
著者付き記事スキーマ:AIが認識する信頼シグナル
著者マークアップ付き記事スキーマがAIシステムの信頼シグナルをいかに構築するかを解説します。著者マークアップを実装し、ChatGPT、Perplexity、Google AI Overviewsでの可視性を向上させましょう。...
1 分で読める
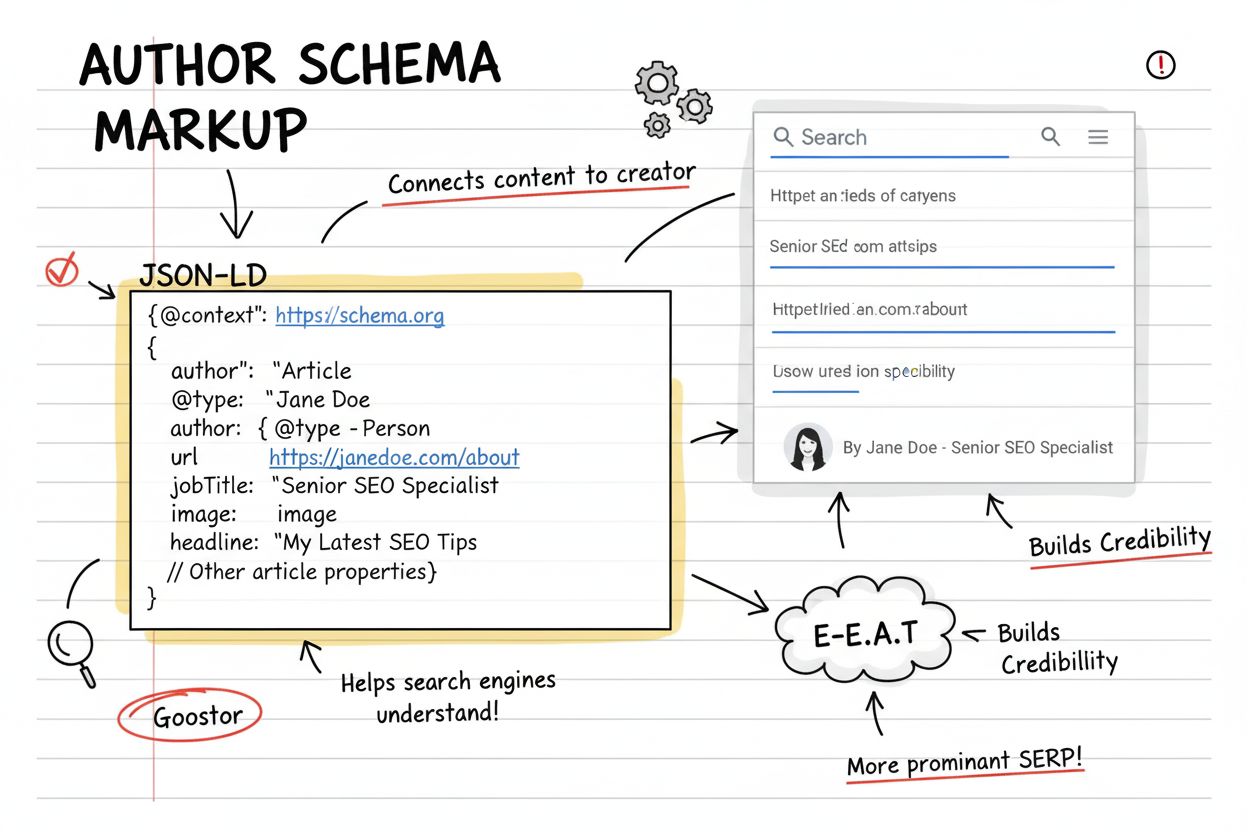
著者スキーマは、ウェブコンテンツの作成者を検索エンジンやAIシステムに明示的に識別させるための標準化された構造化データマークアップです。JSON-LD、Microdata、RDFaなどの形式で実装され、名前、URL、資格、職業などの著者情報を含めることで、コンテンツの権威性を確立し、E-E-A-Tシグナルをサポートします。
著者スキーマは、ウェブコンテンツの作成者を検索エンジンやAIシステムに明示的に識別させるための標準化された構造化データマークアップです。JSON-LD、Microdata、RDFaなどの形式で実装され、名前、URL、資格、職業などの著者情報を含めることで、コンテンツの権威性を確立し、E-E-A-Tシグナルをサポートします。
著者スキーマは、ウェブコンテンツの作成者が誰であるかを検索エンジンやAIシステムに明示的に伝えるための標準化された構造化データマークアップフォーマットです。JSON-LD、Microdata、RDFaの各形式を通じて実装され、作成者の名前、プロフェッショナルURL、資格、職名、所属組織などの機械可読な情報を提供します。このマークアップは通常、Article、BlogPosting、NewsArticleなどの広範なコンテンツスキーマタイプ内にネストされ、現代SEOやコンテンツ帰属戦略の重要な要素となっています。著者情報をウェブページのコードに直接埋め込むことで、作成者の曖昧さを排除し、検索エンジンが特定分野で実績ある実在の個人や組織とコンテンツを結びつけるのに役立ちます。
検索における著者識別の概念は、Google Authorshipプログラム(2011〜2014年、現在は終了)に代表されるように、Googleが著者情報を表示しようとした初期の試みから大きく進化してきました。このプログラムは廃止されましたが、「著者の信頼性が検索品質に重要である」という原則はますます強まっています。2024年時点で4,500万以上のウェブドメインがschema.orgの構造化データを実装しており、JSON-LDの導入率は41%に達し、前年比7%増加しています。この普及は、構造化データが従来の検索だけでなく新興のAI主導の検索システムにも不可欠であるという認識の高まりを反映しています。Googleは品質評価ガイドラインでE-E-A-T(経験・専門性・権威性・信頼性)を重視しており、著者識別はコンテンツ評価においてますます重要になっています。ChatGPT、Perplexity、Google AI Overviews、ClaudeなどAI生成検索結果が台頭する中、これらのシステムが元のコンテンツソースに正しく帰属するためには明確な著者データが必要なため、著者スキーマの重要性はさらに高まっています。
著者スキーマのマークアップには、包括的な著者プロフィールを作成するためのいくつかの主要プロパティが含まれます。@typeプロパティは、著者がPerson(個人)かOrganization(組織)かを指定し、さまざまなコンテンツシナリオに対応可能です。nameプロパティには、すべてのプラットフォームで統一された著者のフルネームを記載し、検索エンジンが複数コンテンツ間で著者を認識しやすくします。urlプロパティは、著者を一意に特定できる専用の著者ページや略歴ページ、またはプロフェッショナルプロフィールへのリンクであり、Googleが著者の実在性と専門性を確証する上で最も強力なプロパティと言えます。jobTitle(職名)は著者の職業上の役割、affiliation(所属)は組織との関連、imageはプロフェッショナルな顔写真のURL、sameAsは著者のSNSや他のウェブプレゼンスへの複数URLを示せます。descriptionプロパティで簡単な略歴を記載でき、honorificPrefixやhonorificSuffixで「Dr.」「Ph.D.」などの称号の明示も可能です。
