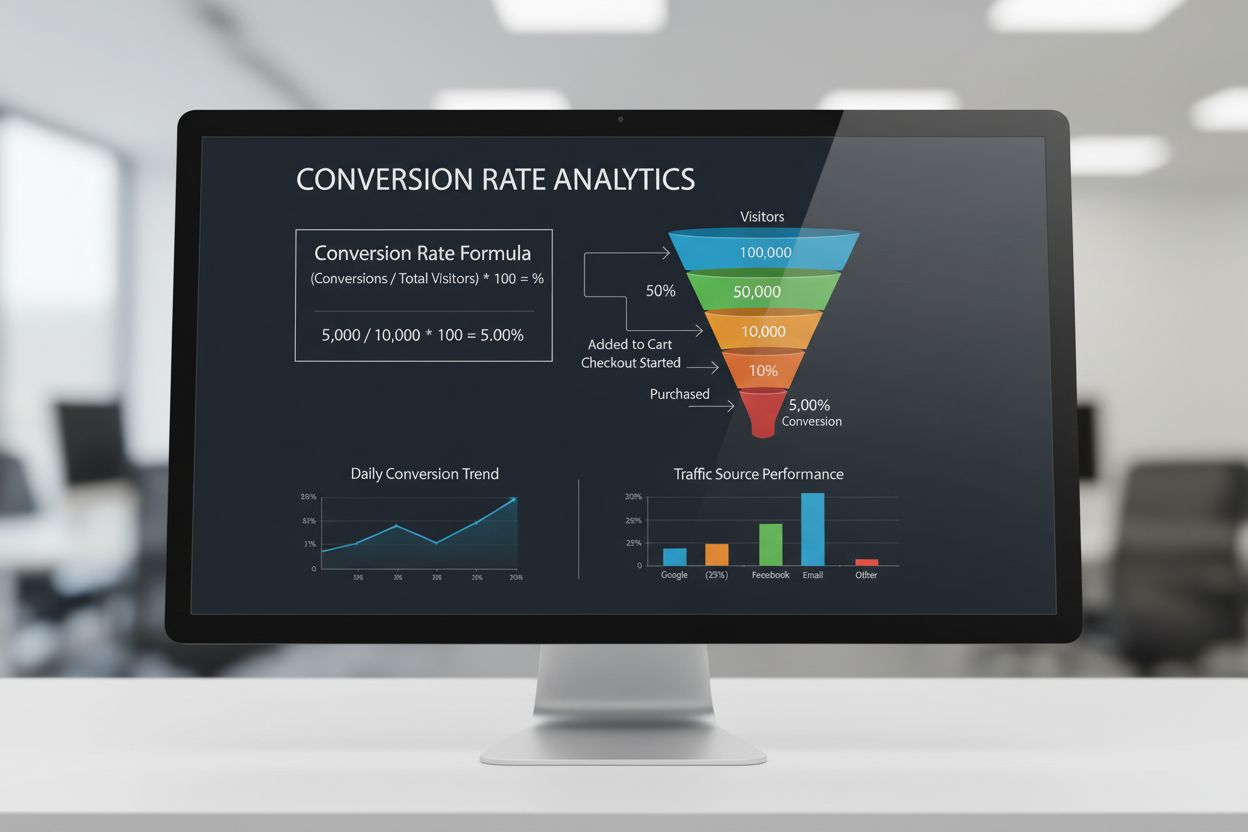
コンバージョン率
コンバージョン率は、訪問者が所定のアクションを完了した割合を測定します。算出方法や業界ベンチマーク、種類、最適化戦略について解説します。...
