JSON-LD:実装方法とSEO効果の完全ガイド
JSON-LDとは何か、SEOのためにどのように実装するのかを学びます。Google、ChatGPT、Perplexity、AI検索での可視性のための構造化データマークアップの利点を解説します。...
2 分で読める
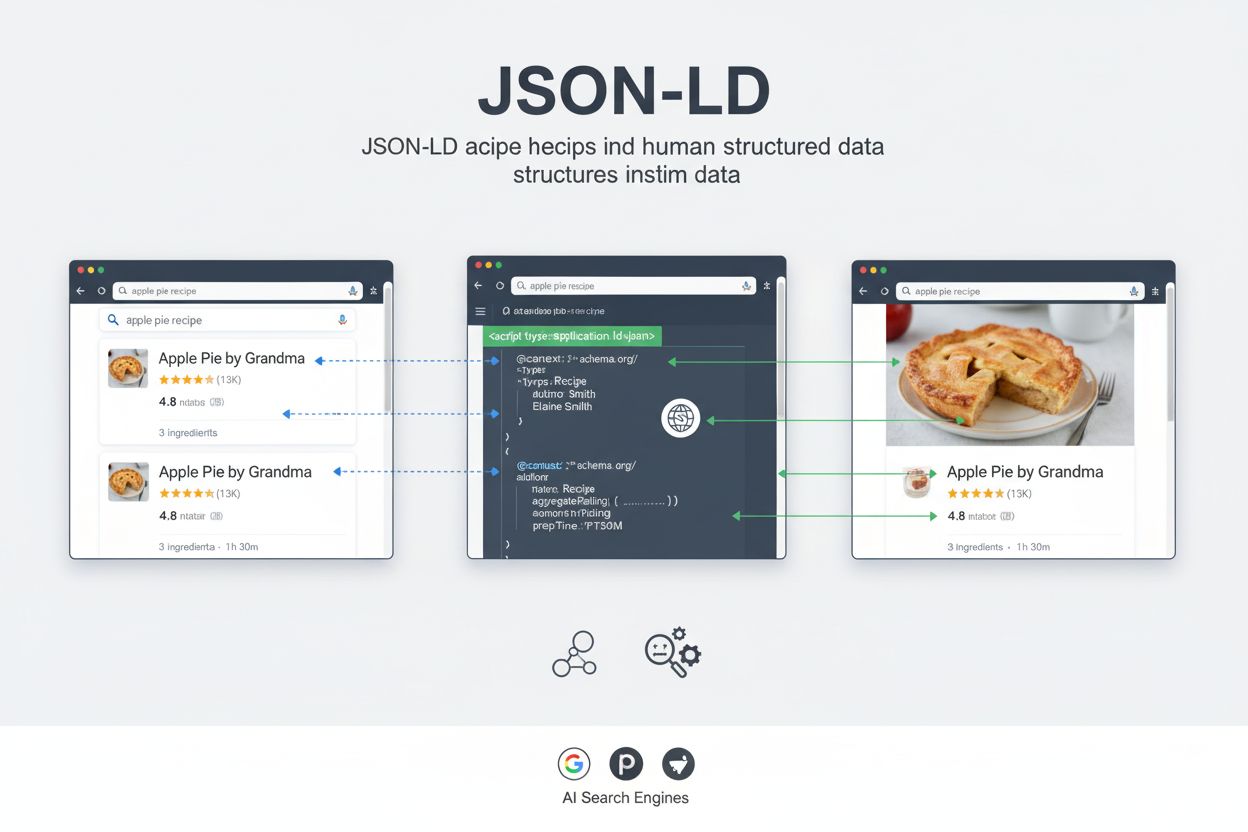
JSON-LD(JavaScript Object Notation for Linked Data)は、JSON構文を用いて構造化データを表現するための軽量でW3C標準化されたフォーマットです。schema.org語彙を通じて検索エンジンやAIシステムがウェブコンテンツを理解できるようにします。JSON-LDはウェブページに機械可読なマークアップとして埋め込まれ、検索エンジンによるリッチリザルトの表示やAIプラットフォーム全体でのコンテンツ発見性向上に役立ちます。
JSON-LD(JavaScript Object Notation for Linked Data)は、JSON構文を用いて構造化データを表現するための軽量でW3C標準化されたフォーマットです。schema.org語彙を通じて検索エンジンやAIシステムがウェブコンテンツを理解できるようにします。JSON-LDはウェブページに機械可読なマークアップとして埋め込まれ、検索エンジンによるリッチリザルトの表示やAIプラットフォーム全体でのコンテンツ発見性向上に役立ちます。
JSON-LDはJavaScript Object Notation for Linked Dataの略であり、ウェブページ上の構造化データを表現するための軽量かつ標準化されたフォーマットです。2014年1月よりW3C勧告として策定され、JSONのシンプルな構文と、特にschema.orgなどのリンクトデータ語彙のセマンティックな力を組み合わせています。他の構造化データフォーマットがHTMLコンテンツとマークアップを混在させるのに対し、JSON-LDはページのヘッダーやボディ内に独立した<script>タグとして埋め込まれ、データとプレゼンテーションマークアップを明確に分離します。この分離により、JSON-LDは大規模なウェブサイトやCMS全体での実装・保守・拡張が非常に容易です。
JSON-LDの主な目的は、検索エンジンやAIシステム、その他のウェブアプリケーションがウェブページ内の意味や関係性を理解できるよう、機械可読なコンテキストを提供することです。正しく実装されたJSON-LDは、検索エンジンがリッチリザルト(評価、価格、画像、イベント詳細などを含む強化検索スニペット)を表示できるようにします。ChatGPT、Perplexity、Google AI Overviews、ClaudeなどのAI検索プラットフォームにとっても、JSON-LDは人間向けコンテンツと機械解釈データの架け橋となり、AI生成の回答や引用の精度・関連性向上に貢献します。
JSON-LDは、Googleや他の主要検索エンジンから推奨されている構造化データフォーマットとなっています。これは、実装ミスを最小限に抑え、JavaScriptフレームワークや動的コンテンツ生成など現代的なウェブ技術とシームレスに連携できるためです。柔軟性の高いフォーマットであり、複雑なネスト構造も表現できるため、単純な商品情報から高度な組織階層やイベント情報まで幅広いコンテンツタイプに適用できます。
JSON-LDは、従来のJSONデータフォーマットとセマンティックウェブ標準を橋渡しする必要性から生まれました。JSON-LD以前、リンクトデータを扱う開発者はRDF/XMLやTurtleといったパワフルだが複雑でウェブ開発に馴染みにくい形式に頼っていました。JSON-LDの開発は2010年代初頭、W3C JSON-LD Community Groupの活動の一環で始まりました。すでにJSONがWeb APIやデータ交換のデファクトスタンダードとなっていたことに対応するものです。このフォーマットは2014年にW3Cで正式標準化され、JSON-LD 1.1が2020年にW3C勧告としてさらなる改良を受けました。
