
クエリリファインメント
クエリリファインメントは、AI検索エンジンでより良い結果を得るために検索クエリを最適化する反復的なプロセスです。ChatGPT、Perplexity、Google AI、Claudeでどのように機能し、情報検索を向上させるかを解説します。...
1 分で読める
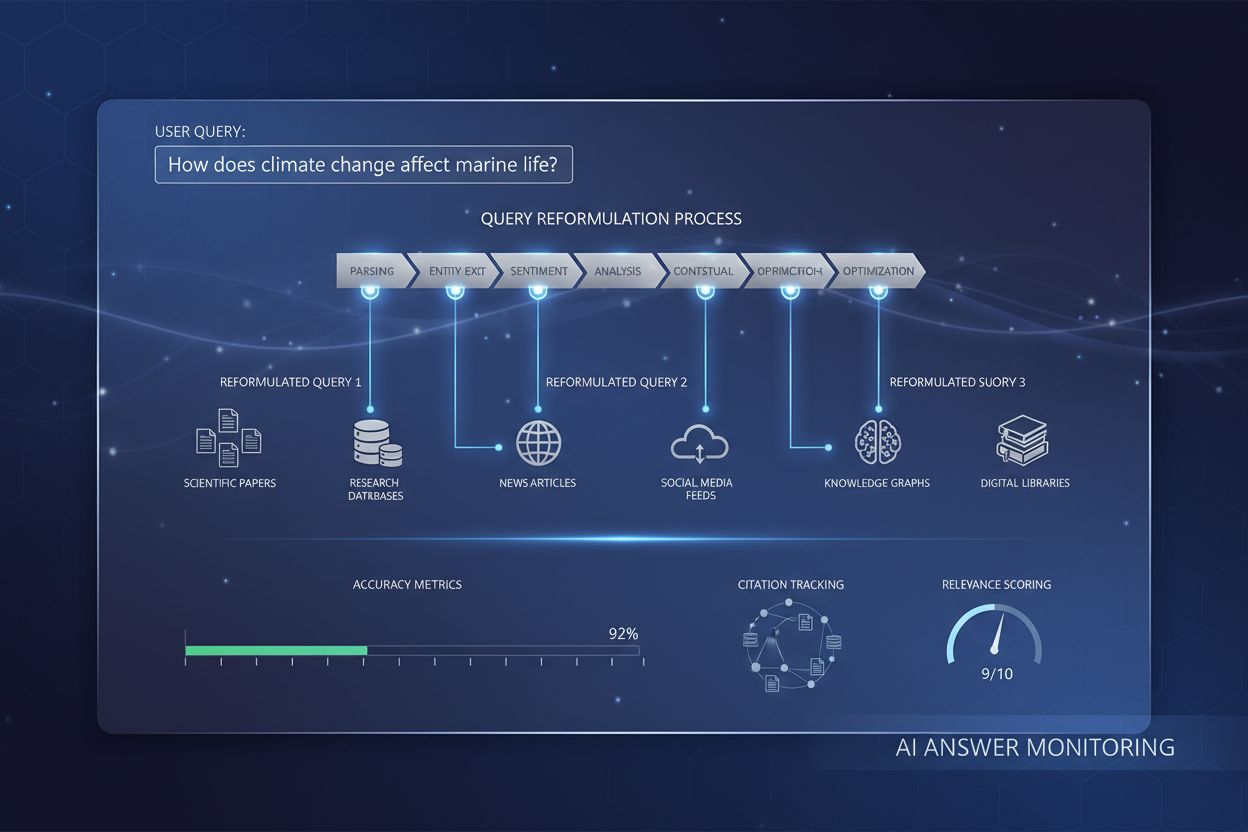
クエリ再構成は、AIシステムがユーザーのクエリを解釈し、再構築し、強化することで情報検索の正確性と関連性を向上させるプロセスです。単純または曖昧なユーザー入力を、AIシステムの理解と一致する、より詳細でコンテキストが豊かなバージョンに変換し、より正確かつ包括的な回答を可能にします。
クエリ再構成は、AIシステムがユーザーのクエリを解釈し、再構築し、強化することで情報検索の正確性と関連性を向上させるプロセスです。単純または曖昧なユーザー入力を、AIシステムの理解と一致する、より詳細でコンテキストが豊かなバージョンに変換し、より正確かつ包括的な回答を可能にします。
クエリ再構成とは、ユーザーが入力した元の検索クエリを変換・拡張・書き換えし、情報検索システムの能力やユーザーの本来の意図により近づけるプロセスです。人工知能や自然言語処理(NLP)の文脈では、クエリ再構成は、ユーザーが自然に表現する情報ニーズとAIシステムがそれを解釈・処理する方法との間の重要なギャップを埋める役割を担っています。現代のAIシステムにおいてこの技術は不可欠であり、ユーザーが曖昧な表現を用いたり、分野特有の用語を一貫性なく使ったり、検索精度を高める文脈情報を含めなかったりするケースが多いためです。クエリ再構成は情報検索・意味理解・機械学習の交差点で機能し、同義語拡張・文脈強化・構造再編成など複数の視点からクエリを再解釈することで、より関連性の高い結果の生成を可能にします。AIシステムがクエリを知的に再構成することで、回答の質を大きく高め、曖昧さを減らし、取得される情報がユーザーの意図により正確にマッチするようになります。
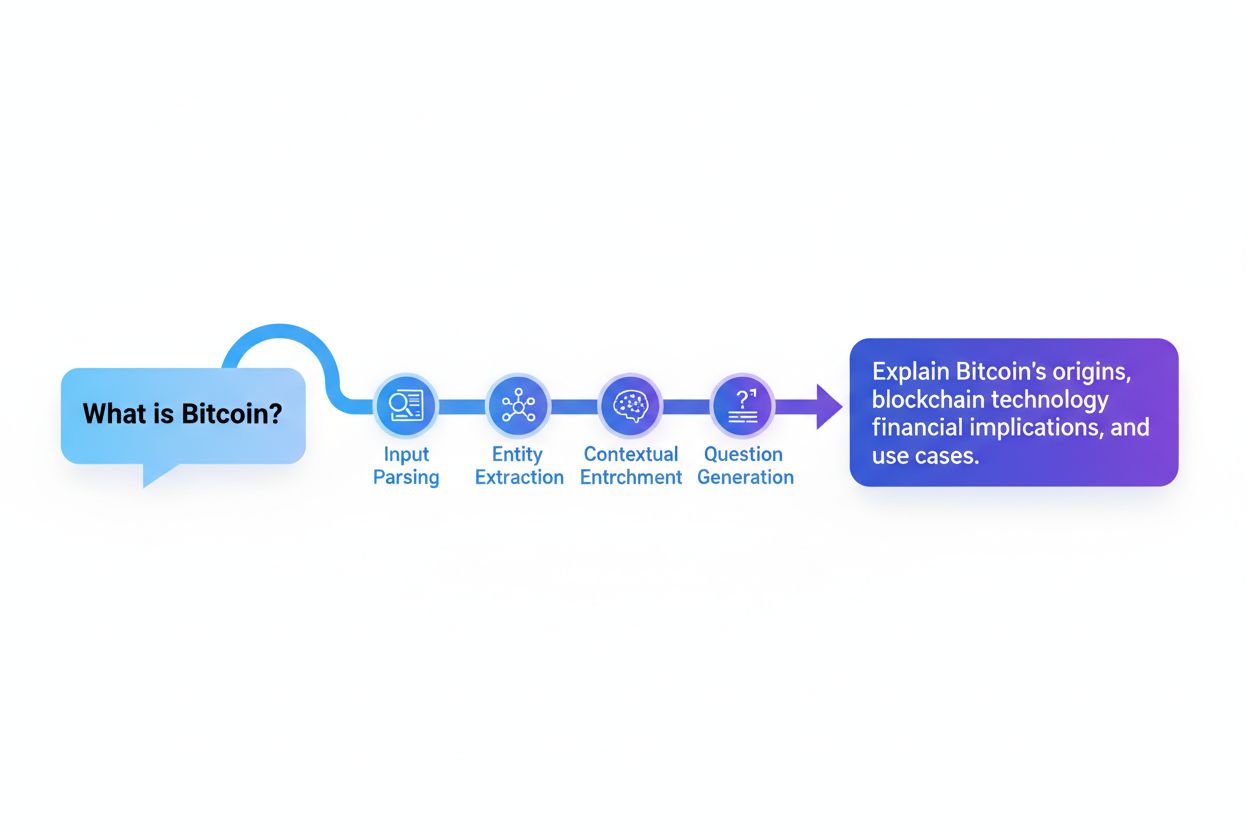
クエリ再構成システムは通常、ユーザーの生の入力を最適化された検索クエリに変換するための5つの相互連携するコンポーネントから構成されます。入力解析は元のクエリを構成要素に分解し、キーワード・フレーズ・構造要素を特定します。エンティティ抽出は固有名詞(人名、地名、組織名、製品など)や意味的重みを持つ分野固有の概念を特定します。感情分析は元のクエリの感情的トーンや評価的スタンスを保持し、再構成後もユーザー本来の視点を維持します。文脈分析はセッション履歴・ユーザープロファイル情報・ドメイン知識を取り入れ、クエリに暗黙的な意味を付加します。質問生成は陳述文や断片を検索システムがより効果的に処理できる構造化された質問に変換します。
