
NoAIメタタグ:ヘッダーによるAIアクセス制御
noaiとnoimageaiメタタグを実装し、AIクローラーによるウェブサイトコンテンツへのアクセスを制御する方法を学びます。AIアクセス制御ヘッダーと実装方法の完全ガイド。...
1 分で読める

AIのトレーニングシステムやウェブクローラーに対して、ウェブサイトのコンテンツを機械学習モデルのトレーニングに使用しないよう指示するHTMLメタタグ。DeviantArtによって最初に導入され、無断のAIデータ収集を懸念するクリエイターのためのコンテンツ保護メカニズムおよびオプトアウト信号として機能します。
AIのトレーニングシステムやウェブクローラーに対して、ウェブサイトのコンテンツを機械学習モデルのトレーニングに使用しないよう指示するHTMLメタタグ。DeviantArtによって最初に導入され、無断のAIデータ収集を懸念するクリエイターのためのコンテンツ保護メカニズムおよびオプトアウト信号として機能します。
NoAIメタタグは、HTMLメタタグとして実装されるコンテンツ保護メカニズムであり、AIトレーニングシステムやウェブクローラーに対して、そのウェブサイトのコンテンツを機械学習モデルのトレーニングに使用しないよう通知するものです。NoAIディレクティブは2022年9月にDeviantArtによって最初に導入され、アーティストの作品が同意や報酬なくジェネレーティブAIモデルの学習に利用されることへの懸念から草の根的に生まれました。このメタタグは、シンプルなHTML宣言をウェブページのヘッダーに追加することで、トレーニング目的での利用をAIシステムに対して明確に拒否する意志を伝えます。多くの法域で法的効力はありませんが、NoAIタグは、急速に進むAIによるデータ収集の時代において知的財産を守ろうとするクリエイターにとって重要なオプトアウト手段となっています。
ウェブクローラー(ボット、スパイダー、スクレイパーとも呼ばれます)は、インターネット上のリンクをたどりながら体系的に巡回し、コンテンツをダウンロードしてインデックス、分析、またはさまざまな目的でデータ収集を行う自動化ソフトウェアです。これらのクローラーは、ウェブサイトのルートディレクトリにあるrobots.txtファイルを読み込むことで、サイトのどの部分に自動訪問者がアクセスしてよいか、またはしてはいけないかの指示を取得します。robots.txtファイルはUser-agent、Disallow、Allowなどのディレクティブでクローラーの許可範囲を指定しますが、遵守は任意であり、クローラー開発者の判断に委ねられています。robots.txt以外にも、HTTPヘッダーやメタタグによってコンテンツの利用権や制限に関する追加のシグナルを送ることができます。クローラーの種類によって、これらのシグナルへの対応度は異なります:
| クローラー種別 | robots.txt遵守度 | メタタグ尊重度 | AIトレーニング利用 |
|---|---|---|---|
| 検索エンジン | 高 | 高 | 限定的 |
| AIトレーニングボット | 中 | 中 | あり |
| 商用スクレイパー | 低 | 低 | さまざま |
| 学術ボット | 高 | 中 | 研究のみ |
| 悪質ボット | なし | なし | 制限なし |
noaiとnoimageaiディレクティブは、どちらもコンテンツ保護を目的としながらも、その適用範囲と具体性に違いがあります。noaiディレクティブはページ内のすべてのコンテンツ(テキスト、画像、コード、その他のメディア)をAIトレーニング目的での利用から拒否する広範な信号であり、混在コンテンツや包括的な保護を求めるウェブサイトに適しています。一方、noimageaiディレクティブは画像コンテンツのみを対象とし、テキストやその他の非画像素材はトレーニングに使われる可能性を残しつつ、視覚的な資産だけをAIモデルの学習から守ります。この違いは、テキストベースのAIによるインデックス化(検索エンジンやアクセシビリティ目的)は許容したいが、画像はジェネレーティブ画像モデルから守りたい場合に特に重要です。実装例は以下の通りです:
<!-- すべてのコンテンツを包括的に保護 -->
<meta name="robots" content="noai">
<!-- 画像のみを保護 -->
<meta name="robots" content="noimageai">
<!-- 両方の組み合わせで最大限の明確化 -->
<meta name="robots" content="noai, noimageai">
NoAIメタタグは、複数の方法で実装でき、技術環境や目的に応じて適した手段を選択できます。最も簡単なのは、HTMLの<head>セクションにメタタグを直接追加する方法で、ページ単位で柔軟にカスタマイズ可能です。多数のページを持つサイトや全体一括適用を目指す場合は、HTTPレスポンスヘッダーでディレクティブを設定すれば、個別ページの修正なしに全コンテンツへ一貫して適用できます。また、robots.txtファイルにAIクローラー向けディレクティブを記述する方法もありますが、メタタグやヘッダーに比べて標準化度は低めです。主な実装方法は以下の3つです:
<!-- 方法1: HTMLメタタグ(最も一般的) -->
<head>
<meta name="robots" content="noai">
</head>
# 方法2: robots.txtディレクティブ
User-agent: *
Disallow: /
X-Robots-Tag: noai
# 方法3: HTTPヘッダー(.htaccessやサーバー設定で)
X-Robots-Tag: noai
Apacheサーバーの場合、.htaccessに追加:
<FilesMatch "\.(html|php)$">
Header set X-Robots-Tag "noai"
</FilesMatch>
Nginxサーバーの場合、サーバーブロックに追加:
add_header X-Robots-Tag "noai" always;
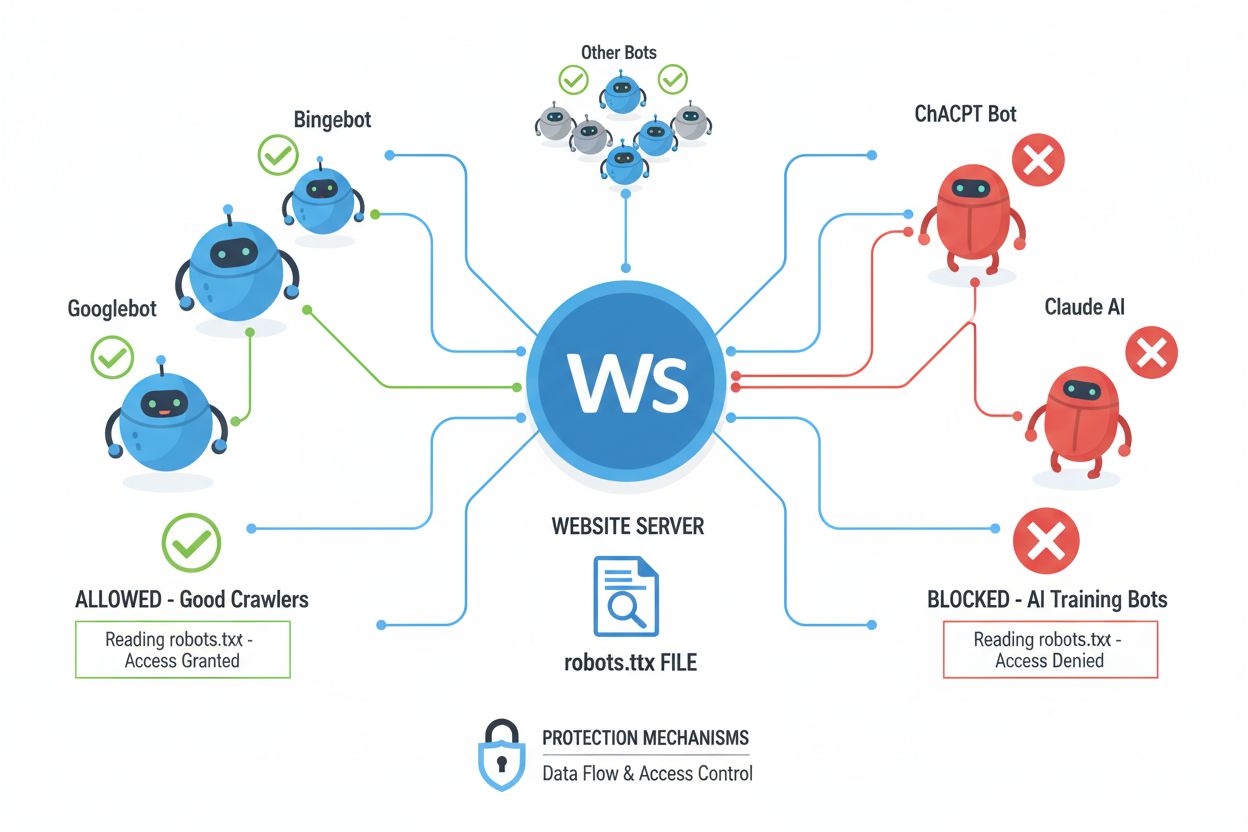
NoAIメタタグはコンテンツ保護に向けた重要な一歩ですが、名誉ベースで運用されており、AI開発者やデータスクレイパーがこのシグナルを尊重するかどうかに完全に依存します。OpenAI、Google、Anthropicといった大手AI企業はクローラーでNoAIディレクティブの尊重を始めていますが、悪質業者や不正スクレイパーはこれらの信号を無視することが多く、意図的なデータ窃盗に対してはタグの効果がありません。また、NoAIは将来のトレーニングを防ぐだけで、既に収集されモデルに組み込まれたデータの削除や、違反時の法的救済はできません。AIシステムによる遵守率には大きな差があり、尊重するものもあれば意図的に回避するものもあるため、NoAIは有用ですが不完全な解決策です。さらに、直接ダウンロードやスクリーンショット、手動コピーに対する保護はなく、単にディレクティブを無視する競合他社の利用も防げません。したがって、NoAIは包括的なコンテンツ保護戦略の一層として捉え、他の手段と組み合わせて利用すべきです。
NoAIメタタグは主要なAI企業やプラットフォームで大きく採用が進み、OpenAI、Google、Stability AIは自社のトレーニングパイプラインでこのディレクティブを尊重することを公表しています。DeviantArtによるNoAIの導入は、倫理的なAI開発やクリエイターの同意に関する業界全体の議論に影響を与え、AI開発者・コンテンツ制作者双方の認知を高めました。ただし、依然として業界全体での採用は一貫しておらず、中小AI企業や学術研究者、商用スクレイパーでの遵守状況はさまざまです。**C2PA(Coalition for Content Provenance and Authenticity)**のような競合規格の登場や、機械判読可能な権利表現に関する議論からも分かるように、業界は自主的なメタタグを超えた、より高度で法的裏付けのある保護メカニズムへと進化しつつあります。業界団体や標準化団体もこれらの保護策の正式化を積極的に進めており、今後AI規制がクリエイターの意思表明への明示的な遵守を要求することで、NoAIが自主的なシグナルから法的強制力を持つ要件へと変わる可能性もあります。
