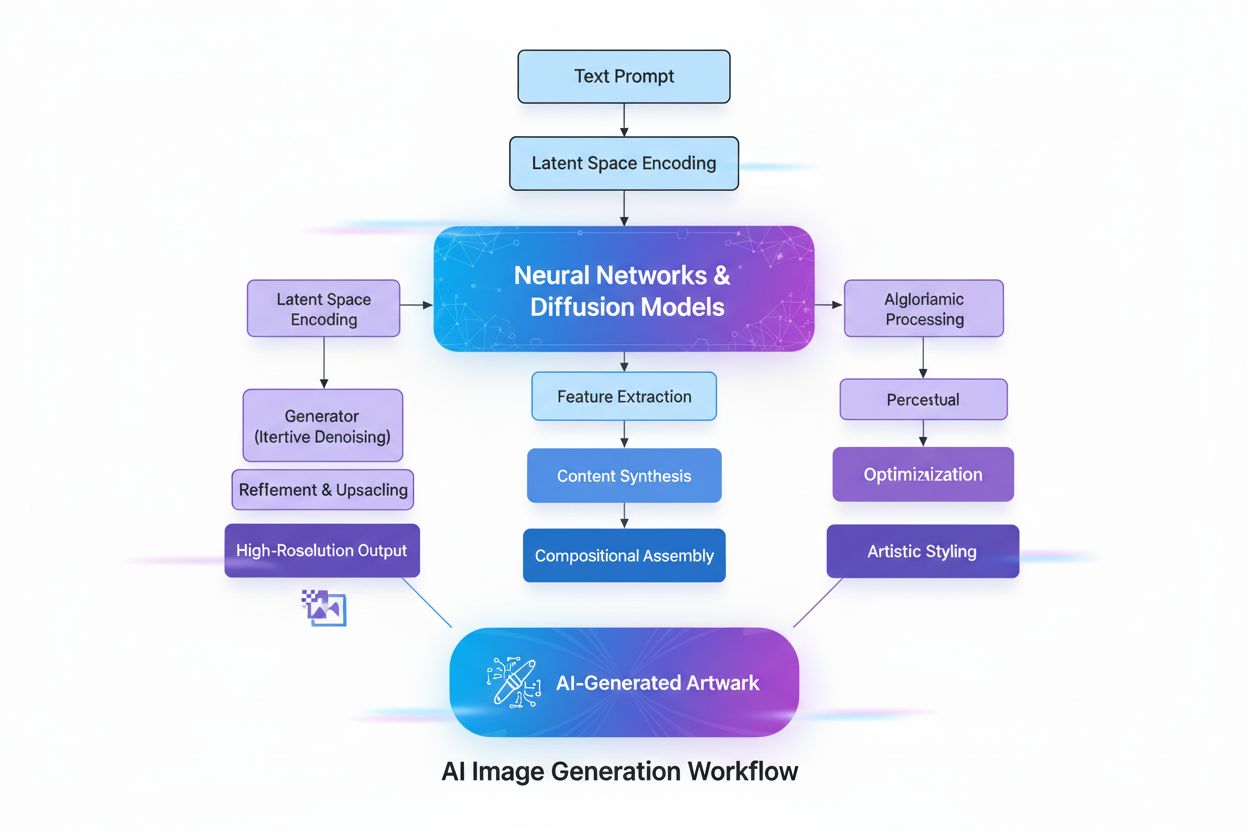
AI生成画像
AI生成画像とは何か、ディフュージョンモデルやニューラルネットワークを使った作成方法、そのマーケティングやデザイン分野での活用、AI画像生成技術を巡る倫理的課題について解説します。...
