
AIモデルのファインチューニング
AIモデルのファインチューニングで、事前学習済みモデルを業界やブランド固有のタスクに適応させ、精度を高めつつコストと計算要件を削減する方法を解説。手法・ユースケース・ベストプラクティスを紹介します。...
1 分で読める

ファインチューニングとは、事前に学習されたAIモデルを、より小規模なドメイン固有のデータセットで追加学習することで特定のタスクに適応させる手法です。この技術は、初期の事前学習で得られた幅広い知識を活かしながら、モデルのパラメータを専門的な用途に最適化するため、ゼロからの学習より効率的かつコスト効果の高い方法となります。
ファインチューニングとは、事前に学習されたAIモデルを、より小規模なドメイン固有のデータセットで追加学習することで特定のタスクに適応させる手法です。この技術は、初期の事前学習で得られた幅広い知識を活かしながら、モデルのパラメータを専門的な用途に最適化するため、ゼロからの学習より効率的かつコスト効果の高い方法となります。
ファインチューニングとは、事前学習済みAIモデルをより小規模なドメイン固有データセットで追加学習し、特定のタスクを実行できるよう適応させるプロセスです。AIモデルをゼロから構築するには膨大な計算資源と大量のラベル付きデータが必要ですが、ファインチューニングは、初期の事前学習で獲得した幅広い知識を活かし、専門的な用途に最適化します。この手法は現代の深層学習や生成AIに不可欠となっており、組織が大規模言語モデル(LLM)のような強力なモデルを独自の業務ニーズに合わせてカスタマイズすることを可能にします。ファインチューニングは転移学習の実践的なアプローチの一つであり、あるタスクで得た知見を関連する別のタスクの性能向上に生かすものです。直感的にも、一般的なパターンを既に理解しているモデルの能力を磨く方が、特定目的のために新たなモデルを一から学習させるよりも遥かに容易かつ低コストです。
深層学習モデルが指数関数的に大規模・複雑化する中で、ファインチューニングは重要な技術として登場しました。2010年代初頭、膨大なデータセットでの事前学習後にタスク特化学習を行うことで、性能向上と学習時間短縮を両立できることが発見されました。このアプローチは、トランスフォーマーモデルやBERT(Bidirectional Encoder Representations from Transformers)の台頭とともに注目され、事前学習済みモデルを多様な下流タスクに効果的にファインチューニングできることが示されました。生成AIや大規模言語モデル(GPT-3、GPT-4、Claudeなど)の急激な発展により、業界がドメイン固有用途向けにこうした強力なモデルをカスタマイズする需要が高まり、ファインチューニングの重要性は一層増しています。直近の企業導入データによると、生成AI利用企業の51%が検索拡張生成(RAG)を活用していますが、ファインチューニングも専門的な用途では不可欠な補完手法となっています。LoRA(Low-Rank Adaptation)など**パラメータ効率型ファインチューニング(PEFT)**の進化により、計算コストは最大90%削減され、GPUインフラが限られた組織にもファインチューニングの門戸が開かれています。
ファインチューニングは、モデルのパラメータ(重み・バイアス)を新タスクに最適化するための数学的かつ計算的な仕組みに基づいています。事前学習では、モデルは勾配降下法や逆伝播を通じて膨大なデータセットから一般パターンを学び、幅広い知識の基盤を築きます。ファインチューニングでは、この事前学習済みの重みを初期値とし、より小規模なタスク固有データセットで追加学習を行います。最大の違いは、学習率(各イテレーションでの重み更新量)を大幅に下げて破滅的忘却を防ぐ点にあります。ファインチューニングでは、モデルが訓練データに対して予測を行い誤差を損失関数で算出、逆伝播で勾配を計算し重みを調整する一連の流れが繰り返されます。エポック(訓練データ全体の通過回数)を重ね、検証データで満足いく性能に到達するまで続けます。事前学習済みの重みを活用することで、ゼロから学習する場合に比べ10~100分の1のデータ・計算資源で高精度に収束できるのがファインチューニングの数理的な強みです。
| 観点 | ファインチューニング | 検索拡張生成(RAG) | プロンプトエンジニアリング | フルモデル学習 |
|---|---|---|---|---|
| 知識ソース | モデルパラメータ内に埋め込み | 外部データベース/ナレッジベース | プロンプト内のユーザー文脈 | データからのゼロ学習 |
| データ鮮度 | 再学習まで静的 | リアルタイム/動的 | プロンプト内のみ現時点 | 学習時点で固定 |
