
AI検索エンジン向け重複コンテンツの対処方法
AIツール使用時の重複コンテンツ管理と防止方法を解説。カノニカルタグやリダイレクト、検出ツール、独自性維持のベストプラクティスを学び、サイト内のコンテンツをユニークに保ちましょう。...
1 分で読める

重複コンテンツとは、同一または非常に類似したコンテンツが複数のURL上に存在する現象を指します。同一サイト内(内部重複)や異なるドメイン間(外部重複)で発生し、検索エンジンを混乱させ、ページのランキング権威を希釈し、SEOのパフォーマンスや可視性に悪影響を及ぼします。
重複コンテンツとは、同一または非常に類似したコンテンツが複数のURL上に存在する現象を指します。同一サイト内(内部重複)や異なるドメイン間(外部重複)で発生し、検索エンジンを混乱させ、ページのランキング権威を希釈し、SEOのパフォーマンスや可視性に悪影響を及ぼします。
重複コンテンツとは、同一または非常に類似したコンテンツが複数のURL上に存在する現象を指します。これには同一ウェブサイト内(内部重複)と異なるドメイン間(外部重複)の両方が含まれます。この基本的なSEOの課題は、検索エンジンが同じ内容の複数バージョンを検出した際、どのバージョンをインデックスし検索結果に表示すべきかを判断しなければならない点にあります。業界専門家による調査では、全ウェブコンテンツの約25〜30%が重複コンテンツであるとされており、デジタルマーケティングにおける最も広範な課題の一つです。この問題は従来型検索エンジンだけでなく、Perplexity、ChatGPT、Google AI Overviews、ClaudeなどのAI搭載検索システムにも波及し、コンテンツ権威やオリジナル情報源の混乱を引き起こします。重複コンテンツとみなされるには、他のコンテンツと文言・構造・フォーマットが顕著に重複し、独自性や付加価値がほとんど存在しない場合が該当します。
重複コンテンツの概念は、検索エンジン最適化初期から大きく進化してきました。1990年代に検索エンジンが登場した当初はウェブ規模が小さく断片的だったため、重複コンテンツはさほど問題視されていませんでした。しかし、インターネットの拡大やCMSの進化により、同一コンテンツを複数URLで公開することが容易となりました。Googleの重複コンテンツに関する公式見解では、正直な重複コンテンツにはペナルティを課さず、アルゴリズムで正規バージョンを選択してインデックス・ランク付けすることが明記されています。この違いは重要で、Googleは技術的な重複で手動ペナルティを出すことはありませんが、重複の存在自体が権威の希釈やクロールバジェットの無駄によりSEOパフォーマンスを損ないます。
ECプラットフォームやCMS、URLパラメータトラッキングの普及により、2000〜2010年代には重複コンテンツ問題が急増しました。セッションIDやソート・フィルターオプションにより、同一コンテンツを持つほぼ無限のURLバリエーションが生まれます。一方、コンテンツのシンジケーション(再掲載)も一般化し、複数ドメインに同じ記事が配信されるようになりました。2023〜2024年にはAI検索エンジンや大規模言語モデルの登場で、重複コンテンツ問題は新たな段階に突入します。AIはどのURLをランク付けし、どの情報源を引用すべきか判断しなければならず、AmICitedのようなブランド監視プラットフォームがAI検索エンジン上での可視性を追跡する必要性が高まっています。
重複コンテンツは複数のメカニズムでSEOに悪影響を及ぼし、サイトの可視性とランキング力を低下させます。主な問題は権威の希釈です。複数のURLに同じコンテンツが存在すると、それぞれに寄せられる被リンクが分散され、権威が1つのページに集約されません。たとえば、1つのバージョンに50件、別のバージョンに30件の被リンクがあると、80件の力を持つ1ページではなく、分裂した状態となり、競合キーワードでのランキングが著しく弱くなります。
検索エンジンはまた、インデックス化の課題にも直面します。どのバージョンをインデックスに含め、どれを除外するか決めなければなりません。万一Googleが質の劣るURLや権威の低いバージョンを選んでしまうと、意図したページがまったくランクインしないこともあります。さらに、重複コンテンツはクロールバジェットを浪費します。これは検索エンジンがサイトのクロールに割り当てる有限のリソースのことで、業界調査では重複コンテンツの修正だけでオーガニックトラフィックが20%以上増加したケースも報告されています。これは、検索エンジンが重複ではなくユニークで価値あるコンテンツのクロールに集中できるようになるためです。
影響はクリック率やユーザー体験にも及びます。同じ内容の複数バージョンが検索結果に表示された場合、ユーザーが質の低いバージョンをクリックしやすくなり、直帰率の上昇やエンゲージメントの低下につながります。AI検索エンジンやLLMでは、重複コンテンツが情報源の権威やオリジナル性にさらに混乱をもたらします。ChatGPTやPerplexityが同一コンテンツの複数バージョンを検出した際、どのURLを引用すべきか判断がつかず、意図しないURLへの引用やAIごとに異なる帰属が発生するリスクがあります。
