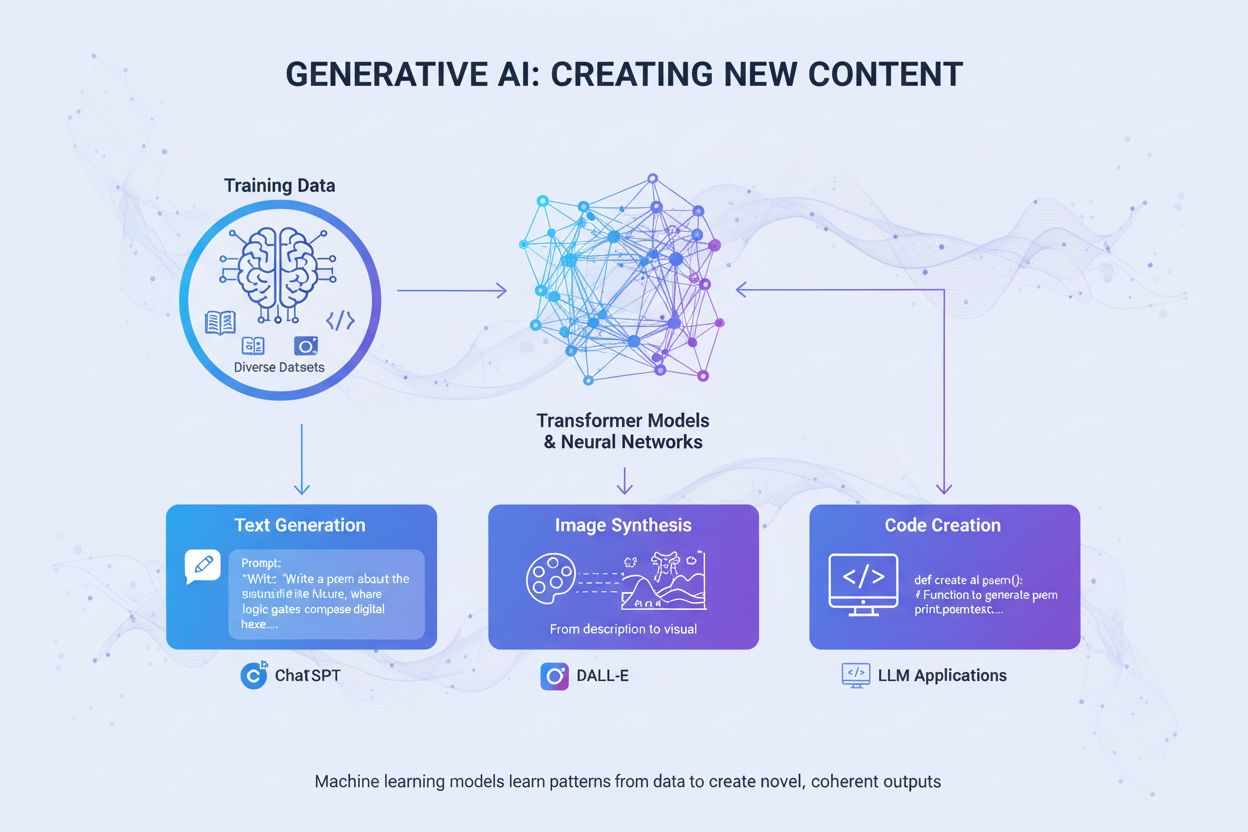
生成AI
生成AIはニューラルネットワークでトレーニングデータから新しいコンテンツを創出します。仕組みやChatGPT・DALL-Eでの応用、ブランドのAI可視性監視がなぜ重要かを解説。...