| 計算コスト | 学習時高い、推論時低い | 学習時低い、推論時中程度 | 極小 | 極めて高い |
| 実装難易度 | 中~高(ML知識要) | 中(インフラ要) | 低(学習不要) | 非常に高い |
| カスタマイズ深度 | 深い(モデル挙動変化) | 浅い(検索のみ) | 表面的(プロンプトレベル) | 完全(ゼロから) |
| 更新頻度 | 数週間~数ヶ月(再学習要) | リアルタイム(DB更新) | クエリごと(手動) | 頻繁更新は非現実的 |
| 出力一貫性 | 高い(学習パターン) | 可変(検索依存) | 中(プロンプト依存) | データ次第 |
| 出典明示 | なし(重み内に内在) | 完全(文書引用) | 一部(プロンプト表示) | なし |
| スケーラビリティ | ドメインごとに複数モデル | 単一モデル+複数データ | 単一モデル+複数プロンプト | 大規模運用は困難 |
| 最適用途 | 専門タスク・一貫出力 | 最新情報・透明性重視 | 簡易反復・単純タスク | 未知分野・独自要件 |
ファインチューニングは、汎用モデルを専門家モデルへと変貌させる体系的なパイプラインに従います。まずはデータ準備から始まり、組織はタスクに関連する事例を収集・精選します。例えば、法務AIアシスタントなら数千件の法律文書と対応するQ&Aデータ、医療診断ツールなら症例と診断結果のペアが用意されます。データセットの質が最重要であり、研究でも「少量でも高品質なデータ」が「大量でも質の低いデータ」を上回ることが一貫して示されています。準備したデータは訓練・検証・テスト用に分割し、モデルの汎化性能を確認できるようにします。
具体的なファインチューニングは、事前学習済みモデルと重みをメモリにロードするところから始まります。モデル構造は変更せず、重みのみを調整します。各イテレーションでバッチ単位の訓練例を処理し、予測と正解を損失関数で比較、逆伝播で勾配を求め、AdamやSGD(確率的勾配降下法)などの最適化アルゴリズムで重みを更新します。ここでの学習率は事前学習時の10~100分の1程度に抑え、一般知識の損失を防ぎます。複数エポックにわたりこの工程を繰り返し、モデルは徐々にタスク固有データへと特化します。訓練中は検証データで性能を評価し、過学習(訓練例の丸暗記)が起きていないか監視します。検証性能が頭打ち、もしくは劣化し始めたら訓練を終了し、過学習を防ぎます。
フルファインチューニングは全パラメータを更新しますが、大規模モデルでは計算コストが非常に高くなります。数十億パラメータのモデルでは逆伝播時に全パラメータ分の勾配も保持する必要があり、GPUメモリだけで100GB超を要することもあります。リソース制約がある組織には現実的でない場合もありますが、全重みを調整できるため最も高い性能が期待できます。
パラメータ効率型ファインチューニング(PEFT)はこの課題を克服するため、全パラメータの一部だけを更新します。代表的なLoRAは特定層に小さな訓練可能行列を追加し、元の重みは固定したままタスク固有の適応を実現します。研究では、LoRAはフルファインチューニング並みの性能を90%少ないメモリ・3~5倍高速な学習で達成できると示されました。さらにQLoRAは基礎モデルを4ビット量子化し、追加でメモリを75%節約します。他にもアダプタ(小規模のタスク特化層挿入)、プロンプトチューニング(ソフトプロンプト学習)、BitFit(バイアス項のみ更新)などがあり、GPUクラスターのない組織でも最先端モデルのカスタマイズが可能になっています。
LLMのファインチューニングは、画像処理や従来型NLPモデルと異なる特有の考慮点があります。GPT-3やLlamaのような事前学習済みLLMは、膨大なテキストコーパスを用いた自己教師あり学習で次単語予測を学びます。この学習により高い文章生成能力を獲得しますが、ユーザー指示への従順さや意図理解力は自動的には身に付きません。例えば「履歴書の書き方を教えて」と入力しても「Microsoft Wordを使って」と文章を補完するだけで、本質的なガイダンスは得られません。
この限界を克服するためにインストラクションチューニングが用いられ、多様なタスクを網羅する(指示, 応答)型データセットでファインチューニングします。これにより、「~のやり方を教えて」などの命令文に、手順説明などの適切な応答が返せるようになります。この手法は実用的AIアシスタントの実現に不可欠となっています。
さらに進んだ技術として**人間フィードバックによる強化学習(RLHF)**があります。これはラベル付き例だけでなく人間が好む応答を学習することで、「有用さ」「事実性」「ユーモア」「共感性」など明示しにくい品質を最適化できます。プロンプトに対する複数出力を人が評価し、報酬モデルを訓練した後、強化学習でモデルを最適化します。RLHFはChatGPTなどのモデルを人間の価値観・嗜好に合わせる上で重要な役割を果たしています。
