
ナレッジグラフとは?なぜ重要なのか | AIモニタリングFAQ
ナレッジグラフとは何か、その仕組み、そして現代のデータ管理・AI応用・ビジネスインテリジェンスに不可欠な理由を解説します。...
1 分で読める
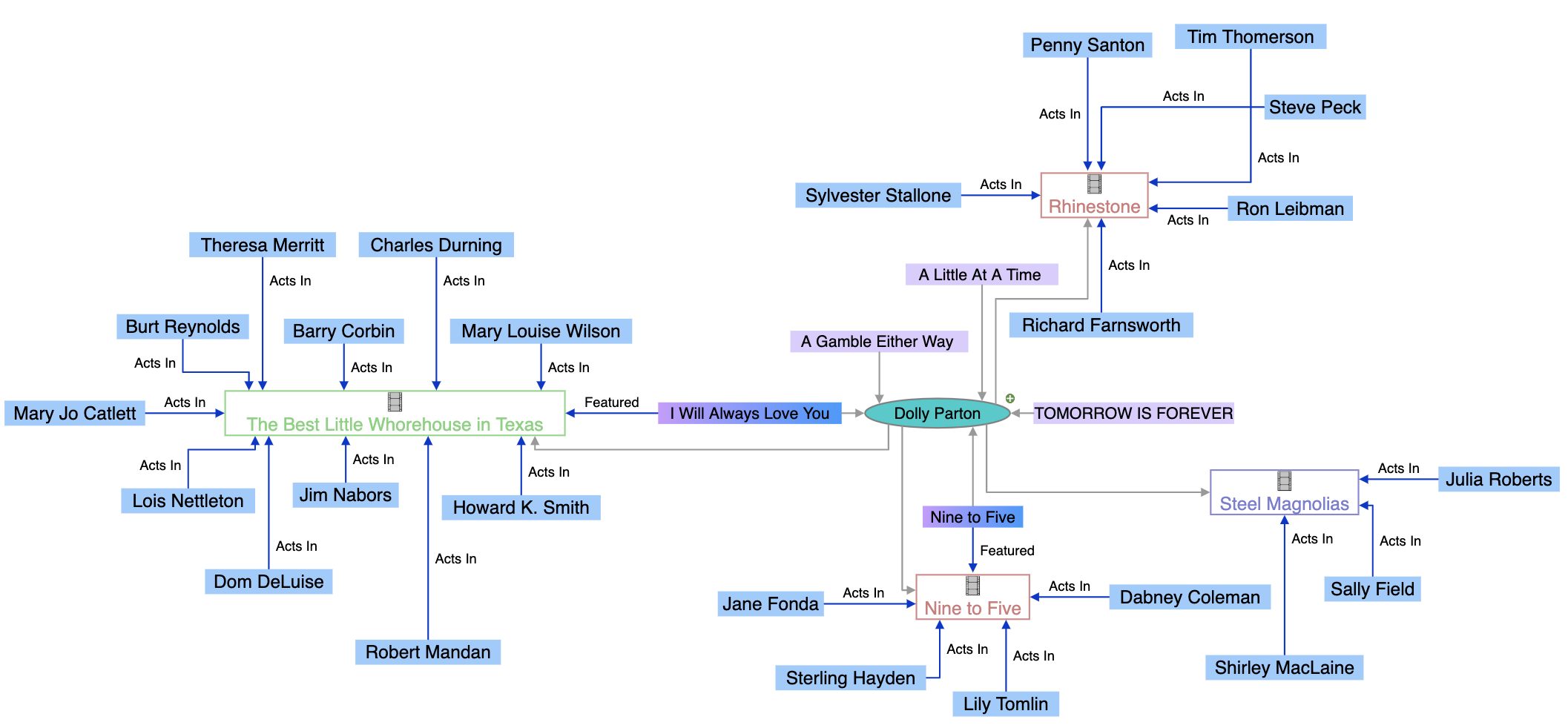
ナレッジグラフは、人物、場所、組織、概念などの実世界のエンティティを表現し、それらの意味的な関係を示す相互接続された情報のデータベースです。Googleのような検索エンジンは、ユーザーの意図を理解し、より関連性の高い検索結果を提供し、ナレッジパネルやAI概要などのAI機能を強化するためにナレッジグラフを利用しています。
ナレッジグラフは、人物、場所、組織、概念などの実世界のエンティティを表現し、それらの意味的な関係を示す相互接続された情報のデータベースです。Googleのような検索エンジンは、ユーザーの意図を理解し、より関連性の高い検索結果を提供し、ナレッジパネルやAI概要などのAI機能を強化するためにナレッジグラフを利用しています。
ナレッジグラフとは、人物、場所、組織、概念などの実世界のエンティティを表現し、それらの意味的な関係を示す相互接続された情報のデータベースです。従来のデータベースが情報を堅固な表形式で整理するのに対し、ナレッジグラフはノード(エンティティ)とエッジ(関係)のネットワークとしてデータを構造化し、システムが単なるキーワード一致ではなく意味や文脈を理解できるようにします。2012年に登場したGoogleのナレッジグラフは、エンティティベースの理解を検索に導入し、「エッフェル塔の高さは?」や「2016年夏季オリンピックはどこで開催された?」といった事実質問に、ユーザーがどんな情報を求めているかを理解して答えることを可能にし、検索を革新しました。2024年5月時点でGoogleのナレッジグラフは540億のエンティティに関する1.6兆以上のファクトを保有しており、2020年の50億エンティティ・5000億ファクトから大幅に拡大しています。この成長は、現代の検索、AIシステム、インテリジェントアプリケーションを支える構造化・セマンティックナレッジの重要性の高まりを示しています。
ナレッジグラフの概念は、人工知能、セマンティックウェブ技術、ナレッジ表現に関する数十年にわたる研究から生まれました。しかし、Googleが2012年にナレッジグラフを導入したことで、その名称が世界的に広まり、検索エンジンの結果提供のあり方が根本的に変わりました。ナレッジグラフ登場以前は、検索エンジンは主にキーワード一致方式を採用しており、たとえば「seal」で検索すると、その単語のあらゆる意味(アザラシ、歌手、軍隊、封印など)に関連する結果が表示され、ユーザーが本当に知りたいエンティティを理解することはできませんでした。ナレッジグラフはオントロジー(エンティティ・属性・関係を定義する形式的枠組み)の原理を大規模に適用することで、このパラダイムを変革しました。「ストリングからシングスへ」という転換は、検索技術の根本的な進化であり、アルゴリズムが「seal=アザラシ/歌手/部隊/封印」のどれを指すのか文脈から判断できるようになりました。ナレッジグラフ市場もこの重要性を反映し、2024年の14.9億ドルから2030年には69.4億ドルに成長すると予測されており、年平均成長率は約35%です。金融、医療、小売、サプライチェーン管理など多様な分野で、エンティティの関係性理解が意思決定・不正検出・業務効率化に不可欠だと認識され、企業による導入が急速に進んでいます。