1 分で読める
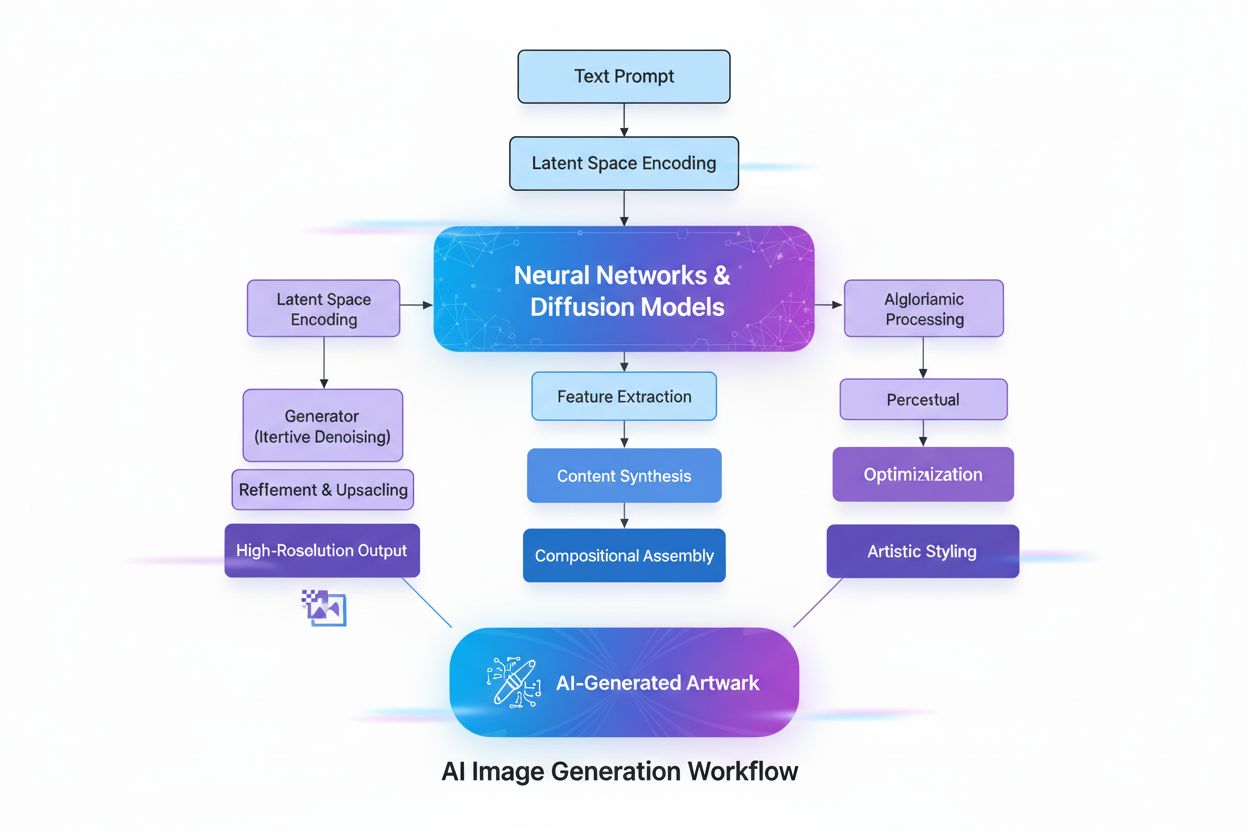
AI生成画像とは、人間のアーティストや写真家ではなく、人工知能アルゴリズムや機械学習モデルによって作成されるデジタル画像です。これらの画像は、ラベル付けされた大量の画像データセットでニューラルネットワークを訓練することで生み出され、AIが視覚的パターンを学習し、テキストプロンプトやスケッチ、その他の入力データから独自でリアルなビジュアルを生成できるようになります。
AI生成画像とは、人間のアーティストや写真家ではなく、人工知能アルゴリズムや機械学習モデルによって作成されるデジタル画像です。これらの画像は、ラベル付けされた大量の画像データセットでニューラルネットワークを訓練することで生み出され、AIが視覚的パターンを学習し、テキストプロンプトやスケッチ、その他の入力データから独自でリアルなビジュアルを生成できるようになります。
AI生成画像とは、人間のアーティストや写真家ではなく、人工知能アルゴリズムや機械学習モデルによって作られるデジタル画像のことです。 これらの画像は、ラベル付きの膨大な画像データセットで訓練された高度なニューラルネットワークによって生成され、AIは視覚的なパターンやスタイル、概念間の関係性を学びます。この技術により、AIシステムは主にテキストプロンプトから、スケッチや参照画像、その他のデータソースからも独自でリアルなビジュアルを生成できます。従来の写真や手作業のアートワークと異なり、AI生成画像は現実ではありえないシナリオや幻想的な世界、抽象的な概念など、想像できるあらゆるものを描写できます。生成プロセスは非常に高速で、数秒で高品質な画像が得られることも多く、クリエイティブ産業やマーケティング、プロダクトデザイン、コンテンツ制作に革命をもたらしています。
AI画像生成の歩みはディープラーニングやニューラルネットワークの基礎研究から始まりましたが、一般に普及したのは2020年代初頭です。2014年にイアン・グッドフェローによって提案された生成的敵対ネットワーク(GANs)は、2つのニューラルネットワークを競わせてリアルな画像を生成する最初の成功例のひとつでした。しかし、真のブレークスルーとなったのは、より安定的で高品質な出力を実現したディフュージョンモデルやトランスフォーマー系アーキテクチャの登場です。2022年にはStable Diffusionがオープンソースモデルとして公開され、AI画像生成へのアクセスが民主化され、一気に普及しました。その直後にはOpenAIのDALL-E 2やMidjourneyが注目を集め、AI画像生成が一般の認知を得ました。最新統計によると、SNS上の画像の71%がAI生成となり、世界のAI画像生成器市場は2023年に2億9920万ドルと評価され、2030年まで年平均17.4%成長が見込まれています。この急成長は、技術の成熟と産業界での広範な導入の両方を反映しています。
AI生成画像の作成には、抽象的な概念を視覚的現実へと変換する複数の高度な技術プロセスが連携しています。まずは自然言語処理(NLP)によるテキスト理解から始まり、AIは人間の言葉を**埋め込み(エンベディング)**と呼ばれる数値表現に変換します。**CLIP(Contrastive Language-Image Pre-training)**のようなモデルは、テキストプロンプトを高次元ベクトルに符号化し、意味や文脈を捉えます。たとえば「木の上にある赤いリンゴ」という入力であれば、NLPモデルが「赤」「リンゴ」「木」やそれらの空間関係を数値座標に分解します。この数値マップが画像生成の指針となり、AIにどの要素を含め、どのように配置するかを指示します。