| コンポーネント | 目的 | 例 |
|---|---|---|
| 入力解析 | クエリを意味単位に分割・トークン化 | “best Python libraries” → [“best”, “Python”, “libraries”] |
| エンティティ抽出 | 固有名詞や分野概念の特定 | “Apple’s latest iPhone” → Entity: Apple(企業), iPhone(製品) |
| 感情分析 | 評価トーン・ユーザー視点の保持 | “terrible customer service” → 否定的感情を再構成に反映 |
| 文脈分析 | セッション履歴・ドメイン知識の取り込み | 前回「機械学習」の検索が今回の「ニューラルネットワーク」クエリに影響 |
| 質問生成 | 断片を構造化された質問に変換 | “Python debugging” → “How do I debug Python code?” |
クエリ再構成プロセスは、クエリの質と関連性を段階的に高める体系的な6ステップで進行します。
入力解析と正規化
エンティティと概念の抽出
感情と意図の保持
文脈強化
クエリ拡張と同義語生成
最適化と評価
クエリ再構成では、従来の語彙的手法から最先端のニューラル手法まで多様な技法が用いられます。同義語ベースの拡張は、WordNetなどのリソースやWord2Vec・GloVeなどの単語埋め込み、BERTなどの文脈モデルで意味的に類似した語を抽出します。クエリ緩和は初期結果が不十分な場合に検索条件を段階的に緩め、例えばレア語の除去や日付範囲の拡大などでリコールを高めます。ユーザーフィードバック・セッション文脈統合は、ユーザーの実際の行動から学習し、ユーザーが関連あると判断した結果に基づき再構成を最適化します。トランスフォーマーベースの書き換えは、T5やGPTのようなモデルを使い、大規模なクエリ対データセットからパターンを学習して全く新しいクエリを生成します。ハイブリッドアプローチでは複数の手法を組み合わせ、例えば自信度の高い語にはルールベースの同義語拡張、曖昧なフレーズにはニューラルモデルを適用します。実際のシステムでは複数の再構成パターンを生成し、学習された関連度モデルでランク付けするアンサンブル手法も一般的です。例えばECサイトでは、商品専門の同義語辞書とBERT埋め込みを組み合わせ、標準的な商品用語と口語的表現双方に対応し、医療検索では専門オントロジーとトランスフォーマーモデルを併用して臨床的正確性を担保します。