ナレッジグラフは、高度なデータ構造、セマンティック技術、機械学習アルゴリズムを組み合わせて動作します。基本となるのは、グラフ構造化データモデルで、ノード(人・組織・概念などのエンティティ)、エッジ(エンティティ間の関係)、ラベル(関係の種類を表す)の3要素から成ります。例えばシンプルなナレッジグラフでは、「Seal」がノード、「is-a」がエッジラベル、「Recording Artist」が別のノードとなり、「Sealはレコーディングアーティストである」という意味的関係を作ります。この構造は、あらかじめ定義されたスキーマで行・列にデータを詰め込むリレーショナルデータベースとは根本的に異なります。ナレッジグラフは、ノードやエッジにプロパティを直接持たせるラベル付きプロパティグラフ型、またはあらゆる情報を主語-述語-目的語(トリプル)で表すRDF(Resource Description Framework)トリプルストア型で構築されます。最大の強みは、異なる構造や形式を持つ複数のソースからデータを統合できる点です。データ取り込み時には、セマンティック・エンリッチメント処理として自然言語処理(NLP)や機械学習が活用され、エンティティの抽出・関係性の特定・文脈の理解が行われます。これにより「IBM」「International Business Machines」「Big Blue」が全て同一エンティティであることや、「Watson」「Cloud Computing」「人工知能」との関係も自動的に認識できます。こうした相互接続構造により、従来型データベースでは不可能な複雑なクエリや推論が可能となり、関係性のたどりや既存情報から新たな知識を導き出すことができます。
| 項目 | ナレッジグラフ | 従来型リレーショナルデータベース | グラフデータベース |
|---|---|---|---|
| データ構造 | エンティティと関係を表すノード・エッジ・ラベル | 事前定義スキーマのテーブル・行・列 | 関係探索最適化のノードとエッジ |
| スキーマ柔軟性 | 新情報追加に応じて柔軟に進化 | 事前のスキーマ定義が必要で堅固 | 動的スキーマ進化に対応し柔軟 |
| 関係性処理 | 複雑な多段階関係をネイティブにサポート | 複数テーブル間の結合が必要で計算コスト大 | 関係性クエリを効率的に最適化 |
| クエリ言語 | SPARQL(RDF向け)、Cypher(プロパティグラフ向け)、カスタムAPI | SQL | Cypher、Gremlin、SPARQLなど |
| 意味理解 | オントロジー活用で意味や文脈を重視 | データ保存・取得が中心 | 効率的なトラバーサルとパターンマッチング重視 |
| 用途 | セマンティック検索、知識発見、AIシステム、エンティティ解決 | ビジネストランザクション、帳票、OLTPシステム | レコメンデーション、不正検出、ネットワーク解析 |
| データ統合 | 異種データの統合に優れる | ETL・データ変換が多大に必要 | 関連データには強いが意味付けは限定的 |
| スケーラビリティ | 数十億エンティティ・数兆ファクトまで拡張可能 | 構造化トランザクションデータに強い | 関係性重視のクエリで高い拡張性 |
| 推論機能 | オントロジーで高度な推論・知識導出 | 限定的・明示的プログラミングが必要 | 限定的・パターンマッチング中心 |
ナレッジグラフは、情報が検索結果やAI生成回答にどのように表示されるかを根本的に左右するため、現代SEOやAI可視性戦略の中心的存在となっています。Googleが検索クエリを処理する際、最初に実行する主要タスクのひとつがユーザーが探しているエンティティの特定であり、その後ナレッジグラフから関連情報を取得してSERP機能を構成します。このエンティティベースアプローチは、単なるキーワード一致を超えて意味や文脈を理解するセマンティック検索の発展につながりました。ナレッジグラフは、クリック率やブランド可視性に直結する多くのSERP機能を支えています。