多くの現代的なAI画像生成器(DALL-E 2やStable Diffusionなど)を支えるディフュージョンモデルは、洗練された反復プロセスで動作します。モデルは純粋なランダムノイズ(無秩序なピクセルの集まり)から始め、複数のノイズ除去ステップを経て徐々に画像を洗練させます。訓練時には、ノイズを画像に付与する過程を逆算することを学び、ノイズまみれの画像を元に戻す「デノイズ」手順を習得します。新しい画像を生成する際は、訓練で学んだデノイズ工程を逆に適用し、ランダムノイズから段階的にまとまった画像へと変換します。この変換の各段階でテキストプロンプトが指針となり、最終的な出力がユーザーの説明と一致するよう導きます。この段階的な洗練により、非常に詳細で高品質な画像を細やかに制御できるのが特徴です。
生成的敵対ネットワーク(GANs)は、ゲーム理論に基づいた全く異なるアプローチです。GANは、ジェネレーター(ランダム入力から偽画像を生成)とディスクリミネーター(本物と偽物を見分ける)という2つのニューラルネットワークで構成されます。これらは対抗的な競争を繰り返し、ジェネレーターはディスクリミネーターを欺く画像生成を目指し、ディスクリミネーターは偽物の発見精度を高めます。この競争により両者は進化し、最終的に本物の写真と区別がつかない画像が生まれます。GANは特に写実的な人物顔やスタイル転写に優れていますが、ディフュージョンモデルより訓練が安定しにくい傾向もあります。
トランスフォーマーモデルは、元々自然言語処理のために開発されたトランスフォーマー技術を画像生成に応用した主要アーキテクチャです。これらのモデルは、複雑なテキストプロンプト内の関係性を読み取り、言語トークンと視覚的特徴を結びつけるのが得意です。自己注意メカニズムにより文脈と関連性を的確に把握し、複雑で情報量の多いプロンプトにも高精度で対応できます。トランスフォーマーは、細かなテキスト説明にきめ細かく合致する画像生成が可能なため、出力特性を厳密に指定したい用途に理想的です。
| 技術 | 仕組み | 強み | 弱み | 主な用途 | 代表的なツール |
|---|---|---|---|---|---|
| ディフュージョンモデル | テキストプロンプトに従い、ランダムノイズを反復的にノイズ除去して構造化画像を生成 | 高品質・高精細な出力、テキストとの高い整合性、安定した訓練、段階的な調整が可能 | 生成に時間と計算資源を要する | テキストから画像生成、高解像度アート、科学可視化 | Stable Diffusion, DALL-E 2, Midjourney |
| GANs | ジェネレーターとディスクリミネーターの2つのニューラルネットが対抗訓練しリアルな画像を生成 | 生成が高速、写実性に優れる、スタイル転写や画像強調に適す | 訓練が不安定化しやすい、モード崩壊、テキスト制御が難しい | 写実的な顔、スタイル転写、画像拡大 | StyleGAN, Progressive GAN, ArtSmart.ai |
