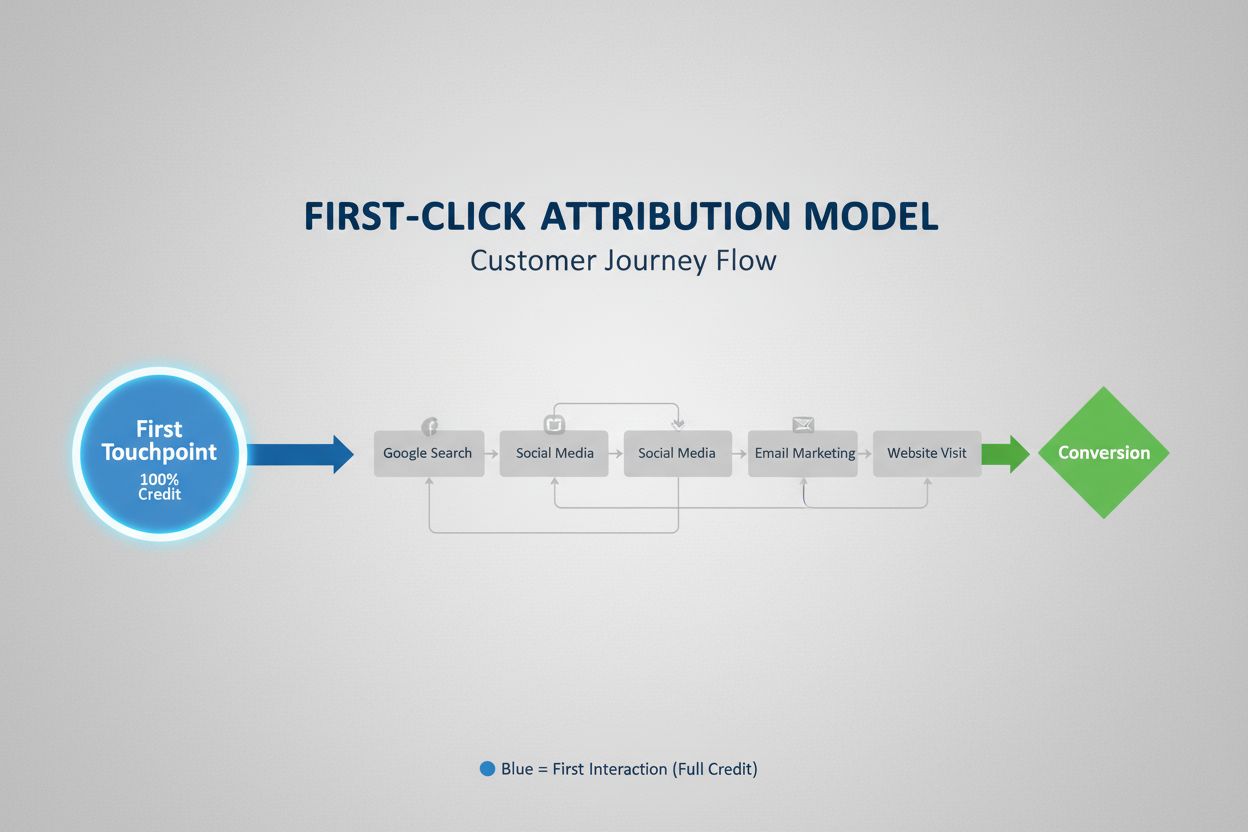
ファーストクリックアトリビューション
ファーストクリックアトリビューションは、コンバージョンクレジットの全てをファーストタッチポイントに割り当てます。このモデルの仕組みや活用方法、マーケティング測定やAIモニタリングへの影響について解説します。...
