
リッチリザルトとは?AIに役立つのか?
リッチリザルトや構造化データがAI検索エンジン、LLM、ChatGPT・Perplexity・Google AI OverviewsなどAIによる回答でのコンテンツ可視性にどのように影響するか解説します。...
1 分で読める

AIリトリーバルスコアリングは、ユーザーのクエリに対して取得された文書やパッセージの関連性と品質を定量化するプロセスです。高度なアルゴリズムを用いて、意味的な意味、文脈の妥当性、情報の質を評価し、RAGシステムで回答生成のために言語モデルに渡すべきソースを決定します。
AIリトリーバルスコアリングは、ユーザーのクエリに対して取得された文書やパッセージの関連性と品質を定量化するプロセスです。高度なアルゴリズムを用いて、意味的な意味、文脈の妥当性、情報の質を評価し、RAGシステムで回答生成のために言語モデルに渡すべきソースを決定します。
AIリトリーバルスコアリングは、ユーザーのクエリやタスクに対して取得された文書やパッセージの関連性と品質を定量化するプロセスです。単純なキーワード一致のような表面的な単語の重複を検出する方法とは異なり、リトリーバルスコアリングは意味的な意味、文脈の妥当性、情報の質を評価する高度なアルゴリズムを使用します。このスコアリング機構はリトリーバル・オーグメンテッド・ジェネレーション(RAG)システムの根幹であり、どのソースが言語モデルに渡されて回答生成に使われるかを決定します。現代のLLMアプリケーションでは、リトリーバルスコアリングは回答の正確性や幻覚(ハルシネーション)の低減、ユーザー満足度に直結しており、最も関連性の高い情報だけが生成段階に到達することを保証します。したがって、リトリーバルスコアリングの品質はシステム全体の性能や信頼性の重要な要素です。
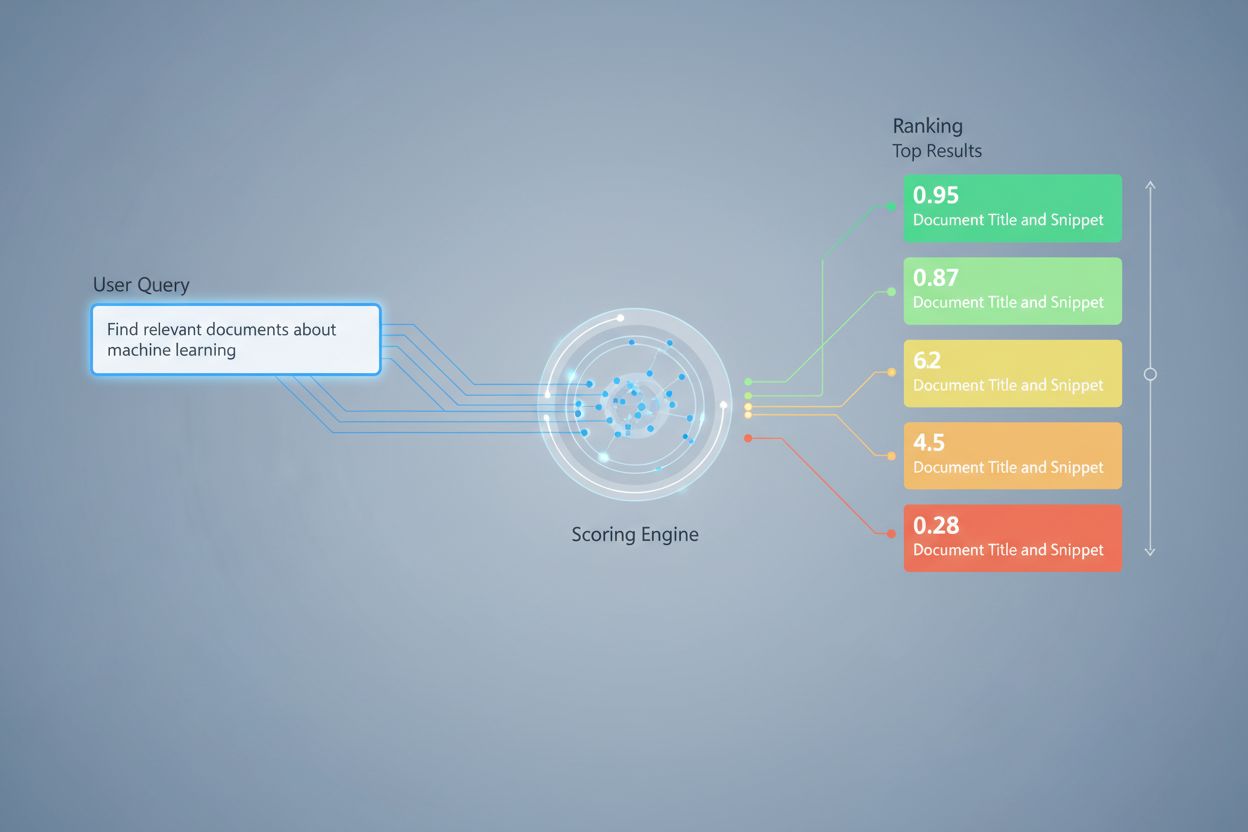
リトリーバルスコアリングは複数のアルゴリズム的アプローチを用い、用途ごとに異なる強みを持ちます。意味的類似度スコアリングは、埋め込みモデルを用いてクエリと文書の概念的一致をベクトル空間で測定し、表面的なキーワードを超えた意味を捉えます。BM25(Best Matching 25)は確率的ランキング関数で、単語頻度や逆文書頻度、文書長正規化を考慮し、従来型テキスト検索に非常に効果的です。TF-IDF(Term Frequency-Inverse Document Frequency)は、単語の文書内とコレクション全体での重要度に基づき重み付けを行いますが、意味理解には乏しいです。