
ナレッジグラフとは?なぜ重要なのか | AIモニタリングFAQ
ナレッジグラフとは何か、その仕組み、そして現代のデータ管理・AI応用・ビジネスインテリジェンスに不可欠な理由を解説します。...
1 分で読める
ニューラルネットワークは、生物の神経回路網に着想を得た計算システムであり、相互に接続された人工ニューロンが層状に構成され、バックプロパゲーションと呼ばれるプロセスを通じてデータからパターンを学習することができます。これらのシステムは、現代の人工知能やディープラーニングの基盤となっており、自然言語処理からコンピュータビジョンまで幅広い応用を支えています。
ニューラルネットワークは、生物の神経回路網に着想を得た計算システムであり、相互に接続された人工ニューロンが層状に構成され、バックプロパゲーションと呼ばれるプロセスを通じてデータからパターンを学習することができます。これらのシステムは、現代の人工知能やディープラーニングの基盤となっており、自然言語処理からコンピュータビジョンまで幅広い応用を支えています。
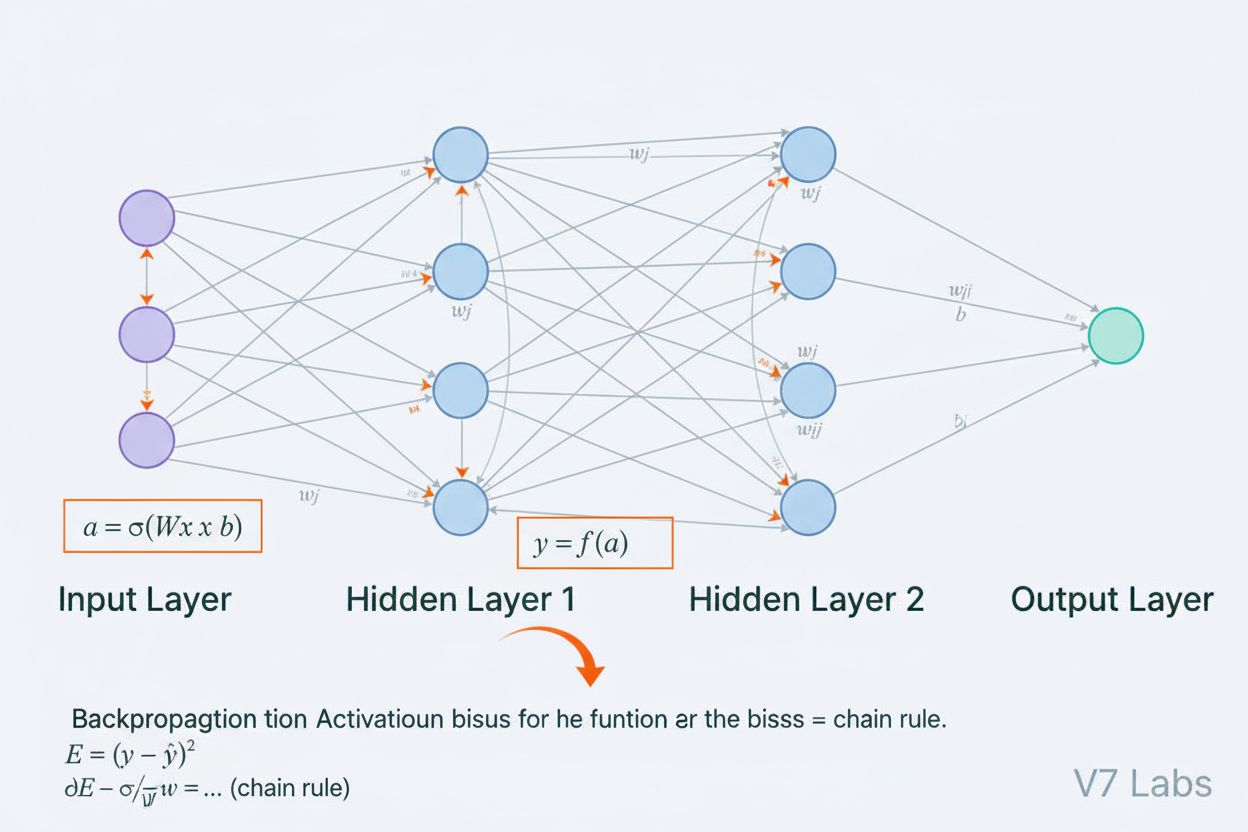
ニューラルネットワークは、動物の脳に見られる生物学的ニューラルネットワークの構造と機能に根本的に着想を得た計算システムです。これは、入力層、1つ以上の隠れ層、出力層からなる層状に構成された相互接続の人工ニューロンで構成され、データを処理し、パターンを認識し、予測を行うために協調して働きます。各ニューロンは入力を受け取り、重みとバイアスによる数学的変換を適用し、その結果を活性化関数に通して出力します。ニューラルネットワークの最大の特徴は、バックプロパゲーションと呼ばれる反復的なプロセスを通じてデータから学習し、内部パラメータを予測誤差が最小になるよう調整できる点です。この学習能力と複雑な非線形関係をモデル化できる性質によって、ニューラルネットワークは現代人工知能システムの基盤技術となり、大規模言語モデルからコンピュータビジョンまで幅広い応用を実現しています。
人工ニューラルネットワークの概念は、生物のニューロンがどのように情報をやりとりし処理するかを数学的にモデル化しようとする初期の試みから生まれました。1943年、ウォーレン・マカロックとウォルター・ピッツは最初のニューロンの数学モデルを提案し、単純な計算単位でも論理演算を実現できることを示しました。この理論的基盤をもとに、1958年フランク・ローゼンブラットはパターン認識のためのアルゴリズムであるパーセプトロンを発表し、現在の高度なニューラルネットワークの祖先となりました。パーセプトロンは線形モデルで単純な決定境界を学習できましたが、1970年代には単層パーセプトロンではXOR関数のような非線形問題を解けないことが判明し、「AIの冬」と呼ばれる停滞期に陥りました。1980年代、バックプロパゲーションの再発見と改良により多層ネットワークの訓練が可能になり、大きな転機となりました。2010年代には大規模データセットやパワフルなGPU、洗練された訓練手法の登場で、ディープラーニング革命が起こり、人工知能を一変させました。