ナレッジパネルは、デスクトップやモバイルの検索結果で目立つ位置に表示され、エンティティに関する厳選された事実をナレッジグラフから引用して示します。AI概要(旧Search Generative Experience)は、ナレッジグラフの関係性で特定された複数情報源から内容を統合し、従来のオーガニックリストをさらに下げるような包括的な回答を提供します。People Also Askボックスはエンティティ関係を活用して関連検索やトピックを提案します。これらの機能は検索結果の一等地を占めており、ブランドにとって非常に重要です。Perplexity、ChatGPT、Claude、Google AI概要といったAIシステムでの存在感をモニタリングする場合も、ナレッジグラフ最適化が不可欠です。これらAIは、正確で文脈的な回答生成において構造化エンティティ情報と意味的関係にますます依存しています。構造化データマークアップ、ナレッジパネル主張、各種ソースでの情報一貫性を通じてエンティティ最適化がなされたブランドは、関連トピックのAI生成回答に登場しやすくなります。一方、情報が不完全・矛盾していると、AIで見落とされ可視性や評判に直接影響します。
Googleのナレッジグラフは多様なデータソースから構成され、それぞれ異なるタイプの情報を提供し、異なる役割を果たしています。WikipediaやWikidataなどのオープンデータ・コミュニティプロジェクトはナレッジグラフの基盤となっており、Wikipediaはナレッジパネルに表示される説明文や要約情報、Wikidataは機械が読めるエンティティデータや関係性を提供します。Googleはかつて独自のコミュニティ型データベースFreebaseを使用していましたが、2016年にFreebaseを終了しWikidataへ移行しました。政府系データソースは主に事実系クエリで権威ある情報を供給します。CIAワールドファクトブックは国・地域・組織情報をカバーし、Data Commons(Googleのパブリックデータ統合プロジェクト)は国連やEUなど政府・多国間組織の統計・人口情報を集約します。気象・大気質データは各国気象機関から得られ、Googleの「今の天気」機能に利用されます。ライセンス取得した民間データは、頻繁に更新される情報や専門的知識が必要な分野を補完します。金融市場データはMorningstar、S&P Global、Intercontinental Exchangeなどからライセンスし、株価や市場情報を提供。スポーツデータはStats Performなどとの提携を通じ、リアルタイムスコアや統計を提供します。Webサイトの構造化データもナレッジグラフ充実に大きく貢献しています。Schema.orgマークアップをWebサイトに実装すると、Googleは明示的な意味情報を抽出・取り込み可能です。だからこそ、OrganizationやLocalBusiness、FAQPageなど適切なスキーマ実装がブランドのナレッジグラフ表示に重要です。Google Booksのデータは4000万冊超の書籍のスキャン・デジタル化情報から歴史的背景や詳細説明を提供し、エンティティ知識を深めています。ユーザーフィードバックやナレッジパネル主張では、個人や組織が直接ナレッジグラフ情報に影響を与えることができます。ユーザーがパネルのフィードバックを送信したり、正規代理人がパネルを主張・更新すると、その情報が処理されナレッジグラフの更新につながる場合があります。この人間参加型アプローチで、ナレッジグラフの正確性と代表性が保たれますが、最終的に何が表示されるかはGoogleの自動システムが判断します。