クエリ再構成はAIシステムの性能やユーザー体験の多方面にわたり大きな改善をもたらします。
検索精度の向上:再構成されたクエリはユーザーの意図をより正確に捉え、高品質の文書取得やより的確なAI回答につながります。システムが同義語や関連概念でクエリを拡張することで、元のクエリとは異なる用語を用いた文書も取得でき、真に関連性の高い情報を得られる確率が大幅に上がります。
リコール・網羅性の強化:クエリ拡張により意味的バリエーションや関連概念を探索し、取得文書数が増加します。特に専門分野で用語のばらつきが大きい場合、語彙差による情報の取りこぼしを防げます。
曖昧さの除去と明確化:再構成プロセスは文脈を取り入れたり複数解釈を生成することで曖昧・不明瞭なクエリを明確化します。例えば「apple」(果物か企業か)のような場合、文脈別の再構成で的確な結果を取得できます。
ユーザー体験・満足度の向上:より関連性の高い結果が迅速に得られ、ユーザー自身が何度もクエリ修正する手間が減ります。失敗検索や的外れな検索結果が減ることで満足度が向上し、認知的負荷も軽減されます。
スケーラビリティと効率性:様々な語彙・習熟度・言語的背景を持つ多様なユーザーにも対応可能です。1つの再構成エンジンで複数分野や言語をカバーでき、インフラ増強を抑えながら拡張性を確保できます。
継続的な改善・学習:再構成システムはユーザーのインタラクションデータで学習し、成功につながった再構成をもとに戦略を随時最適化できます。これにより利用が進むほど性能が向上する好循環が生まれます。
分野適応・専門化:医療・法務・技術分野などには、ドメイン固有のクエリ対データやオントロジーを活用して再構成技術を微調整できます。これにより、汎用的な手法よりも高い専門的精度を実現します。
クエリの多様性への強さ:誤字・文法ミス・口語表現があっても標準化したクエリに再構成でき、特に音声インターフェースやモバイル検索など入力品質が不安定な場合に有効です。
クエリ再構成はAI生成回答の正確性・信頼性に直結するため、AI回答モニタリングプラットフォーム(例:AmICited.com)では極めて重要な役割を果たします。AIシステムが回答生成前にクエリを再構成する場合、その質が取得文書や引用の適切さを直接左右します。再構成が不適切だと、AIは無関係な文書を取得し、根拠の薄い回答や不適切な情報源の引用に繋がります。AIモニタリング・引用追跡の観点では、どのようにクエリが再構成されたかを把握することで、AIが実際にユーザーの意図した質問に答えているか、それとも歪められた解釈に基づいているかを検証可能です。