ニューラルネットワークのアーキテクチャは、複数の重要な要素が協調して構成されています。入力層は外部からの生データ特徴量を受け取り、各ニューロンが1つの特徴に対応します。隠れ層は計算の中心であり、重み付き和と非線形活性化関数を通じて入力を次第に抽象的な表現に変換します。隠れ層の数や幅は、ネットワークが学習できるパターンの複雑さを決定し、深いネットワークほど高度な関係性を捉えられますが、より多くのデータや計算資源が必要です。出力層は最終的な予測結果を出力し、その構造は回帰なら1ニューロン、多クラス分類なら複数ニューロン、その他の応用では特殊な構成となります。各ニューロン間の接続には重みが設定されており、各入力の影響度を調整します。また、各ニューロンにはバイアスがあり、活性化閾値をシフトさせます。これらの重みとバイアスは訓練で調整される学習可能なパラメータです。各ニューロンで使われる活性化関数はネットワークに非線形性を与え、線形モデルでは捉えられない複雑な決定境界やパターンの学習を可能にします。
ニューラルネットワークは2つのフェーズからなる反復的なプロセスで学習します。順伝播では、入力データが入力層から出力層まで順に流れ、それぞれのニューロンで重み付き和とバイアス(z = w₁x₁ + w₂x₂ + … + wₙxₙ + b)が計算され、活性化関数を通して出力が生成されます。このプロセスを全ての隠れ層で繰り返し、最終的に出力層でネットワークの予測値を得ます。ネットワークは、損失関数を用いて予測値と正解ラベルとの差を誤差として定量化します。逆伝播では、この誤差が微分法の連鎖律を用いてネットワークを逆方向に伝わり、各重みやバイアスが全体の誤差にどれだけ寄与したかの勾配を算出します。これらの勾配をもとに、重みやバイアスが学習率でスケーリングされつつ、勾配の逆方向へと更新されます。この一連の順伝播、損失計算、逆伝播、パラメータ更新のサイクルを繰り返すことで、ニューラルネットワークはデータから徐々に学習し、予測精度を向上させていきます。
| アーキテクチャタイプ | 主な用途 | 主な特徴 | 強み | 制約 |
|---|---|---|---|---|
| フィードフォワードネットワーク | 構造化データの分類・回帰 | 情報が一方向のみで流れる | シンプル、高速訓練、解釈しやすい | 時系列や空間データには不向き |
| 畳み込みニューラルネットワーク(CNN) | 画像認識、コンピュータビジョン | 畳み込み層で空間特徴抽出 | ローカルパターン抽出に優れ、パラメータ効率が高い | 大規模なラベル付き画像データが必要 |
| リカレントニューラルネットワーク(RNN) | 時系列、シーケンス、NLP | 隠れ状態で過去情報を保持 | 可変長系列の処理が可能 | 勾配消失・爆発問題が発生しやすい |
| 長短期記憶(LSTM) | シーケンスの長距離依存 | 入力・忘却・出力ゲート付きメモリセル | 長期依存関係の学習に強い | RNNより複雑で学習が遅い |
| トランスフォーマーネットワーク | 自然言語処理、大規模言語モデル | マルチヘッドアテンションによる並列処理 | 高並列性、長距離依存の表現に強い | 莫大な計算資源が必要 |
| 敵対的生成ネットワーク(GAN) | 画像生成、合成データ作成 | ジェネレータと判別器が競合 | リアルな合成データ生成が可能 | 訓練が難しく、モード崩壊問題あり |