JSON-LDの普及が大きく加速したのは、2013年にGoogleなど主要検索エンジンがschema.orgマークアップの推奨フォーマットとして採用したことが契機でした。この推奨は大きな転換点となり、JSON-LDが単なる学術的な試みにとどまらず、実用的かつ本番環境でのSEOやコンテンツ発見性向上の有力なソリューションであることをウェブ開発の現場に示しました。過去10年でJSON-LDの普及は飛躍的に進み、**現在では全ウェブサイトの41%がJSON-LDによる構造化データマークアップを利用しています(2022年の34%から増加)。構造化データを導入しているウェブサイトに限れば、JSON-LDの利用率は約70%**に達し、構造化データ分野の主流フォーマットとなっています。
JSON-LDの進化は、AI検索エンジンや大規模言語モデルの台頭とも密接に関係しています。ChatGPT、Perplexity、Google AI Overviewsといったプラットフォームが一般化するにつれ、これらのシステムが正確かつ文脈に沿った情報をウェブページから抽出するために構造化データへの依存度が増しています。エンティティの型や関係性、プロパティを明確に定義できるJSON-LDの特性は、AIによるウェブコンテンツの大規模理解・学習に不可欠なものとなっています。
JSON-LDドキュメントは、標準的なJSON構文に準拠しつつ、@記号で始まる特別な予約キーワードがセマンティックな意味を持ちます。最も基本的なキーワードは@context、@type、@idです。@contextプロパティは、通常https://schema.orgとされる語彙の名前空間を指定し、すべてのプロパティや型の意味付けを定義します。これはXMLの名前空間宣言に似た役割を持ち、異なるシステムやプラットフォーム間でプロパティ名の解釈を一貫させるものです。
@typeプロパティは、記述対象のエンティティのスキーマタイプ(Product、Article、Event、Organization、LocalBusinessなど)を指定します。各タイプはschema.orgで定義された関連プロパティ群を持ちます。たとえば、Productタイプならname、description、price、image、aggregateRating、offersなどが含まれます。@idプロパティはエンティティを一意に識別するための識別子であり、通常は詳細情報に解決されるURLが指定されます。
これらの基本キーワードに加え、JSON-LDドキュメントにはschema.org語彙に直接対応したカスタムプロパティが含まれます。これらのプロパティはシンプルな値(文字列、数値、日付)や、関連エンティティを表す複雑なネストオブジェクトを持つこともできます。たとえば、Productエンティティのoffersプロパティには、独自の@typeやprice、priceCurrencyなどのプロパティを持つOfferオブジェクトが埋め込まれる場合があります。このネスト構造により、JSON-LDは他のフラットなフォーマット(Microdataなど)では煩雑になる複雑なデータ関係や階層も自然に表現できます。
| 観点 | JSON-LD | Microdata | RDFa |
|---|---|---|---|
| 実装場所 | <head>や<body>内の独立<script>タグ | HTML属性内に埋め込み | HTML属性内に埋め込み |
| 実装の容易さ | 非常に簡単・HTML変更最小限 | 中程度・HTML属性追加が必要 | 中~複雑・名前空間宣言が必要 |
| 保守の複雑さ | 低・データと表示を分離 | 中・マークアップがコンテンツと混在 | 中~高・複数語彙対応で複雑化 |
| 動的コンテンツ対応 | 優秀・JavaScript注入と相性良い | 限定的・サーバーサイドレンダリング必須 | 限定的・サーバーサイドレンダリング必須 |
| Googleの推奨度 | 推奨 | サポート | サポート |
| 普及率(2024年) | 全ウェブの41%、構造化データサイトの70% | 構造化データサイトの約20% | 構造化データサイトの約15% |
| 語彙の柔軟性 | 1ドキュメント1語彙(多くはschema.org) | 1ドキュメント1語彙 | 複数語彙の併用が可能 |
| ネスト表現力 | 優秀・JSONネイティブ階層 | 良好・itemscope宣言が必要 | 良好・複雑な関係も記述可能 |
| AI検索エンジン対応 | 優秀・ChatGPT, Perplexity, Claude推奨 | 良好・サポートはあるが優先度低 | 良好・サポートはあるが優先度低 |