著者スキーマとE-E-A-Tの関係は、現代SEO戦略の根幹を成します。経験は、職歴や実績を詳細に記した著者略歴ページで示されます。専門性は、著者の知識や資格を示すコンテンツやリンクで確立されます。権威性は、専門認定、出版物、業界団体など外部の検証源に著者スキーマが繋がることで強化されます。信頼性は、透明な著者情報、一貫した帰属、著者の経歴や資格の明示によって構築されます。特にYMYL(Your Money Your Life)分野、すなわち健康・金融・法律・科学系コンテンツでは、著者スキーマの重要性がさらに増します。Googleの品質評価ガイドラインは、評価者にページの品質判断の際に作成者の権威性を判断するよう明示しています。包括的な著者プロフィールページへのリンクを含む適切な著者スキーマの実装は、E-E-A-Tの4つの柱すべてを証明する具体的かつ検証可能な証拠となり、競争の激しい分野での検索順位向上に大きく貢献します。
著者スキーマは主に3つのフォーマットで実装できます。それぞれ異なる利点があります。JSON-LD(JavaScript Object Notation for Linked Data)はGoogleが最も推奨する形式で、構造化データ導入の41%を占めます。ページの<head>内の<script>タグに配置され、HTML構造に影響を与えないため、現代のウェブ開発に最適です。MicrodataはHTML属性(itemscope、itemtype、itempropなど)をページ本文内で使用し、著者情報が検索エンジンとユーザー両方に可視化されます。RDFa(Resource Description Framework in Attributes)はさらに別のセマンティックマークアップ手法ですが、JSON-LDほど普及していません。ほとんどのパブリッシャーにとってはJSON-LDが推奨されます。柔軟性が高く、実装が容易で、最新のウェブ技術やCMSと直接互換性があるためです。WordPressユーザーはYoast SEO、Rank Math、Schema Proなどのプラグインを使い、手作業なしで著者スキーマを自動生成できます。カスタムサイトでは、開発者が直接JSON-LDを組み込むか、スキーマジェネレーターでコードスニペットを生成して貼り付けることも可能です。
| 側面 | JSON-LD | Microdata | RDFa |
|---|---|---|---|
| 導入率 | 41%(最多) | 低め | 最も低い |
| 実装場所 | <head>内の<script>タグ | HTML属性でインライン | HTML属性でインライン |
| HTML構造への影響 | 影響なし | HTMLに組み込み | HTMLに組み込み |
| 使いやすさ | 非常に簡単・開発者向け | 中程度 | 複雑 |
| 検索エンジン対応 | 優秀(Google推奨) | 良好 | 良好 |
| CMSプラグイン対応 | 豊富 | 中程度 | 限定的 |
| ユーザーへの可視性 | ページ表示から非表示 | 表示可能 | 表示可能 |
| 推奨用途 | モダンサイト、WordPress | セマンティックHTML統合 | 高度なセマンティックマークアップ |
AI主導の検索システムが普及する中で、著者スキーマはコンテンツ帰属と作成者認識の重要な仕組みとなりました。Perplexity、ChatGPT、Google AI Overviews、Claudeなどのプラットフォームは、構造化データを解析してコンテンツソースを理解し、回答に正しい帰属を行います。AIシステムが適切に実装された著者スキーマを検出した場合、著者情報を抽出し、資格を検証し、生成された回答に正しい帰属を含められます。これは、AmICitedのようなブランド・ドメイン言及をAI検索で追跡するモニタリングプラットフォームにとって特に重要です。著者スキーマを解析することで、単なる引用・参照の有無だけでなく、「誰が」作成したかやAI回答内でどのように扱われたかも把握できます。作成者・パブリッシャーにとっては、著者スキーマの実装は単なるSEOのベストプラクティスにとどまらず、AI時代の正しい帰属確保のための必須要件となりました。スキーママークアップを実装したウェブサイトは未導入より平均30%クリック率が向上するというデータもあり、この優位性はAI分野にも及びます。