1 分で読める
アテンションメカニズムは、ニューラルネットワークの構成要素であり、異なる入力要素の重要度を動的に重み付けすることで、モデルが予測時に最も関連性の高いデータ部分に集中できるようにします。クエリ、キー、バリューの学習済み変換を通じてアテンション重みを計算し、深層学習モデルがシーケンシャルデータ内の長距離依存性やコンテキスト依存の関係性を捉えることを可能にします。
アテンションメカニズムは、ニューラルネットワークの構成要素であり、異なる入力要素の重要度を動的に重み付けすることで、モデルが予測時に最も関連性の高いデータ部分に集中できるようにします。クエリ、キー、バリューの学習済み変換を通じてアテンション重みを計算し、深層学習モデルがシーケンシャルデータ内の長距離依存性やコンテキスト依存の関係性を捉えることを可能にします。
アテンションメカニズムとは、ディープラーニングモデルが予測時に入力データの最も関連性の高い部分を優先的に(「注目して」)処理するよう指示する機械学習手法です。全ての入力要素を同等に扱うのではなく、アテンションメカニズムは各要素の重要度を表すアテンション重みを計算し、その重みに基づいて特定の入力を動的に強調または抑制します。この根本的な革新は、現代のトランスフォーマーアーキテクチャや大規模言語モデル(LLM)(ChatGPT、Claude、Perplexityなど)の基盤となり、シーケンシャルデータをこれまでにない効率と精度で処理できるようになりました。このメカニズムは人間の認知的注意――重要な情報に選択的に集中し、無関係な情報を除外する能力――に着想を得ており、この生物学的原理を数学的に厳密かつ学習可能なニューラルネットワークの構成要素として応用しています。
アテンションメカニズムの概念は、2014年にBahdanauらが機械翻訳で使用されるリカレントニューラルネットワーク(RNN)の重要な限界を克服するために最初に提案しました。アテンション導入以前、Seq2Seqモデルはソース文全体を1つのコンテキストベクトルにエンコードしていたため、長いシーケンスで情報のボトルネックが生じ、性能が大きく制限されていました。元祖アテンションメカニズムは、デコーダがエンコーダの全隠れ状態にアクセスできるようにし、各デコードステップで最も関連する入力部分を動的に選択できるようにしました。このブレイクスルーにより、特に長文の翻訳品質が劇的に向上しました。2015年にはLuongらがドット積アテンションを導入し、計算コストの高い加法型アテンションを効率的な行列積に置き換えました。転機となったのは2017年、「Attention is All You Need」の発表で、トランスフォーマーアーキテクチャが完全にアテンションメカニズム主体となり、再帰を排除しました。この論文は深層学習に革命を起こし、BERTやGPTシリーズなど現代の生成AIのエコシステムを生み出しました。今日ではアテンションメカニズムは自然言語処理、コンピュータビジョン、マルチモーダルAIシステム全般で広く利用され、最先端モデルの85%以上が何らかのアテンション型アーキテクチャを採用しています。
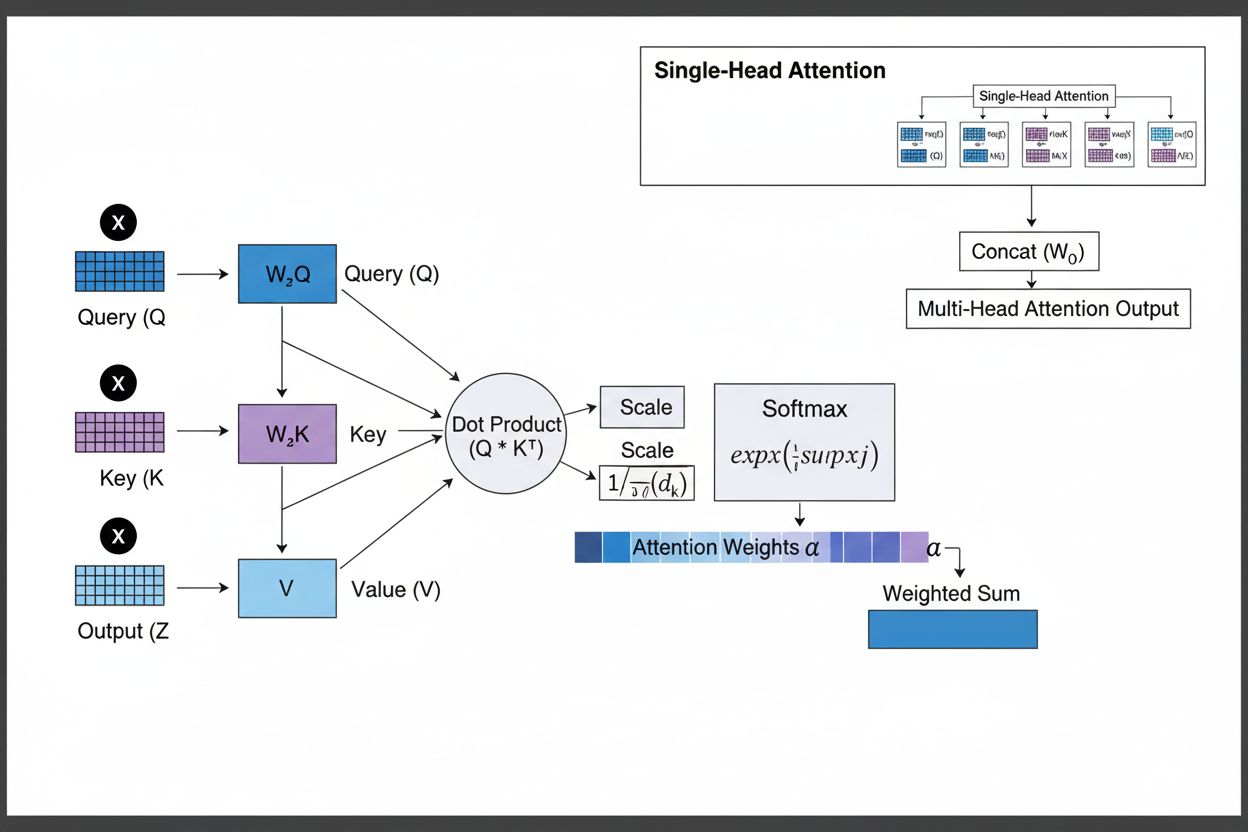
