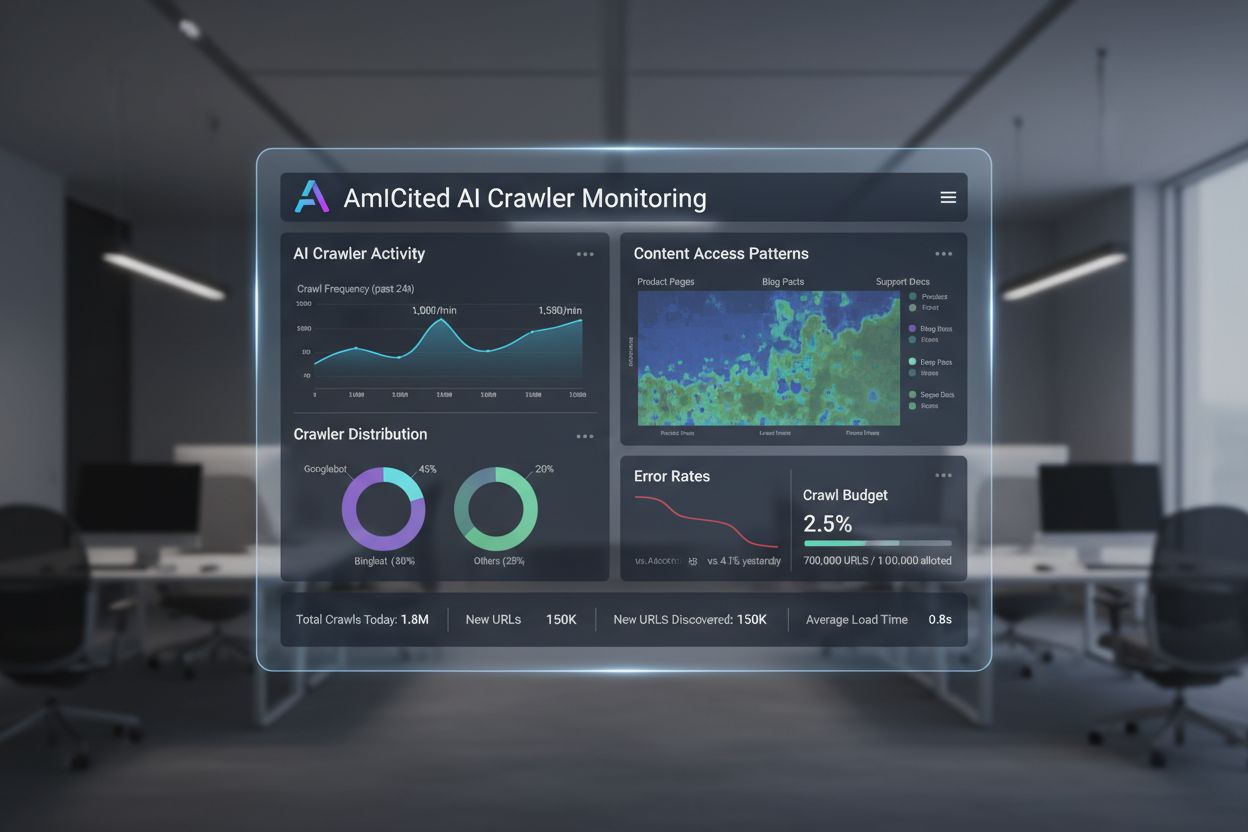
AIクローラーアナリティクス
AIクローラーアナリティクスとは何か、サーバーログ解析がAIクローラーの行動、コンテンツアクセスパターン、ChatGPT・Perplexity・Google AI OverviewsのようなAI検索プラットフォームでの可視性をどのように追跡するかを学びましょう。...