検索エンジンのクローラーやAIシステムがJSON-LDマークアップを含むウェブページにアクセスすると、<script type="application/ld+json">タグを解析し、構造化データを抽出します。クローラーは@contextで使用されている語彙を把握し、各プロパティをschema.org定義に従って解釈します。この過程により、検索エンジンは自然言語処理や推論に頼らずページの内容を機械的に把握できるのです。
Google検索では、JSON-LDマークアップを利用することで、評価・価格・画像・イベント情報など視覚的要素を含むリッチリザルトが表示されます。たとえば、商品ページに正しくJSON-LDが実装されていれば、商品名・価格・在庫状況・レビュー・画像などが構造化データから直接抽出され、クリック率の高いリッチリザルトが検索結果に表示されます。大手サイトの調査では、Rotten Tomatoesは構造化データ強化ページでクリック率25%向上、ネスレはリッチリザルト表示ページでクリック率82%向上を実現しています。
Perplexity、ChatGPT、Google AI OverviewsなどのAI検索エンジンでは、JSON-LDは異なるが同様に重要な役割を果たします。これらのシステムは構造化データを利用してコンテンツの意味や、主要エンティティ・関係性を理解し、AI生成の回答に正確な情報を組み込みます。AIがJSON-LDマークアップを識別できれば、どのようなエンティティか・どんな属性があるか・どう他エンティティと関係しているかを明確に把握でき、より正確で文脈に即した回答や引用が可能となります。
JSON-LDを効果的に実装するには、いくつかの重要な原則やベストプラクティスを理解する必要があります。まず、JSON-LDはHTMLドキュメントの<head>セクションに配置するのが推奨されます(<body>でも可)。<head>内配置は、ページコンテンツより先に構造化データがパースされるため最適ですが、現代の検索エンジンやAIはページ内どこでもJSON-LDを認識できます。
次に、@contextは必ず明示的に定義しましょう(通常は"@context": "https://schema.org")。これにより、すべてのプロパティや型がschema.org定義として解釈されます。技術的には複数コンテキストやカスタム語彙も利用可能ですが、実際のウェブ実装の大多数はschema.orgのみを使用しています。
また、JSON-LDマークアップはページの可視コンテンツと正確に対応させる必要があります。検索エンジンやAIは、構造化データがユーザーに表示される内容と一致することを期待しています。ユーザーに見えない情報や矛盾する内容をJSON-LDでマークアップすると、ペナルティや無視の対象となる場合があります。これは検索エンジンとの信頼関係やAIによる正確な引用のために非常に重要です。
さらに、選択したスキーマタイプの必須プロパティは必ず含めましょう。schema.orgには多くのオプションがありますが、必須項目が揃っていないと検索エンジンが正しくバリデーションできず、リッチリザルト表示の対象外となります。例えば、Productスキーマでは最低でもname、description、offersが必要です。
最後に、GoogleリッチリザルトテストやSchema.orgバリデータなどのツールで、公開前にマークアップを必ず検証しましょう。これらのツールは構文エラーや必須プロパティ不足などの問題をチェックし、安心して本番導入できます。
JSON-LDによる構造化データ実装は、さまざまな観点で測定可能なメリットをもたらします。SEO面では、JSON-LDがリッチリザルトを可能にし、クリック率を大幅に向上させます。Food Networkはページの80%を構造化データ化し、訪問数が35%増加。楽天は構造化データ導入ページで滞在時間が1.5倍、AMPページの検索機能利用時にはインタラクション率が3.6倍になったと報告しています。
AI検索可視性の観点では、JSON-LDの重要性はさらに高まっています。構造化データを導入したサイトは、AI検索エンジンによる正確な理解・引用・フィーチャーの可能性が高まります。特にAmICitedユーザーにとっては、ChatGPT、Perplexity、Google AI Overviews、Claudeなど複数AIプラットフォームで自社ブランド・ドメイン・URLがどのようにAI検索結果に現れているかをモニタリングする上で、JSON-LDによる信頼できるコンテキスト提供が不可欠です。