| トランスフォーマー | セルフアテンションとトークン埋め込みでテキストプロンプトから画像生成 | 複雑なプロンプトも高度に対応、優れた意味理解、テキストから画像合成に強い | 大きな計算資源が必要、最適化事例が少ない新技術 | 詳細なテキストからクリエイティブ画像、デザイン、広告、コンセプトアート | DALL-E 2, Runway ML, Imagen |
| ニューラルスタイル転写 | 1つの画像の内容ともう1つの画像のアートスタイルを融合 | 芸術的制御ができる、内容を保ちながらスタイル付与、解釈が容易 | スタイル転写専用、参照画像が必要、他技術より柔軟性が低い | 芸術的画像生成、スタイル適用、クリエイティブな強調 | DeepDream, Prisma, Artbreeder |
AI生成画像のビジネス分野での導入は非常に急速かつ変革的です。Eコマースや小売では、商品写真を大量生成し、高額な撮影を不要にしています。最新データによると、小売業幹部の80%が2025年までにAI自動化を導入すると予測し、小売企業は2023年に197億1千万ドルをAIツールに投資、その大きな割合を画像生成が占めます。AI画像編集市場は2025年に887億ドル、2034年には89億ドルと予測され、企業ユーザーが全支出の約**42%**を占めています。
マーケティングと広告分野では、マーケターの62%がAIで新しい画像アセットを作成し、AIでSNSコンテンツを作成する企業はエンゲージメント率が15~25%向上しています。多数のクリエイティブバリエーションを迅速に生成でき、かつ大規模なA/Bテストでデータ駆動型の最適化が可能です。Cosmopolitan誌は2022年6月にDALL-E 2で完全生成した表紙を発行し、大手メディアとして初めてAI生成画像をカバーに採用したことで話題となりました。使用されたプロンプトは「無限の宇宙の中、火星を歩くアスリート体型の女性宇宙飛行士を下から広角で、シンセウェーブ、デジタルアート」です。
医療画像分野でも、AI生成画像は診断や合成データ生成目的で注目されています。研究により、DALL-E 2がテキストプロンプトからリアルなX線画像を生成したり、放射線画像の欠損部分を再構成できることが示されています。これは医療教育やプライバシー保護下でのデータ共有、新たな診断ツール開発を加速させる可能性があります。AI駆動のSNS市場は2021年の21億ドルから2031年には120億ドルへ拡大が見込まれ、デジタルプラットフォーム全体でのコンテンツ生成におけるAI技術の中心的役割を示しています。
AI生成画像の急速な普及は、業界や規制当局がまだ対応しきれていない重大な倫理的・法的課題を提起しています。中でも著作権や知的財産権の問題は最も対立の激しい課題の一つです。大半のAI画像生成器は、ネット上から収集した著作権付きの膨大な画像データで訓練されています。2023年1月にはStability AI、Midjourney、DeviantArtに対して、アーティスト3名が「無断で著作権画像を訓練に使用した」と訴訟を起こしました。これは技術革新とアーティストの権利の対立を象徴する事例です。
AI生成画像の所有権や権利についても法的に明確ではありません。2022年、Midjourneyで作成されたAI作品がコロラド州博覧会の美術コンテストで1位を受賞し、ジェイソン・アレン氏が提出したことをきっかけに大きな論争が巻き起こりました。AIが生成した作品は「人間の創作物」と認められるべきかを巡り議論となっています。米国著作権局は、人間の創造的関与なしにAIのみで作成された作品は著作権保護対象外とする見解を示していますが、これは今なお訴訟や法整備が進行中の分野です。