ファインチューニングは企業AI戦略の中核となり、独自要件やブランドトーンを反映したカスタマイズモデルの実運用を支えています。Databricks「2024年AI動向レポート」によれば、1万社以上のデータ分析から、AIモデルの実験から本番投入までの効率が16:1から5:1へと3倍向上しています。RAGの利用率は生成AIユーザーの51%に上昇していますが、ファインチューニングは一貫出力・専門性・オフライン運用などで不可欠な手法として活躍し続けています。
金融業界はAI導入で先行し、GPU利用率の高さ・半年間で88%のGPU利用増加が見られますが、その多くは詐欺検出・リスク評価・アルゴリズム取引用モデルのファインチューニングが牽引しています。ヘルスケア・ライフサイエンス分野も意外な先進導入業種で、Pythonライブラリ利用の69%が自然言語処理用途となり、創薬・臨床研究・医療文書分析への応用が進みます。製造・自動車分野はNLP利用が前年比148%増で、品質管理・サプライチェーン最適化・顧客フィードバック分析にファインチューニングモデルが使われています。これらの導入動向から、ファインチューニングが実験段階から本番システムへと移行し、実際のビジネス価値を生み出していることが分かります。
ファインチューニングが依然として注目され続ける背景には、他手法にはない魅力的な利点が多数あります。ドメイン特化の高精度は最大の強みであり、数千件の法律文書でファインチューニングされたモデルは用語だけでなく、法的思考や条項構造、判例まで専門家水準で理解します。この深い専門性により、汎用モデルでは到達できない品質の出力が可能です。効率性の向上も顕著であり、Snorkel AIの研究では、ファインチューニング済みの小型モデルがGPT-3同等の精度を1/1,400のサイズ・1%未満のラベル数・0.1%の本番運用コストで実現しました。これにより限られた予算でも高度なAIを使えるようになります。
トーンや文体のカスタマイズも企業にとって大きな利点で、法務向けならフォーマルに、小売向けなら親しみやすくなど、ブランド一貫性を維持できます。オフライン運用可能性も重要な強みで、ファインチューニング後のモデルは必要な知識を全パラメータ内に保持しているため、外部データ不要でモバイル・組み込み・セキュア環境でも利用可能です。ドメイン特化により幻覚(誤情報生成)も減少し、専門領域での正確性が高まります。
一方で、ファインチューニングには克服すべき課題も多く存在します。データ要件は大きな障壁であり、数百~数千件の高品質ラベル付きデータが必要となり、その収集・クリーニング・アノテーションに数週間~数ヶ月を要します。計算コストも依然高く、大型モデルのフルファインチューニングには高性能GPU/TPUが必要で、1回の学習に数十万円以上かかるケースもあります。パラメータ効率型手法でも、専門知識やハードウェアが必要な点は変わりません。
破滅的忘却も大きなリスクで、法務文書で集中的にファインチューニングしたモデルは契約書分析に特化する一方、それまで得意だった一般タスクが苦手になる場合があります。このため実務では用途ごとに複数モデルを維持する必要が生じます。また、保守負担も大きく、法改正や研究進展・製品更新などドメイン知識が変化するたびに再学習が必須となり、数週間・数万円単位のコストが発生します。変化の速い分野ではモデルの陳腐化リスクも高まります。
出典明示の困難さは信頼性・透明性の課題となり、ファインチューニングモデルは内部パラメータから回答を生成するため、どの情報源に基づいているか検証できません。医療ではどの論文が根拠か、法務ではどの判例か確認できないため、監査証跡や規制遵守が必要な用途には不向きです。過学習リスクも小規模データでは深刻で、訓練例を丸暗記してしまい、初見のケースで性能が低下することがあります。
ファインチューニングを巡る技術動向は進化を続けており、今後も複数の重要トレンドが予想されます。パラメータ効率型手法の更なる進化により、計算コストをさらに抑えつつ高精度を維持できる新技術が続々登場しています。**少量データによるファインチューニング(few-shot)**の研究も進み、データ準備負担の軽減が期待されます。
ファインチューニングとRAGのハイブリッド戦略にも注目が集まり、両者は対立ではなく相補的な関係として、専門性と最新情報取得の両立を目指す運用が増えています。特に規制産業では、両者の長所を組み合わせた本番システムが主流となりつつあります。