1 分で読める
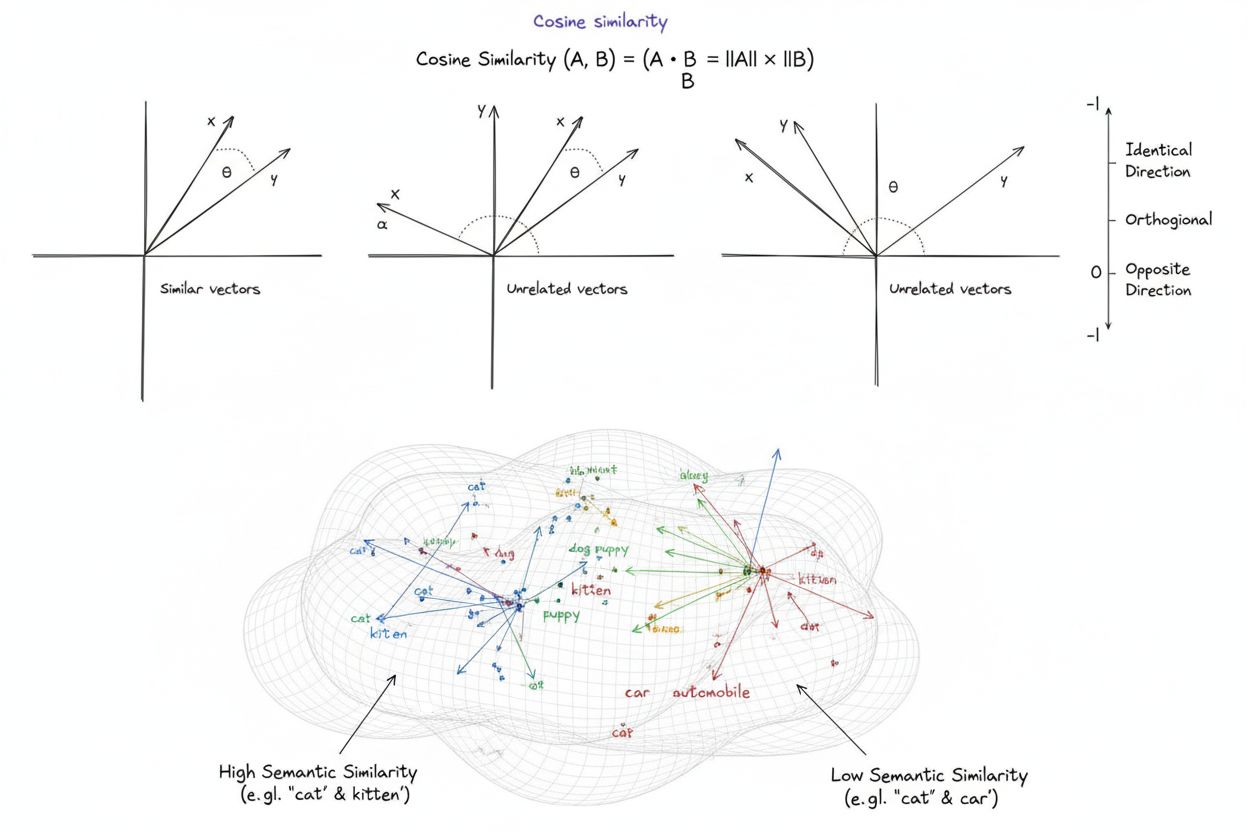
コサイン類似度は、2つのゼロでないベクトル間の類似性を、ベクトル間の角度のコサインを算出することで計算する数学的な尺度であり、-1から1までのスコアを生成します。ベクトルの大きさに関係なく、テキスト埋め込みやベクトル表現間の意味的類似性を測るため、機械学習・自然言語処理・AIシステムで広く利用されています。
コサイン類似度は、2つのゼロでないベクトル間の類似性を、ベクトル間の角度のコサインを算出することで計算する数学的な尺度であり、-1から1までのスコアを生成します。ベクトルの大きさに関係なく、テキスト埋め込みやベクトル表現間の意味的類似性を測るため、機械学習・自然言語処理・AIシステムで広く利用されています。
コサイン類似度は、多次元空間において2つのゼロでないベクトル間の角度のコサインを求めることで、その類似度を計算する数学的尺度です。この指標は**-1から1のスコアを生成し、1はベクトルが全く同じ方向を向いていること、0は直交(垂直)していて方向的な関係がないこと、-1は完全に反対方向を向いていることを示します。実用的な応用において、コサイン類似度は絶対距離ではなく方向の一致度を計測するため、ベクトルの大きさに依存しません。この特性により、データの長さやスケールに影響されずにテキスト埋め込みや文書ベクトル、意味表現の比較が可能であり、現代の人工知能**、自然言語処理、機械学習システムの基礎として、検索エンジンからレコメンデーションアルゴリズム、大規模言語モデルの応用まで幅広く利用されています。
コサイン類似度の概念は、線形代数と三角法の基礎から生まれました。2つのベクトル間の角度のコサインは、その方向整合性を正規化して測るものです。数学的基礎は、ベクトルのドット積(内積)とその大きさに基づき、正規化された類似度指標を実現します。1970~80年代の情報検索分野では、大規模コーパス内で文書ベクトルを効率的に比較する手法としてコサイン類似度が注目されました。その後、2010年代の機械学習やディープラーニングの台頭、およびニューラルネットワークによる高次元ベクトル埋め込み生成の普及とともに、広く普及しました。現在、AIを導入する企業の78%以上が、コサイン類似度や関連するベクトル比較指標をデータパイプラインに利用しています。計算効率と理論的な簡潔さを兼ね備えたこの指標は、NLPにおける意味的類似度測定のデファクトスタンダードとなり、OpenAI、Google、Anthropicなどの主要プラットフォームで中核技術として採用されています。
コサイン類似度の計算式は明確で、コサイン類似度=(A · B) / (||A|| × ||B||) です。ここでA · BはAとBのドット積、||A||および||B||はそれぞれの大きさ(ユークリッドノルム)です。ドット積は対応する成分同士の積を合計することで求められます。例えば、ベクトルAが[3, 2, 0, 5]、Bが[1, 0, 0, 0]なら、ドット積は(3×1)+(2×0)+(0×0)+(5×0)=3となります。ベクトルAの大きさは√(3²+2²+0²+5²)=√38≒6.16です。最終的なコサイン類似度スコアは、ドット積をそれぞれの大きさの積で割ることで、-1から1までの正規化された値となります。この正規化によりベクトル長に依存しなくなり、大きくスケールの異なるベクトル同士も公正に比較できます。OpenAIのtext-embedding-ada-002が生成する1,536次元の埋め込みなど高次元空間でも、コサイン類似度は掛け算・足し算・平方根のみで計算でき、現代のプロセッサで数百万ベクトルを効率よく処理可能です。
