第です。精度重視のシステムでは高いレイテンシーコストを許容してでも積極的な無効化を選ぶ一方、パフォーマンス重視なら多少古いデータを許容してもミリ秒未満の応答速度を優先します。
大規模言語モデルにおけるプロンプトキャッシングは、キャッシュ管理の中でも特化した応用例であり、中間的なモデル状態やトークン列を保存することで、同一または類似入力の再処理を回避します。LLMでは、完全一致による厳密キャッシュ(プロンプトが文字単位で完全一致する場合)と、意味的に同等とみなすセマンティックキャッシュの2つが主に用いられます。OpenAIは自動プロンプトキャッシュを導入しており、1024トークン以上のプロンプト区間でキャッシュが有効になり、キャッシュ済みトークンは50%コスト削減されます。Anthropicはより積極的な90%コスト削減を提供しますが、開発者がキャッシュキーや持続時間を明示的に管理する必要があり、モデル構成によって1024~2048トークンの最小要件があります。LLMのキャッシュ持続時間は通常数分から数時間で、キャッシュ状態の再利用による計算コスト削減と、時間依存性の高いアプリにおける古いモデル出力のリスクをバランスさせています。
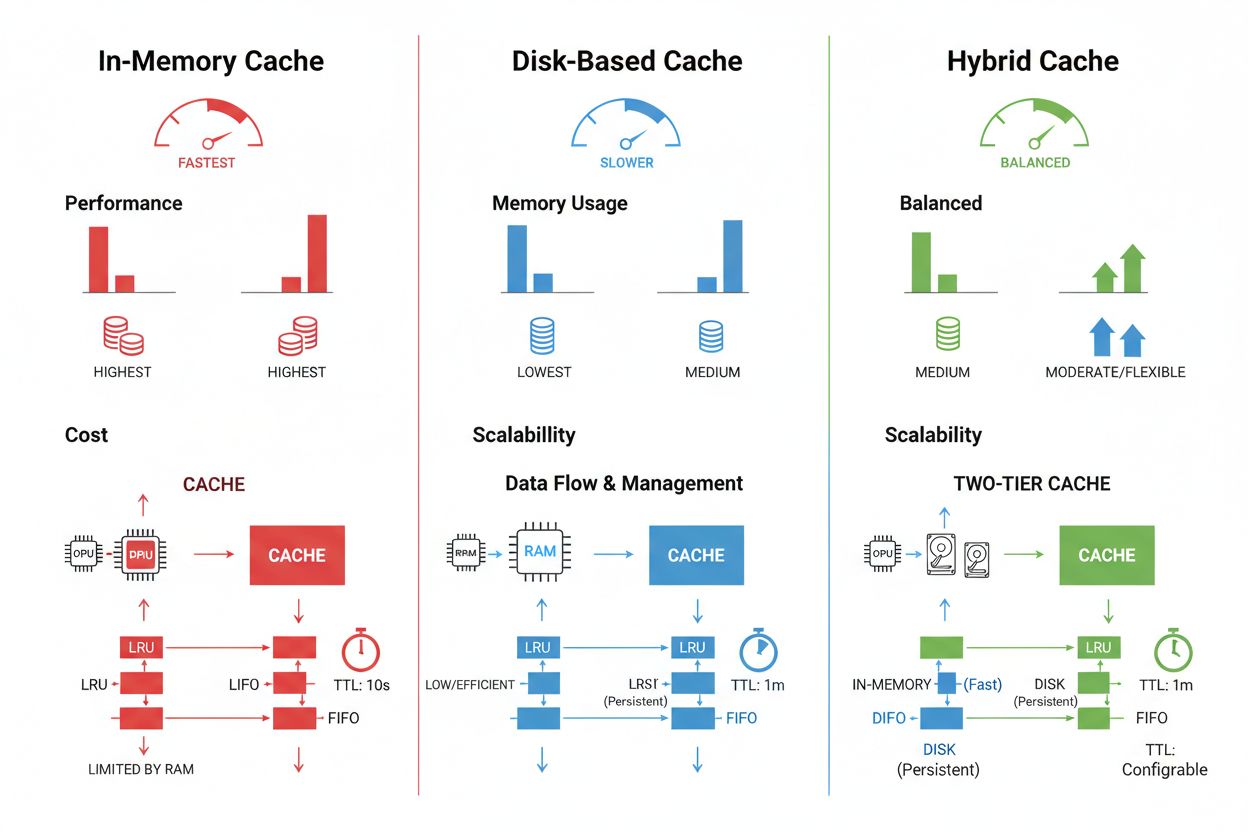
キャッシュストレージや管理手法は、求められるパフォーマンスやデータ量、インフラ制約によって大きく異なります。それぞれに利点と制約があります。Redisなどのインメモリキャッシュはマイクロ秒単位の超高速アクセスが特徴で、頻繁なクエリに最適ですがRAM消費量が大きくメモリ管理が重要です。ディスクベースキャッシュは大規模データの格納や再起動時の持続性に優れますが、レイテンシーはミリ秒単位とインメモリより遅くなります。ハイブリッド方式では、頻繁アクセスデータはメモリ、その他はディスクに保存することでバランスを図ります。
| ストレージ種別 | 適した用途 | パフォーマンス | メモリ使用量 |
|---|---|---|---|
| インメモリ(Redis) | 頻繁なクエリ | 最速 | 高い |
| ディスクベース | 大規模データ | 中程度 | 低い |
| ハイブリッド | 混在ワークロード | バランス型 | バランス型 |
効果的なキャッシュ管理には、データ変動性に合わせたTTL設定(変化が激しいデータは短いTTL、安定した内容は長いTTL)と、キャッシュヒット率・エビクションパターン・メモリ利用状況などの継続的な監視・最適化が不可欠です。
実際のAIアプリケーションは、キャッシュ管理の変革的な効果と運用上の複雑さの両面を示しています。カスタマーサービス用チャットボットでは、よくある質問への応答をキャッシュすることで一貫性ある回答と60~70%の推論コスト削減を実現し、数千ユーザーへのコスト効率的なスケーリングを可能にします。コーディングアシスタントは、よく使うコードパターンやドキュメントスニペットをキャッシュし、ピーク時でも100ms未満でサジェスト可能です。ドキュメント処理システムは頻繁に分析する文書の埋め込みや意味表現をキャッシュし、類似検索や分類タスクを高速化します。
一方、運用上の課題も多数存在します。分散システムではキャッシュ一貫性の維持が複雑化し、リソース制約下ではキャッシュ容量とカバー範囲のトレードオフが求められます。機密データをキャッシュする場合、暗号化やアクセス制御が不可欠で、キャッシュ更新の調整にはレースコンディションやデータ不整合のリスクも伴います。キャッシュの新鮮度・ヒット率・無効化イベントなどを監視する包括的なモニタリングは、システム信頼性確保と、データパターンやユーザー行動の変化に応じたキャッシュ戦略の見直しに不可欠です。