| 問題タイプ | 原因 | 内部/外部 | 最適な解決策 | シグナルの強さ |
|---|---|---|---|---|
| URLパラメータ | トラッキング・フィルタ・ソート(例:?color=blue&size=10) | 内部 | カノニカルタグまたはGSCでパラメータ制御 | 強い |
| ドメインバリエーション | HTTPとHTTPS、wwwと非www | 内部 | 優先バージョンへの301リダイレクト | 非常に強い |
| ページネーション | 複数ページへの分割掲載 | 内部 | セルフカノニカルタグ | 中程度 |
| セッションID | 訪問者識別用IDのURL付与 | 内部 | セルフカノニカルタグ | 強い |
| コンテンツシンジケーション | 他ドメインへの正規再配信 | 外部 | カノニカルタグ+シンジケート側でnoindex | 中程度 |
| コンテンツスクレイピング | 他ドメインでの無断コピー | 外部 | DMCA申請+カノニカルタグ | 弱い(強制力要) |
| トレーリングスラッシュ | URL末尾の有無 | 内部 | 標準化フォーマットへの301リダイレクト | 非常に強い |
| 印刷用バージョン | 印刷向け別URL | 内部 | メインバージョンへのカノニカルタグ | 強い |
| ランディングページ | 広告用類似ページの量産 | 内部 | ランディングページにnoindexタグ | 強い |
| ステージング環境 | テストサイトの誤インデックス | 内部 | HTTP認証またはnoindex | 非常に強い |
重複コンテンツの技術的発生メカニズムを理解することは、効果的な対策を講じる上で不可欠です。URLパラメータは特にECや大規模サイトでよく見られる技術的原因です。例えばexample.com/shoes?size=9&color=blueのように、サイズや色ごとにパラメータを変えると、同じ商品ページなのに50通りものURLが生成されます。検索エンジンはこれら全バリエーションをクロールするため、クロールバジェットが浪費され、権威の分裂も招きます。
ドメイン設定の不備も大きな重複要因です。http://example.com、https://example.com、http://www.example.com、https://www.example.comなど複数のドメインバリエーションが存在し、正しく設定されていないと全てが別ページとしてインデックスされます。同様にトレーリングスラッシュの有無やURLの大文字小文字(GoogleはURLを区別します)も重複化の要因です。例えばexample.com/products/shoes/、example.com/products/shoes、example.com/Products/Shoes、example.com/products/Shoes/など、1ページに複数のURLが割り当てられることになります。
セッションIDやトラッキングパラメータも複雑化を招きます。?utm_source=twitter&utm_medium=social&utm_campaign=promoのようなURLごとに異なるIDやパラメータが付与されると、検索エンジンからはすべて別ページ扱いとなるため重複コンテンツとなります。ページネーションも、内容が重複したり、ページ間の関係が検索エンジンに正しく伝わらない場合、重複を引き起こします。
AI搭載検索エンジンや大規模言語モデルの登場で、重複コンテンツ問題は新たな課題を生み出しています。Perplexity、ChatGPT、Google AI Overviews、Claudeなどが同一コンテンツの複数バージョンを検出した際、どの情報源を引用し、どのように帰属させるか判断しなければなりません。これはブランドモニタリングや可視性追跡にとって重要な意味を持ちます。AmICitedのようなプラットフォームは、AI応答内でブランドがどこに出現しているかをトラッキングする際、重複コンテンツの影響を考慮しなければなりません。
例えば、企業が公式サイト(company.com/blog/article)で記事を公開し、同じ内容が他の3つのドメインにもシンジケートされている場合、AIはこれら4つのいずれかを引用することになります。ブランドの観点では、非推奨URLへの引用が権威を分散させ、競合サイトや質の低い転載先にトラフィックが流れるリスクもあります。ドメイン横断の重複コンテンツは、AIによるオリジナル作者の特定にも課題をもたらします。もし競合が先にスクレイピングしてインデックスされた場合、AIが誤って競合をオリジナルと認識することもあり得ます。