活性化関数の導入は、ニューラルネットワーク設計における最重要な革新の一つです。活性化関数がなければ、どれだけ層を重ねてもネットワークは単なる線形変換にしかならず、複雑なパターンの学習が不可能となります。活性化関数は各ニューロンに非線形性をもたらし、この問題を解決します。ReLU(Rectified Linear Unit)はf(x) = max(0, x)と定義され、計算効率と深層ネットワークでの有効性の高さから現代ディープラーニングで最も広く使われています。シグモイドはf(x) = 1/(1 + e^(-x))で出力を0~1に収め、バイナリ分類に有用です。tanhはf(x) = (e^x - e^(-x))/(e^x + e^(-x))で-1~1の範囲を出力し、隠れ層でシグモイドより性能が良い場合もあります。活性化関数の選択は学習のダイナミクス、収束速度、最終的な性能に大きな影響を与えます。現代のアーキテクチャでは、隠れ層にReLU、出力層にシグモイドやソフトマックスなどがよく用いられます。活性化関数による非線形性によって、ニューラルネットワークは任意の連続関数を近似できる万能近似定理が成立し、多様な応用での驚異的な適応力の根拠となっています。
ニューラルネットワーク市場は、現代人工知能の中核技術として爆発的な成長を遂げています。近年の市場調査によると、世界のニューラルネットワークソフトウェア市場は2025年に約347.6億ドル、2030年までに1,398.6億ドルに達すると予測されており、年平均成長率(CAGR)は32.10%です。より広範なニューラルネットワーク市場では、2024年の340.5億ドルから2033年には3,852.9億ドルに拡大し、CAGRは**31.4%**と見積もられています。この爆発的成長は、大規模データセットの普及、効率的な訓練アルゴリズムの開発、GPUやAI専用ハードウェアの進化、そして産業分野全体への普及が要因です。スタンフォード大学の2025年AIインデックスレポートによれば、2024年には組織の78%がAIを導入しており、前年の55%から大幅増となっています。ニューラルネットワークはほとんどすべての企業AI導入の中核であり、医療、金融、製造、小売などあらゆる業界で、パターン認識・予測・意思決定の競争優位性を支えています。
ニューラルネットワークは、ChatGPT、Perplexity、Google AI Overviews、Claudeなど、現在最先端のAIシステムを支えています。これらの大規模言語モデルは、注意機構を用いたトランスフォーマーベースのニューラルネットワークアーキテクチャ上に構築され、人間の言語を高度に処理・生成します。2017年に登場したトランスフォーマーアーキテクチャは、逐次処理ではなく一度に全系列を並列処理できるため、訓練効率や性能を劇的に向上させました。ブランドモニタリングやAIによる引用追跡の観点では、これらのシステムが文脈を理解し、関連情報を検索・生成し、ブランドやドメイン、コンテンツを参照する際にニューラルネットワークがどのように用いられるかを理解することが不可欠です。AmICitedは、ニューラルネットワークが情報を処理・検索する仕組みを活用し、AI生成応答でブランドがどこで引用されているかを多方面で監視します。ニューラルネットワークが意味理解や情報検索能力を高めるにつれ、AI応答におけるブランド露出のモニタリングは、AI駆動の検索やコンテンツ生成時代のブランド可視性と評判管理においてますます重要となります。