ハイブリッドアプローチは、BM25と意味的スコアを組み合わせるなど、複数手法を統合して語彙的・意味的シグナルの両方を活用します。スコアリング手法以外にも、Precision@k(上位k件のうち関連する結果の割合)、Recall@k(上位k件で見つかった関連文書の割合)、NDCG(順位に基づく正規化割引累積利得)、MRR(平均逆順位)などがリトリーバル品質の定量評価指標となります。BM25の効率性と意味的スコアリングの深い理解など、各手法の強みと弱みを理解することが、用途に合った適切な選択に不可欠です。
| スコアリング手法 | 仕組み | 適した用途 | 主な利点 |
|---|---|---|---|
| 意味的類似度 | コサイン類似度などで埋め込みを比較 | 概念的意味、同義語、言い換え | キーワードを超えた意味関係を捉える |
| BM25 | 単語頻度や文書長を考慮した確率的ランキング | 正確なフレーズ一致、キーワード検索 | 高速・効率的・実運用実績あり |
| TF-IDF | 文書内頻度とコレクション希少性で単語を重み付け | 従来の情報検索 | シンプル・解釈しやすい・軽量 |
| ハイブリッドスコアリング | 意味的・キーワード両手法を重み付けで融合 | 汎用リトリーバル、複雑なクエリ | 複数手法の強みを活用 |
| LLMベーススコアリング | カスタムプロンプトで言語モデルが関連性を判定 | 複雑な文脈評価、専門的タスク | 微妙な意味関係も捉える |
RAGシステムでは、リトリーバルスコアリングが複数のレベルで動作し、生成品質を担保します。システムは一般に文書内のチャンクやパッセージごとに個別にスコア付けを行い、文書全体を一つの単位として扱うのではなく、きめ細やかな関連性評価を可能にします。このチャンク単位の関連性スコアリングにより、最も重要な情報部分のみを抽出でき、ノイズや無関係な文脈が言語モデルの混乱要因になることを減らします。また、RAGシステムはスコア閾値やカットオフ機構を実装し、低スコアの結果を生成段階に到達する前に排除することで、低品質ソースが最終回答に影響するのを防ぎます。取得した文脈の品質は生成品質と直結しており、高スコアの関連パッセージはより正確で根拠ある回答を生み出し、低品質なリトリーバルは幻覚や事実誤認を招きます。リトリーバルスコアのモニタリングはシステム劣化の早期警告指標となり、AI回答監視や品質保証の重要なメトリクスです。