AmICited.comは、AIシステムがクエリをどのように再構成したかを追跡し、AI生成回答で引用された情報源が元のユーザー質問に本当に関連しているかを保証します。このモニタリングは、クエリ再構成がユーザーには見えない「裏側」で行われるため特に重要です。ユーザーは最終的な回答と引用しか目にせず、その裏でクエリがどう変換されたか把握できません。クエリ再構成パターンを分析することで、AIが元の意図から大きく逸脱した再構成に基づく回答を生成していないか検出し、ユーザーに届く前に精度問題を特定できます。さらに、再構成が曖昧なクエリに対して適切に複数パターンを生成し横断的な情報統合を行っているか、不当な意図推定をしていないかも評価できます。
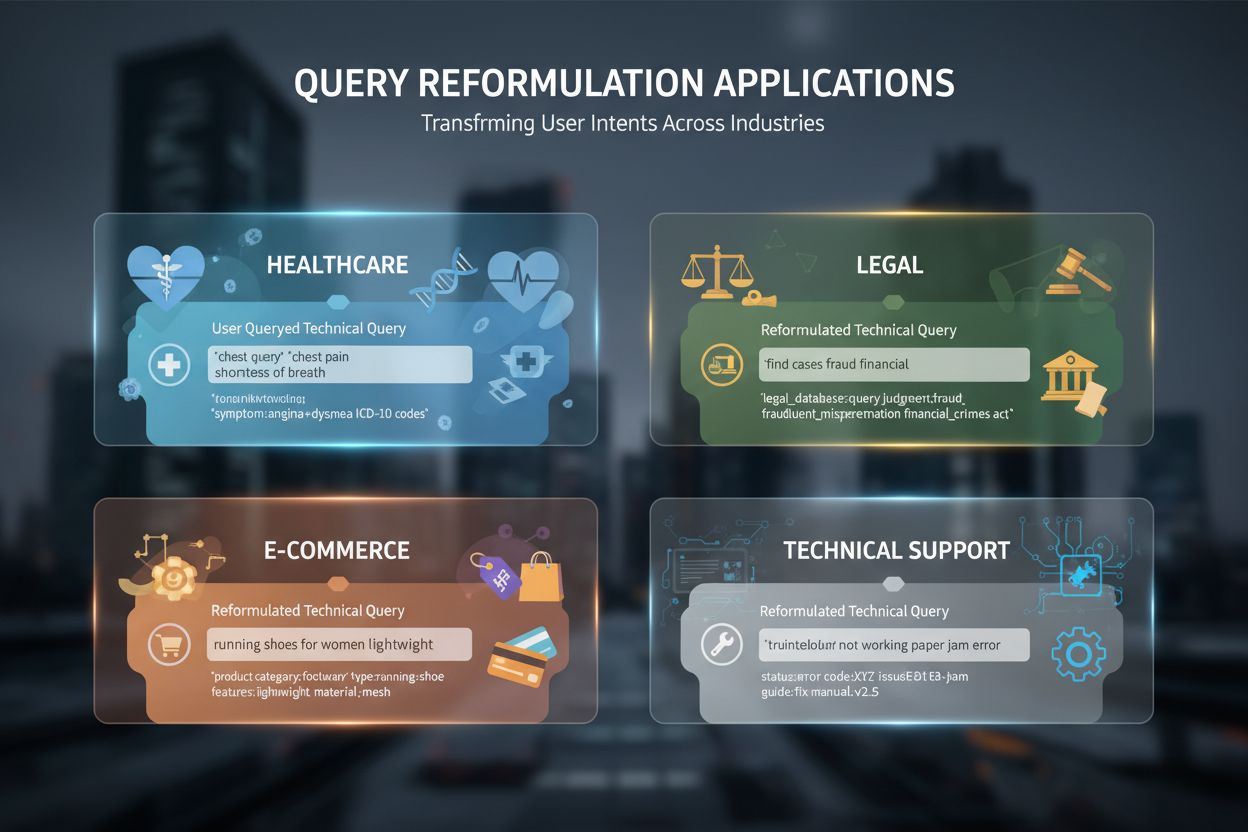
クエリ再構成は、様々なAI主導のアプリケーションや産業で不可欠となっています。医療・医学研究では、患者が「heart attack」と検索し、医学文献は「myocardial infarction」と記載するなど、語彙ギャップを再構成で埋め、臨床的に正確な情報の取得を実現します。法務文書解析システムでは、厳密かつ古典的な法文書の言い回しと現代的な検索語のギャップを再構成で橋渡しし、どのような表現でも関連する判例を見つけられます。技術サポートでは、ユーザーの口語的な問題記述(例:“my computer is slow”)を技術用語(“system performance degradation”)に変換し、適切なトラブルシューティングガイドの検索に役立てます。EC検索最適化では、ユーザーが「ランニングシューズ」と入力し、カタログでは「アスレチックフットウェア」や特定ブランド名が使われている場合でも、用語差を超えて目的の商品にたどり着けます。会話AI・チャットボットでは、複数ターンの対話で暗黙的文脈を再構成に反映し、フォローアップ質問も前回の内容を盛り込んで再構成します。RAG(検索拡張生成)システムは特にクエリ再構成を重視し、ユーザー質問に本当に関連する文脈を複数のバリエーションで検索し、回答の質を高めます。例えば「データベースクエリの最適化方法は?」という質問を「database query performance tuning」「SQL optimization techniques」「query execution plans」など複数のバリエーションに再構成し、幅広い文脈を取得してから詳細な回答を生成します。
