
Meta AI最適化:FacebookとInstagramのAIアシスタント
Meta AIの最適化によって、FacebookとInstagramの広告がAIによる自動化、リアルタイム入札、インテリジェントなオーディエンスターゲティングで最大限のROIを実現する仕組みを解説します。...
1 分で読める
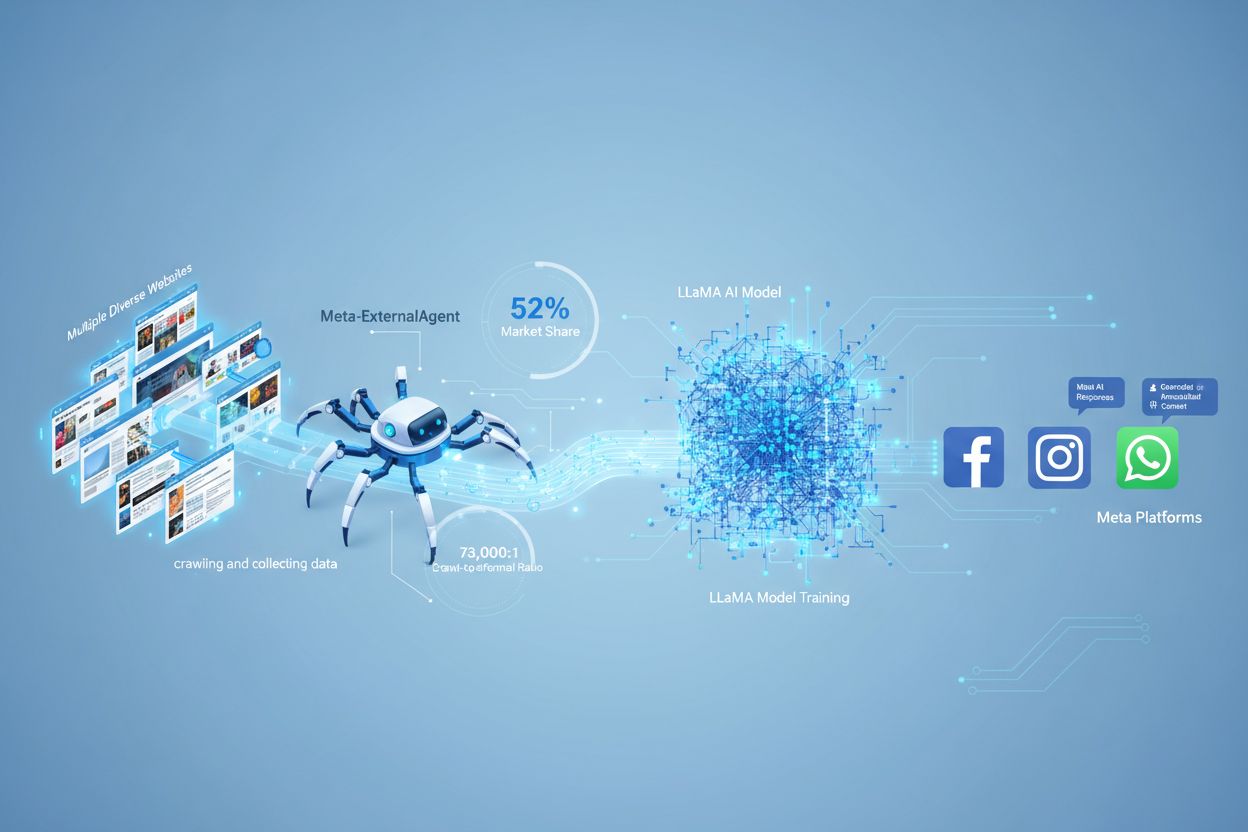
Meta-ExternalAgentは、Metaが2024年7月に導入したウェブクローラーボットで、LLaMAのようなAIモデルの学習用に公開ウェブコンテンツを収集します。User-Agent文字列meta-externalagent/1.1を使用して自身を識別し、Facebook、Instagram、WhatsApp全体のMeta AIの回答にコンテンツが表示されるかどうかを制御します。robots.txtやサーバーレベルの設定でブロックできますが、従うかどうかは任意であり法的拘束力はありません。
Meta-ExternalAgentは、Metaが2024年7月に導入したウェブクローラーボットで、LLaMAのようなAIモデルの学習用に公開ウェブコンテンツを収集します。User-Agent文字列meta-externalagent/1.1を使用して自身を識別し、Facebook、Instagram、WhatsApp全体のMeta AIの回答にコンテンツが表示されるかどうかを制御します。robots.txtやサーバーレベルの設定でブロックできますが、従うかどうかは任意であり法的拘束力はありません。
Meta-ExternalAgentは、Meta Platformsが2024年7月に導入した人工知能モデルの学習用データ収集を目的としたウェブクローラーです。User-Agent文字列meta-externalagent/1.1で識別され、主にリンクプレビューやソーシャルシェア機能のために使われてきた従来のfacebookexternalhitクローラーとは異なる存在です。Meta-ExternalAgentは、LLaMA言語モデルやFacebook・Instagram・WhatsAppに組み込まれたMeta AIチャットボット向けなど、MetaのAI戦略に必要な学習データの収集方法に大きな転換をもたらしています。従来のMetaクローラーと比べて透明性が非常に低く、正式な公表もなく配備されました。

Meta-ExternalAgentは、自動ボットとしてインターネット上のウェブサイトを体系的にクロールし、AIモデルの学習用にテキストやコンテンツを抽出します。このクローラーはHTTPリクエストをウェブサーバーに送り、独自のUser-Agentヘッダーで識別しながらページの内容をダウンロードして処理します。収集されたコンテンツはMetaのシステムで分析・トークナイズされ、大規模言語モデルの性能向上に役立つ学習データへと変換されます。なお、このクローラーはrobots.txtファイルの指示を任意で尊重しますが、これは名誉ベースの仕組みであり法的義務ではありません。Cloudflareのデータによると、Meta-ExternalAgentはインターネット全体の**AIクローラートラフィックの約52%**を占めており、AI業界でも最も積極的なデータ収集活動の一つとなっています。クロールは常時行われており、一部のパブリッシャーの報告では、Metaが選択的ではなく包括的なウェブコンテンツ収集を優先していることが示唆されています。
| クローラー名 | User-Agent文字列 | 主な目的 | 導入時期 | データ利用用途 |
|---|---|---|---|---|
| Meta-ExternalAgent | meta-externalagent/1.1 | AIモデル学習(LLaMA・Meta AI) | 2024年7月 | 生成AI用学習データ |
| facebookexternalhit | facebookexternalhit/1.1 | リンクプレビュー・ソーシャルシェア | 2010年頃 | Open Graphメタデータ・サムネイル |