1 分で読める
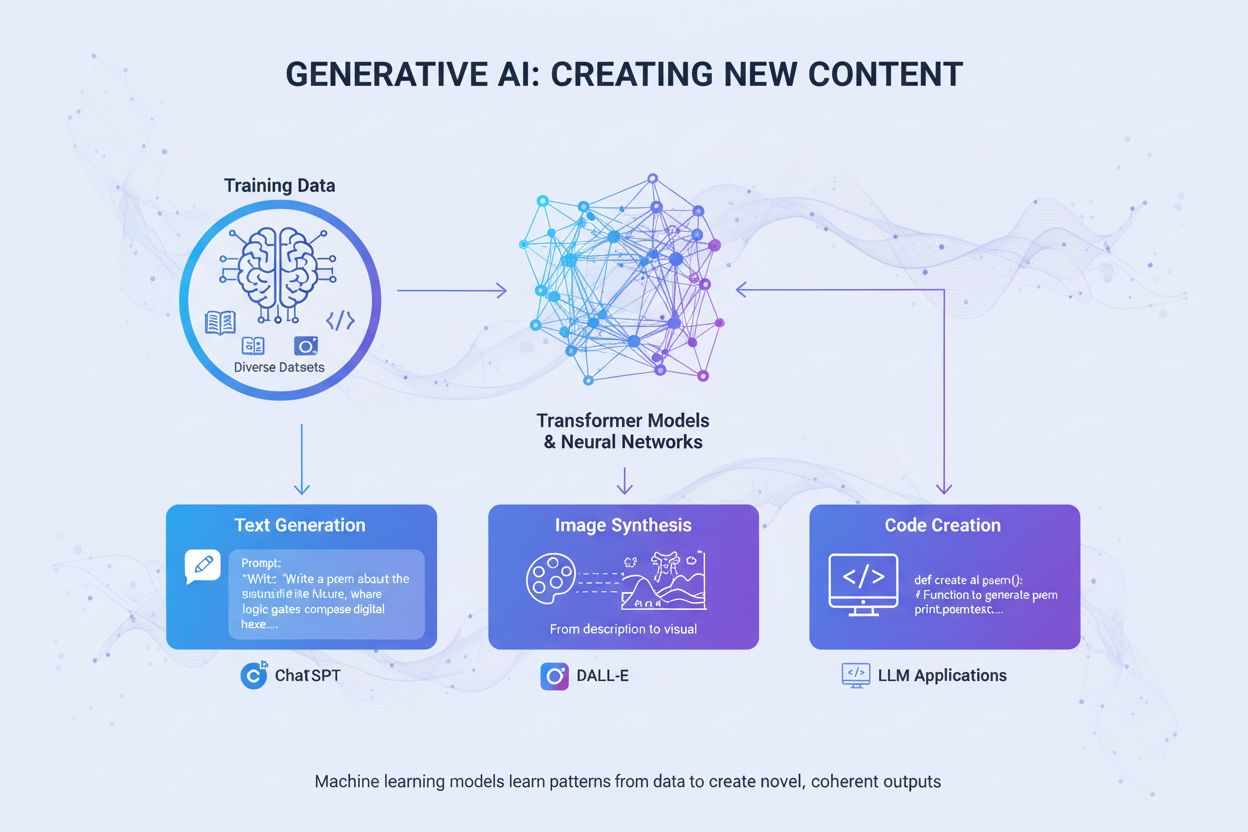
生成AIは、トレーニングデータから学習したパターンに基づき、テキスト、画像、動画、コード、音声などの新しく独創的なコンテンツを生成する人工知能です。トランスフォーマーや拡散モデルのような深層学習モデルを活用し、ユーザーからのプロンプトやリクエストに応じて多様なアウトプットを生み出します。
生成AIは、トレーニングデータから学習したパターンに基づき、テキスト、画像、動画、コード、音声などの新しく独創的なコンテンツを生成する人工知能です。トランスフォーマーや拡散モデルのような深層学習モデルを活用し、ユーザーからのプロンプトやリクエストに応じて多様なアウトプットを生み出します。
生成AIは、トレーニングデータから学んだパターンに基づいて新しく独創的なコンテンツを生成する人工知能の一分野です。従来のAIが情報の分類や予測を主とするのに対し、生成AIモデルはテキスト・画像・動画・音声・コードなど多様なデータをユーザーの指示やリクエストに応じて自律的に生み出します。これらのシステムは高度な深層学習モデルやニューラルネットワークを用いて膨大なデータセットから複雑なパターンや関係性を特定し、学習した知識を活かして、トレーニングデータに似ているが異なる新しいコンテンツを生成します。“generative(生成的)“という言葉は、既存情報の分析や分類だけでなく、新しいものを「生み出す」能力を強調しています。ChatGPTが2022年11月に一般公開されて以来、生成AIはコンピュータ分野で最も変革的な技術の一つとなり、組織のコンテンツ制作・課題解決・意思決定のアプローチをあらゆる業界で根本から変えています。
生成AIの基礎は数十年前に遡りますが、近年その技術は飛躍的に進化しました。20世紀の初期統計モデルはデータ分布理解の土台となりましたが、真の生成AIは2010年代の深層学習やニューラルネットワークの進歩によって生まれました。2013年の変分オートエンコーダー(VAE)の登場は、画像や音声などデータのリアルなバリエーションを生成可能にする画期的な進歩でした。2014年には敵対的生成ネットワーク(GAN)や拡散モデルが登場し、生成コンテンツの品質やリアルさがさらに向上しました。2017年、“Attention is All You Need"という論文でトランスフォーマーアーキテクチャが発表され、生成AIモデルが逐次データを処理・生成する手法を根本から変えました。この革新で、OpenAIのGPTシリーズのような**大規模言語モデル(LLM)**が誕生し、人間の言語を理解・生成する驚異的な能力が示されました。マッキンゼーの調査によれば、2023年時点で3分の1の組織がビジネス機能の少なくとも1つで生成AIを定常的に利用しており、ガートナーは2026年までに80%以上の企業が生成AIアプリケーションやAPIを導入すると予測しています。研究段階からビジネス必需品への急速な普及は、史上最速の技術導入サイクルの一つです。