ニューラルネットワークの効果的な訓練には、研究者や実務者が克服すべき多くの課題があります。過学習は、ネットワークが訓練データのノイズや特異性まで覚えすぎてしまい、未知データでの汎化性能が低下する現象で、特にパラメータ数が多い深層ネットワークで顕著です。未学習は逆に、ネットワークの表現力や訓練が不十分でデータのパターンを捉えきれない問題です。勾配消失問題は、非常に深いネットワークで逆伝播時の勾配が極端に小さくなり、初期層の重みがほとんど更新されなくなる現象です。勾配爆発問題はその逆で、勾配が極端に大きくなり訓練が不安定になります。現代的な解決策には、バッチ正規化(層への入力正規化による安定化)、残差接続(スキップ接続による勾配流の確保)、勾配クリッピング(勾配値の上限設定)などがあります。L1・L2正則化による大きな重みへのペナルティ付与や、ドロップアウトによるランダムなニューロン無効化で汎化性能を高めることも重要です。最適化手法(Adam、SGD、RMSpropなど)や学習率の選択も訓練効率と最終性能に大きな影響があります。モデルの複雑さ、データ量、正則化強度、最適化パラメータを適切にバランスさせることが、効果的な学習には不可欠です。
ニューラルネットワークのアーキテクチャ進化は、情報処理の高度化に向けて明確な軌跡をたどっています。初期のフィードフォワードネットワークは固定サイズ入力しか扱えず、時系列や順序依存性を捉えられませんでした。**リカレントニューラルネットワーク(RNN)**はフィードバックループを導入し、時系列処理を実現しましたが、勾配消失問題や逐次計算による並列化困難という欠点がありました。長短期記憶(LSTM)はメモリセルとゲート機構で一部を解決しましたが、やはり逐次処理型でした。革新となったのがトランスフォーマーネットワークで、注意機構によって再帰構造を完全に排除。ネットワークが入力全体の異なる部分に動的に注目し、すべての入力に対して重み付き和を並列計算できます。これにより長距離依存も効率的に捉えつつ、GPUクラスタによる完全な並列化が可能となりました。トランスフォーマーは大規模(現代の大規模言語モデルは数十億~数兆パラメータ)かつ多様なタスクで圧倒的な効果を発揮し、最先端AIシステムの標準アーキテクチャへと進化しました。アーキテクチャ的な革新と計算資源・データ規模の拡大が、ニューラルネットワークの限界を押し広げ続けています。
ニューラルネットワーク分野は急速に進化し、今後も有望な方向性が続々と登場しています。ニューロモルフィックコンピューティングは、生物の神経回路網により近いハードウェア実装を目指し、さらに高効率・高性能な計算を実現しようとしています。Few-shot・Zero-shot学習は、少数またはゼロの例からニューラルネットワークが学習できるようにし、人間に近い学習能力を目指す研究分野です。説明性・解釈性も重要性を増しており、医療・金融・司法などハイリスク分野でニューラルネットワークが何を学び、どのように意思決定するかの可視化手法が開発されています。連合学習は、個人情報を集中管理せずに分散データでモデル訓練を可能にし、プライバシー問題に対応します。量子ニューラルネットワークは量子コンピュータの原理とニューラルネットワークを組み合わせ、特定問題での指数的高速化を目指す最先端分野です。マルチモーダルニューラルネットワークは、テキスト・画像・音声・動画など複数データタイプを統合的に扱い、より包括的なAIシステムを実現します。省エネ型ニューラルネットワークも、モデルの訓練・運用時の計算コストや環境負荷を低減するために活発に研究されています。こうした進化により、ニューラルネットワークの高度化とAI監視システム(AmICited等)への統合は、ChatGPT、Perplexity、Google AI Overviews、Claudeといった多様なプラットフォーム上でのブランド露出の把握・管理に今後ますます重要性を増していくでしょう。