アテンションメカニズムは、クエリ(Q)、キー(K)、バリュー(V)という3つの基本的な数学的成分の精緻な相互作用によって機能します。各入力要素は学習済みの線形射影を通じてこれら3つの表現に変換され、キーが識別子、バリューが実際の情報を持つデータベース的構造となります。類似度の計算には主にスケールドドット積アテンションが用いられ、QK^T/√d_kの形でアライメントスコアを出します。これらの生スコアはソフトマックス関数で正規化され、全ての重みが1となる確率分布に変換されます(各要素の重みが0~1の範囲に収まる)。最終的にこれらのアテンション重みでバリューベクトルの重み付き和を計算し、入力シーケンス全体から最も関連性の高い情報を表すコンテキストベクトルが得られます。このベクトルは元の入力と残差接続で結合され、フィードフォワード層を通してモデルが入力理解を反復的に洗練させます。学習可能な変換、類似度計算、確率的重み付けの組み合わせによるこの数学的な優雅さが、アテンションメカニズムに複雑な依存関係の捕捉と勾配最適化の両立をもたらしています。
| アテンションタイプ | 計算方法 | 計算量 | 最適適用例 | 主な利点 |
|---|---|---|---|---|
| 加法型アテンション | フィードフォワード+tanh活性化 | O(n·d)/クエリ | 短いシーケンス、可変次元 | クエリ・キーの次元が異なっても対応可 |
| ドット積アテンション | 単純な行列積 | O(n·d)/クエリ | 標準的シーケンス | 計算効率が高い |
| スケールドドット積 | QK^T/√d_k+ソフトマックス | O(n·d)/クエリ | 現代のトランスフォーマー | 勾配消失を防ぐ |
| マルチヘッドアテンション | 複数並列ヘッド | O(h·n·d)(hはヘッド数) | 複雑な関係性 | 多様な意味的側面を同時抽出 |
| セルフアテンション | クエリ・キー・バリューが同一シーケンス | O(n²·d) | シーケンス内関係性 | 並列処理が可能 |
| クロスアテンション | クエリとキー・バリューが異なるシーケンス | O(n·m·d) | エンコーダ・デコーダ、マルチモーダル | 異種モダリティの整合 |
| グループ化クエリアテンション | クエリヘッド間でキー・バリューを共有 | O(n·d) | 高速推論 | メモリ・計算量削減 |
| スパースアテンション | 局所・ストライド位置のみ注目 | O(n·√n·d) | 超長シーケンス | 極めて長いシーケンス対応 |
アテンションメカニズムは、ニューラルネットワークが関連情報に動的に集中できるよう、厳密に設計された数式変換の連鎖で動作します。入力シーケンスの各要素はまず高次元ベクトル空間に埋め込まれ、意味・構文情報を持ちます。これらの埋め込みは学習済み重み行列で3つの空間――クエリ空間(求める情報)、キー空間(各要素の持つ情報)、バリュー空間(集約対象データ)――に投影されます。各クエリ位置ごとに全キーとの類似度スコア(ドット積)が計算され、生のアライメントスコアのベクトルが得られます。これらはキー次元の平方根(√d_k)でスケーリングされ、大次元時のドット積過大化による勾配消失を防ぎます。スケーリング後、ソフトマックス関数で各スコアが指数化・正規化され、全入力位置に対する確率分布となります。最後にこのアテンション重みでバリューベクトルの重み付き平均を計算し、重みが高い位置ほど最終的なコンテキストベクトルへの寄与が大きくなります。このコンテキストベクトルは残差接続で元入力と結合され、フィードフォワード層で再度処理されます。全プロセスは微分可能であり、学習時に最適なアテンションパターンが勾配降下法で得られます。
