
Google-Extendedとは何か?その仕組みとブロックすべきかの判断基準
Google-Extendedとは何か、その仕組み、robots.txtでブロックすべきかを解説。AIの学習制御とAI Overviewsの違いも理解できます。...
1 分で読める
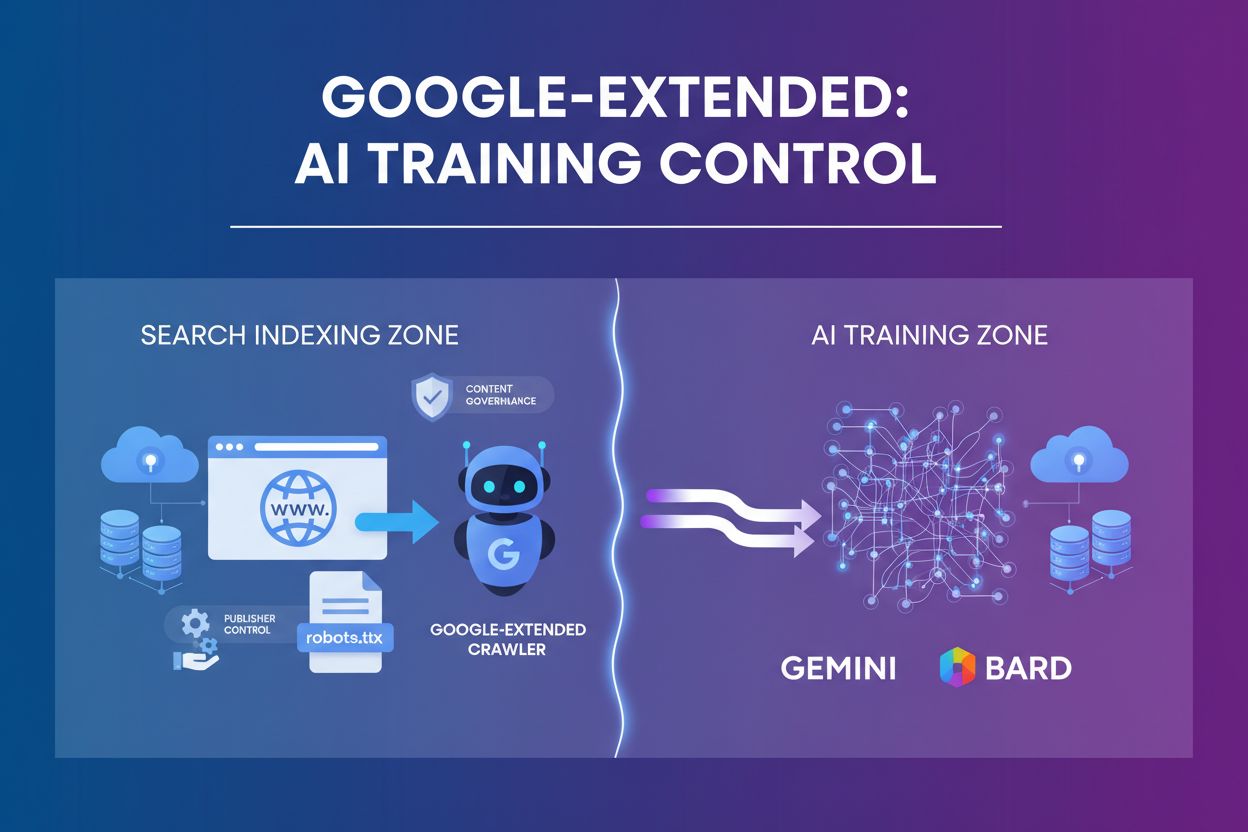
Google-Extendedは、Geminiやその他のGoogle AI製品の向上のためにサイトコンテンツが使用されるかどうかを制御するユーザーエージェントトークンです。標準のGooglebotクロールとは別に機能し、パブリッシャーがrobots.txtを通じてAI学習用アクセスを管理でき、検索上の可視性には影響しません。2023年9月に導入され、AIモデル開発におけるコンテンツ利用に関するパブリッシャーの懸念に対応しています。Google-ExtendedはSEOランキングや検索結果への掲載には影響しません。
Google-Extendedは、Geminiやその他のGoogle AI製品の向上のためにサイトコンテンツが使用されるかどうかを制御するユーザーエージェントトークンです。標準のGooglebotクロールとは別に機能し、パブリッシャーがrobots.txtを通じてAI学習用アクセスを管理でき、検索上の可視性には影響しません。2023年9月に導入され、AIモデル開発におけるコンテンツ利用に関するパブリッシャーの懸念に対応しています。Google-ExtendedはSEOランキングや検索結果への掲載には影響しません。
Google-Extendedは、ウェブサイトのパブリッシャーが自身のコンテンツをGoogleの生成系AIモデル(Gemini、Bard、Vertex AIなど)の学習に利用するかどうかを制御できるユーザーエージェントトークンです。Googlebotがウェブサイトをクロールして検索結果用にコンテンツをインデックス化するのとは異なり、Google-ExtendedはAIモデルの学習や根拠情報収集のためだけに独立してデータを収集します。このユーザーエージェントトークン自体は独立したHTTPクローラーではなく、robots.txtファイル内でパブリッシャーがAI開発に自分のコンテンツをどう関与させるか戦略的判断を行うための制御メカニズムとして機能します。Google-Extendedの導入は、人工知能時代におけるウェブパブリッシャーによる知的財産管理における重要な転換点となります。