1 分で読める

ログファイル分析は、サーバーアクセスログを調査することで、検索エンジンのクローラーやAIボットがウェブサイトとどのようにやり取りしているかを把握し、クロールパターン、技術的な問題、SEOパフォーマンス向上のための最適化機会を明らかにするプロセスです。
ログファイル分析は、サーバーアクセスログを調査することで、検索エンジンのクローラーやAIボットがウェブサイトとどのようにやり取りしているかを把握し、クロールパターン、技術的な問題、SEOパフォーマンス向上のための最適化機会を明らかにするプロセスです。
ログファイル分析とは、検索エンジンクローラー、AIボット、ユーザーがウェブサイトとどのようにやり取りしているかを理解するために、サーバーアクセスログを体系的に調査することです。これらのログはウェブサーバーによって自動生成され、リクエスト元のIPアドレス、タイムスタンプ、リクエストURL、HTTPステータスコード、ユーザーエージェント文字列など、あなたのサイトへのあらゆるHTTPリクエストの詳細な記録が含まれています。SEO担当者にとって、ログファイル分析はクローラーの行動に関する究極の情報源となり、Google Search Consoleや従来型クローラーなどの表面的なツールでは取得できないパターンを明らかにします。シミュレーションクロールや集約アナリティクスデータとは異なり、サーバーログは検索エンジンやAIシステムが実際にあなたのウェブサイト上で何をしているかを、リアルタイムかつフィルタリングされていない一次情報として提供します。
デジタル環境の進化に伴い、ログファイル分析の重要性は飛躍的に高まっています。現在、世界のインターネットトラフィックの51%以上がボットによって生成されている(ACS, 2025)中、GPTBot、ClaudeBot、PerplexityBotなどのAIクローラーがウェブサイトの定期的な訪問者となったことで、クローラー行動の把握はもはや選択肢ではなく、従来型検索と新たなAI主導の検索プラットフォームの両方で可視性を維持するために不可欠となっています。ログファイル分析は、「サイト上で何が起きていると思っているか」と「実際に起きていること」のギャップを埋め、検索順位やインデックス速度、オーガニック全体パフォーマンスに直接影響するデータ主導の意思決定を可能にします。
ログファイル分析は数十年にわたり技術的SEOの基盤であり続けてきましたが、近年その重要性は劇的に増しています。従来、SEO担当者は主にGoogle Search Consoleや外部クローラーに依存して検索エンジンの行動を把握していました。しかし、これらのツールには大きな制約があります。Google Search ConsoleはGoogleクローラーの集約・サンプリングデータのみを提供し、外部クローラーはクローラー行動を模擬するだけで実際のインタラクションは記録できず、いずれも非Google検索エンジンやAIボットの行動は十分に把握できません。
AI主導の検索プラットフォームの登場は状況を根本的に変化させました。Cloudflareの2024年調査によると、GooglebotがAIおよび検索クローラートラフィック全体の39%を占める一方、AI専用クローラーが最も急速に成長するセグメントとなっています。MetaのAIボットだけで**AIクローラートラフィックの52%**を生み出しており、Google(23%)やOpenAI(20%)の2倍以上です。この変化により、現在のウェブサイトには数十種類の異なるボットが訪れ、その多くは従来のSEOプロトコルや標準のrobots.txtルールを無視します。ログファイル分析だけがこの全体像を捉えることができ、現代SEO戦略にとって不可欠な存在となっています。
世界のログ管理市場は2025年の3228.5百万ドルから2029年までに大幅な拡大が見込まれており、年平均成長率(CAGR)は14.6%に達します。この成長は、ログ分析がセキュリティ、パフォーマンス監視、SEO最適化に不可欠であるという企業の認識の高まりを反映しています。組織は、自動化されたログ分析ツールやAI搭載プラットフォームへの投資を強化し、何百万件ものログエントリをリアルタイムで処理し、生データをビジネス成果につながる実用的インサイトへと変換しています。
ユーザーまたはボットがあなたのウェブサイトでページをリクエストすると、ウェブサーバーはそのリクエストを処理し、インタラクションの詳細情報をログに記録します。このプロセスは自動的かつ継続的に行われ、サーバー活動の完全な監査記録が作成されます。この仕組みを理解することは、ログファイルデータを正しく解釈するうえで不可欠です。