アテンションメカニズムはトランスフォーマーアーキテクチャの根幹を成し、現在の深層学習の主流となっています。RNNが逐次処理、CNNが固定窓処理なのに対し、トランスフォーマーはセルフアテンションで全位置が互いに直接注目でき、GPU・TPUでの大規模並列化を可能にしています。アーキテクチャはマルチヘッドセルフアテンション層とフィードフォワード層を交互に積み重ね、各アテンション層で異なる側面に選択的に集中し理解を深めます。マルチヘッドアテンションは複数のアテンション機構を並列実行し、あるヘッドは文法依存、別のヘッドは意味的関係、さらに別のヘッドは長距離コアリファレンスに特化します。全ヘッドの出力を連結・射影することで、複数の言語現象を同時に把握します。GPT-4、Claude 3、Geminiなどの大規模言語モデルは、各トークンが過去のトークンのみを参照できる(因果マスキング)デコーダ専用トランスフォーマーを使用し、自己回帰生成特性を維持します。アテンションメカニズムはRNNで問題だった勾配消失なしに長距離依存性を捉え、10万トークン超の文脈ウィンドウでも一貫性を維持できます。最新NLPモデルの約92%がアテンション駆動型トランスフォーマーを採用しており、現代AIシステムに不可欠な基盤であることが示されています。
ChatGPT、Perplexity、Claude、Google AI OverviewsなどAI検索プラットフォームにおいて、アテンションメカニズムは取得文書やナレッジベースのどの部分がユーザークエリに最も関連するかを決定する上で重要な役割を果たします。これらのシステムが応答を生成する際、アテンションメカニズムは複数ソースや記述の中から関連性に応じて重み付けを動的に変化させ、複数ソースから一貫性ある回答を合成しつつ事実性を維持します。生成時のアテンション重みを分析することで、モデルがどの情報に重点を置いたかを理解でき、AIシステムがクエリをどう解釈し応答したかの洞察が得られます。ブランドモニタリングや**GEO(Generative Engine Optimization)**の観点では、アテンションメカニズムの理解が不可欠です。なぜなら、どのコンテンツやソースがAI応答内で強調されるかを決定しているためです。エンティティ定義の明確化、権威ある出典、文脈的関連性を意識して構成されたコンテンツは、アテンション重みが高くなり、AI応答で引用・強調されやすくなります。AmICitedは、アテンションメカニズムの洞察を活用して、ブランドやドメインがAIプラットフォーム上でどのように現れているかを追跡し、アテンション重み付きの引用がAI生成コンテンツで最も影響力のある言及であることを認識しています。企業がAI応答での自社の存在感を監視する時代において、アテンションメカニズムが引用パターンを左右することを理解することは、コンテンツ戦略最適化やブランド可視性維持のために極めて重要です。
アテンションメカニズムの分野は急速に進化を続けており、研究者は計算上の制約や性能向上に対応するため、より高度なバリエーションを開発しています。スパースアテンションパターンは、局所近傍やストライド位置のみに注目範囲を限定し、O(n²)からO(n·√n)への複雑度削減と超長シーケンスへの対応を両立します。FlashAttentionのような効率的アテンションは、アテンション計算時のメモリアクセスパターンを最適化し、GPU活用で2~4倍の高速化を実現します。