ニューラルネットワークは、人間の脳における生物学的ニューロンの構造と機能に着想を得ています。脳では、ニューロンがシナプスを介して電気信号で通信し、経験に応じて強化や弱化が行われます。人工ニューラルネットワークは、重み付きリンクで接続されたニューロンの数学的モデルを用いることで、この動作を模倣し、データから学習・適応することができ、生物の脳が情報を処理し記憶を形成する方法と類似しています。
バックプロパゲーションは、ニューラルネットワークの学習を可能にする主要なアルゴリズムです。順伝播では、データがネットワーク層を通過して予測を生成します。その後、ネットワークは損失関数を用いて予測値と実際の出力との誤差を計算します。逆伝播では、この誤差がネットワークを逆方向に伝播し、微分計算によって各重みやバイアスが誤差にどれだけ寄与したかを算出します。重みは誤差が最小となる方向に調整され、通常は勾配降下法で最適化されます。
代表的なニューラルネットワークのアーキテクチャには、フィードフォワードネットワーク(データが一方向に流れる)、畳み込みニューラルネットワーク(CNN、画像処理に最適化)、リカレントニューラルネットワーク(RNN、時系列や逐次データ向け)、長短期記憶ネットワーク(LSTM、記憶セルを持つRNNの改良型)、トランスフォーマーネットワーク(注意機構による並列処理)があり、それぞれ画像認識や自然言語処理など異なるタスクやデータに特化しています。
ChatGPT、Perplexity、Claudeといった現代のAIシステムは、注意機構を活用したトランスフォーマーベースのニューラルネットワーク上に構築されています。これらのニューラルネットワークは、文脈理解や一貫したテキスト生成、複雑な推論タスクを可能にします。大量のデータからパターンを学び、言語の繊細な特徴を捉える能力は、会話型AIの精度向上に不可欠となっています。
ニューラルネットワークの重みは、ニューロン間接続の強さを制御し、各入力が出力に及ぼす影響の度合いを決定します。バイアスはニューロンの活性化閾値を調整する追加パラメータで、入力が弱い場合でもニューロンが活性化できるようにします。重みとバイアスは学習可能なパラメータであり、訓練時に調整されることで複雑なパターンの学習を実現します。
活性化関数はニューラルネットワークに非線形性を導入し、データ内の複雑な非線形関係を学習できるようにします。もし活性化関数がなければ、多層化しても線形変換にしかならず、ネットワークの表現力が大幅に制限されます。代表的な活性化関数にはReLU(Rectified Linear Unit)、シグモイド、tanhなどがあり、各関数が異なる非線形性を導入することで、ネットワークが高度なパターンや予測を実現できます。
隠れ層は入力層と出力層の間にある中間層であり、ネットワークの計算の大部分がここで行われます。これらの層は、生の入力データから特徴を抽出・変換し、より抽象的な表現へと進化させます。隠れ層の深さや幅は、ネットワークがどれだけ複雑なパターンを学習できるかに直結しており、深いネットワークほど高度な関係性を捉えられますが、計算資源や訓練の工夫も必要となります。
ChatGPT、Perplexity、その他のプラットフォームでAIチャットボットがブランドを言及する方法を追跡します。AI存在感を向上させるための実用的なインサイトを取得します。
ナレッジグラフとは何か、その仕組み、そして現代のデータ管理・AI応用・ビジネスインテリジェンスに不可欠な理由を解説します。...