Googleは、ナレッジグラフの構築・更新時にE-E-A-T(経験・専門性・権威性・信頼性)を示すソースの情報を優先すると明言しています。E-E-A-Tとナレッジグラフ採用との関係は偶然ではなく、「信頼できる情報を優先する」というGoogleの方針を反映しています。もし自社サイトのコンテンツがナレッジグラフ由来のSERP機能に取り込まれていれば、その分野の権威としてGoogleに認識されている強いシグナルです。逆に取り込まれていない場合は、E-E-A-Tの課題がある可能性があります。ナレッジグラフ可視性のためのE-E-A-T構築は多面的アプローチが必要です。経験はトピックの実体験や現場経験を示すことであり、医療サイトなら有資格医師の執筆、テック企業なら開発者自身による専門的説明が該当します。専門性は、表面的説明を超えた深い知識・正確性・網羅性が求められます。権威性は、業界内での認知・賞や認定・メディア掲載・他権威サイトからの引用などで構築できます。組織なら業界リーダーとしてのブランド確立が重要です。信頼性は透明性・正確性・適切な引用・明確な著者情報・顧客対応などで示されます。E-E-A-Tシグナルを強化した組織ほど、ナレッジグラフ採用やAI生成回答での露出が高まり、可視性→権威→更なる可視性という好循環を生みます。
大規模言語モデル(LLM)や生成AIの登場により、ナレッジグラフのAIエコシステムでの重要性は一段と高まりました。ChatGPTやClaude、PerplexityなどのLLMはGoogleの専有ナレッジグラフで直接訓練されているわけではありませんが、同様の構造化知識や意味理解にますます依存しています。多くのAIシステムは**RAG(retrieval-augmented generation)**手法を採用し、推論時にナレッジグラフや構造化データベースへクエリを発行し、回答を事実で裏付け、幻覚を減らします。Wikidataのようなパブリックナレッジグラフもモデルのファインチューニングや知識注入に使われ、エンティティ関係の理解や正確な回答能力を底上げしています。これは、ナレッジグラフ最適化が従来のGoogle検索を超えて重要になったことを意味します。業界・製品・組織についてAIに問われた場合、その正確性は構造化ナレッジソースでのエンティティ表現に左右されます。Wikidataのエントリーが整い、Googleナレッジパネルが主張され、Webサイトの構造化データも一貫性があれば、AI生成回答でも正確にブランドを表現できます。逆に情報が不完全・矛盾していれば、AIで誤解や見落としが生じることも。こうした状況は、AI可視性モニタリングの新しい次元を生み出しています。従来の検索結果だけでなく、AI生成回答でのブランド表現も監視し、ナレッジグラフでのエンティティ関係や表現を重視するツールやサービスが増えています。
ナレッジグラフでの存在感を高めるには、SEOの基本に加え、エンティティ特有の戦略を系統立てて実施しましょう。まずSchema.orgによる構造化データマークアップの実装が第一歩です。JSON-LD、Microdata、RDFa等を使い、組織・商品・人物・FAQなど主要エンティティを明示的に記述しましょう。主要スキーマはOrganization(会社)、LocalBusiness(店舗)、Person(人物)、Product(商品)、FAQPage(よくある質問)です。実装後はGoogle構造化データテストツールで正しく認識されているか検証しましょう。次にWikidataやWikipediaの情報監査・最適化が重要です。自社や主要エンティティのWikipediaページがあれば、内容が正確・網羅的・出典明確か確認しましょう。Wikidataでもエンティティが存在し、プロパティや関係性が正しく表現されているかを確認します。ただしWikipedia/Wikidataの編集は規約遵守や利益相反の慎重な配慮が必要です。次はGoogleビジネスプロフィールの主張・最適化(ローカルビジネス向け)とナレッジパネルの主張(人物・組織向け)です。