グループ化クエリアテンションやマルチクエリアテンションはキー・バリューヘッド数を削減しつつ性能を維持し、大規模モデルの推論時メモリ要件を大幅に軽減します。Mixture of Experts構造はアテンションとスパースルーティングを組み合わせ、パラメータ数を兆単位に拡張しながら計算効率を維持します。入力特性に応じて動的に適応する学習型アテンションパターンや、複数階層で機能する階層アテンションの研究も進行中です。RAG(検索拡張生成)との統合によって、外部知識に動的に注目し事実性や幻覚低減が進みます。また、説明性機能を強化してモデル意思決定の透明性を高める動きも活発です。今後は、アテンションと状態空間モデル(例:Mamba)などの新規機構を組み合わせて線形計算量と高性能を両立するハイブリッドアーキテクチャが主流となる可能性があります。次世代AIシステムの構築やAI生成コンテンツでの存在感監視において、進化するアテンションメカニズムの理解は不可欠です。なぜなら、引用パターンやコンテンツの際立ち方を決定する仕組み自体が今後も進化し続けるためです。
AmICitedを活用してAI応答内のブランド露出を監視する組織にとって、アテンションメカニズムの理解は引用パターンの解釈に重要な文脈を与えます。ChatGPT、Claude、Perplexityが応答中に自社ドメインを引用する際、その生成過程で計算されたアテンション重みが自社コンテンツをユーザークエリに最も関連すると判断した結果です。エンティティが明確で権威ある情報を提供する高品質なコンテンツは、自然と高いアテンション重みを受け、引用されやすくなります。AIプラットフォームによってはアテンション可視化機能があり、応答生成時にどのソースが最も注目されたかが分かります。これは、アテンションメカニズムが明快さ、関連性、信頼性を持つコンテンツを評価することを示しており、企業がコンテンツ戦略を最適化する際の指針となります。AI検索の普及が進み、企業の60%以上が生成AIへの投資を進める今、アテンションメカニズムへの最適化理解は、ブランド可視性や正確な表現維持のためにますます重要となっています。アテンションメカニズムとブランドモニタリングの交差点はGEOの最前線であり、AIシステムが情報を重み付け・引用する数理的基盤の理解が、生成AIエコシステムでの影響力と可視性の向上に直結します。
従来のRNNはシーケンスを逐次処理するため長距離依存性を捉えるのが難しく、CNNは固定された局所受容野により遠く離れた関係性のモデリングが制限されます。アテンションメカニズムは全ての入力位置間の関係性を同時に計算できるため、並列処理が可能となり、距離に関係なく依存関係を捉えることができます。この時間的・空間的な柔軟性が、複雑なシーケンシャルデータや空間データに対してアテンションメカニズムを非常に効率的かつ効果的なものにしています。
クエリはモデルが現在求めている情報を表し、キーは各入力要素が持つ情報内容を、バリューは集約される実際のデータを示します。モデルはクエリとキー間の類似度スコアを計算し、どのバリューに最も重みを付けるべきかを決定します。このデータベースに着想を得た用語は、『Attention is All You Need』論文で広まり、アテンションメカニズムが入力シーケンスから関連情報を選択的に取得・統合する仕組みを理解するための直感的な枠組みを提供します。