権威の集約はAI検索時代にさらに重要性を増しています。カノニカルタグや301リダイレクトで重複を集約することで、従来型SEOだけでなくAIによる正しい情報源の特定と引用を促進できます。ブランド保護やオピニオンリーダーシップの観点からも、権威あるURLが引用される体制構築が不可欠です。AmICitedでAI可視性をモニタリングする組織にとって、重複コンテンツがAI応答に与える影響を正しく把握することは大きなメリットとなります。
重複コンテンツは技術的・意図的な両側面から発生し、それぞれ解決策が異なります。技術的にはWebサーバーの設定不備が大きな原因です。ドメイン形式標準化が不十分だと、example.com、www.example.com、example.com/index.html、example.com/index.phpなど一つのホームページに複数のURLが割り当てられ、インデックスも分散します。CMSもカテゴリーやタグ付け機能によって、1記事が複数のカテゴリURLからアクセスできる=重複が生まれやすい構造です。
ECプラットフォームでは、商品フィルタやソートの組み合わせで同一商品のURLが何百通りにも生成されやすく、カノニカル化が不十分だと深刻な重複問題となります。ページネーションも、シリーズ記事や商品リストで内容が重複したり、ページ間の関係性が曖昧な場合は重複扱いされます。
意図的な重複はビジネス上の正当な理由から生じることもあります。コンテンツシンジケーション(複数ドメインへの再配信)は外部重複の代表例です。広告用ランディングページも既存コンテンツを微修正して量産されがちですし、印刷用バージョンも別URLで同一内容を提供します。これらは本来の目的があるため、カノニカルタグやnoindexで適切に管理する必要があります。
無断スクレイピングによる外部重複は最も深刻な課題です。競合や集約サイトにコンテンツをコピーされ、もし相手ドメインの方が権威が高ければ、オリジナルより上位表示されてしまい、トラフィックや権威を失うリスクがあります。
重複コンテンツ解消には、原因と状況に応じた多面的なアプローチが必要です。最も強力な方法が301リダイレクトで、URLを恒久的に別URLへ転送し、順位権威をまとめて移管します。これはドメイン標準化(HTTP→HTTPSや非www→wwwなど)に最適で、主要ホスティングやCMSの多くが設定ファイルや管理画面で容易に実装可能です。
カノニカルタグは、複数URLをユーザーに提供しつつ検索エンジンには優先URLを指定したい場合に有効です。重複ページの
内に<link rel="canonical" href="https://preferred-url.com">を設置することで、被リンクや権威を集約できます。URLパラメータ・ページネーション・シンジケートコンテンツなどにも有効です。noindexタグは、ユーザーには公開しつつ検索エンジンにはインデックスさせたくないページ(ランディングページ、印刷用、ステージング、検索結果ページ)に利用します。<meta name="robots" content="noindex">を設置するだけで、リダイレクトやカノニカルの必要がありません。
コンテンツ差別化も有効な対策です。各ページの内容を独自化し、オリジナルの調査や専門家コメント、具体例、実践的なアドバイスを盛り込むことで、重複ではなく相補的なコンテンツとして成立させられます。
無断スクレイピングによる外部重複には、GoogleのリーガルトラブルシューターでDMCA削除申請を行ったり、相手サイト管理者に削除やカノニカルタグ追加を要請します。応じない場合は法的措置も検討が必要です。
**重複コンテンツの定義と影響は、検索技術の進化や新プラットフォーム登場に伴い変化し続けています。**従来はGoogleやBing、Yahoo!などの検索エンジン対策が中心でしたが、AI搭載検索エンジンや大規模言語モデルの普及により、単なる重複判定に留まらず「どのバージョンが権威情報源か」をAIが判断・引用する時代に突入しています。
今後はAI検索でのブランド可視性や権威維持のためにも、重複コンテンツ管理の重要性がさらに高まると予想されます。AI検索利用者が増えるにつれ、どのバージョンが引用されるかコントロールすることが重要な競争要因となります。そのため、伝統的SEOだけでなくAI対応を見据えた重複管理戦略の実装が求められます。具体的にはカノニカルURLの明示、AIクローラーにとって発見しやすい優先バージョンの整備、ブランド帰属の明確化などです。
AmICitedのようなAIモニタリングツールのSEOワークフロー統合は、重複コンテンツが複数AI検索エンジンでの可視性にどう影響するかを可視化し、管理する上で大きな進化です。AIがオリジナル情報源や正しい帰属をより精度高く判定できるようになれば、カノニカルタグや301リダイレクト等の従来手法もより重要性を増します。今から積極的に重複コンテンツ対策を講じることで、今後のAI時代でもブランドの可視性と権威を維持し続けることができます。