生成AIは、大量データでのトレーニング、用途に合わせたチューニング、そして生成・評価・再チューニングの繰り返しという多段階プロセスで動作します。トレーニングフェーズでは、膨大な未構造データ(インターネット上のテキストや画像、コードなど)を深層学習アルゴリズムに投入し、アルゴリズムは何百万回もの「空欄埋め」問題をこなし、次に来る要素を予測し誤差を最小化するように自己調整します。この過程で、データ内のパターンやエンティティ、関係性がパラメーターとしてニューラルネットワークに記憶されます。こうして生まれるのがファウンデーションモデル(大規模事前学習モデル)で、様々な分野の複数タスクに対応します。GPT-3、GPT-4、Stable Diffusionなどは多用途なファウンデーションモデルの代表例です。チューニングフェーズでは、特定タスクに合わせてラベル付きデータでファインチューニングしたり、出力内容を人間評価者がスコア付けして精度・関連性を高める**人間フィードバック付き強化学習(RLHF)**が用いられます。開発者やユーザーは出力を継続的に評価し、場合によっては週単位でモデルを更に調整します。**検索拡張生成(RAG)**のような最適化手法では、外部ソースへのアクセス能力をモデルに付与し、常に最新情報に基づいたアウトプットと情報源の透明性を確保します。
| モデルタイプ | 学習アプローチ | 生成速度 | 出力品質 | 多様性 | 最適な用途 |
|---|---|---|---|---|---|
| 拡散モデル | ランダムデータからのノイズ除去反復 | 遅い(多段階反復) | 非常に高い(写実的) | 高い | 画像生成、高精度合成 |
| 敵対的生成ネットワーク(GAN) | 生成器と識別器の競争 | 速い | 高い | やや低い | ドメイン特化生成、スタイル転送 |
| 変分オートエンコーダー(VAE) | 潜在空間付エンコーダ‐デコーダ | 中程度 | 中程度 | 中程度 | データ圧縮、異常検知 |
| トランスフォーマーモデル | 逐次データへの自己注意 | 中~速 | 非常に高い(テキスト/コード) | 非常に高い | 言語生成、コード生成、LLM |
| ハイブリッドアプローチ | 複数アーキテクチャの組み合わせ | 可変 | 非常に高い | 非常に高い | マルチモーダル生成、複雑タスク |
トランスフォーマーアーキテクチャは現代生成AIを支える最重要技術です。トランスフォーマーは自己注意機構を使い、各要素を処理する際に入力データのどの部分が重要かを判断し、長期的な依存関係や文脈を捉えます。位置エンコーディングによって入力要素の順序情報を持たせ、逐次処理なしで系列構造を理解します。この並列処理能力は従来のRNN(再帰型ニューラルネットワーク)よりトレーニングを大幅に高速化しました。エンコーダ‐デコーダ構造と複数のアテンションヘッド層の組み合わせにより、多様な観点からデータを同時に考慮し、層ごとに文脈埋め込み(エンベディング)を洗練させます。これらの埋め込みは文法や構文から複雑な意味まで表現できます。ChatGPT、Claude、Geminiのような大規模言語モデル(LLM)はトランスフォーマー基盤であり、数十億のパラメータ(学習パターンの符号化表現)を持ちます。このスケールとインターネット規模データによる訓練によって、翻訳・要約・クリエイティブライティング・コード生成など多彩なタスクを実現します。拡散モデルも重要なアーキテクチャで、最初にトレーニングデータにノイズを加えてランダム化し、目的の出力が現れるまで段階的にノイズを除去するよう訓練します。拡散モデルはVAEやGANより学習に時間を要しますが、特に高精度な画像生成ツール(DALL-EやStable Diffusion)で出力品質の制御性に優れています。