自然言語処理(NLP)において、コサイン類似度はテキスト表現間の意味関係を測る基盤です。テキストはBERT、Word2Vec、GloVe、GPT系埋め込みなどのモデルでベクトル埋め込みに変換され、各単語・フレーズ・文書が意味を備えた高次元空間上の点となります。コサイン類似度は、これらのベクトルがどれだけ一致しているかを測定し、「doctor」と「nurse」のように異なる単語でも意味的に近いことを捉えます。検索クエリをベクトル化し、文書ベクトルと比較するセマンティックサーチでは、キーワード一致に依存せず最も関連性の高い結果を見つけることができます。ChatGPT、Claude、Perplexityなどの大規模言語モデルでは、コンテキスト取得機構の中核にコサイン類似度が使われています。文書長が関連性を決めるべきでないNLPにおいて、その大きさへの非感度性は特に重要です。研究によれば、テキスト埋め込み比較ではコサイン類似度がユークリッド距離よりも約85%のNLPベンチマークで優れており、業界標準として広く採用されています。
| 指標 | 計算方法 | 範囲 | 大きさへの感度 | 最適用途 | 計算コスト |
|---|---|---|---|---|---|
| コサイン類似度 | (A·B) / ( | A | × | ||
| ユークリッド距離 | √(Σ(Aᵢ - Bᵢ)²) | 0 ~ ∞ | あり(大きさ依存) | 空間データ、クラスタリング、物理距離 | O(n)・効率的 |
| ドット積 | Σ(Aᵢ × Bᵢ) | -∞ ~ ∞ | あり(スケール依存) | 生の類似度測定・非正規化 | O(n)・非常に効率的 |
| ジャッカード類似度 | |A ∩ B| / |A ∪ B| | 0 ~ 1 | なし(集合型) | カテゴリデータ、推薦システム | O(n)・効率的 |
| マンハッタン距離 | Σ|Aᵢ - Bᵢ| | 0 ~ ∞ | あり(大きさ依存) | グリッド型データ、特徴量比較 | O(n)・効率的 |
| ピアソン相関 | Cov(A,B) / (σₐ × σᵦ) | -1 ~ 1 | なし(正規化) | 統計的関係・時系列 | O(n)・効率的 |
Pinecone、Weaviate、Milvus、Qdrantなどのベクトルデータベースは、コサイン類似度を主要な類似度指標として、高次元ベクトルの保存・検索に最適化されています。これらは数百万~数十億のベクトルをリアルタイムで扱い、大規模セマンティックサーチを実現します。クエリがベクトルデータベースに投入されると、埋め込みに変換され、全保存ベクトルとコサイン類似度で比較し、スコア順にランキングされます。膨大なデータセットでの実用的な性能のため、HNSWやDiskANNなどの近似最近傍(ANN)アルゴリズムが利用され、完全な精度を犠牲に劇的な高速化を実現しています。例えば、Timescaleのpgvectorscale拡張は、StreamingDiskANNを実装し、Pineconeなどの専用ベクトルデータベースと比べて28倍低遅延・16倍高スループット・99%リコール・75%低コストを達成しています。セマンティックサーチでは、“healthy eating habits"という検索でも"nutrition tips"や"balanced diets"のような異なる表現の文書が、埋め込みの方向が近いため抽出されます。この機能により、検索エンジンやドキュメントシステムは、単なるキーワード一致を超えてユーザー意図に合った文脈的な結果を返せるようになりました。