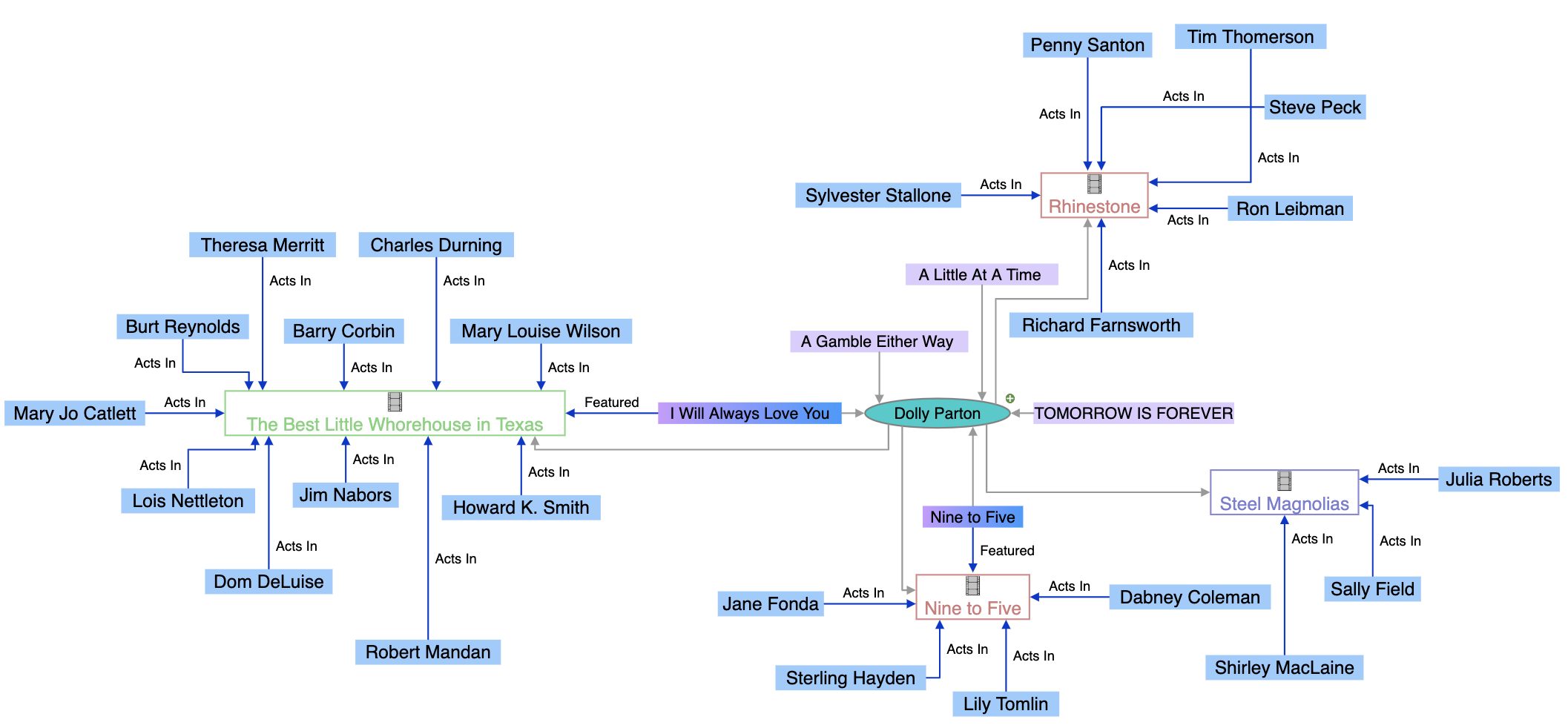
ナレッジグラフとは何か、検索エンジンがエンティティ間の関係をどのように理解するために活用しているのか、そして現代のAIでの可視性やブランドモニタリングにおいてなぜ重要なのかを解説します。...