生成AIはビジネスにおいて、生産性向上やコスト削減など明確な効果をもたらしています。OpenAIの2025年エンタープライズAIレポートによると、生成AIアプリケーション利用者は1日40〜60分の業務時間短縮を報告し、組織全体の生産性向上に寄与しています。生成AI市場は2024年に168.7億ドル、2030年までに1,093.7億ドルへと年平均成長率37.6%で拡大し、エンタープライズソフトウェア史上最速級の成長率となっています。エンタープライズによる生成AI支出は2025年に370億ドル(2024年の115億ドルから3.2倍増)となり、ROIへの信頼感も高まっています。AI購入者のコンバージョン率は47%で、従来SaaSの25%を大きく上回り、生成AIが即効性ある価値をもたらしていることを示します。生成AIは様々な業務で活用されており、カスタマーサービスではAIチャットボットによる個別対応・一次解決、マーケティングではコンテンツ生成によるブログやメール・SNS投稿、ソフトウェア開発ではコード生成ツールによる開発サイクル短縮、リサーチ部門では複雑なデータ解析や新規解決策提案に役立っています。金融業界は詐欺検出や個別アドバイス、医療分野は創薬や画像診断解析などで応用し、業界を問わず業務変革の原動力となっています。
生成AIの用途はほぼ全ての業界・機能に広がっています。テキスト生成では、文書・マーケティングコピー・ブログ記事・論文・創作など文脈に沿った高品質なコンテンツを作成可能です。要約やメタデータ生成など煩雑な業務も自動化し、人間はより創造的な仕事に集中できます。画像生成ツール(DALL-E、Midjourney、Stable Diffusion)はフォトリアルな画像やアート、スタイル転送や画像編集もこなします。動画生成ではテキストプロンプトからアニメーションや特殊効果を迅速に作成可能です。音声・音楽生成は自然な音声でのチャットボットやデジタルアシスタント、オーディオブックのナレーション、プロ顔負けの楽曲制作も実現します。コード生成により、開発者はオリジナルコード記述、スニペットの自動補完、言語間変換やデバッグも効率的に行えます。医療では新規タンパク質や分子構造生成による創薬スピードアップ、合成データ生成は学習データが制限・不足している場合のラベル付きデータ作成に活躍します。自動車分野では3Dシミュレーションや自動運転向け合成データ生成が可能です。メディア・エンタメではアニメ・シナリオ・ゲーム環境・パーソナライズされた推薦コンテンツの生成に活用されています。エネルギー業界では電力網管理や運用最適化、予測にも適用されており、組織の創造・解析・イノベーションの基盤技術となっています。
高い能力を持つ一方で、生成AIには無視できない課題も存在します。AIハルシネーション(もっともらしく見えるが事実無根の出力)は、生成モデルがパターン予測によって次の要素を決めるため、事実確認をしないことが原因です。実際、法律家がChatGPTで判例を調査し、架空の判例や引用を提示された事例もあります。バイアス・公平性の問題は、学習データに社会的偏見が含まれると、不適切・偏った出力を生じます。一貫性のなさは、同じ入力でも異なる出力が返る確率的性質によるもので、カスタマーサービスのように安定回答が求められる場面では課題です。説明性の欠如により、どのようにその出力に至ったかが不明瞭で、開発者自身も「ブラックボックス」モデルの判断根拠を説明できない場合があります。セキュリティ・プライバシーの脅威としては、機密データの学習利用や知的財産の流出・侵害リスクも挙げられます。ディープフェイク(AI生成または操作された画像・音声・動画)はサイバー犯罪・詐欺に悪用され、重大な懸念となっています。計算コストも依然大きく、大規模モデルの訓練には数千台のGPUと数週間、数百万ドルの費用がかかります。こうしたリスクに対しては、信頼できるデータソースへの制限(ガードレール)、継続的な評価とチューニングによるハルシネーション低減、多様なトレーニングデータによるバイアス最小化、プロンプトエンジニアリングで一貫出力を確保、セキュリティ対策による機密保護などが重要です。AI利用の透明性と重要判断への人間関与は引き続き必須のベストプラクティスです。