ブロックチェーンによるコンテンツ証明や分散型IDシステムなど新技術の登場も期待されていますが、当面はカノニカルタグ・301リダイレクト・noindexなどの伝統的手法が最も実効性の高い対策です。重要なのは、これらの施策を一貫して実装し、従来型検索エンジンとAI型検索システムの双方で効果をモニタリングし続けることです。そのことで、ブランドの最適な可視性と権威性を維持できるでしょう。
内部重複コンテンツは、同一ウェブサイト内の複数のURLに同一または非常に類似したコンテンツが存在する場合に発生します。例えば、商品説明が複数ページに掲載されたり、異なるURLパラメータで同じページが表示される場合などです。外部重複コンテンツは、異なるドメイン上に同一のコンテンツが存在することで、主にコンテンツのシンジケーションや無断スクレイピングによって発生します。いずれもSEOに悪影響を及ぼしますが、内部重複はカノニカルタグや301リダイレクトなど技術的な手段で制御しやすいです。
Googleは、意図的かつ大規模に検索順位操作を目的とした場合を除き、通常は重複コンテンツに対して手動ペナルティを科しません。ただし、重複コンテンツはSEOパフォーマンスに悪影響を及ぼし、どのバージョンをインデックス・ランク付けするかで検索エンジンを混乱させたり、被リンクの権威が分散したり、クロールバジェットが無駄になる等の問題を引き起こします。Googleは主にアルゴリズムで正規ページを選択して対応しており、技術的なミスに対して罰則を科すものではありません。
重複コンテンツは、ChatGPT、Perplexity、ClaudeなどのAIシステムがどのバージョンを権威ある情報源として引用すべきか判断する際に問題となります。同一コンテンツが複数のURLに存在する場合、AIモデルは元の情報源を特定しづらくなり、権威の低いバージョンを引用したり、コンテンツの所有権に関して混乱が生じたりします。特に、AI検索結果での自社コンテンツの露出をモニタリングするブランド監視プラットフォームにとって、重複コンテンツは可視性を分断させる要因となります。
主な原因には、トラッキングやフィルタリング用のURLパラメータ(例:?color=blue&size=large)、ドメインのバリエーション(HTTPとHTTPS、wwwと非www)、複数ページにまたがるページネーション、コンテンツのシンジケーション、セッションID、印刷用ページ、Webサーバーの設定ミスなどがあります。トレーリングスラッシュやURLの大文字小文字の不一致、インデックスページ(index.html, index.php)も重複の要因です。また、ランディングページのコピーや他サイトによる無断転載など人為的な原因も重複コンテンツ問題を大きく助長します。
カノニカルタグはHTML要素(rel="canonical")で、同一または類似したコンテンツを持つ複数のURLがある場合に、どのURLが優先されるべきかを指定します。重複ページにカノニカルタグを追加してメインバージョンを指し示すことで、検索エンジンにインデックス・ランク付けすべきページを伝えます。これにより、ランキング権威や被リンクの力を1つのURLに集約でき、リダイレクトせずともユーザーには複数URLを提供しつつ検索エンジンには1つのバージョンを優先させられます。
Google Search Consoleのインデックスカバレッジレポートを使うと、重複コンテンツの問題があるページが表示されます。Semrush Site Audit、Screaming Frog、Conductorなどのツールでサイト全体をクロールし、85%以上一致しているページを検出できます。外部重複コンテンツの場合はCopyscapeなどのサービスでネット上のコピーを検索できます。定期的な監査でページタイトル・メタディスクリプション・H1見出しの一意性をチェックすることも内部重複の特定に役立ちます。
重複コンテンツは、検索エンジンがサイトのクロールに割り当てる有限のリソースであるクロールバジェットを浪費します。Googlebotが同じコンテンツの複数バージョンを検出すると、新規や更新されたページのインデックス化ではなく重複のクロールにリソースを消費してしまいます。大規模なサイトでは、これによりインデックスされる一意のページ数が大きく減少します。カノニカルタグや301リダイレクト、noindexタグで重複を整理することで、重要なコンテンツのインデックスやランキングの可能性を高め、クロールバジェットを有効活用できます。
ChatGPT、Perplexity、その他のプラットフォームでAIチャットボットがブランドを言及する方法を追跡します。AI存在感を向上させるための実用的なインサイトを取得します。
AIツール使用時の重複コンテンツ管理と防止方法を解説。カノニカルタグやリダイレクト、検出ツール、独自性維持のベストプラクティスを学び、サイト内のコンテンツをユニークに保ちましょう。...