一般的な流れとしては、クローラー(GooglebotやAIボット、またはユーザーブラウザ)がサーバーにHTTP GETリクエストを送り、リクエスターを特定するユーザーエージェント文字列を含めます。サーバーはこのリクエストを受け取り、処理し、HTTPステータスコード(200は成功、404は未検出、301は恒久的リダイレクトなど)とリクエストされたコンテンツを返します。これらすべてのやり取りがサーバーのアクセスログファイルに記録され、IPアドレス、リクエストURL、HTTPメソッド、ステータスコード、レスポンスサイズ、リファラー、ユーザーエージェント文字列などを含むタイムスタンプ付きエントリが作成されます。
HTTPステータスコードはSEO分析で特に重要です。200はページ配信成功、3xxはリダイレクト、4xxはクライアントエラー(404 Not Foundなど)、5xxはサーバーエラーを示します。これらのステータスコードの分布をログで分析することで、クローラーがコンテンツにアクセスできなくなる技術的問題を特定できます。たとえば、重要なページのクロール時にクローラーが複数の404レスポンスを受けている場合、リンク切れやコンテンツ消失の問題があることを示しています。
ユーザーエージェント文字列も、どのボットがサイトを訪れているかを特定するうえで非常に重要です。各クローラーには固有のユーザーエージェント文字列があります。Googlebotは"Googlebot/2.1"、GPTBotは"GPTBot/1.0"、ClaudeBotは"ClaudeBot"が含まれます。これらの文字列を解析することで、クローラーごとにログデータをセグメントし、どのボットがどのコンテンツを優先しているかやクロールパターンの違いを明らかにできます。こうした詳細な分析は、各検索プラットフォームやAIシステムごとの最適化戦略を立てるのに役立ちます。
| 項目 | ログファイル分析 | Google Search Console | 外部クローラー | アナリティクスツール |
|---|---|---|---|---|
| データソース | サーバーログ(一次データ) | Googleのクロールデータ | シミュレーションクローラー | ユーザー行動追跡 |
| 完全性 | すべてのリクエスト(100%) | サンプリング・集約データ | シミュレーションのみ | 人間のトラフィックのみ |
| ボット対応範囲 | すべてのクローラー(Google, Bing, AIボット) | Googleのみ | シミュレーションクローラー | ボットデータなし |
| 履歴データ | 完全履歴(保持期間は環境による) | 限定的期間 | 単一クロールスナップショット | 履歴あり |
| リアルタイム性 | あり(自動化時) | 報告に遅延あり | なし | 報告に遅延あり |
| クロールバジェット可視化 | 正確なクロールパターン | 概要のみ | 推定 | 該当なし |
| 技術的問題可視化 | 詳細(ステータスコード・応答時間) | 限定的 | シミュレーション上の問題 | 該当なし |
| AIボット追跡 | 可能(GPTBot, ClaudeBot等) | 不可 | 不可 | 不可 |
| コスト | 無料(サーバーログ) | 無料 | 有料ツール | 無料/有料 |
| 設定難易度 | 中~高 | 簡単 | 簡単 | 簡単 |
ログファイル分析は、検索エンジンやAIシステムがサイトとどのようにやり取りしているかを理解するために欠かせない存在となっています。Googleの視点と集約データしか得られないGoogle Search Consoleと異なり、ログファイルはすべてのクローラーの活動全体像を記録します。この包括的な視点は、クロールバジェットの浪費、つまり検索エンジンが重要でないページにリソースを費やし、重要なコンテンツのクロールが疎かになる状況の特定に不可欠です。大規模サイトでは、ページネーションアーカイブやファセットナビゲーション、古いコンテンツなど、非本質的URLへのクロールバジェット浪費が30~50%に上ることもあります。