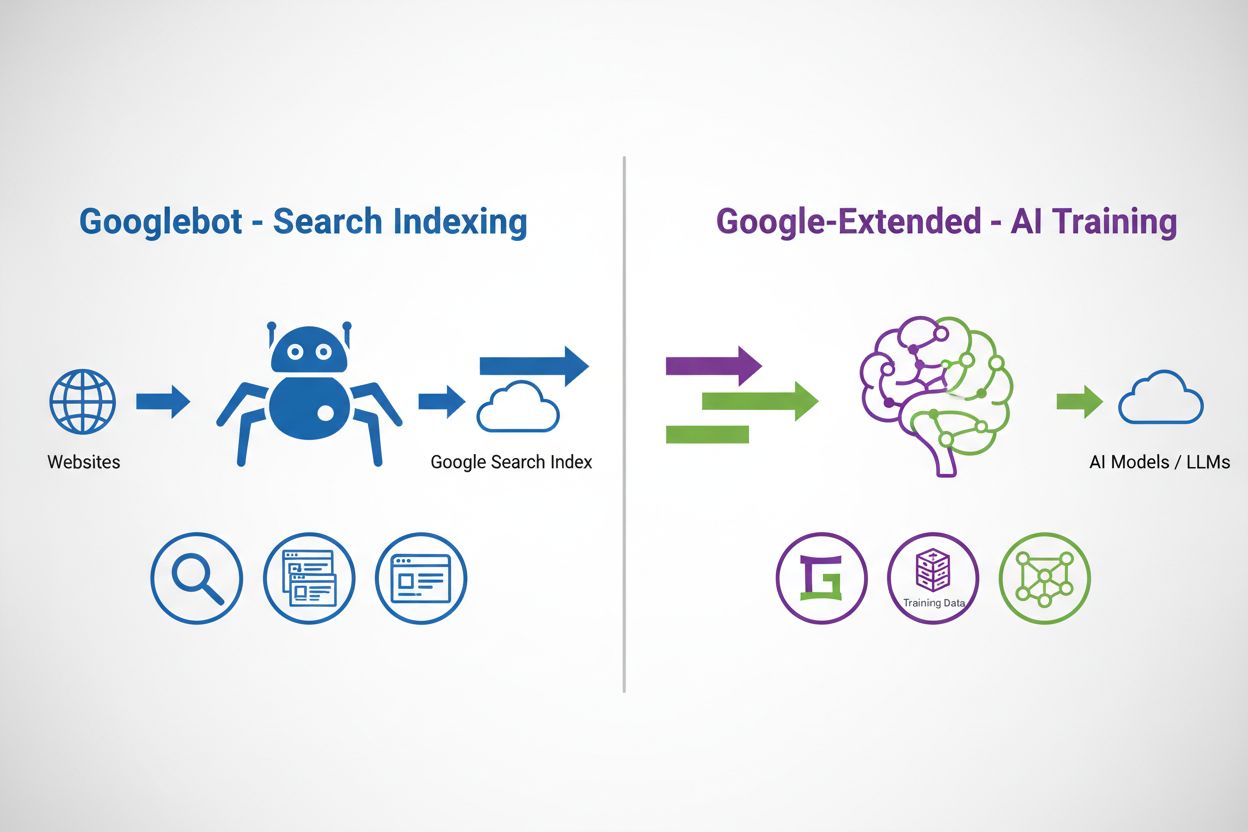
Google-Extendedは、ウェブサイトのルートに設置するプレーンテキストファイルであるrobots.txtプロトコルを通じて動作します。他のGoogleクローラー(GooglebotやGooglebot-Imageなど)とは異なり、Google-Extendedには独自のHTTPリクエストユーザーエージェント文字列はありません。Googleは既存のユーザーエージェント文字列でクロールしますが、robots.txtのユーザーエージェントトークンがAI学習目的用の制御メカニズムとして機能します。robots.txtにGoogle-Extended用のディレクティブを追加することで、サイトのコンテンツが将来のGeminiモデル学習や根拠情報(AI回答精度の向上のためのリアルタイム情報)に使われるかどうかGoogleに指示できます。この分離により、パブリッシャーは検索可視性を維持しつつ、AI学習アクセスを独立して管理できます。
| クローラー | ユーザーエージェントトークン | HTTPリクエスト方式 | 対象プロダクト |
|---|---|---|---|
| Googlebot | Googlebot | 独自ユーザーエージェント | Google検索、画像、ニュース、Discover |
| Googlebot-Image | Googlebot-Image | 独自ユーザーエージェント | Google画像、Discover、動画 |
| Google-Extended | Google-Extended | 既存のGoogleユーザーエージェントを使用 | Geminiアプリ、Vertex AI、根拠情報 |
| Google-CloudVertexBot | Google-CloudVertexBot | 独自ユーザーエージェント | Vertex AIエージェント(サイトオーナー要請時) |
Google-Extendedの最も重要な特徴のひとつは、ウェブサイトの検索エンジンランキングやGoogle検索での可視性に一切影響しないという点です。2025年4月、Googleは公式ドキュメントを明確に更新し、「Google-ExtendedはGoogle検索への掲載やランキングシグナルとしては一切使用されません」と明言しました。