ディープフェイクや偽情報も重要な懸念事項です。AI画像生成器は、実際には起こっていない出来事のリアルな画像を作成できるため、虚偽情報の拡散を助長します。2023年3月には、Midjourneyで作られた「元大統領トランプ氏が逮捕される」という偽のディープフェイク画像がSNSで広まり、一部のユーザーが本物と信じてしまいました。現代のAI生成画像の精巧さは検知を困難にし、プラットフォームや報道機関にとってコンテンツの信憑性維持が大きな課題となっています。
訓練データのバイアスも重大な倫理課題です。AIモデルは、文化的・ジェンダー的・人種的なバイアスを含むデータセットから学習します。MITメディアラボのジョイ・ブオラミニ主導によるGender Shadesプロジェクトは、商用AI性別判定システムにおける有色人種女性への誤認識率が白人男性より大幅に高いことを明らかにしました。同様のバイアスは画像生成にも現れ、偏見や特定属性の過小表現を助長する恐れがあります。こうしたバイアス対策には、慎重なデータセット選定、多様な訓練データ、モデル出力の継続的評価が不可欠です。
AI生成画像の品質は、入力プロンプトの質と詳細度に大きく左右されます。プロンプトエンジニアリング(効果的なテキスト記述の作成)は、望ましい結果を得るための重要なスキルとなっています。効果的なプロンプトの特徴は、具体的かつ詳細であること、スタイルやメディウムの指定(例:「デジタルペインティング」「水彩画」「フォトリアリスティック」)、雰囲気やライティング情報(例:「ゴールデンアワー」「シネマティックな照明」「ドラマチックな影」)が含まれ、要素間の明確な関係性を示すことです。
例えば「猫」とだけ入力するよりも、「夕日が差し込む窓辺に座るふわふわのオレンジ色のトラ猫、暖かな黄金色の光、写実的、プロの写真風」といった詳細なプロンプトの方が、AIに見た目や状況、照明、雰囲気の具体的な指示を与えられます。階層的に整理されたプロンプトは一貫性と満足度の高い結果をもたらすことが研究で示されています。ユーザーはしばしば、芸術スタイルの指定、形容詞の追加、写真技術用語の記載、特定アーティストや美術運動の参照などのテクニックも活用し、理想の出力へとAIを導きます。
各AI画像生成プラットフォームは、それぞれ異なる特徴・強み・用途を持っています。OpenAIのDALL-E 2は、テキストプロンプトからの詳細な画像生成や高度なインペインティング・編集機能が特徴で、クレジット制での利用(画像生成ごとにクレジット消費)となっています。DALL-E 2は多様かつ複雑なプロンプトにも対応できる汎用性の高さから、プロやクリエイターに人気です。
Midjourneyはアーティスティックでスタイリッシュな画像生成に特化し、独特の美的センスがデザイナーやアーティストに好まれています。プラットフォームはDiscordボット経由で利用し、/imagineコマンドでプロンプトを入力します。Midjourneyは色彩バランスやライティング、シャープなディテールなど、画家風の魅力的な画像生成が得意です。価格は月額10~120ドルのサブスクリプション制で、上位プランほど画像生成上限が増えます。