AI主導の検索台頭により、ログファイル分析の重要性はさらに増しています。GPTBot、ClaudeBot、PerplexityBotなどのAIボットがサイトの定期訪問者となり、その行動を把握することがAI生成回答での可視性最適化に不可欠です。これらのボットは従来型クローラーと異なり、robots.txtルールを無視したり、アグレッシブにクロールしたり、特定タイプのコンテンツに集中することが多いのが特徴です。ログファイル分析のみがこうしたパターンを明らかにし、AI発見の最適化とボットアクセス管理を両立できます。
技術的SEO課題も、ログ分析によって発見できます。リダイレクトチェーン、5xxサーバーエラー、ページ読み込み速度低下、JavaScriptレンダリングの問題など、すべてサーバーログに痕跡が残ります。これらのパターンを分析することで、検索エンジンのアクセス性やインデックス速度に直結する修正の優先順位付けが可能です。たとえば、Googlebotが特定セクションで503 Service Unavailableエラーを頻発していることがログで分かれば、どこに技術的対応を集中すべきかが明確になります。
ログファイル分析の第一歩はサーバーログの取得ですが、その方法はホスティング環境によって異なります。自社運用サーバー(ApacheやNGINX)の場合、通常は/var/log/apache2/access.logや/var/log/nginx/access.logに保存されており、SSHやサーバーファイルマネージャから直接アクセス可能です。WP EngineやKinstaなどのマネージドWordPressホスティングでは、ホスティングダッシュボードやSFTP経由でログが提供されている場合もありますが、パフォーマンス保護のためにアクセスが制限されていることもあります。
**CDN(Cloudflare, AWS CloudFront, Akamai等)**を利用している場合は、ログ取得のために特別な設定が必要です。CloudflareはLogpush機能により、HTTPリクエストログを指定したストレージバケット(AWS S3, Google Cloud Storage, Azure Blob Storageなど)に送信できます。AWS CloudFrontも標準ロギング機能があり、S3バケット保存が可能です。これらCDNログは、コンテンツがCDN経由で配信される際のボット行動把握に不可欠で、オリジンサーバーではなくエッジでのリクエストを記録します。
共有ホスティング環境ではログアクセスが制限されていることが多く、BluehostやGoDaddyなど一部プロバイダーではcPanel経由で部分的なログが提供されますが、多くの場合ログのローテーションが早く、重要なフィールドが省略されていることもあります。包括的なログ分析が必要な場合は、VPSやマネージドホスティングへの移行を検討しましょう。
ログ取得後はデータ前処理が重要です。生ログファイルにはユーザー、ボット、スクレイパー、悪意あるアクセスなどすべてのリクエストが含まれているため、SEO分析では検索エンジンやAIボットの活動にフォーカスするためのフィルタリングが必要です。一般的なプロセスは以下の通りです:
ログファイル分析は他のSEOツールでは見えないインサイトを提供し、戦略的な最適化判断の基盤となります。最も価値のあるインサイトの一つがクロールパターン分析であり、検索エンジンがどのページをどれくらいの頻度で訪れているかを正確に把握できます。クロール頻度を時系列で追跡することで、Googleが特定セクションへの関心を高めているのか、減らしているのかが分かります。急な頻度低下は技術的問題やページの重要度変化、上昇は最適化の成果を示唆します。
クロールバジェット効率も重要な指標です。成功応答(2xx)とエラー応答(4xx, 5xx)の比率を分析することで、クローラーが問題に遭遇しているサイト内セクションが特定できます。特定のディレクトリで404エラーが多発していれば、リンク切れによるクロールバジェット浪費が発生していることが分かります。同様に、ページネーションURLやファセットナビゲーションでクロール時間を浪費していれば、低価値コンテンツにリソースが割かれている証拠です。ログ分析はこの無駄を定量化し、最適化の効果予測にも役立ちます。
オーファンページの発見もログファイル分析ならではのメリットです。オーファンページは内部リンクがなくサイト構造から外れているURLで、従来型クローラーは発見できないことが多いですが、ログファイルには外部リンクや古いサイトマップ経由でクロールされた痕跡が残ります。こうしたページの存在を把握することで、サイト構造への再統合、リダイレクト、削除などの判断ができます。