つまり、Google-Extendedをブロックしても、オーガニックトラフィックや検索可視性、SEO上のメリットを失う心配はありません。重要なのは、Google-ExtendedのブロックはコンテンツのAI学習・根拠利用だけを防ぎ、Googleの検索アルゴリズムによる評価や掲載順位には一切影響しないということです。これにより、パブリッシャーは自社のビジネスモデルや価値観に基づいて、検索可視性とAI学習参加の二者択一を迫られることなくコンテンツ管理を行えます。
Google-Extendedのコントロールは簡単で、robots.txtファイルに数行追加するだけです。Google-Extendedによるコンテンツアクセスを禁止するには、ウェブサイトのルートに以下のディレクティブを追加してください:
User-agent: Google-Extended
Disallow: /
これにより、GoogleのAI学習クローラーがウェブサイトのどの部分にもアクセスできなくなります。標準の検索クローラー(Googlebotなど)によるインデックスは許可しつつ、AI学習のみをブロックしたい場合、robots.txtは以下のようになります:
User-agent: Google-Extended
Disallow: /
User-agent: Googlebot
Disallow:
User-agent: Bingbot
Disallow:
また、選択的ブロックとして特定のディレクトリやファイルタイプのみを指定することも可能です。たとえば、有料コンテンツだけAI学習から守りたい場合は、次のようにします:
User-agent: Google-Extended
Disallow: /premium/
Disallow: /subscription/
User-agent: Googlebot
Disallow:
この方法により、AIモデル学習への参加部分を細かく制御しながら、ドメイン全体での検索エンジン可視性を維持できます。
AI学習アクセスと検索インデックスの区別を正しく理解することが、Google-Extendedの適切な運用には不可欠です。Google-Extendedを許可すると、あなたのコンテンツはGeminiモデルの学習やAI生成回答の根拠情報として使われる可能性があり、Bardの回答やGeminiアプリ、Vertex AIアプリケーションで表示される場合もあります。Google-Extendedをブロックすると、コンテンツはGoogle検索にしっかりインデックスされ、従来通り検索結果に表示されますが、AI学習データセットやAI回答の根拠としては使われません。以下のような使い分けが考えられます:
このように、両クローラーは独立して動作し、パブリッシャーは自社コンテンツのGoogle製品・サービスにおける利用方法を前例のないレベルで制御できます。
Google-Extendedは、ウェブサイト運営者やジャーナリスト、コンテンツクリエイターによる「自分たちの著作物が明示的な同意や対価なしでAI学習に利用されている」という高まる懸念に応えて導入されました。パブリッシャーは特に著作権所有、コンテンツ帰属、ブランド希釈、競合関係といった問題を提起してきました—AIが自社コンテンツを学習し、最終的に自社の提供価値と競合する可能性があるからです。多くのクリエイターは、自分たちの知的財産が見えない形で収集され、AI開発にどう影響しているのか不透明で、オプトアウト手段もないと感じていました。Google-Extendedはこうした懸念に直接対応し、パブリッシャーが自分のコンテンツをAI学習に参加させるかどうか明確かつドキュメント化された方法で制御できるようにしました。これはGoogleが「コンテンツ制作者には知的財産に対する権限と、AI技術の未来に自分の作品がどう関与するか決定する権利がある」と認めた大きな進展といえます。
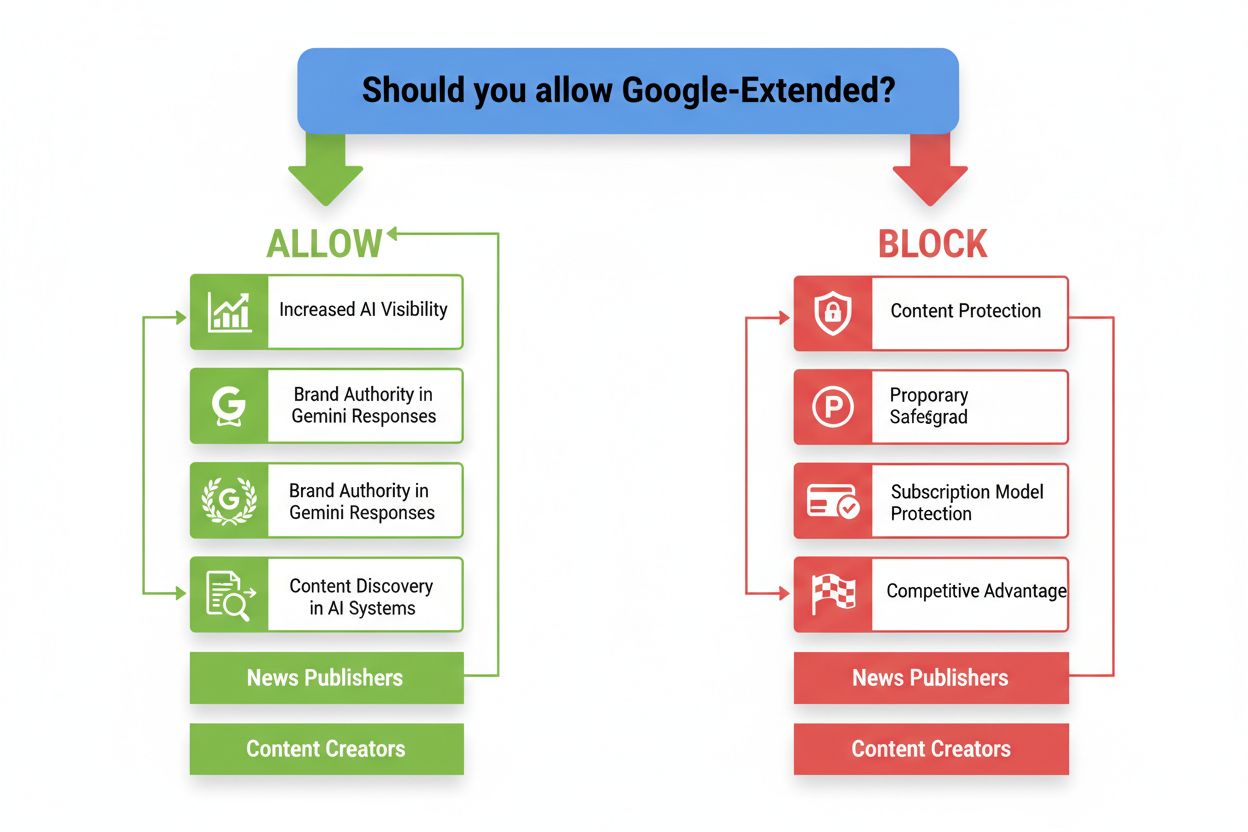
Google-Extendedを許可するかブロックするかの判断は、自社のビジネスモデル、コンテンツ戦略、長期ビジョンに合わせて行うべきです。可視性を最大化し、オピニオンリーダーとしての地位を築きたいコンテンツ制作者や教育者であれば、Google-Extendedを許可することでGeminiの回答やAI生成コンテンツに登場し、ブランド認知や権威性を大きく高められます。ニュースパブリッシャーやサブスクリプション型プラットフォームは、独自コンテンツの保護や競争優位性維持のため、Google-Extendedをブロックすることを慎重に検討すべきです—とくに独自報道へのアクセスがビジネスの根幹である場合です。エンタープライズ向けソフトウェア企業やコンサルティング会社は、一般教育向けコンテンツのみ許可し、独自手法やケーススタディはブロックするハイブリッドアプローチも有効です。戦略的な問いは「AI学習が善か悪か」ではなく、自社コンテンツは幅広いAI露出から利益を得るのか、競争資産として保護すべきなのかです。自社のターゲット、収益モデル、AI生成回答への登場が価値を生むかブランド希釈につながるかをよく検討しましょう。