セルフアテンションは1つの入力シーケンス内で、クエリ・キー・バリュー全てが同じソースから生成され、異なる要素間の関係性をモデルが理解できるようにします。対してクロスアテンションは、クエリをあるシーケンスから、キーとバリューを別のシーケンスから取得することで、複数ソース間の情報を結び付け統合できます。クロスアテンションは機械翻訳のようなエンコーダ・デコーダ構造や、Stable Diffusionのようなテキストと画像を組み合わせるマルチモーダルモデルで不可欠です。
スケールドドット積アテンションは、加法ではなく乗算を用いることで、GPUの並列計算が可能な行列演算により計算効率が大幅に向上します。キーの次元数が大きい場合にドット積が過度に大きくなり勾配消失を引き起こすのを防ぐため、1/√dkというスケーリング係数を用います。次元が非常に大きい場合は加法型アテンションが優れることもありますが、スケールドドット積アテンションは計算効率と実用性能が高いため、現代のトランスフォーマーアーキテクチャで標準となっています。
マルチヘッドアテンションは複数のアテンションメカニズムを並列に実行し、それぞれのヘッドが文法関係、意味的特徴、長距離依存性など異なる側面に着目して学習します。各ヘッドは入力の異なる線形射影上で動作し、様々なタイプの関係性を同時に捉えることができます。全てのヘッドの出力を連結・射影することで、複数の言語的・コンテキスト的特徴を網羅的に把握でき、表現力や下流タスク性能が大幅に向上します。
ソフトマックスはクエリとキー間で計算された生のスコアを、合計が1となる確率分布に正規化します。これによりアテンション重みを重要度スコアとして解釈でき、値が大きいほど高い関連性を示します。ソフトマックスは微分可能であり、学習時に勾配に基づく最適化を可能にします。また指数関数的な性質によりスコア間の差異を強調し、モデルのフォーカスをより選択的かつ解釈しやすくします。
アテンションメカニズムは、モデルが現在の生成ステップに関連する入力の異なる部分に動的に重み付けを行うことを可能にします。応答を生成する際、モデルはどの過去のトークンや入力要素が次のトークン予測に最も影響を与えるかをアテンションで判断します。この文脈認識的な重み付けにより、長文でも一貫性の維持やエンティティの追跡、曖昧さの解消、入力の特定部分への適切な参照が可能となり、より正確かつコンテキストに合った応答が生成されます。
ChatGPT、Perplexity、その他のプラットフォームでAIチャットボットがブランドを言及する方法を追跡します。AI存在感を向上させるための実用的なインサイトを取得します。
ファーストクリックアトリビューションは、コンバージョンクレジットの全てをファーストタッチポイントに割り当てます。このモデルの仕組みや活用方法、マーケティング測定やAIモニタリングへの影響について解説します。...

アトリビューションモデルの概要、仕組み、ビジネスに最適なモデルの選び方を学びましょう。ファーストタッチ、ラストタッチ、マルチタッチ、アルゴリズム型アトリビューションのフレームワークを詳しく解説し、正確なコンバージョントラッキングを実現します。...

アンビエントAIアシスタントとは何か、スマートホームでどのように機能するのか、購買決定への影響、そしてインテリジェントな生活環境の未来について解説。積極的なAIシステムの包括的ガイド。...
クッキーの同意
閲覧体験を向上させ、トラフィックを分析するためにクッキーを使用します。 See our privacy policy.