連合学習によるファインチューニングも新たな分野で、データを中央集約せず分散環境でモデルを更新できるため、医療・金融など機密性の高い領域のプライバシー課題に対応します。継続学習(Continual Learning)の進展により、モデルが新情報に適応しつつ破滅的忘却を防ぐ仕組みの実装も期待されます。さらにマルチモーダルファインチューニングが進み、テキストだけでなく画像・音声・動画にも対応した多様なカスタマイズが可能となります。
また、AmICitedのようなAIモニタリング基盤との統合も重要な潮流です。ChatGPT・Claude・Perplexity・Google AI Overviews等の各種AIプラットフォームにファインチューニング済みモデルを展開する際、AI生成回答におけるブランド露出や帰属管理が不可欠となっています。ファインチューニング技術とAI監視インフラの融合は、生成AIが実験段階から本格運用フェーズへと成熟する象徴です。
+++
ファインチューニングは転移学習の一種です。転移学習は、あるタスクで得た知識を別のタスクの性能向上に利用するという幅広い概念ですが、ファインチューニングは特に事前学習済みモデルを新たなタスク特化データセットで再学習させるプロセスを指します。転移学習が包括的な概念であるのに対し、ファインチューニングはその具体的な実装方法の1つです。ファインチューニングではラベル付きデータを用いた教師あり学習でモデルの重みを調整しますが、転移学習には再学習を伴わず特徴抽出だけを行う手法なども含まれます。
必要なデータ量はモデル規模やタスクの複雑さによりますが、一般的には数百から数千のラベル付きサンプルが目安です。小規模でも高品質なデータセットは、大規模でも質の低いデータセットより優れた結果を生み出します。研究によると、少量でも高品質なデータは大量の低品質データより価値があります。LoRAのようなパラメータ効率型ファインチューニング手法では、従来よりさらに少ないデータで済む場合もあります。
破滅的忘却は、ファインチューニングによってモデルが事前学習で得た一般知識を失ったり不安定化したりする現象です。これは学習率が高すぎたり、ファインチューニング用データが元の学習データと大きく異なる場合に起こりやすく、重要な学習パターンが上書きされます。これを防ぐためには、ファインチューニング時の学習率を下げたり、正則化などの手法でモデルの基本能力を維持しながら新タスクに適応させる工夫が用いられます。
パラメータ効率型ファインチューニング(PEFT)手法は、全ての重みを更新するのではなく、一部のパラメータのみを更新することで計算負荷を大幅に削減します。LoRA(Low-Rank Adaptation)は特定層に小さな訓練可能行列を追加し、元の重みは固定したまま学習することで、フルファインチューニングと同等の精度を保ちながらメモリや計算資源を約90%削減できます。他にもアダプタやプロンプトチューニング、量子化に基づく手法があり、大規模なGPUリソースがなくてもファインチューニングが可能になりました。
ファインチューニングは知識をモデルパラメータに直接埋め込むのに対し、RAG(検索拡張生成)はクエリ時に外部データベースから情報を取得します。ファインチューニングは専門性の高いタスクや出力フォーマットの一貫性で優れますが、計算資源を多く必要とし情報更新には再学習が必要です。RAGはリアルタイム情報やアップデートの容易さで優れますが、専門性の高い出力には向きません。多くの組織が両者を組み合わせ最適な運用を行っています。
インストラクションチューニングは、ユーザー指示への対応力や多様なタスクへの応答力を高めるための特殊なファインチューニングです。質問応答・要約・翻訳など様々な用途の(指示, 応答)ペアデータセットを用いて学習させます。通常のファインチューニングは単一タスク最適化が中心ですが、インストラクションチューニングは複数の指示タイプを理解し、より柔軟に指示に従う力を養うため、汎用AIアシスタント構築に特に有用です。
はい、ファインチューニング済みモデルはエッジデバイスやオフライン環境にも展開可能であり、これはRAGベースの手法に対する大きな利点の一つです。ファインチューニング後のモデルは必要な知識を全てパラメータ内に保持しているため、外部データアクセスを必要としません。これにより、モバイルアプリや組み込みシステム、インターネット接続のない安全な環境でも利用できますが、リソース制約のあるデバイスではモデルサイズや計算要件に注意が必要です。
ChatGPT、Perplexity、その他のプラットフォームでAIチャットボットがブランドを言及する方法を追跡します。AI存在感を向上させるための実用的なインサイトを取得します。
AIモデルのファインチューニングで、事前学習済みモデルを業界やブランド固有のタスクに適応させ、精度を高めつつコストと計算要件を削減する方法を解説。手法・ユースケース・ベストプラクティスを紹介します。...