AIボット行動分析も重要性が高まっています。AIボットのユーザーエージェントごとにログデータをセグメントすることで、どのコンテンツが優先クロールされているか、アクセス頻度、技術的障壁の有無が分かります。例えば、GPTBotがFAQページばかりをクロールしブログにはあまりアクセスしない場合、AIシステムがFAQ型コンテンツをトレーニングデータとして重視していることが示唆され、コンテンツ戦略やAI可視性最適化の方針決定に役立ちます。
効果的なログファイル分析には、適切なツールと戦略的アプローチが必要です。Screaming FrogのLog File Analyzerは大規模なログファイルの処理、ボットパターンの特定、クロールデータの可視化に優れた専用ツールです。BotifyはSEO指標と統合されたエンタープライズ向けログ分析を提供し、ボット活動とランキング・トラフィックの相関分析を可能にします。seoClarityのBot Clarityはログ分析をSEOプラットフォームに統合し、クロールデータと他SEO指標の連携を容易にします。
大規模トラフィックや複雑なインフラを持つ組織では、Splunk、Sumo Logic、Elastic StackなどAI搭載のログ分析プラットフォームが、自動パターン認識・異常検知・予測分析など高度な機能を提供します。これらは数百万件のログエントリをリアルタイムで処理し、新しいボットタイプやセキュリティリスク、技術的問題の兆候を自動検出します。
ベストプラクティスは以下の通りです:
AI主導の検索が重要性を増す中で、ログファイル分析によるAIボット監視はSEOの重要機能となりました。どのAIボットが、どのコンテンツに、どれくらいの頻度でアクセスしているかを把握することで、AI検索ツールや生成AIモデルへのコンテンツ供給状況が分かり、robots.txtやHTTPヘッダーで特定AIボットの許可・拒否・制限を戦略的に判断できます。
クロールバジェット最適化は、ログファイル分析の最も実用的な応用分野です。何千・何百万ページを持つ大規模サイトではクロールバジェットは有限資源であり、ログ分析によって重要度に比べて過剰クロールされているページや、本来もっとクロールされるべきなのにされていないページを特定できます。よくあるクロールバジェット浪費の例は以下の通り:
これらの課題をrobots.txt、カノニカル、noindexタグ、技術的修正などで解消することで、クロールバジェットを高価値コンテンツへ再配分し、インデックス速度およびビジネス上重要なページの検索可視性を向上できます。
AI主導の検索の急速な進化が、ログファイル分析の未来を形作っています。より多様で高度なAIボットが登場し、その行動が複雑化する中で、ログファイル分析はコンテンツがAIシステムにどのように発見・アクセス・利用されるかを理解するために、ますます重要となるでしょう。主なトレンドは以下の通りです:
機械学習によるリアルタイムログ分析の普及で、SEO担当者はクロール問題を数日単位ではなく数分で検知・対応できるようになります。自動化システムが新規ボットタイプや異常パターンを検出し、最適化施策も提案することで、分析は受動的から能動的へと進化します。これにより、継続的な最適なクロール性・インデックス性の維持が可能となります。
AI可視性トラッキングとの連携により、ログファイルデータとAI検索パフォーマンス指標が統合されます。ログ単体で分析するのではなく、クローラー行動とAI生成回答での実際の可視性を関連付け、どのようにクロールパターンがAI検索順位に影響するかを正確に把握できるようになります。これにより、クロールからAIトレーニングデータ、ユーザー向けAI回答までの流れが可視化され、かつてない洞察が得られます。
倫理的なボット管理も重要性を増し、どのAIボットにコンテンツアクセスを許可するかの戦略が求められます。ログファイル分析により、価値や帰属をもたらすAIクローラーのみを許可し、それ以外をブロックするなど、きめ細かなボット管理が実現します。LLMs.txtのような新たな標準プロトコルがポリシー伝達手段として登場し、ログ分析でその遵守状況を検証する動きも広がります。
プライバシー配慮型分析も進化し、GDPRなどの規制下でも詳細なクロールインサイトと個人情報保護の両立が求められます。高機能な匿名化やプライバシー重視の分析ツール導入が進み、ログ分析の普及拡大と規制強化に対応します。