NoAIによる保護は単独ではなく、技術的・法的・監視的な多層的アプローチの一部として実施するのが望ましいです。効果を最大化するためのベストプラクティス:
加えて、全ページに適切なディレクティブが実装されているか定期的に監査し、公開AIデータセットやトレーニングレポジトリで自分のコンテンツが使われていないか自動ツールでスキャンすることも検討しましょう。NoAIの実装内容はコンテンツガバナンスポリシーとして文書化し、ユーザー投稿型プラットフォームであればこれらの取り組みを利用者へ周知することも重要です。
noaiディレクティブはすべてのコンテンツタイプ(テキスト、画像、コードなど)をAIトレーニングから保護します。一方、noimageaiは画像コンテンツのみを保護します。包括的に保護したい場合はnoai、テキストのインデックス化は許可したいが画像だけを生成AIモデルから守りたい場合はnoimageaiを使用してください。
いいえ、NoAIメタタグはあくまで名誉ベースで機能し、AI開発者がそれを尊重するかどうかに依存します。OpenAIやGoogleのような大手企業はこれを尊重しますが、不正な業者や悪質なスクレイパーはこれらの信号を頻繁に無視するため、完全な解決策ではなく一つの保護レイヤーに過ぎません。
HTMLメタタグをページヘッダーに追加する、サーバーでHTTPレスポンスヘッダーを設定する、robots.txtファイルにディレクティブを含める、の3つの方法があります。HTMLメタタグを使う方法が最も一般的で多くのウェブサイト運営者にとって簡単です。
OpenAI(ChatGPT)、Google、Anthropic(Claude)、Stability AIなどの大手AI企業は、トレーニングパイプラインでNoAIディレクティブを尊重することを公言しています。ただし、中小AI企業や学術研究者、商用スクレイパーでは遵守状況がまちまちです。
はい、両方を同時に使うことで最大限の効果を得られます。NoAIメタタグとrobots.txtディレクティブは、それぞれ異なる種類のクローラーやシステムへコンテンツ保護の意図を伝える役割を果たします。
NoAIに加え、HTTPヘッダー、robots.txtルール、ウォーターマーキング、アクセス制御、法的利用規約など他の保護手段も組み合わせましょう。AIのデータセット内で自分のコンテンツを監視し、不正利用の追跡ツールも活用してください。
大手AI企業には広く採用されていますが、NoAIはまだ正式なW3C標準ではありません。ただし、C2PAや機械判読可能な権利表現など、より高度な標準化を目指す業界団体による取り組みが進められており、いずれ法的な裏付けが与えられる可能性があります。
NoAIはrobots.txt、HTTPヘッダー、ウォーターマーキング、アクセス制御、法的保護など他の手段と組み合わせて使うことで最も効果を発揮します。単独では完全な保護はできないため、重層的な対策が包括的なコンテンツセキュリティには推奨されます。
AmICitedのAI監視プラットフォームで、どのAIシステムがあなたのブランドやコンテンツを引用しているかを追跡しましょう。ChatGPT、Perplexity、Google AI Overviews、その他のAIシステムであなたの作品がどう使われているか正確に把握できます。
noaiとnoimageaiメタタグを実装し、AIクローラーによるウェブサイトコンテンツへのアクセスを制御する方法を学びます。AIアクセス制御ヘッダーと実装方法の完全ガイド。...

noai メタタグについて、その仕組みやAIのトレーニングデータ収集を防ぐ方法、制限事項、そしてウェブサイトでの実装方法を学び、あなたのコンテンツをジェネレーティブAIプログラムから守る方法を解説します。...
noaiメタタグがAIの学習からコンテンツを本当に守れるのかについてのコミュニティディスカッション。ユーザーの実体験やこの方法の限界について共有されています。...