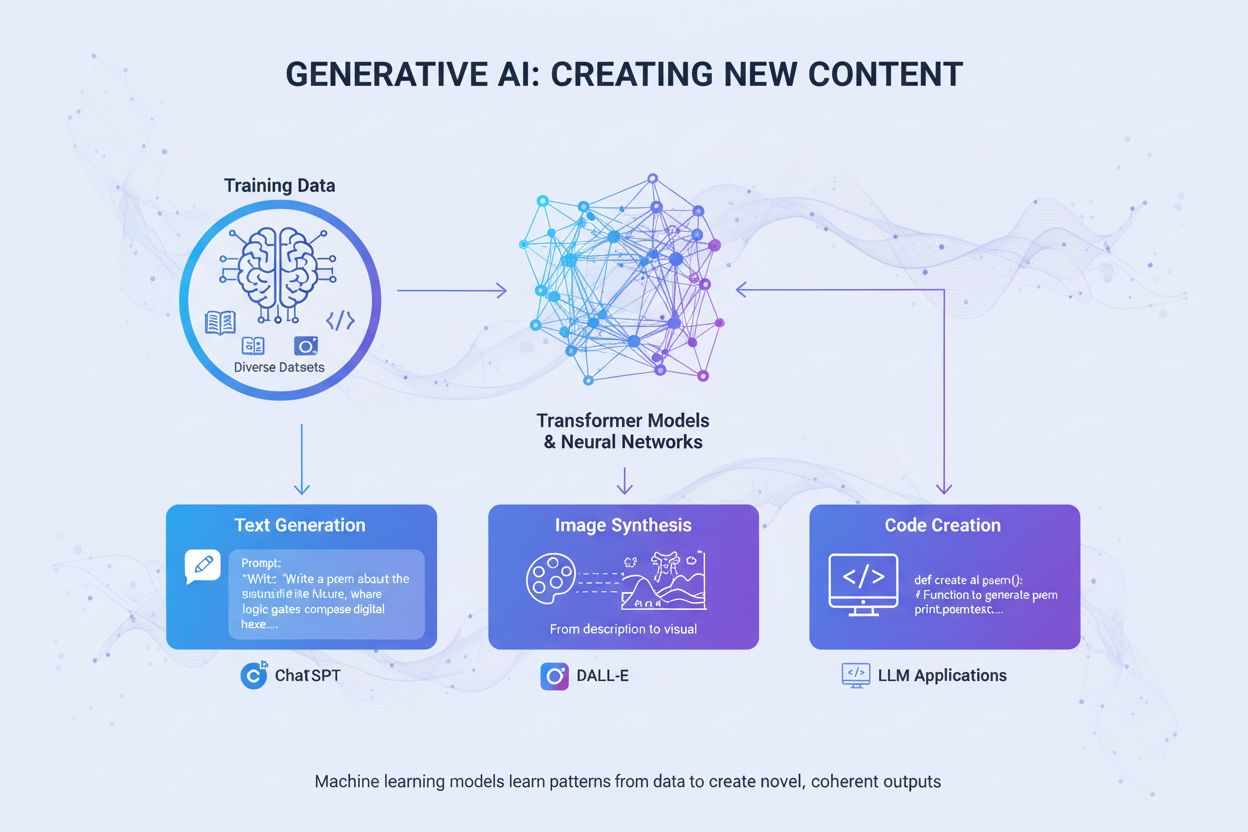
生成AIはニューラルネットワークでトレーニングデータから新しいコンテンツを創出します。仕組みやChatGPT・DALL-Eでの応用、ブランドのAI可視性監視がなぜ重要かを解説。...