リランキングは、初期リトリーバル結果をさらに洗練する第二段階のフィルタリング機構であり、ランキング精度を大幅に向上させることができます。初期リトリーバルで候補結果と一次スコアが生成された後、リランカーがより高度なスコアリングロジックでこれらを再評価・並べ替えします。リランカーは計算負荷の高いモデルを使って、より深い分析を行えるのが特徴です。**Reciprocal Rank Fusion(RRF)**は、複数リトリーバル手法のランキングを位置に基づいてスコア化し、それらを融合することで個別リトリーバルを上回る統合ランキングを実現する人気手法です。スコアの正規化は異なるリトリーバル手法の生スコア(BM25、意味的類似度等)が異なるスケールで出るため、統一した範囲にキャリブレーションする際に重要です。アンサンブルリトリーバル手法は複数のリトリーバル戦略を同時利用し、リランキングで統合証拠に基づく最終順位を決定します。この多段階アプローチは、単一段階リトリーバルと比べてランキング精度と堅牢性を大きく向上させ、特に複雑な領域で相補的な関連性シグナルを捉えます。
Precision@k:上位k件の中に含まれる関連文書の割合を測定。取得結果が信頼できるかの評価に有用(例:Precision@5 = 4/5なら上位5件のうち80%が関連)
Recall@k:上位k件で見つかった全関連文書の割合。関連情報の網羅性を担保する指標
Hit Rate:上位k件内に少なくとも1件関連文書があるかを示すバイナリ指標。実運用での即時品質チェックに有用
NDCG(Normalized Discounted Cumulative Gain):関連文書が早く出現するほど高評価となる順位考慮型指標。0〜1の範囲でランキング品質評価に最適
MRR(Mean Reciprocal Rank):最初の関連文書の平均順位(逆数)を測定。最も関連性の高い文書が上位に来ているかの評価に適す
F1スコア:PrecisionとRecallの調和平均。偽陽性・偽陰性が同等に重要な場合のバランス評価に有効
MAP(Mean Average Precision):関連文書が出現した各位置でのPrecisionの平均。複数クエリにまたがる総合ランキング品質指標
LLMベースの関連性スコアリングは、言語モデル自体を関連性判定者として活用し、従来アルゴリズムとは異なる柔軟なアプローチを提供します。このパラダイムでは、精巧に設計されたプロンプトによりLLMに取得パッセージがクエリに答えているかを評価させ、**バイナリ(関連/非関連)または数値(例:1〜5段階)**でスコアを出力させます。この方法は、従来アルゴリズムが見落としがちな微妙な意味関係やドメイン固有の関連性も捉えることができ、特に深い理解を要する複雑なクエリで有用です。ただし、LLMベーススコアリングは計算コスト(埋め込み類似度と比べLLM推論は高価)、プロンプトやモデルによる一貫性の課題、人手ラベルによるキャリブレーションの必要性などの課題も伴います。それでも、RAGシステムの品質評価や専門的スコアリングモデルの学習データ作成に有効であり、AI回答品質評価の重要なツールとなっています。