生成AIが何百万人もの情報源となる今、組織は自社ブランドや製品・コンテンツがAI生成回答でどのように扱われているかを把握する必要があります。AI可視性監視は、ChatGPT、Perplexity、Google AI Overviews、Claudeなど主要生成AIプラットフォームがブランドや競合をどう説明しているかを体系的に追跡します。AIは従来の検索エンジンの可視性指標とは異なり、情報源や引用元を独自に参照するため、この監視が欠かせません。AI回答に現れないブランドは、AI主導の検索環境で露出と影響力の機会を失います。AmICitedのようなツールを使えば、ブランド言及や引用の正確性、AI回答で参照されるドメインやURL、競合ポジショニングの把握も可能です。こうしたデータはAI引用に最適化したコンテンツ設計や誤情報・不正確な記述の特定、AIが主要な情報インターフェースとなる中での競争力維持に役立ちます。**GEO(Generative Engine Optimization)**はAI引用・可視性最適化に特化した取り組みであり、従来のSEO戦略を補完します。AI可視性を積極的に監視・最適化する組織は、新たなAI情報エコシステムで競争優位を築くことができます。
生成AI分野は急速に進化を続け、今後を形作る複数のトレンドがあります。テキスト・画像・動画・音声をシームレスに統合するマルチモーダルAIはより複雑で高度な生成を可能にしつつあります。人の介在なしにタスクを自律遂行するAgentic AI(エージェント型AI)は、生成AIからさらに一歩進み、生成コンテンツを使って外部ツールと連携し意思決定も行います。小型・高効率モデルの登場で、巨大なファウンデーションモデルに代わり、計算コスト・推論速度に優れた生成AIが幅広い組織に導入可能になります。検索拡張生成(RAG)も進化し、外部知識へのアクセスでハルシネーションや正確性の課題に対応しています。世界各国で規制枠組みの整備が進み、責任あるAI開発・運用のガイドラインが策定されています。エンタープライズ向けのファインチューニングやドメイン特化モデルの導入も加速し、各組織が独自の事業文脈に合わせて生成AIを活用し始めています。倫理的AI運用は競争力の源泉ともなり、透明性・公平性・責任ある導入が重視されています。これらが収束することで、生成AIはより効率的かつ身近な存在となり、組織規模を問わず業務に深く組み込まれ、強固なガバナンスや倫理基準の下で展開されていくでしょう。生成AIを理解し、AI可視性を監視し、責任ある運用を実践する組織こそが、この変革技術の価値を最大化しつつリスクを最小限に抑えることができます。
生成AIはデータの分布を学習し新しいアウトプットを創出しますが、識別AIはカテゴリ間の境界を学び分類や予測を行います。GPT-3やDALL-Eのような生成AIは創造的なコンテンツを生み出し、識別モデルは画像認識やスパム検出などに適しています。目的がコンテンツ生成なのかデータ分類なのかによって、両者の使い分けがなされます。