| Facebot | facebot/1.0 | Facebookアプリのコンテンツ検証 | 2015年頃 | モバイルアプリのコンテンツ検証 |
| Applebot | Applebot/0.1 | Apple Siri・検索インデックス | 2015年頃 | 検索インデックス・音声アシスタント |
| Googlebot | Googlebot/2.1 | Google検索インデックス | 1998年頃 | 検索エンジンのインデックス構築 |
Meta-ExternalAgentは、これまでにない規模で動作し、パブリッシャーが自社コンテンツの利用状況を把握しにくいため、コンテンツ制作者や発信者にとって重大な懸念材料となっています。Cloudflareの調査によれば、Meta-ExternalAgentは**AIクローラートラフィックの52%**を占めており、OpenAIのGPTBotやGoogleのAIクローラーをはるかに上回っています。Metaは業界で最も多くの学習データを収集していますが、パブリッシャーは自社コンテンツがAI学習に利用されても補償や帰属表示を受けていません。73,000:1のクロール対リファラル比率は、Metaが膨大なコンテンツを抽出しながら、元サイトへほぼトラフィックを返していないという根本的な価値交換の不均衡を示しています。にもかかわらず、**Meta-ExternalAgentを積極的にブロックしているウェブサイトはわずか2%**で、GPTBotのブロック率25%と比べて低く、多くのパブリッシャーがこのクローラーの存在や影響を認識していないことがわかります。MetaがAIインフラに400億ドルを投資している現状からも、今後このデータ収集活動はさらに加速する可能性が高く、パブリッシャーはMeta-ExternalAgentとの関係を理解し、積極的な管理が求められます。
パブリッシャーはrobots.txtファイルによってMeta-ExternalAgentのアクセスを制御できますが、これは任意であり法的拘束力がないことを理解しておく必要があります。Meta-ExternalAgentをブロックするには、robots.txtファイルに以下の指示を追加します。
User-agent: meta-externalagent
Disallow: /
あるいは、クロールを許可しつつ特定のディレクトリだけ制限したい場合は、以下のように記載します。
User-agent: meta-externalagent
Disallow: /private/
Disallow: /admin/
Allow: /public/
ただし、一部のパブリッシャーからは、robots.txtでブロックしてもMeta-ExternalAgentがクロールを続けているとの報告があり、Metaが必ずしもこれらの指示を遵守していない可能性も示唆されています。より徹底した対策を講じたい場合は、HTTPヘッダーによるブロックやContent Delivery Network(CDN)ルールを活用し、User-Agent文字列でMeta-ExternalAgentのリクエストを検出・拒否する方法が有効です。また、サーバーログでmeta-externalagent/1.1のUser-Agentを監視すれば、クローラーが自社コンテンツへアクセスしているか確認できます。AmICited.comのようなツールを使えば、自社コンテンツがMeta AIの回答で引用・参照されているかも把握でき、MetaのAIシステムに自社コンテンツがどう利用されているかの可視化に役立ちます。