キャッシュの無効化は、変更があった際に古いデータを削除または更新し、即座に新鮮な情報を提供しますが、イベント駆動型のトリガーが必要です。キャッシュの有効期限(TTL)は、データがキャッシュに残る期間を設定し、シンプルに実装できますが、TTLが長すぎると古いデータが提供される場合があります。多くのシステムは両方のアプローチを組み合わせて最適なパフォーマンスを実現しています。
効果的なキャッシュ管理により、キャッシュヒット率やシステム構成によってはAPIコストを50~90%削減できます。OpenAIのプロンプトキャッシュはトークンごとに50%のコスト削減、Anthropicは最大90%の削減を提供します。実際の削減幅はクエリパターンやどれだけ効果的にキャッシュできるかによって異なります。
プロンプトキャッシングは、大規模言語モデルで中間モデル状態やトークン列を保存し、同一または類似の入力の再処理を回避します。文字単位で一致させる厳密キャッシュと、異なる表現でも意味が同じプロンプトを判別するセマンティックキャッシュがあります。これにより繰り返しクエリ時のレイテンシーが80%、コストが50~90%削減されます。
主な戦略は次のとおりです:設定時間経過後に自動削除する「時間ベース有効期限(TTL)」、データ変更時に即時更新する「イベントベース無効化」、意味ベースで類似クエリを無効化する「セマンティック無効化」、複数の手法を組み合わせる「ハイブリッド型」です。選択はデータの変動性や新鮮さの要件によります。
インメモリキャッシュ(例:Redis)はマイクロ秒レベルの高速アクセスが可能で頻繁なクエリに最適ですが、多くのRAMを消費します。ディスクベースキャッシュは大きなデータセットに対応し、再起動時も持続しますが、レイテンシーはミリ秒単位になります。ハイブリッド型は、よく使うデータをメモリ、その他をディスクで管理します。
TTLはキャッシュされたデータが有効である期間を決めるカウントダウンタイマーです。変化の激しいデータには短いTTL(数分)、安定したコンテンツには長いTTL(数時間~数日)が適しています。適切なTTL設定によりデータの新鮮さと不要なキャッシュ更新やサーバー負荷とのバランスを取ります。
効果的なキャッシュ管理により、インフラ拡張を伴わずにAIシステムがより多くのリクエストを処理できるようになります。キャッシュによるリクエストごとの計算負荷軽減で、数百万ユーザーにも低コストで対応可能です。キャッシュヒット率はインフラコストやユーザー満足度に直結します。
機密データのキャッシュは、適切な暗号化やアクセス制御がなければセキュリティリスクとなります。不正アクセス、無効化時のデータ漏洩、意図しない機密情報のキャッシュ化などがリスクです。完全な暗号化、アクセス制御、監視により機密データの保護が不可欠です。
現代のAI検索テックスタックを構築するために必要な主要コンポーネント、フレームワーク、ツールについて学びましょう。検索システム、ベクトルデータベース、埋め込みモデル、デプロイ戦略を紹介します。...
AI検索での可視性を損なう重大なミスを解説します。コンテンツ構造の不備、スキーママークアップ未実装などのGEOエラーがChatGPT・Perplexity・Claudeによるブランド引用を妨げる理由を学びましょう。...
ChatGPT、Perplexity、その他のAI回答生成システムにおけるコンテンツパフォーマンスの測定方法を解説します。ブランドの可視性やコンテンツ有効性を追跡するための主要指標、KPI、監視戦略を紹介。...