
リトリーバル・オーグメンテッド・ジェネレーションの仕組み:アーキテクチャとプロセス
RAGがLLMと外部データソースを組み合わせて正確なAI応答を生成する仕組みを解説。5段階のプロセス、構成要素、ChatGPTやPerplexityなどのAIシステムで重要な理由を理解します。...
1 分で読める

リトリーバル・オーグメンテッド・ジェネレーション(RAG)パイプラインは、AIシステムが応答を生成する際に外部ソースを検索・評価・引用できるようにするワークフローです。ドキュメント検索、セマンティックランキング、LLMによる生成を組み合わせ、実データに基づいた正確で文脈に即した回答を提供します。RAGシステムは、応答前に外部ナレッジベースを参照することでハルシネーションを減らし、事実性や出典明記が求められる用途で不可欠となっています。
リトリーバル・オーグメンテッド・ジェネレーション(RAG)パイプラインは、AIシステムが応答を生成する際に外部ソースを検索・評価・引用できるようにするワークフローです。ドキュメント検索、セマンティックランキング、LLMによる生成を組み合わせ、実データに基づいた正確で文脈に即した回答を提供します。RAGシステムは、応答前に外部ナレッジベースを参照することでハルシネーションを減らし、事実性や出典明記が求められる用途で不可欠となっています。
リトリーバル・オーグメンテッド・ジェネレーション(RAG)パイプラインは、情報検索と大規模言語モデル(LLM)による生成を組み合わせることで、より正確で文脈に即し、検証可能な応答を生み出すAIアーキテクチャです。LLMの学習データのみに頼るのではなく、RAGシステムは回答生成前に外部ナレッジベースから関連ドキュメントやデータを動的に取得し、ハルシネーションを大幅に減らし事実性を向上させます。このパイプラインは、静的な学習データとリアルタイム情報の橋渡しとなり、AIが最新の業界情報や独自コンテンツも参照できるようにします。出典付き回答や正確性基準の遵守、AI生成コンテンツの透明性が求められる組織にとって不可欠な手法となっています。特に出典追跡や情報源の明示が重要なAI監視用途でRAGパイプラインは高い価値を持ちます。
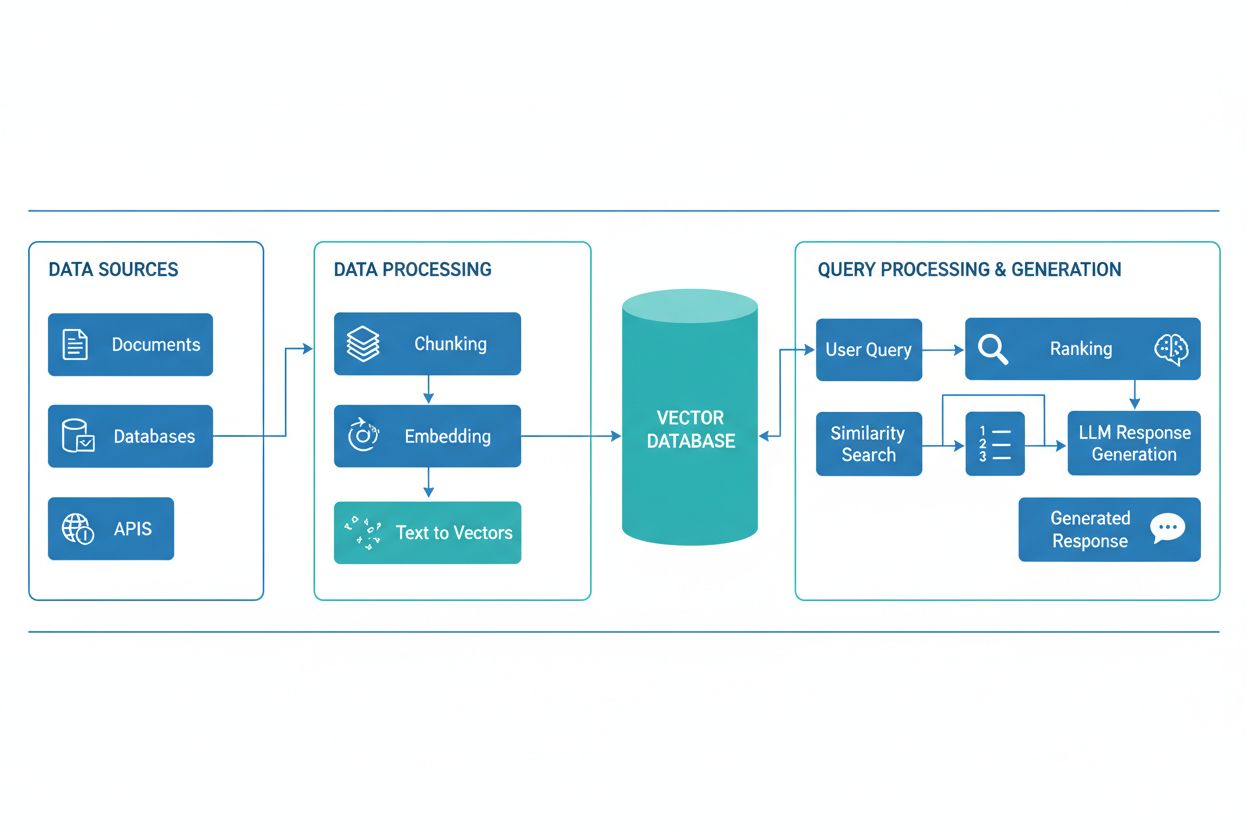