効果的なリトリーバルスコアリングの実装には、複数の実践的な要素の検討が必要です。手法選択は用途要件に依存し、意味的スコアリングは意味把握に優れる一方、BM25は語彙一致で速度・効率に優れます。速度と精度のトレードオフも重要です。埋め込みベーススコアリングは高い関連性理解を提供しますが遅延コストが発生し、BM25やTF-IDFは高速ですが意味的洗練度が劣ります。計算コストとしてはモデル推論時間・メモリ要求・インフラ拡張性などがあり、大規模運用では特に重要です。パラメータ調整では、閾値設定やハイブリッド手法での重み、リランキングカットオフなど、用途やドメインに最適化する必要があります。NDCGやPrecision@kなどでスコアリング性能を継続監視し、劣化を早期検知して能動的なシステム改善を行うことで、運用中のRAGシステムで一貫した回答品質を担保できます。
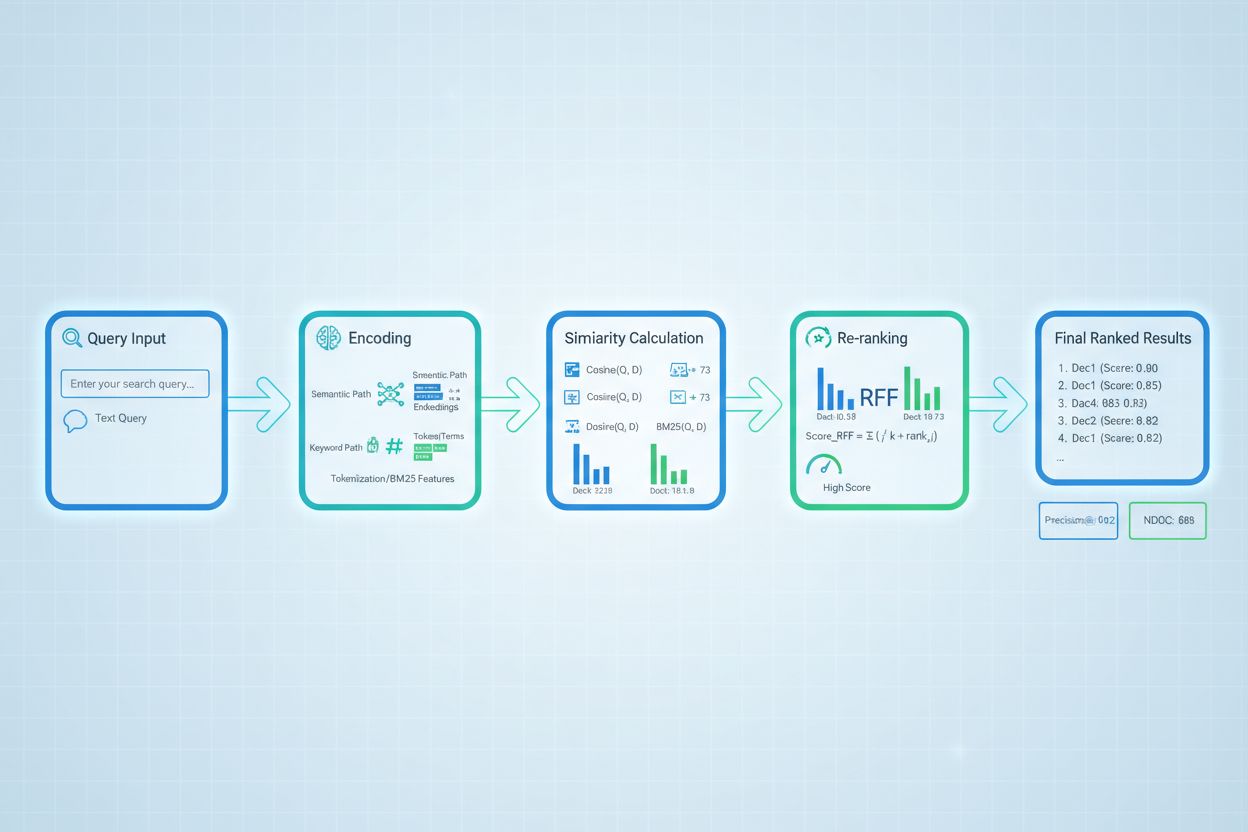
高度なリトリーバルスコアリング手法は、基本的な関連性評価を超えて複雑な文脈関係を捉えます。クエリリライティングは、ユーザーのクエリを複数の意味的に等価な形に再構成することで、単純な一致では見逃されがちな関連文書を見つけやすくします。**仮想文書埋め込み(HyDE)**は、クエリから合成的な関連文書を生成し、それを理想的な関連性の基準として実際の文書検索を改善します。マルチクエリアプローチは、複数のクエリバリエーションをリトリーバルに投入し、スコアを集約することで単一クエリよりも堅牢性と網羅性を高めます。ドメイン特化型スコアリングモデルは、特定業界や知識ドメインのラベルデータで訓練されることで、汎用モデルより優れた性能を発揮し、医療や法律AIのような専門用途で価値を発揮します。文脈的スコア調整は、文書の新しさやソースの権威性、ユーザー状況なども考慮し、純粋な意味的類似度を超えて実世界での関連性要素を取り入れた高度な評価を可能にします。
リトリーバルスコアリングは、クエリとの関係に基づいて文書に数値的な関連性値を割り当てるのに対し、ランキングはこれらのスコアに基づいて文書を並べ替えることです。スコアリングは評価プロセスであり、ランキングはその結果の並べ替えです。どちらもRAGシステムが正確な回答を提供するために不可欠です。