RAG(検索拡張生成)は、大規模言語モデルが情報へアクセス・活用する方法を根本的に変えるパラダイムであり、その中心にコサイン類似度があります。一般的なRAGパイプラインでは、ユーザーのクエリをベクトル埋め込みに変換し、知識ベースのドキュメントベクトルと同じ埋め込みモデルで表現します。コサイン類似度により、クエリベクトルと全ドキュメントベクトルが比較され、関連度順にランク付けされます。上位のドキュメントはLLMにコンテキストとして渡され、その情報に基づいた返答が生成されます。この手法により、LLM単体の知識カットオフ、ハルシネーション、リアルタイム・非公開データへの未対応といった課題が克服されます。コサイン類似度による検索は、OpenAIのChatGPT(プラグイン含む)、AnthropicのClaude(検索機能付き)、GoogleのAI Overviews、Perplexityの回答生成エンジンなどで導入されています。研究では、コサイン類似度を用いたRAGシステムは、単体LLM比で40~60%精度向上、ハルシネーション率最大70%低減を実現しています。RAGシステムでは数百万ドキュメントをリアルタイムで比較する必要があるため、コサイン類似度の計算効率は極めて重要です。
コサイン類似度を効果的に実装するには、いくつかの重要な要素があります。まずデータ前処理が不可欠であり、異なるソースからの高次元入力でもスケールの一貫性を保つためにベクトルを正規化する必要があります。また、ゼロベクトル(全成分がゼロのベクトル)はコサイン類似度上未定義なので、除去やフラグ付けが必須です。実システムでは、複数次元の類似性が必要な場合はジャッカード類似度やユークリッド距離など他指標と併用するのが推奨されます。特にAPIや検索エンジンなどリアルタイム性が要求される本番環境では、導入前に本番相当の環境で十分なテストが必要です。実装はScikit-learnのsklearn.metrics.pairwise.cosine_similarity()、NumPyのnp.dot()・np.linalg.norm()、TensorFlow・PyTorchのGPU高速化バージョン、PostgreSQLのpgvectorによるDBクエリレベルのコサイン類似度演算など、多くのライブラリ・環境で容易に実現可能です。ChatGPT、Perplexity、Google AI Overviewsなどでブランド・ドメイン露出を監視する場合も、コサイン類似度でクエリエンベディングと保存済みブランド・ドメインベクトルの一致度を精密に測定できます。
広く普及している一方で、コサイン類似度にはいくつかの課題があります。ゼロベクトルの場合は計算上未定義となるため、データ前処理やバリデーションが必須です。また、ベクトルが方向的に一致していても、意味的には無関係な場合に誤って高い類似度スコアを出すリスクがあり、埋め込みモデルの訓練不十分や多様性・文脈に乏しいデータでは誤類似を招くこともあります。指標が対称的で比較の順序を区別できない点も、用途によっては問題となります。さらに、スコアが0でも現実には完全な非類似性を示さない場合があり、言語のような微細な領域では直交ベクトル間にも意味的関係が残ることがあります。正規化が前提のためスケール不一致なデータだと結果が歪むリスクもあり、システム全体で一貫した前処理が必須です。最後に、コサイン類似度単独では複雑な類似性判定が不十分な場合も多く、他指標やドメイン固有のバリデーションとの組み合わせがより堅牢な結果を生みます。