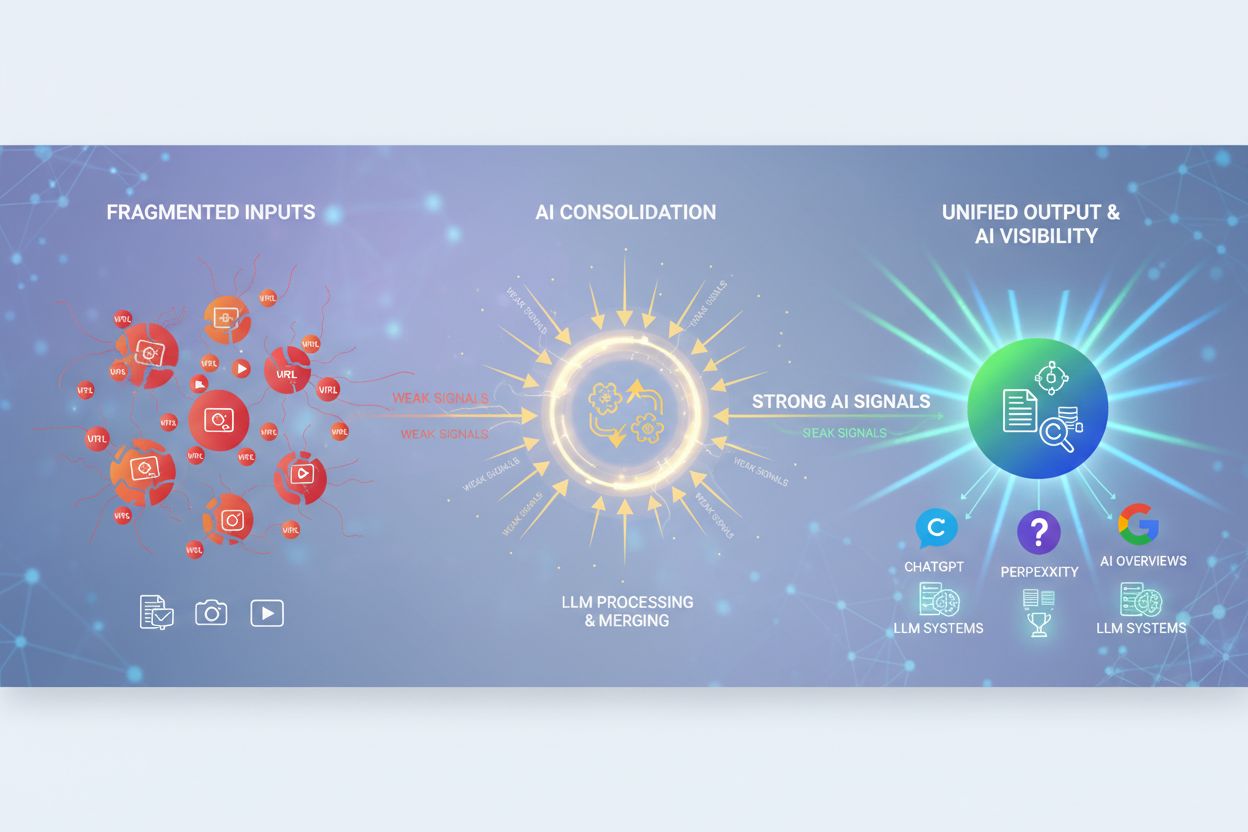
AIコンテンツ統合とは何か、類似コンテンツの統合がChatGPT、Perplexity、Google AI Overviewsでの可視性シグナルをどのように強化するかを学びましょう。統合戦略、ツール、ベストプラクティスを解説します。...
AIシステムが従来の検索エンジンとは異なる方法で重複コンテンツを扱う方法についてのコミュニティディスカッション。SEOプロフェッショナルがAIでのコンテンツ独自性について知見を共有します。...
クッキーの同意
閲覧体験を向上させ、トラフィックを分析するためにクッキーを使用します。 See our privacy policy.