主張済みパネルは検索結果での表示コントロールや編集提案の反映が迅速化できます。さらに全プロパティでの一貫性維持(Webサイト・ビジネスプロフィール・SNS・第三者ディレクトリ)が不可欠。ソース間で情報が矛盾するとGoogleのシステムは正確に認識できません。最後に、従来のキーワード中心ではなくエンティティ中心のコンテンツ戦略を展開しましょう。例えば「ベストCRMソフト」「Salesforceの特徴」「HubSpotの価格」など別記事に分けるのではなく、「SalesforceはCRMプラットフォームで、HubSpotと競合し、Slackと連携する」といったエンティティ間の関係性を明示した包括的なコンテンツクラスターを作成します。このアプローチにより、ナレッジグラフがコンテンツの意味や関係性を理解しやすくなります。
AIの進化、検索行動の変化、新たなプラットフォームや技術の登場を受けて、ナレッジグラフも急速に進化しています。重要なトレンドの一つは、テキスト・画像・音声・動画データを統合したマルチモーダルナレッジグラフの拡大です。音声検索や画像検索が普及する中、Google Lensのようなマルチモーダル検索では、テキストクエリだけでなく画像入力も理解し、異なるメディアタイプを横断して情報を表現・接続できるナレッジグラフが必要です。もう一つの進展は、セマンティック・エンリッチメントや自然言語処理の高度化です。NLP能力が向上することで、未構造化テキストからより微妙な意味的関係性を抽出でき、手作業や構造化データへの依存が減少します。高品質な文章コンテンツがあれば、マークアップなしでもナレッジグラフに情報が取り込まれる可能性が高まります(ただし正確な表現には構造化マークアップも依然重要)。さらに、大規模言語モデルや生成AIとの統合が最大の進化かもしれません。AIが情報発見の中心になるにつれ、ナレッジグラフ最適化は従来検索を超え、複数プラットフォームでのAI可視性まで広がります。ナレッジグラフを理解・最適化できる組織は、検索・AI回答の両方で優位に立てます。また、エンタープライズナレッジグラフの普及も、社内ナレッジマネジメントや意思決定、AI活用で重要性が増している証拠です。ビジネスリーダーやデータサイエンティスト、マーケターにとって、ナレッジグラフリテラシーは今後ますます重要になります。最後に、ナレッジグラフが数十億人の情報表示を左右する存在となったことで、規制や倫理面も注目されています。情報の正確性・偏り・表現・コントロール権などの課題が増大しており、自社のナレッジグラフでの表現が可視性や評判、ビジネス成果に直結することを認識し、他のWeb施策と同様、厳
従来のデータベースは事前に定義されたスキーマを持つ堅固な表形式でデータを保存しますが、ナレッジグラフはエンティティとその意味的な関係をノードとエッジとして相互接続して構造化します。ナレッジグラフはより柔軟で自己記述的であり、多様なデータタイプ間の複雑な関係を理解するのに適しています。システムが単なるキーワードマッチングではなく、意味や文脈を理解できるようにするため、AIやセマンティック検索に理想的です。
Googleはナレッジグラフを活用して、ナレッジパネル、AI概要、People Also Askボックス、関連エンティティの提案など、複数のSERP機能を実現しています。2024年5月時点で、Googleのナレッジグラフは540億のエンティティに関する1.6兆以上のファクトを保有しています。ユーザーが検索すると、Googleはそのエンティティを特定し、ナレッジグラフから関連性の高い情報を表示することで、Googleの言う「ストリング(文字列)ではなく、もの(実体)」を見つけやすくしています。