技術的観点でも、JSON-LDは実装・保守の負荷を軽減します。マークアップがHTMLコンテンツと分離されているため、レイアウト変更があっても構造化データを独立して管理できます。これは大規模なCMSを持ち、複数チームが運用する組織にとって特に大きな価値があります。
ユーザー体験の面でも、JSON-LDは間接的にエンゲージメント向上に貢献します。評価・価格・画像などリッチな情報が検索結果に表示されることで、クリック率やコンバージョン率が高まります。
JSON-LDは現代的なウェブ開発技術や手法とシームレスに統合されます。MicrodataやRDFaがサーバーサイドレンダリングを前提とするのに対し、JSON-LDはJavaScriptで動的にページへ挿入可能です。これはSPA(シングルページアプリケーション)、PWA(プログレッシブウェブアプリ)、その他JavaScript主導の動的ウェブサイトで特に重要です。
WordPress、Shopify、Wix、DrupalなどのCMSも、JSON-LD生成を標準またはプラグインでサポートするケースが増えています。これにより、非技術者でもコードを書かずに構造化データを導入できるようになりました。多くのCMSはページメタデータやコンテンツに基づき自動的にJSON-LDマークアップを生成し、開発者やコンテンツ制作者の負担を軽減します。
ヘッドレスCMSのように、コンテンツとプレゼンテーションを分離したアーキテクチャにもJSON-LDは適します。サーバーサイドで生成・ページレスポンスに組み込むことも、ReactやVue、AngularなどのJavaScriptフレームワークでクライアントサイド生成することも可能です。この柔軟性により、JSON-LDはほぼあらゆる現代的Webアーキテクチャで活用できます。
https://schema.orgで明示し、語彙解釈の一貫性を保つJSON-LDの今後の重要性はさらに高まる見通しです。AI検索エンジンや大規模言語モデルが高度化するほど、高品質で機械可読な構造化データの需要は拡大します。検索エンジンやAIは、リッチリザルト表示目的だけでなく、理解・ランキングアルゴリズムの中核要素として構造化データを活用し始めています。
JSON-LD-star(より複雑な知識グラフ関係に対応)やCBOR-LD(JSON-LDデータのよりコンパクトなバイナリ表現)などの新拡張も登場しており、JSON-LDエコシステムは今後もウェブアプリケーションやAIの進化に対応し続けるでしょう。
AI検索エンジンの台頭は、構造化データの使われ方にパラダイムシフトをもたらします。従来の検索エンジンは主にリッチリザルト生成のために構造化データを利用していましたが、AI検索エンジンは「理解・推論」のための基礎入力として活用します。したがって、JSON-LDを効果的に実装したウェブサイトは、AI検索での可視性や引用頻度で大きなアドバンテージを得られます。
さらに、プライバシーやデータガバナンスへの関心が高まる中、JSON-LDはデータの出所・ライセンス・利用権の表現にも役立つ可能性があります。柔軟かつ拡張性の高いフォーマットゆえ、データソースや利用制限に関するメタデータも記述可能であり、今後AIによるデータ利用管理が重要性を増す中でますます重要となるでしょう。
AmICitedのようなプラットフォームでAI検索結果のブランド表示モニタリングを行う組織にとっても、包括的なJSON-LDマークアップ導入は戦略的な投資です。AIシステムに自社コンテンツの明確な構造化コンテキストを提供することで、ブランドやドメイン、URLがAI生成回答で正確に理解・引用・フィーチャーされる確率が高まります。AI検索の重要性が増す今後、JSON-LDは包括的なSEO・コンテンツ可視化戦略の不可欠な要素となるでしょう。
JSON-LDとMicrodataはいずれも構造化データフォーマットですが、実装方法が異なります。JSON-LDは別の<script>タグ内に埋め込まれ、HTMLコンテンツと混在しないため、大規模運用やメンテナンスが容易です。MicrodataはHTML属性をページコンテンツ内に直接追加します。Googleは、ユーザーエラーが起こりにくく、JavaScriptフレームワークやCMSによる動的コンテンツともシームレスに動作するため、多くの実装においてJSON-LDを推奨しています。