従来型SEOとAI検索最適化の融合が進む中で、ログファイル分析は今後も技術的SEO戦略の中核であり続けるでしょう。現在ログファイル分析をマスターしている組織は、今後進化する検索環境でも可視性とパフォーマンスを維持できる最良のポジションを手にすることができます。
ログファイル分析は、すべてのクローラーからのリクエストを記録したサーバーの完全な未加工データを提供しますが、Google Search Consoleのクロール統計はGoogleのクローラーによる集約・サンプリングデータのみを表示します。ログファイルは、詳細な過去データや、GPTBotやClaudeBotなどAIクローラーを含む非Googleボットの行動インサイトも得られるため、実際のクローラー行動の全貌把握やGSCでは見落とされがちな技術的問題の発見により有用です。
トラフィックの多いサイトでは、問題の早期発見やクロールパターンの変化モニタリングのために週次のログファイル分析が推奨されます。小規模サイトでは、傾向把握や新しいボット活動の特定のために月次レビューが効果的です。サイト規模にかかわらず、自動化ツールによる継続的な監視を導入することで、クロールバジェットの無駄遣いや検索可視性に影響する技術的問題をリアルタイムで検知し、迅速な対応が可能になります。
はい、ログファイル分析はAIボットのトラフィック追跡に最も効果的な手法の一つです。サーバーログ内のユーザーエージェントやIPアドレスを調査することで、どのAIボットがサイトを訪れ、どのコンテンツにアクセスし、どれくらいの頻度でクロールしているかを特定できます。これらのデータは、あなたのコンテンツがAI検索ツールや生成AIモデルにどのように取り込まれているかを理解し、AI可視性の最適化やrobots.txtルールによるボットアクセス管理に役立ちます。
ログファイル分析では、クロールエラー(4xxや5xxステータスコード)、リダイレクトチェーン、ページの読み込み速度低下、内部リンクされていないオーファンページ、低価値URLへのクロールバジェット浪費、JavaScriptレンダリングの問題、重複コンテンツの問題など、多くの技術的SEO課題を明らかにします。また、偽装ボット活動の検出や、正規クローラーがアクセシビリティ障壁に直面した際の特定にも役立ち、検索エンジンでの可視性やインデックス化に直接影響する修正の優先順位付けが可能です。
ログファイル分析により、検索エンジンがどのページをどれくらいの頻度でクロールしているかが正確に分かるため、ページネーションアーカイブやファセットナビゲーション、古いURLなど低価値コンテンツへのクロールバジェット浪費箇所が判明します。これらの非効率を特定することで、robots.txtの調整や優先ページへの内部リンク強化、カノニカルの実装で、検索エンジンのクロールをビジネス上重要なページに集中させることができます。
サーバーログファイルには通常、IPアドレス(リクエスト元の特定)、タイムスタンプ(リクエスト日時)、HTTPメソッド(主にGETまたはPOST)、リクエストURL(アクセスされたページ)、HTTPステータスコード(200, 404, 301など)、レスポンスサイズ(バイト数)、リファラー情報、ユーザーエージェント(クローラーやブラウザの特定)が記録されます。この豊富なデータにより、SEO担当者は各サーバーインタラクションの内容を正確に再現し、クロールやインデックス化に影響するパターンを特定できます。
偽装ボットは、正規の検索エンジンクローラーを名乗りますが、IPアドレスが検索エンジンの公開IPレンジと一致しません。特定するには、ユーザーエージェント(例:'Googlebot')とGoogleやBingなどが公開している公式IPレンジを照合します。Screaming FrogのLog File Analyzerなどのツールは自動でボットの正当性を検証します。偽装ボットはクロールバジェットの浪費やサーバー負荷の原因となるため、robots.txtやファイアウォールルールでのブロックが推奨されます。
ChatGPT、Perplexity、その他のプラットフォームでAIチャットボットがブランドを言及する方法を追跡します。AI存在感を向上させるための実用的なインサイトを取得します。
AIクローラーアナリティクスとは何か、サーバーログ解析がAIクローラーの行動、コンテンツアクセスパターン、ChatGPT・Perplexity・Google AI OverviewsのようなAI検索プラットフォームでの可視性をどのように追跡するかを学びましょう。...