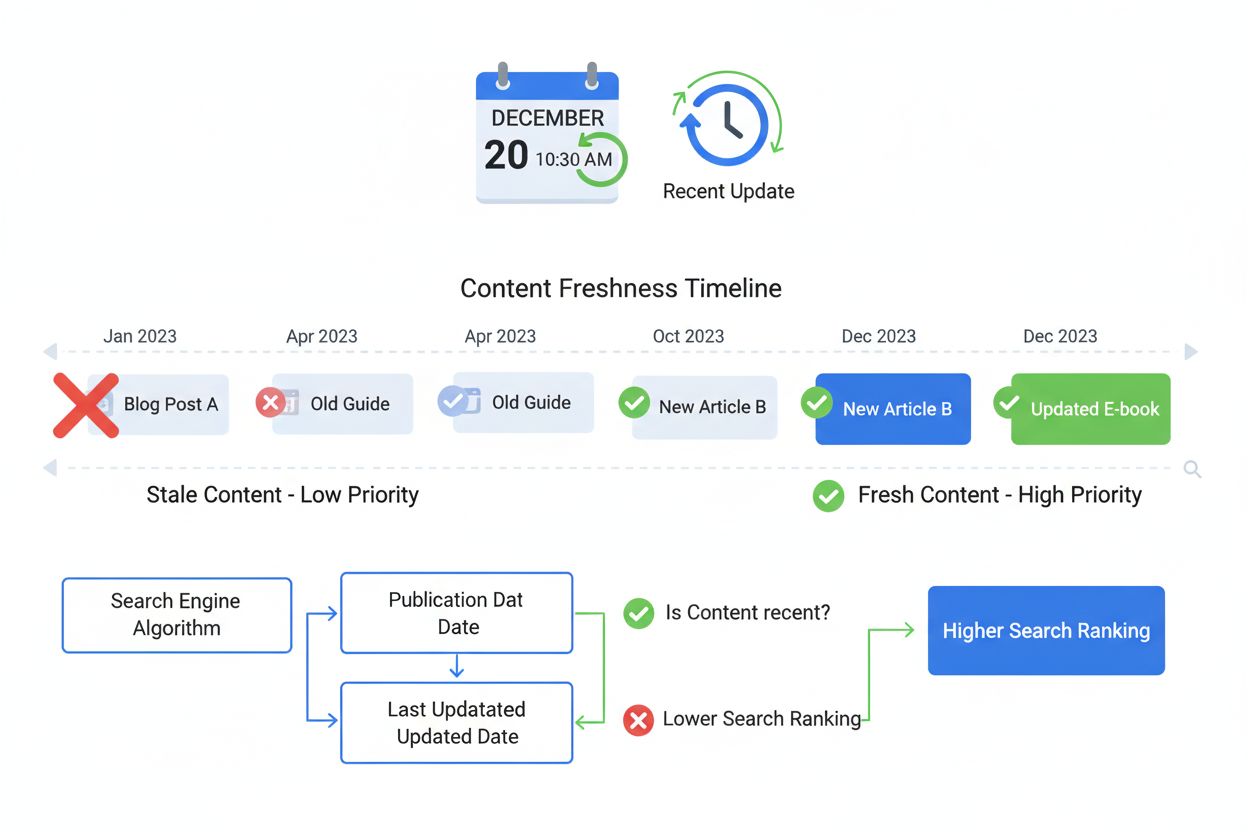
フレッシュネスシグナルは、コンテンツの新しさと更新頻度を測定するランキング要因です。公開日、更新頻度、コンテンツの変更点がSEOやAI検索での可視性にどのように影響するかを解説します。...
クッキーの同意
閲覧体験を向上させ、トラフィックを分析するためにクッキーを使用します。 See our privacy policy.