リトリーバルスコアリングは、どのソースが回答生成のために言語モデルに到達するかを決定します。高品質なスコアリングは関連性の高い情報が選択されることを保証し、幻覚(ハルシネーション)を減らし、回答の正確性を向上させます。低品質なスコアリングは無関係な文脈や信頼できないAI応答につながります。
意味的スコアリングは埋め込み(エンベディング)を使って概念的な意味を理解し、同義語や関連概念を捉えます。キーワードベースのスコアリング(BM25など)は、正確な用語やフレーズの一致を重視します。意味的スコアリングは意図の理解に優れ、キーワードスコアリングは特定情報の発見に優れています。
主な指標にはPrecision@k(上位結果の正確性)、Recall@k(関連文書の網羅率)、NDCG(ランキング品質)、MRR(最初の関連文書の位置)などがあります。用途に応じて選択してください:高品質重視ならPrecision@k、網羅性重視ならRecall@kが適しています。
はい、LLMベースのスコアリングは言語モデルを判定者として関連性を評価します。この方法は微妙な意味的関係も捉えますが、計算コストが高くなります。RAG品質の評価やトレーニングデータ作成に有用ですが、人間のラベルによる調整が必要です。
リランキングは、より高度なモデルを使って初期結果を再評価し、精度を高めます。Reciprocal Rank Fusionのような手法は複数のリトリーバル方法を組み合わせ、精度と堅牢性を向上させます。複雑な領域で単一段階のリトリーバルより大きな効果があります。
BM25やTF-IDFは高速かつ軽量でリアルタイムシステム向きです。意味的スコアリングはエンベディングモデル推論が必要なため遅延が増します。LLMベースのスコアリングが最も高コストです。レイテンシ要件や利用可能な計算資源に応じて選択しましょう。
重視する点に応じて選びましょう:意味重視なら意味的スコアリング、速度や効率重視ならBM25、バランス重視ならハイブリッドアプローチ。NDCGやPrecision@kなどの指標で自分のドメインで評価し、複数手法をテストして最終回答品質への影響を測定しましょう。
ChatGPT、Perplexity、Google AIなどのAIシステムがあなたのブランドをどのように参照し、ソース取得やランク付けの品質を評価しているかを追跡しましょう。あなたのコンテンツがAIシステムによって正しく引用・ランク付けされているか確認できます。
リッチリザルトや構造化データがAI検索エンジン、LLM、ChatGPT・Perplexity・Google AI OverviewsなどAIによる回答でのコンテンツ可視性にどのように影響するか解説します。...