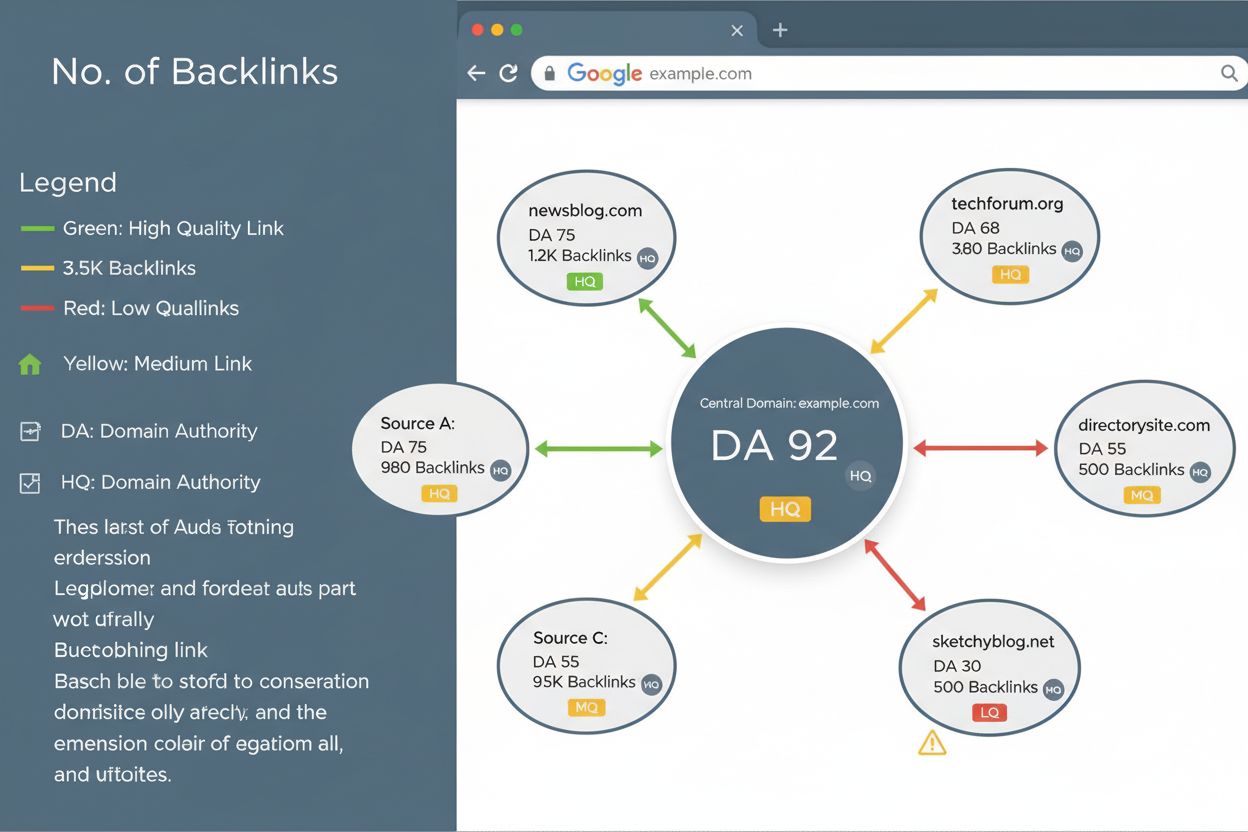
リンクプロファイルとは何か、SEOランキングにどのような影響を与えるのか、そしてバックリンクの質、多様性、ドメインオーソリティの監視がなぜウェブサイトの可視性と検索エンジンからの信頼に不可欠なのかを解説します。...