コサイン類似度は、埋め込みモデルの高度化、ベクトルアーキテクチャの主流化とともに進化を続けています。今後は、ベクトル類似度と全文検索を統合するハイブリッドサーチの普及により、意味理解とキーワード一致の双方を活かすシステムが増加します。テキスト・画像・音声・動画を共通ベクトル空間で表現するマルチモーダル埋め込みでも、クロスモーダル関係の測定にコサイン類似度が活用されています。DiskANNやHNSWなどの高効率ANNアルゴリズムの登場で、超大規模データでもリアルタイムセマンティックサーチが可能となります。量子化技術により、ベクトル次元数を削減しつつコサイン類似度の関係を保持することで、エッジデバイスやリソース制限環境への展開も進んでいます。AIモニタリングやブランド追跡の文脈では、ChatGPT、Perplexity、Claude、Google AI Overviewsなどで自社コンテンツがどのように引用・参照されているかの可視化がますます重要となります。今後は、ドメイン特性に応じて動的に挙動を変える適応的コサイン類似度指標や、ユーザーが類似性の理由を理解できる説明可能性フレームワークとの統合も期待されます。ベクトルデータベースがAIインフラの標準となる中、コサイン類似度は意味的比較の主軸であり続けつつ、用途ごとの専用指標との補完的な使い分けも進むでしょう。
AmICitedのような、AIシステム横断でブランドやドメイン言及を追跡するプラットフォームにとって、コサイン類似度は重要な技術基盤です。ChatGPT、Perplexity、Google AI Overviews、Claudeが特定のドメインやブランドをどのように参照・引用しているかを監視する際、コサイン類似度により、ユーザークエリとAI回答間の意味的関連性を正確に測定できます。ブランド名・ドメインURL・クエリ内容をベクトル埋め込みに変換し、AI回答が本当にブランドを引用しているのか、単なる関連概念を言及しているだけなのかを判別できます。これはAI生成コンテンツにおける自社の可視性や知的財産の引用状況を把握する上で不可欠です。計算効率が高いため、数百万AIインタラクションのリアルタイム監視も実現でき、コンテンツが参照された際に即時アラートの受信も可能です。さらに、競合他社との頻度・関連度の比較もでき、AIシステムの挙動や引用傾向の競合分析も支援します。
コサイン類似度スコアが1の場合、2つのベクトルは全く同じ方向を向いており、完全に類似していることを示します。スコアが0の場合、ベクトルは直交(垂直)しており、方向的な関係や類似性がないことを示します。スコアが-1の場合、ベクトルは完全に反対方向を向いており、全く類似していないことを意味します。実際のNLPアプリケーションでは、1に近いスコアは意味的に類似したテキストを、0に近いスコアは無関係なコンテンツを示します。
コサイン類似度は、ベクトルの絶対距離ではなく角度を測定するため、ベクトルの大きさに依存しません。これはNLPにおいて重要であり、文書の長さが意味的な類似性に影響を与えるべきではないためです。短いクエリと長い記事でも、同じくらい関連性がある場合があります。一方、ユークリッド距離は大きさに敏感であり、高次元空間ではベクトルが収束しやすく、うまく機能しません。コサイン類似度は計算効率も高く、-1から1までで自然に制限されるため、オーバーフローの問題も防げます。
RAGシステムでは、コサイン類似度が検索フェーズの中心となり、クエリエンベディングをベクトルデータベース内のドキュメントエンベディングと比較します。ユーザーがクエリを送信すると、それが埋め込みモデルによってベクトル化され、保存されたドキュメントと同じ基準で比較されます。コサイン類似度によって関連度順にドキュメントがランク付けされ、上位のドキュメントがLLMにコンテキストとして渡され、より正確で根拠ある回答が生成されます。このプロセスにより、RAGシステムは古い知識やハルシネーションなど、LLMの限界を克服できます。