利点が多い一方で、クエリ再構成には実務上いくつかの大きな課題が伴います。計算コストの増加は、複数の再構成クエリ生成とその関連性評価で著しく上昇します。各再構成案ごとに処理が必要であり、特にリアルタイム用途では精度向上と応答遅延のバランスが重要です。学習データ品質は再構成の有効性を左右し、不適切なクエリ対データやバイアスのあるデータセットで訓練されたシステムは、その偏りを再構成にも反映し、問題を悪化させるリスクがあります。過剰再構成リスクは、バリエーションを増やしすぎて元の意図を見失い、かえって関連性の低い結果を増やしてしまうことです。分野適応の困難さもあり、一般的なWebクエリで訓練したモデルは、医療や法務など専門分野では再訓練やドメイン特化調整が不可欠です。精度とリコールのトレードオフも根本問題で、積極的な拡張はリコールを高めますが無関係な結果も増え、逆に抑制的な再構成は精度を維持しつつ関連情報を見逃しやすくなります。バイアスの新規発生は、再構成システムが訓練データ中の社会的偏見をそのまま反映し、例えば「看護師」のクエリを女性に偏った結果に導いてしまうなど、検索結果やAI回答で差別を助長する危険があります。
クエリ再構成はAIの進化とともに急速に進歩し続けています。LLM(大規模言語モデル)による再構成の進化で、より高度でコンテキストに富んだクエリ変換が可能となり、ユーザーの微妙な意図も理解し自然かつ意味豊かな再構成を生成できるようになっています。マルチモーダルAI統合では、テキスト以外に画像・音声・動画クエリも扱い、視覚検索クエリをテキスト記述に再構成するなど、検索対象の幅が拡大します。パーソナライズと学習によって、再構成システムがユーザーごとの語彙・傾向・検索パターンに適応し、個々のスタイルに合った再構成を生成することが期待されます。リアルタイム適応再構成では、中間検索結果に応じて動的にクエリを再構成し、初期再構成がさらなる改善にフィードバックされるループが形成されます。知識グラフ統合により、エンティティや関係性の構造化知識を活用した、より意味精度の高い再構成も実現可能です。評価・ベンチマーク標準の整備も進み、再構成品質の客観的比較や業界全体の品質底上げに繋がっています。
クエリ再構成は検索精度を高めるためにクエリを変換する広範なプロセスであり、クエリ拡張はその中の具体的な手法で、同義語や関連語を追加します。クエリ拡張は検索範囲を広げることに特化していますが、再構成は構文解析、エンティティ抽出、感情分析、文脈強化など複数の技術を含み、クエリの質を根本的に向上させます。
クエリ再構成は曖昧な語句の明確化や文脈追加、オリジナルクエリの様々な解釈を生成することで、AIシステムがユーザーの意図をより正確に理解できるようにします。これにより、より関連性の高い情報源が検索され、最終的にAIが正確で根拠のある回答と適切な引用を行うことが可能になります。