ユーザーがFacebook、Instagram、WhatsApp上のMeta AIチャットボットとやりとりする際、その回答はMeta-ExternalAgentが収集したコンテンツを一部もとに生成されています。しかし、Meta AIの回答には通常、元のウェブサイトへの明示的な引用や帰属表示が含まれていません。つまり、どのパブリッシャーのコンテンツがAI回答に使われているのか、ユーザーが把握することは困難です。この透明性の欠如は、自社コンテンツがMetaのAIシステムにどのような価値をもたらしているかを知りたいパブリッシャーにとって大きな課題となります。一部の競合他社はAI生成回答に引用を含めていますが、Metaはユーザー体験を優先してパブリッシャーの帰属表示を行わない方針です。そのため、パブリッシャーは自社コンテンツがどれだけMeta AIの回答に影響を与えているかを容易に追跡できず、AI学習利用によるビジネスインパクトを評価しにくい状況となっています。この可視化のギャップこそが、近年モニタリングソリューションの重要性が高まっている理由の一つです。
パブリッシャーは、サーバーログ分析を通じてMeta-ExternalAgentの活動を検証できます。これにより、クローラーのIPアドレスやリクエストパターン、コンテンツへのアクセス頻度が把握できます。アクセスログでUser-Agentmeta-externalagent/1.1を確認すれば、どのページが頻繁にクロールされているか特定可能です。高度なモニタリングツールを利用すれば、クロールパターンの時系列的な推移も追跡でき、Metaが特定のコンテンツタイプやウェブサイト内のセクションを優先しているかどうかも分析できます。また、Meta-ExternalAgentによる集中的なクロールはサーバーリソースや帯域幅を大きく消費するため、大規模コンテンツサイトでは帯域の監視も推奨されます。加えて、AmICited.comのようなツールでMeta AI回答に自社コンテンツが使われているかや、Metaプラットフォーム全体での引用状況を追跡できます。異常なクロール活動があった場合にアラートを設定しておくと、Metaのデータ収集行動の変化を素早く検知し、能動的に対応できます。サーバーログの定期監査は、AIクローラー管理戦略における必須事項となります。
Meta-ExternalAgentの法的な位置づけは依然として争点となっており、コンテンツ制作者やアーティスト、パブリッシャーによる訴訟が、明示的な同意や補償なしでAI学習に利用するMetaの権利を問う形で進行中です。Meta側はウェブクローリングはフェアユース(公正使用)に該当すると主張していますが、反対派は、収集規模や営利目的性、帰属表示の欠如などが著作権侵害に該当すると訴えています。robots.txtファイルは業界標準として広く用いられていますが、法的効力はなく、Metaがブロック指示に従う義務はありません。欧州連合のAI法や他地域での新たな法制化により、今後はMetaのような企業に対してより厳しい要件が課される可能性もあります。倫理面では、コンテンツ制作者が自作物の商用AI学習利用に関与・制御できる権利や、コンテンツの価値に見合う報酬が得られているかが根本的なテーマです。パブリッシャーは、進展する法制度を常に把握し、必要に応じて法律専門家と相談のうえ、AIクローラーへの対応方針を検討することが推奨されます。イノベーションとクリエイター保護のバランスは未だ明確な解決策がなく、今後も活発な法的・規制的議論が続く分野です。
AIクローラー管理を巡る状況は、パブリッシャー・規制当局・AI企業の間でデータ収集や利用条件の調整が進む中で急速に変化しています。MetaによるMeta-ExternalAgentの積極展開は、大手テック企業がウェブコンテンツを競争力あるAIシステムの学習素材と見なしている証拠であり、今後もこの傾向はAIの重要性が高まるほど加速していくでしょう。将来的には、クリエイターへの法的保護強化やAI学習データの強制ライセンス制度、パブリッシャーがコンテンツ利用を制御・収益化しやすくする技術標準の策定などが進む可能性があります。AmICited.comのようなツールの登場は、公開コンテンツがAIシステムにどのように利用されているかの透明性・説明責任への需要が高まっていることを示しており、今後はこうした監視・検証がコンテンツ制作者の標準的な業務となるでしょう。AI業界が成熟するにつれ、コンテンツ制作者とAI企業の間でより高度な交渉がなされ、公平な補償モデルが確立される可能性も見込まれます。