著者スキーマを効果的に実装するには、いくつかの重要なベストプラクティスに注意を払う必要があります。一貫性が最重要:スキーマ内の著者名は略歴ページ、SNSプロフィール、他の出版物と完全に一致させましょう。この一貫性が検索エンジンによる著者プロファイルの強化につながります。完全性も重要で、技術的には著者名だけでも動作しますが、url、jobTitle、affiliation、imageなど追加プロパティを含めることで、検索エンジンが理解しやすいリッチな著者情報になります。正確性も不可欠です。スキーマ内の情報はすべて検証可能かつ正確であるべきです。虚偽の情報はGoogleガイドライン違反となり、手動対策のリスクがあります。可視性にも配慮し、スキーマの著者情報と実際にページ上で見える情報が一致するようにします。両者に食い違いがあると品質面で問題視される場合があります。保守性も重要で、著者の職名や所属、略歴などはキャリアの変化に合わせて随時更新しましょう。バリデーションはGoogleリッチリザルトテストを使い、マークアップの正確性とエラーの有無を定期的に確認します。最後に、リンク戦略も大切です。author.urlプロパティは、できれば外部SNSではなく自サイト内の専用著者ページを指すのが最も強力な権威シグナルとなり、サイトのトピック権威性構築にも役立ちます。
著者スキーマは、検索エンジンがナレッジグラフ(エンティティや関係のデータベース)を構築・維持する際にも重要な役割を果たします。複数コンテンツにわたる適切な著者スキーマを検出すると、検索エンジンはそれらを集約し、詳細な著者プロファイルをナレッジグラフ内に構築できます。これにより、著者の専門分野、経歴、各トピックでの信頼性などを理解しやすくなります。例えば、医師が複数の記事に著者スキーマを正しく付与していれば、Googleはその人物が医療分野の権威であると判別し、医療検索でそのコンテンツを重視できます。ナレッジグラフ連携は、検索結果右側に表示される著者パネル(著者情報ボックス)表示にもつながります。AIシステムがナレッジグラフを参照し、根拠のある情報を抽出して回答するケースが増える中、著者スキーマの重要性は一層高まります。著者スキーマを含むデータで訓練されたAIシステムは、著者の専門性をより深く理解し、正確かつ適切に帰属された回答を提供できます。このように、適切な著者スキーマは従来型検索とAI主導型検索の両方で可視性と帰属を強化する好循環を生み出します。
著者スキーマの重要性は、デジタル環境の進化とともに今後さらに増していくと予想されます。AI生成コンテンツの増加に伴い、検索エンジンやAIシステムは著者の信頼性やコンテンツ帰属をより重視するようになります。ゼロクリック検索やAI Overviewsの台頭で、コンテンツの可視性は正しい帰属やAIが正確にソースを理解・引用できる構造化データに依存するようになっています。今後は著者の本人確認機構の高度化や、ブロックチェーン型IDとの連携、構造化データをもとにした著者評価スコアの導入も考えられます。音声検索や会話型AIが主流化する中で、著者スキーマは「誰が作成したか」「その人物が信頼できるか」をAIが理解する上で不可欠な要素となります。今から包括的な著者スキーマ導入に取り組むパブリッシャーは、検索環境変化後も可視性と帰属を維持しやすくなります。また、AIの透明性やコンテンツ帰属に関する法規制が厳しくなるに従い、一部業界やコンテンツタイプにおいて著者スキーマはベストプラクティスを超えた「遵守義務」となる可能性もあります。セマンティックSEO、AI発見性、コンテンツ帰属の交点に立つ著者スキーマは、戦術的SEOツールからデジタルプレゼンスとブランド保護のための戦略的要素へと移行しつつあります。