Stable Diffusionは、Stability AI・EleutherAI・LAIONの協力で開発されたオープンソースモデルで、AI画像生成の民主化を推進しました。オープンソースであるため、開発者や研究者によるカスタマイズや独自展開が可能で、実験プロジェクトや企業導入にも最適です。Stable Diffusionは潜在ディフュージョンモデルを採用し、一般的なグラフィックカードでも効率的な生成ができます。価格は1画像あたり0.0023ドルと手頃で、初回ユーザー向けの無料トライアルもあります。
GoogleのImagenも注目の一角で、かつてない写実性と高い言語理解力を持つテキスト→画像ディフュージョンモデルを提供します。こうした各プラットフォームはAI画像生成分野における多様なアプローチとビジネスモデルを示し、それぞれが異なるニーズや用途に応えています。
AI画像生成分野は急速に進化しており、いくつかの大きなトレンドが今後の技術を形作っています。モデルの進化と効率化は凄まじい速度で進み、新モデルはより高解像度・高精度・高速な生成を実現しています。AI画像生成器市場は2030年まで年平均17.4%成長が見込まれ、投資とイノベーションが継続するでしょう。新たな潮流としては、テキストからの動画生成や3Dモデル生成、リアルタイム画像生成(インタラクティブな創作ワークフロー対応)などが登場しています。
規制枠組みも世界的に整備が始まり、透明性・著作権保護・倫理的利用の基準策定が進行中です。NO FAKES法などの法案は、AI生成コンテンツへの透かし付与やAI利用開示義務を提案しています。**グローバルマーケターの62%**が「AI生成コンテンツへのラベル義務化はSNSのパフォーマンス向上に有益」と考えており、業界内でも透明性の必要性が認識されています。
他のAIシステムとの統合も加速しており、画像生成はより広範なAIプラットフォームやワークフローに組み込まれています。テキスト・画像・音声・動画を統合するマルチモーダルAIシステムも高度化しつつあります。また、パーソナライズやカスタマイズへの対応も進み、特定の芸術スタイルやブランド、個人の趣向にAIモデルを微調整できるようになっています。AI生成画像がデジタルプラットフォームでますます普及する中、ブランド監視や引用追跡の重要性も高まり、AI生成コンテンツでのブランド可視性と権威性維持を目指す企業にとって、これらの追跡ツールが不可欠になりつつあります。
AI生成画像は、テキストプロンプトやその他の入力から機械学習アルゴリズムによって完全に作成されるのに対し、従来の写真撮影はカメラのレンズを通して現実世界の光景を捉えます。AI画像は、現実では不可能なシナリオなど、想像できるあらゆるものを描写できますが、写真撮影は存在するものや物理的に演出できるものに限られます。AI生成は通常、写真撮影よりも迅速かつ低コストで実現できるため、迅速なコンテンツ制作やプロトタイピングに最適です。
ディフュージョンモデルは、純粋なランダムノイズから始め、繰り返しノイズ除去を行うことで徐々に画像を洗練させます。テキストプロンプトは数値的な埋め込み(エンベディング)に変換され、このノイズ除去プロセスの指針となります。こうしてノイズが段階的に説明に合致したまとまりある画像へと変換されていきます。この段階的なアプローチにより、入力テキストに正確に合わせた高品質かつ詳細な出力が可能となります。
主な技術は3つあり、対抗するニューラルネットワーク同士でリアルな画像を生成する「生成的敵対ネットワーク(GANs)」、ランダムノイズから段階的にノイズを除去して構造化された画像を作る「ディフュージョンモデル」、自己注意メカニズムでテキストプロンプトを画像に変換する「トランスフォーマー」です。それぞれのアーキテクチャには特徴があり、GANは写実性に優れ、ディフュージョンモデルは高精細な出力、トランスフォーマーは複雑なテキストから画像合成が得意です。