現時点で、自分のコンテンツがGoogle AIモデルでどのように使われているか正確に把握できる公開ツールは存在しません。Google-Extendedによってアクセス制御はできるものの、実際に自分のコンテンツがAI出力やGemini回答にどう影響しているか、詳細な可視性はパブリッシャー側にありません。この課題により、AmICited.comのようなブランドやコンテンツがAIシステムでどのように参照・引用されているかをトラッキングする高度なモニタリングツールの必要性が高まっています。今後、AIによる帰属表示、コンテンツライセンス、パブリッシャーへの報酬といった業界標準の整備が進むことが予想されます—伝統的なメディアライセンスのような仕組みに近づいていくかもしれません。当面は、ハイブリッドアプローチ:最も重要・独自性の高いコンテンツはGoogle-Extendedをブロック、広く流通させたいコンテンツは許可、さらにサードパーティのモニタリングツールでAI生成コンテンツでのブランドの見え方を追跡するのが推奨されます。AIが検索や情報探索にますます統合されていくなかで、こうしたシステムにおける自社コンテンツの参加を制御・監視する能力は今後ますます重要となるでしょう。
Gemini、Perplexity、Google AI OverviewsなどのAIプラットフォームでのブランド引用をAmICitedで追跡。AIシステムがあなたのコンテンツをどのように参照しているかを把握し、AIでの可視性を測定しましょう。
Google-Extendedとは何か、その仕組み、robots.txtでブロックすべきかを解説。AIの学習制御とAI Overviewsの違いも理解できます。...

robots.txtを使って、どのAIボットがあなたのコンテンツにアクセスできるかをコントロールする方法を学びましょう。GPTBot、ClaudeBot、その他のAIクローラーをブロックするための実践的な例と設定戦略を網羅した完全ガイドです。...

GPTBotやClaudeBotなどのAIクローラーをrobots.txt、サーバーレベルブロック、高度な保護方法でブロックまたは許可する方法を学びます。事例付きの完全な技術ガイド。...