+++
記事スキーマは、見出し、公開日、画像など複数のプロパティを含む、記事全体を記述するより広範な構造化データタイプです。著者スキーマは記事スキーマ内にネストされた要素で、コンテンツ作成者を特定し詳細情報を提供します。記事スキーマがコンテンツの内容を説明するのに対し、著者スキーマは「誰が作成したか」を明確にし、その信頼性を確立します。
著者スキーマは、作成者の専門性、経験、信頼性に関する検証可能な情報を提供することで、E-E-A-Tを直接サポートします。資格や職歴が記載された著者のプロフィールページへのリンクを設けることで、検索エンジンはコンテンツの質をより正確に評価できます。特に健康、金融、法律などのYMYL(Your Money Your Life)分野では、著者の権威性が非常に重要です。
はい、著者スキーマは個人(Person)にも組織(Organization)にも対応しています。組織コンテンツの場合、Organizationスキーマタイプを使って会社自体を著者として指定できます。これは企業発表やプレスリリース、全社的なコンテンツなど、個人ではなく組織が情報源となる場合に有用です。
著者スキーマは、ChatGPT、Perplexity、GoogleのAI OverviewsなどのAIシステムが解析できる機械可読な帰属データを提供します。AI生成検索結果が増える中、著者スキーマは、AIシステムがコンテンツを引用・参照する際に、元の作成者に正しい帰属を与えることを保証し、AmICitedのようなコンテンツモニタリングプラットフォームもサポートします。
著者スキーマ自体は直接的なランキング要因ではありませんが、E-E-A-Tシグナルを強化しリッチスニペットを可能にすることで間接的にランキングをサポートします。適切に実装された著者スキーマのあるページは、強化された検索機能の対象となりやすく、クリック率の向上につながります。リッチリザルトによる可視性とユーザーエンゲージメントの向上が、SEO全体のパフォーマンスに好影響を与えます。
厳密な必須プロパティはありませんが、Googleは最低限、著者名とプロフィールまたは略歴ページへのURLの記載を推奨しています。ベストプラクティスとしては、jobTitle、affiliation、imageなども含め、検索エンジンやユーザーが作成者の専門性や信頼性を理解しやすくすることが推奨されます。
著者スキーマは、AmICitedのようなプラットフォームがChatGPT、Perplexity、Google AI Overviewsなどで作成者のコンテンツがどこでどのように登場するか追跡するのを可能にします。構造化された著者情報を提供することで、AIモニタリングツールがコンテンツを適切に帰属し、作成者がブランドのAI検索結果での可視性を理解する助けとなります。
ChatGPT、Perplexity、その他のプラットフォームでAIチャットボットがブランドを言及する方法を追跡します。AI存在感を向上させるための実用的なインサイトを取得します。
著者マークアップ付き記事スキーマがAIシステムの信頼シグナルをいかに構築するかを解説します。著者マークアップを実装し、ChatGPT、Perplexity、Google AI Overviewsでの可視性を向上させましょう。...

著者スキーママークアップがChatGPT、Perplexity、Google AI OverviewsでのAI引用をどのように向上させるかを学びましょう。AI生成回答でブランドの可視性を高める実装戦略もご紹介。...
著者スキーマがAIによる引用に役立つかどうかに関するコミュニティディスカッション。ChatGPT、Perplexity、AI Overviewsで著者マークアップの効果をテストしたSEOの専門家による実体験。...
クッキーの同意
閲覧体験を向上させ、トラフィックを分析するためにクッキーを使用します。 See our privacy policy.