JSON-LDは検索エンジンがページ内容をよりよく理解できるようにし、リッチリザルト(評価、価格、画像などの構造化情報を含む強化表示)を実現します。構造化データをマークアップしたページは、クリック率が有意に高くなることが研究で示されています。例えば、ネスレはリッチリザルト表示ページでクリック率が非リッチページより82%高いことを測定し、JSON-LDが検索パフォーマンスとユーザーエンゲージメントに直接影響することを実証しました。
JSON-LDの@contextは、マークアップで使用されるプロパティや型の意味を定義する語彙の名前空間(通常はschema.org)を指定します。これはXMLの名前空間のような役割を果たし、検索エンジンやAIシステムにデータの解釈方法を伝えます。例えば、@context: 'https://schema.org'は、@typeの'Product'や'Article'がschema.org定義を指していることをパーサーに伝え、異なるプラットフォームやシステム間で一貫した解釈を保証します。
はい、JSON-LDによる構造化データはAI検索エンジンにとってますます重要になっています。ChatGPT、Perplexity、Google AI Overviewsのようなプラットフォームは、ウェブページから情報をよりよく理解・抽出するために構造化データを利用しています。JSON-LDは機械可読なコンテキストを提供し、AIシステムが主要なエンティティや関係、コンテンツタイプを特定しやすくし、あなたのコンテンツがAI生成の回答や引用に取り上げられる可能性を高めます。
主なJSON-LDプロパティには@context(語彙の定義)、@type(ProductやArticleなどスキーマタイプの指定)、@id(エンティティの一意の識別子)、およびスキーマタイプに応じたカスタムプロパティがあります。Productスキーマの場合、name、description、price、image、aggregateRatingなどを含めることができます。各プロパティはschema.orgの定義と対応しており、検索エンジンがあなたのコンテンツに関する具体的な情報を抽出・理解できます。
JSON-LDの普及は大きく進み、2024年には全ウェブサイトの41%、2022年の34%から増加しました。構造化データマークアップを利用しているウェブサイトの中では、JSON-LDが最も広く採用されており、全体の約70%が使用しています。これはGoogleが推奨フォーマットとしてJSON-LDを掲げ、他の形式(MicrodataやRDFa)と比べて実装が容易であることが普及に寄与しています。
JSON-LDにはRDFaに対する複数の利点があります。実装とメンテナンスが容易で、HTMLコンテンツと混在させる必要がなく、JavaScript生成コンテンツともシームレスに動作し、エラーも起こりにくいです。RDFaは複数の語彙を組み合わせて複雑な要件に対応できますが、JSON-LDはシンプルであり、Googleの明確な推奨もあって、検索可視性やAIによる発見性を目指す多くのウェブサイトで最適な選択肢となっています。
ChatGPT、Perplexity、その他のプラットフォームでAIチャットボットがブランドを言及する方法を追跡します。AI存在感を向上させるための実用的なインサイトを取得します。
JSON-LDとは何か、SEOのためにどのように実装するのかを学びます。Google、ChatGPT、Perplexity、AI検索での可視性のための構造化データマークアップの利点を解説します。...
AI検索での可視性向上のためのJSON-LD実装に関するコミュニティディスカッション。開発者やSEO担当者が、構造化データがAIの引用やベストプラクティスにどう影響するかを共有します。...
構造化データは、検索エンジンがウェブページの内容を理解するための標準化マークアップです。JSON-LD、schema.org、マイクロデータがSEO、リッチリザルト、AIでの可視性をどう高めるのかを学びましょう。...
クッキーの同意
閲覧体験を向上させ、トラフィックを分析するためにクッキーを使用します。 See our privacy policy.