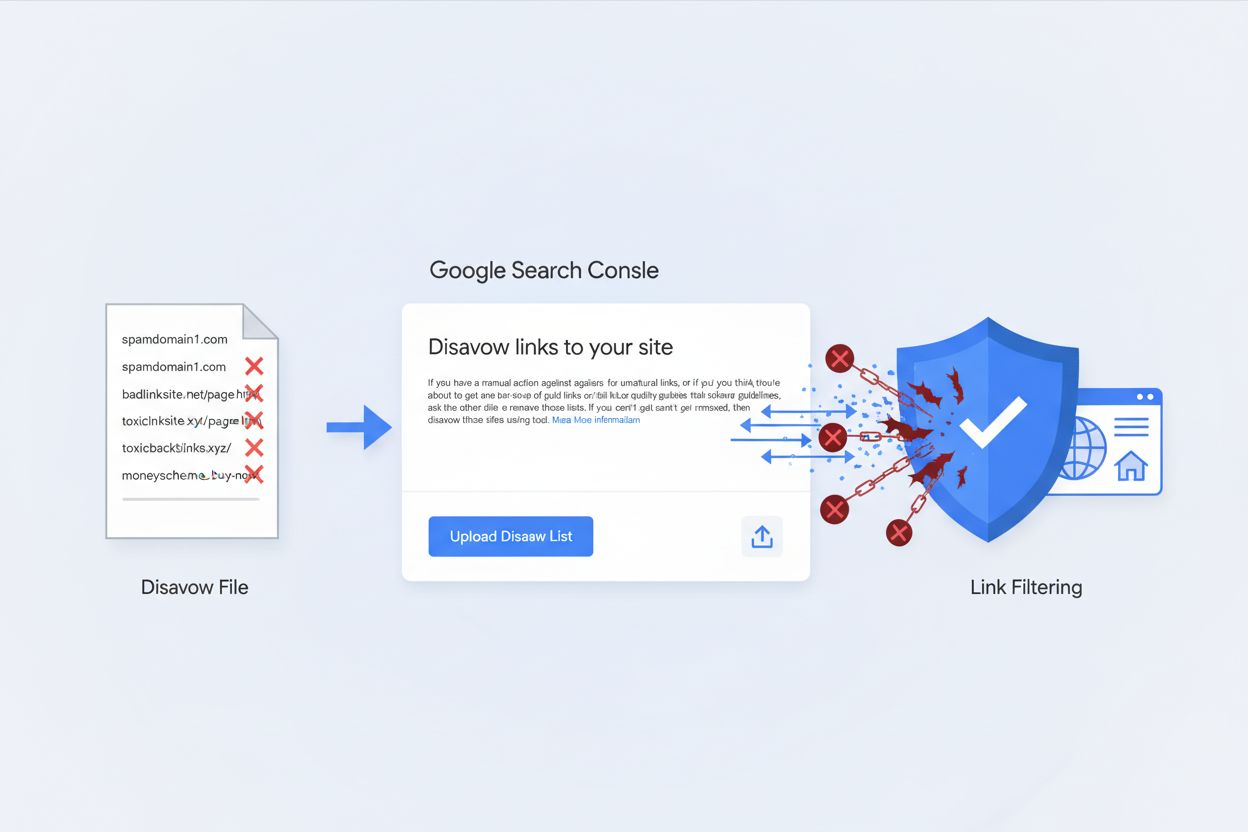
ディサヴァウファイルとは何か、Google Search Consoleでの働きや、ウェブサイトを有害なバックリンクやSEOペナルティから守るための使い方を解説します。...
クッキーの同意
閲覧体験を向上させ、トラフィックを分析するためにクッキーを使用します。 See our privacy policy.