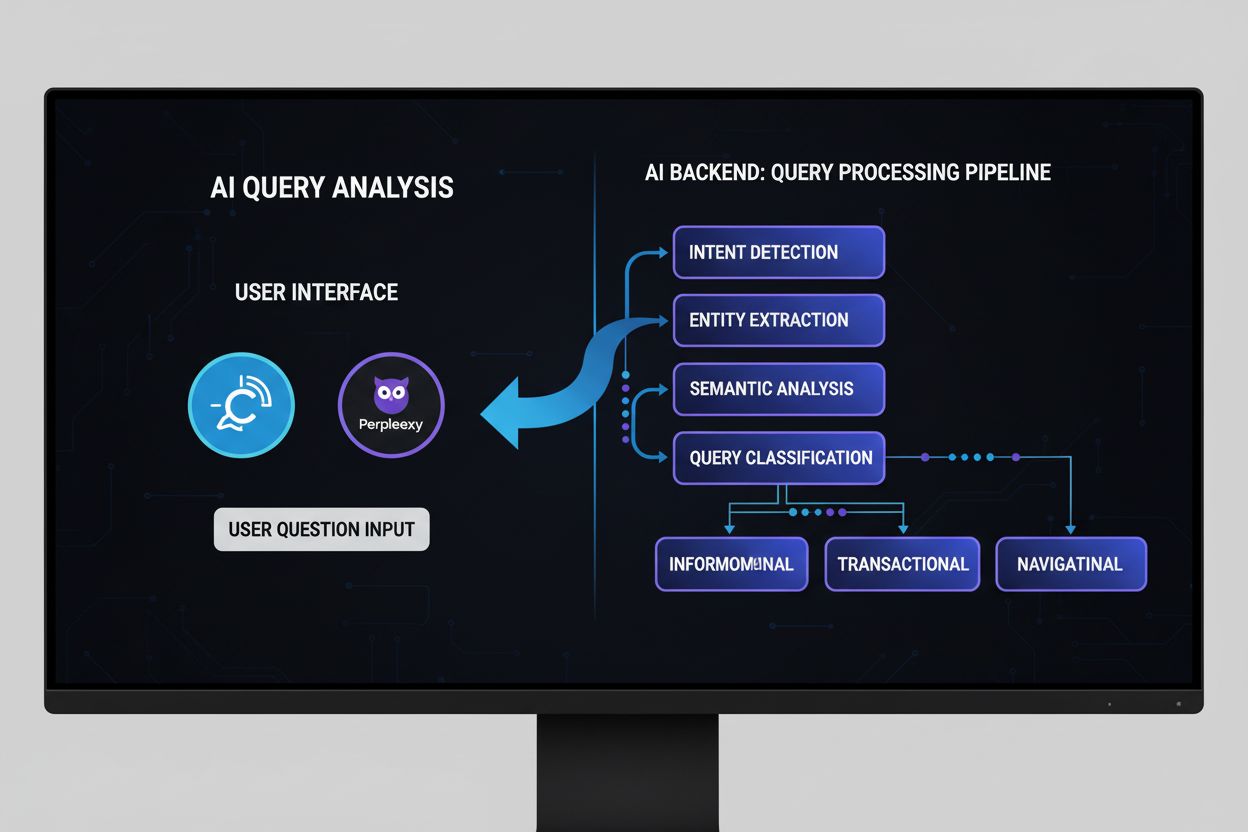
AIクエリアナリシスとは何か、その仕組み、そしてAI検索での可視性向上の重要性について解説します。クエリ意図の分類、意味解析、ChatGPT、Perplexity、Google AIを横断したモニタリングについて理解しましょう。...