トランスフォーマーモデルは、自己注意機構と位置エンコーディングを用いて、テキストなどの逐次データを順次処理せずに扱います。この構造により、従来モデルよりも長期的な依存関係や文脈を効果的に捉えることができます。一度に系列全体を処理し複雑な関係性を学習できることで、ChatGPTやGPT-4など現代生成AIの基盤となっています。
ファウンデーションモデルは、大量のラベルなしデータで事前学習され、様々な分野の複数タスクをこなせる大規模深層学習モデルです。GPT-3、GPT-4、Stable Diffusionなどがその例で、多様な生成AI用途の基盤となり、個別の目的に合わせて微調整することで、新規開発よりも高い柔軟性とコスト効率を実現します。
ChatGPT、Perplexity、Google AI Overviewsなど生成AIが主要な情報源となる中で、ブランドがAI生成回答にどのように登場するかを把握する必要があります。AI可視性を監視することで、ブランド認知や情報の正確性・競争優位性を維持できます。AmICitedのようなツールを使えば、AIプラットフォーム全体での言及や引用の追跡が可能です。
生成AIは、学習パターンに基づきもっともらしいが事実とは異なる“ハルシネーション”を生じることがあります。また、学習データのバイアスを反映したり、同一入力でも一貫しない出力を生成したり、判断根拠の不透明さも課題です。これらの解決には多様なデータや継続的評価、信頼できるデータソースへの制限などが求められます。
拡散モデルはランダムなデータからノイズを段階的に除去して高品質な出力を生成しますが、生成速度は遅めです。GANは2つのニューラルネットワーク(生成器と識別器)が対抗し合い、素早くリアルなコンテンツを生み出しますが、多様性はやや低めです。画像生成では拡散モデルが高精度を誇り、GANはスピードと品質のバランスが求められる用途に適しています。
生成AI市場は2024年に168.7億米ドル、2030年には1,093.7億米ドルに達すると予測されており、2025~2030年の年間平均成長率(CAGR)は37.6%です。エンタープライズの生成AI支出は2025年に370億ドルとなり、前年比3.2倍(2024年は115億ドル)と産業全体で急速な導入が進んでいます。
責任ある生成AI導入には、まず社内アプリケーションでテストし、AI利用時は明確な説明を行い、不正なデータアクセス防止のセキュリティ対策や多様なシナリオでの十分なテストが不可欠です。さらに、ガバナンス体制を整備し、出力のバイアスや正確性を監視し、重要な判断には人間の関与を維持することが推奨されます。
ChatGPT、Perplexity、その他のプラットフォームでAIチャットボットがブランドを言及する方法を追跡します。AI存在感を向上させるための実用的なインサイトを取得します。
AI生成画像とは何か、ディフュージョンモデルやニューラルネットワークを使った作成方法、そのマーケティングやデザイン分野での活用、AI画像生成技術を巡る倫理的課題について解説します。...

生成エンジンとは何か、従来の検索との違い、ChatGPT・Perplexity・Google AI Overviews・Claudeへの影響までを解説。AI検索の完全ガイド。...
AIコンテンツ生成とは何か、どのように機能するか、その利点と課題、AIプラットフォームの可視性に最適化されたマーケティングコンテンツを作成するためのAIツールのベストプラクティスを学びましょう。...