はい。クエリ再構成は、ユーザー入力を標準化・サニタイズしてメインAIシステムに渡す前のセキュリティ層として機能します。専門の再構成エージェントが潜在的に有害な入力を検出・無効化し、疑わしいパターンをフィルタし、安全で標準化されたフォーマットにクエリを変換することで、プロンプトインジェクション攻撃のリスクを低減します。
RAG(検索拡張生成)システムでは、クエリ再構成がユーザーの質問に本当に関連する文書を取得するために不可欠です。複数のバリエーションにクエリを再構成することで、RAGシステムはより包括的で多様な文脈を取得でき、生成される回答の質と正確性が直接向上します。
実装には用途に応じた技術の選択が必要です。意味的類似性にはBERTやWord2Vecによる同義語拡張、ニューラル再構成にはT5やGPTのようなトランスフォーマーモデル、専門分野にはドメイン固有のオントロジーの活用、ユーザーインタラクションや検索成功率に基づくフィードバックループの導入などが考えられます。
計算コストは手法によって異なります。単純な同義語拡張は軽量ですが、トランスフォーマーベースの再構成は大きなGPUリソースを必要とします。ただし、再構成には小型の専門モデル、最終回答生成には大型モデルを使い分けることでコスト最適化が可能です。多くのシステムはキャッシュやバッチ処理で計算コストを分散しています。
クエリ再構成は引用の正確性に直接影響します。再構成されたクエリがどの文書を取得し引用するかを決定するため、元の意図から大きく逸脱した再構成が行われると、AIは再構成後のクエリに関連する情報源を引用しがちです。AmICitedのようなAIモニタリングプラットフォームはこれらの変換を追跡し、実際のユーザー質問に本当に関連する引用が行われているかを検証します。
はい。クエリ再構成は、トレーニングデータに社会的偏見が含まれている場合、そのバイアスを増幅することがあります。例えば、特定のクエリを再構成する際に、特定の属性や集団に偏った検索結果が強調される場合があります。これを防ぐにはデータセットの精査やバイアス検出、訓練例の多様化、再構成出力の継続的な監視が必要です。
クエリ再構成はAIシステムがあなたのコンテンツをどのように理解し引用するかに影響します。AmICitedはこれらの変換を追跡し、AI生成の回答であなたのブランドが正しく帰属されることを保証します。
クエリリファインメントは、AI検索エンジンでより良い結果を得るために検索クエリを最適化する反復的なプロセスです。ChatGPT、Perplexity、Google AI、Claudeでどのように機能し、情報検索を向上させるかを解説します。...