AI生成画像の著作権所有権は法的に曖昧であり、管轄によって異なります。多くの場合、プロンプト作成者やAIモデル開発者、あるいはAIが自律的に生成した場合は誰にも帰属しない可能性もあります。米国著作権局は、人間の創造的関与なしにAIのみで作られた作品は著作権保護の対象外とする見解を示していますが、これは現在も訴訟や規制の進展により変化し続ける法的領域です。
AI生成画像は、Eコマースの商品写真、マーケティングキャンペーンやSNS用のビジュアル作成、ゲーム開発におけるキャラクター・アセット制作、医療画像の診断補助や広告における迅速なコンセプトテストなどで広く活用されています。最新のデータによると、マーケターの62%がAIで新しい画像アセットを作成しており、AI画像編集市場は2025年に887億ドルと評価され、業界全体での大規模導入が進んでいます。
現在のAI画像生成器は、特に人間の手や顔の解剖学的正確な描写が苦手で、不自然な特徴(指が多い、顔の左右非対称など)を生成することがあります。また、訓練データの質に大きく依存するため、バイアスが入りやすく多様性が制限されることもあります。さらに、細部の指定には綿密なプロンプト設計が必要で、時に自然な外観や繊細な創造意図を十分に表現できない場合があります。
大半のAI画像生成器は、インターネット上から収集した膨大な画像データセットを訓練に使用しており、多くが著作権作品です。このため、Stability AIやMidjourneyといった企業が許可や補償なしに著作権画像を利用したとしてアーティストから訴訟を起こされています。Getty ImagesやShutterstockのように、未解決の著作権問題を理由にAI生成画像の投稿を禁止するプラットフォームもあり、データの透明性や公正な報酬に関する規制枠組みが構築途上です。
世界のAI画像生成器市場は2023年に2億9920万ドルと評価され、2030年までに年平均17.4%で成長すると予測されています。より広いAI画像編集市場は2025年に887億ドル、2034年には89億ドルに達すると見込まれています。さらに、SNS上の画像の71%がAI生成となっており、AI駆動のSNS市場は2031年に120億ドルに拡大すると予測されるなど、爆発的な成長と普及が進んでいます。
ChatGPT、Perplexity、その他のプラットフォームでAIチャットボットがブランドを言及する方法を追跡します。AI存在感を向上させるための実用的なインサイトを取得します。
生成AIはニューラルネットワークでトレーニングデータから新しいコンテンツを創出します。仕組みやChatGPT・DALL-Eでの応用、ブランドのAI可視性監視がなぜ重要かを解説。...
AIコンテンツ生成とは何か、どのように機能するか、その利点と課題、AIプラットフォームの可視性に最適化されたマーケティングコンテンツを作成するためのAIツールのベストプラクティスを学びましょう。...
AI Overview(AIO)とは何か、SEOやオーガニックトラフィックへの影響、そしてGoogleのAI生成検索要約で可視性を高めるための最適化戦略を学びましょう。...
クッキーの同意
閲覧体験を向上させ、トラフィックを分析するためにクッキーを使用します。 See our privacy policy.