Meta-ExternalAgentは、2024年7月に導入されたMeta専用のAI学習用クローラーで、User-Agent文字列meta-externalagent/1.1で識別されます。ソーシャルシェア用リンクプレビューを生成するfacebookexternalhitとは異なり、Meta-ExternalAgentはLLaMAモデルやMeta AIの学習データ収集に特化しています。facebookexternalhitは2010年頃からソーシャル機能で使用されてきました。
Meta-ExternalAgentはrobots.txtファイルに指示を追加することでブロックできます。'User-agent: meta-externalagent'に続けて'Disallow: /'と記載すれば完全にブロック可能です。より強力な対策として、.htaccess(Apache)やNginxの設定ルールでサーバーレベルのブロックを実装できます。ただしrobots.txtは任意であり法的拘束力はないため、ブロックしてもクロールが続くという報告もあります。
いいえ、Meta-ExternalAgentをブロックしてもFacebookのリンクプレビューには影響しません。リンクプレビューやソーシャルシェア機能はfacebookexternalhitクローラーが担当しています。そのため、meta-externalagentをブロックしつつ、facebookexternalhitによるプレビュー生成は継続させることが可能です。
Meta-ExternalAgentのクローリングからリファラルへの比率は約73,000:1で、Metaは膨大な量のコンテンツを抽出する一方、元サイトにほとんどトラフィックを返していません。これは、従来の検索エンジンがリファラルトラフィックを提供する代わりにコンテンツをクロールするのとは根本的にバランスが異なっています。
robots.txtは任意のルールであり法的拘束力はありません。多くのクローラーはrobots.txtの指示に従いますが、Meta-ExternalAgentが明示的なrobots.txtブロックにもかかわらずクロールを続けているという報告も一部あります。確実にブロックするには、HTTPヘッダーやCDNルール、ファイアウォール設定などサーバーレベルでの対策が有効です。
サーバーアクセスログで'User-Agent: meta-externalagent/1.1'というリクエストを確認してください。また、AmICited.comのような監視ツールを活用すれば、自社コンテンツがMeta AIの回答に使われているか追跡できます。Dark VisitorsやCloudflare AnalyticsなどもAIクローラーの活動を可視化するのに役立ちます。
Cloudflareのデータによると、Meta-ExternalAgentはインターネット全体のAIクローラートラフィックの約52%を占めており、最も積極的なAIデータ収集活動となっています。これはOpenAIのGPTBotやGoogleのAIクローラーを大きく上回り、MetaがAI学習用ウェブコンテンツ収集で圧倒的な地位にあることを示します。
判断はビジネスの優先順位によります。Meta AIのトラフィックがあなたのオーディエンスにとって価値がある場合は許可するという選択肢もあります。ただし、MetaはAI学習に使われたコンテンツに対して補償や帰属表示を行いません。そのため、AI学習はブロックしつつ、ソーシャルシェア用のリンクプレビュー機能だけを維持する選択的なブロック戦略を取るパブリッシャーも多くいます。
Meta AIの最適化によって、FacebookとInstagramの広告がAIによる自動化、リアルタイム入札、インテリジェントなオーディエンスターゲティングで最大限のROIを実現する仕組みを解説します。...

noaiとnoimageaiメタタグを実装し、AIクローラーによるウェブサイトコンテンツへのアクセスを制御する方法を学びます。AIアクセス制御ヘッダーと実装方法の完全ガイド。...

NoAIメタタグとは何か、AIスクレイピングを防ぐ仕組み、実装方法、そして無断のAIトレーニングからコンテンツを守るための有効性について解説します。...