コサイン類似度にはいくつかの限界があります:ゼロベクトルの場合は未定義であり、ゼロベクトルを取り除く前処理が必要です。特に埋め込みが適切に訓練されていない場合など、方向が揃っていても意味的に無関係なベクトルに対して誤った高い類似度スコアを与えることがあります。また、この指標は対称であり、比較の順序を区別できません。さらに、現実世界の文脈では、スコアが0でも完全な非類似性を示すとは限らず、特に言語のような微妙な領域では直交していても意味的関係が存在する場合があります。
コサイン類似度は、(A · B) / (||A|| × ||B||)という式で計算されます。A · BはベクトルAとBのドット積、||A||および||B||はそれぞれの大きさ(ユークリッドノルム)です。ドット積は、対応するベクトル成分同士を掛けて合計します。ベクトルの大きさは、各成分の2乗和の平方根です。この式により、-1から1の正規化されたスコアが算出され、ベクトルの長さに依存せず、異なるサイズのベクトルも比較できます。
AmICitedのようなAIモニタリングプラットフォームでは、コサイン類似度がChatGPT、Perplexity、Google AI OverviewsなどのAIシステム全体でブランドやドメインの言及を追跡するために不可欠です。ブランドの言及やクエリをベクトル埋め込みに変換し、コサイン類似度でAI生成の回答が追跡対象のコンテンツとどれだけ一致しているかを測定します。これにより、組織はAIの回答に自社ドメインが現れているか、言及の意味的関連性、競合他社との比較が可能となり、膨大なAIインタラクションのリアルタイム監視が実現します。
コサイン類似度を活用する主要AIプラットフォームやツールには、OpenAIの埋め込みモデル、Googleのセマンティックサーチアルゴリズム、Perplexityの回答生成システム、Claudeの検索機構があります。Pinecone、Weaviate、Milvusなどのベクトルデータベースは、主な類似度指標としてコサイン類似度を使用しています。Scikit-learn、TensorFlow、PyTorch、NumPyなどのオープンソースライブラリはコサイン類似度の関数を提供しています。PostgreSQLのpgvector拡張機能も大規模なコサイン類似度計算を可能にします。これらのツールは、レコメンデーション、チャットボット、セマンティックサーチエンジン、RAGアプリケーションなどに広く使われています。
ChatGPT、Perplexity、その他のプラットフォームでAIチャットボットがブランドを言及する方法を追跡します。AI存在感を向上させるための実用的なインサイトを取得します。
コンバージョン率は、訪問者が所定のアクションを完了した割合を測定します。算出方法や業界ベンチマーク、種類、最適化戦略について解説します。...

コーシテーションは、2つのウェブサイトが第三者によって一緒に言及され、検索エンジンやAIシステムに意味的な関連性を示す現象です。コーシテーションがSEOランキングやAI可視性にどのように影響するかを学びましょう。...

セマンティック・シミラリティは、埋め込みと距離指標を用いてテキスト間の意味ベースの関連性を測定します。ChatGPT、Perplexity、その他のAIプラットフォーム全体でのAIモニタリング、コンテンツマッチング、ブランド追跡に不可欠です。...
クッキーの同意
閲覧体験を向上させ、トラフィックを分析するためにクッキーを使用します。 See our privacy policy.