リスティクル最適化とは何か、AI抽出のための番号付き・箇条書きリストの構造化方法を学びましょう。AI検索での可視性と引用を高めるベストプラクティスを紹介します。...
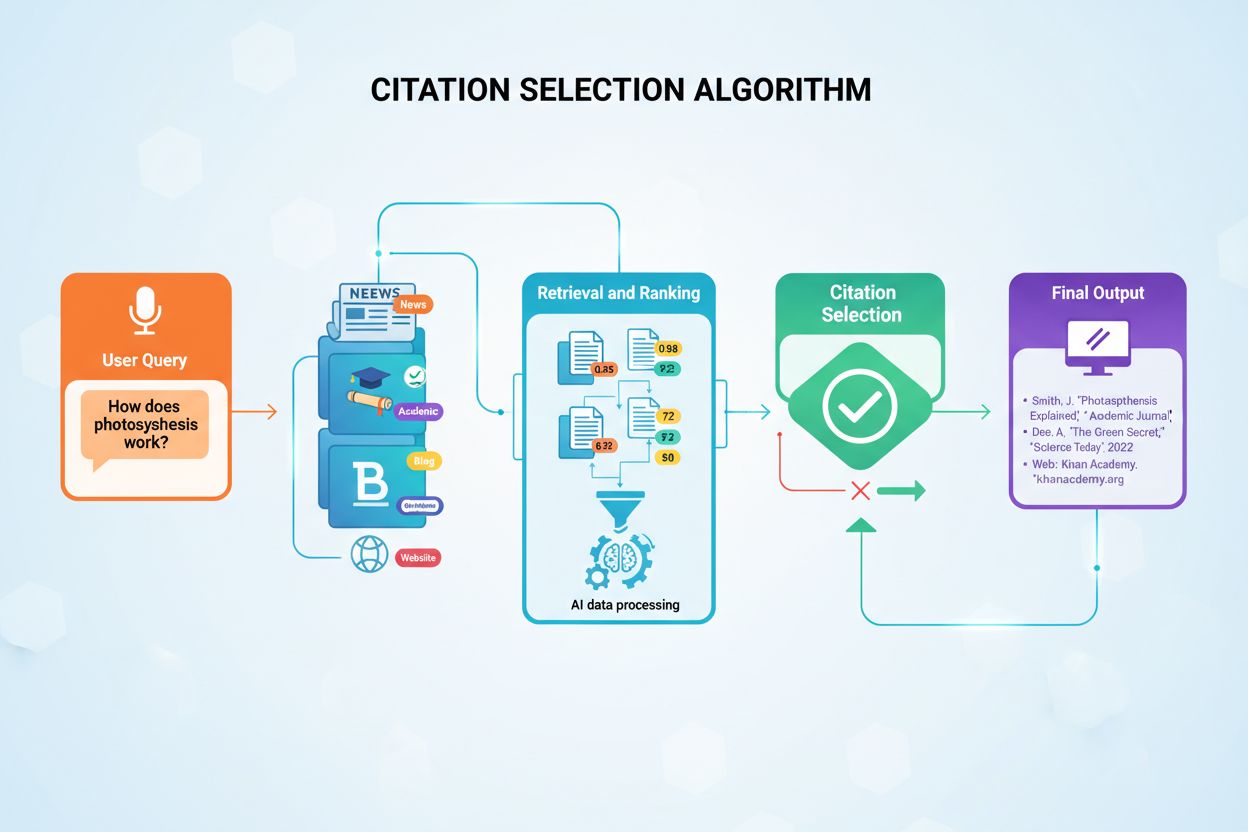
AIシステムがどの情報源を引用し、どれを要約・言い換えるかを選ぶ仕組みを解説。引用選択アルゴリズム、バイアスパターン、AI生成応答におけるコンテンツ可視性向上の戦略を理解しよう。...