ナレッジグラフは、WikipediaやWikidataなどのオープンソースプロジェクト、CIAワールドファクトブックのような政府データベース、金融やスポーツ情報のライセンスデータ、Schema.orgによるWebサイトの構造化データマークアップ、Google Booksのデータ、ナレッジパネル修正によるユーザーからのフィードバックなど、複数のソースからデータを集約しています。このマルチソースアプローチにより、数十億件のファクトにわたる包括的で正確なエンティティ情報が確保されます。
ナレッジグラフはエンティティ間の関係や接続を確立することで、検索結果やAIシステム上でブランドがどのように表示されるかに直接影響します。構造化データ、ナレッジパネルの主張、情報の一貫性などエンティティ最適化を図るブランドは、AI生成の回答でも高い可視性を得やすくなります。ナレッジグラフの関係性を理解することで、ChatGPT、Perplexity、ClaudeといったAIシステム内でのブランドの存在をモニタリングできます。これらのAIはますます構造化エンティティ情報に依存しています。
セマンティック・エンリッチメントとは、機械学習や自然言語処理(NLP)アルゴリズムによってデータから個々のオブジェクトやその関係を特定し、意味や文脈を理解するプロセスです。データ取り込み時に、エンリッチメント処理が自動的にエンティティや属性、他エンティティとの関係を認識し、単なるキーワードマッチングを超えて、よりインテリジェントな検索や質疑応答を可能にします。
Schema.orgによる構造化データマークアップの実装、Webサイト・Googleビジネスプロフィール・SNS全体での情報一貫性の維持、ナレッジパネルの主張・更新、権威性の高いコンテンツによるE-E-A-Tシグナルの構築、情報の正確性確保などが重要です。従来のキーワードクラスターではなくエンティティ中心のコンテンツクラスターを作成すると、ナレッジグラフが認識・活用しやすい強固な関係性を築けます。
ナレッジグラフは、AIシステムがエンティティの関係性や文脈を理解するためのセマンティックな基盤を提供します。AIが検索サマリーを生成する際、ナレッジグラフのデータを活用して関連エンティティやそのつながりを特定し、複数ソースから情報を統合します。これにより単なるキーワード一致を超えた、より正確かつ文脈的な回答が可能となり、ナレッジグラフは現代の生成型検索体験の基盤となっています。
ナレッジグラフはエンティティや関係性のモデリングと意味理解を定義する設計パターン・セマンティック層であり、グラフデータベースはそのデータを保存・クエリする技術インフラです。ナレッジグラフは意味や関係性に焦点を当て、グラフデータベースは効率的な保存や検索に特化しています。ナレッジグラフはNeo4j、Amazon Neptune、RDFトリプルストアなど様々なグラフデータベース上に実装できますが、ナレッジグラフ自体は概念モデルです。
ChatGPT、Perplexity、その他のプラットフォームでAIチャットボットがブランドを言及する方法を追跡します。AI存在感を向上させるための実用的なインサイトを取得します。
ナレッジグラフとは何か、その仕組み、そして現代のデータ管理・AI応用・ビジネスインテリジェンスに不可欠な理由を解説します。...
データ可視化におけるグラフとは何かを学びましょう。グラフがノードとエッジを使ってデータの関係をどのように表現し、なぜ分析やAI監視において複雑なデータ接続を理解するために不可欠なのかを解説します。...
ナレッジグラフの解説とAI検索での重要性についてのコミュニティディスカッション。専門家がエンティティやリレーションシップがAIの引用に与える影響を共有します。...
クッキーの同意
閲覧体験を向上させ、トラフィックを分析するためにクッキーを使用します。 See our privacy policy.