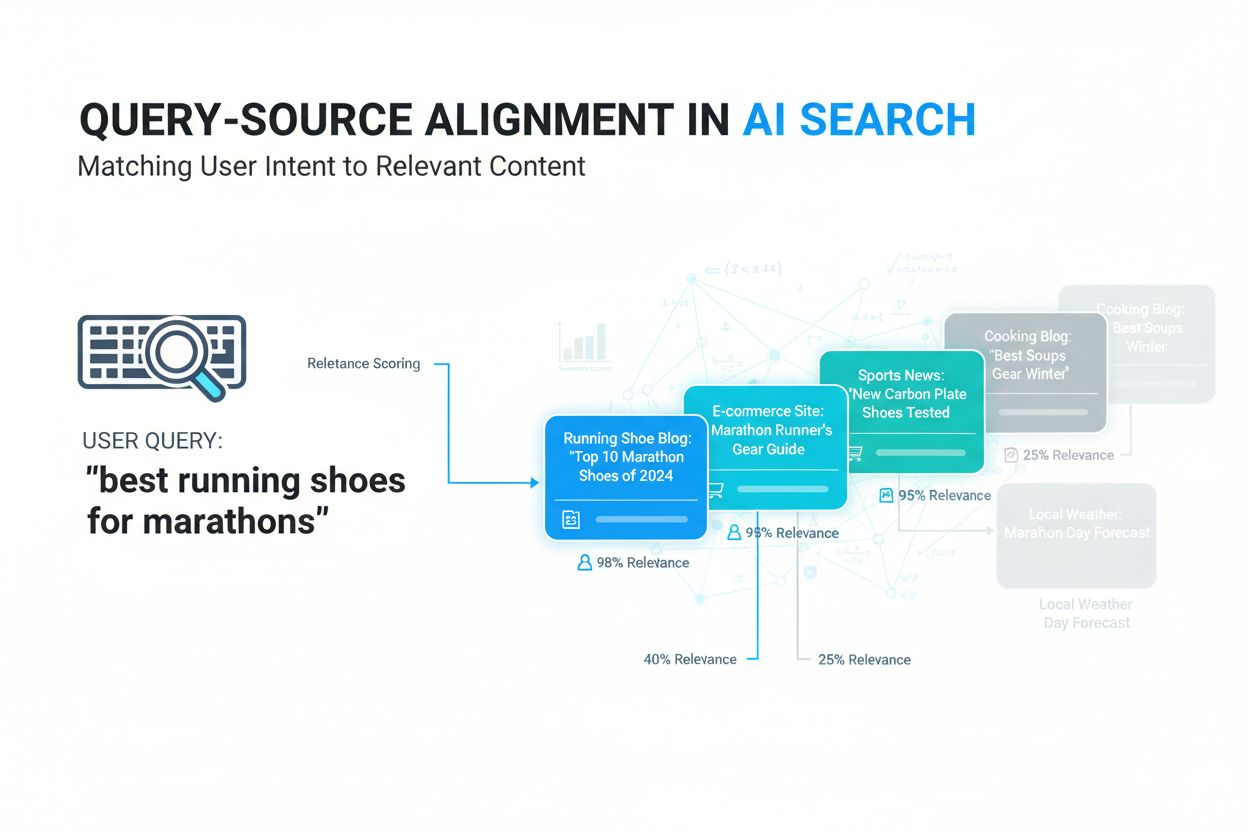
クエリ・ソースアライメントとは何か、AIシステムがどのようにユーザーのクエリと関連ソースをマッチングするのか、そしてGoogle AIオーバービューやChatGPTなどのAI検索プラットフォームでコンテンツの可視性にどのように影響するのかを学びましょう。...
クエリ拡張最適化が語彙ギャップを埋めることでAI検索結果をどのように向上させるかを解説。手法や課題、AIモニタリングやコンテンツ発見の重要性を学びましょう。...
クッキーの同意
閲覧体験を向上させ、トラフィックを分析するためにクッキーを使用します。 See our privacy policy.