RAGパイプラインは、関連情報の検索と根拠ある回答生成を連携して行う複数のコンポーネントから成ります。一般的な構成は、生データを処理・整形するドキュメントインジェスチョン層、埋め込みやインデックス情報を格納するベクターデータベース/ナレッジベース、ユーザークエリに基づき関連ドキュメントを特定する検索機構、最も関連性の高い結果を優先するランキングシステム、検索情報をもとに一貫した回答を生成するLLM搭載の生成モジュールです。さらに、ユーザー入力の正規化・前処理を行うクエリプロセッサ、テキストを数値表現に変換する埋め込みモデル、検索精度を継続的に改善するフィードバックループも含まれます。これらのコンポーネントの連携がRAGシステム全体の有効性・効率性を左右します。
| コンポーネント | 役割 | 主な技術 |
|---|---|---|
| ドキュメントインジェスチョン | 生データの処理・整形 | Apache Kafka, LangChain, Unstructured |
| ベクターデータベース | 埋め込み・インデックスデータの保存 | Pinecone, Weaviate, Milvus, Qdrant |
| 検索エンジン | 関連ドキュメントの特定 | BM25, Dense Passage Retrieval (DPR) |
| ランキングシステム | 検索結果の優先順位付け | クロスエンコーダー、LLMベースリランキング |
| 生成モジュール | 文脈に基づく回答生成 | GPT-4, Claude, Llama, Mistral |
| クエリプロセッサ | ユーザー入力の正規化・理解 | BERT, T5, カスタムNLPパイプライン |
RAGパイプラインは「検索フェーズ」と「生成フェーズ」の2段階で動作します。検索フェーズでは、ユーザーのクエリをナレッジベース文書と同じ埋め込みモデルでベクトル化し、ベクターデータベースから意味的に最も近いドキュメントやパッセージを検索します。ここで得られた候補ドキュメントは、クロスエンコーダーやLLMスコアリングによるリランキングでさらに精度向上が図られることもあります。生成フェーズでは、上位の検索ドキュメントをコンテキストウィンドウとして整形し、元クエリとともにLLMへ渡すことで、実際のソースに基づいた応答を生成します。この2段階アプローチにより、回答が文脈に即しつつ情報源も明確なものとなり、出典表示や説明責任が不可欠な用途に最適です。最終アウトプットの品質は、検索したドキュメントの関連性とLLMの情報統合能力の両方に大きく依存します。
RAGのエコシステムには、パイプライン構築や運用を支援する多様な専門ツール・フレームワークが存在します。現代のRAG実装で活躍する主な技術カテゴリは以下の通りです:
これらをモジュール的に組み合わせることで、各組織の要件やインフラに適合したRAGシステムを柔軟に構築できます。
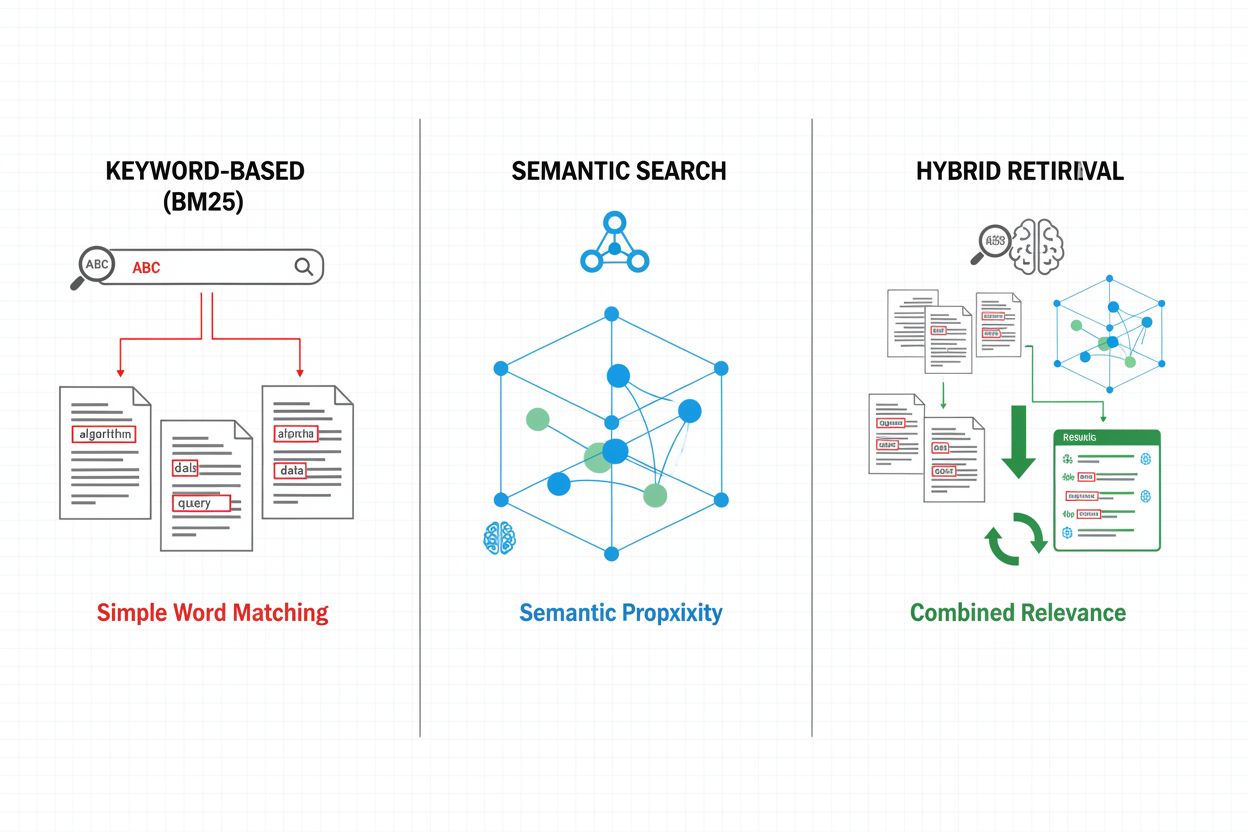
検索メカニズムはRAGパイプラインの基盤であり、シンプルなキーワード検索から高度なセマンティック検索へと進化しています。BM25アルゴリズムによる従来型キーワード検索は、完全一致の場面で効率的かつ有効ですが、意味理解や類義語対応には弱点があります。Dense Passage Retrieval(DPR)などのニューラル検索は、クエリ・ドキュメント双方を密なベクトル埋め込みに変換し、表面上のキーワードを超えた意味的マッチングを実現します。ハイブリッド検索はキーワードとセマンティック手法を組み合わせ、幅広いクエリ種別で再現率・精度を両立します。さらに、クエリ拡張(関連語や言い換え追加)や、より深い意味理解やタスク固有基準で候補を評価するリランキング層も高度な検索には不可欠です。検索方式の選択は、文脈の正確性と計算コストのバランスに大きく影響します。
RAGパイプラインは、精度・鮮度・追跡性が求められる用途で従来のLLM単独方式に比べて大きな優位性を発揮します。検索したドキュメントに根拠を持たせることで、LLMがもっともらしいが誤った情報を生成する「ハルシネーション」を大幅に減らし、医療・法務・金融などの重要分野にも適用可能とします。外部ナレッジベース参照により、モデルを再学習せずとも最新情報を反映でき、新たな知見やアップデートにも即応できます。独自ドキュメントや内部知識ベース、専門用語の組み込みによるドメイン特化型カスタマイズも容易です。検索コンポーネントが引用ソースを明示することで、説明責任やユーザー信頼確保、コンプライアンス対応が可能です。関連情報があれば小型・効率的なLLMでも高品質な応答が可能となり、計算コストも抑制できます。これらの利点は、特に引用精度やコンテンツの可視化が重要なAI監視システムの構築に大きな価値をもたらします。
RAGパイプラインには多くの利点がある一方、技術的・運用上の課題も存在します。検索したドキュメントの質がそのまま回答の質を決定するため、検索ミスはリカバリーが難しく(いわゆる「ゴミが入ればゴミが出る」問題)、ナレッジベースの不適切な情報が最終回答に波及します。埋め込みモデルは専門用語や希少言語、極めて技術的な内容に対して意味一致が難しく、関連文書の取りこぼしを招くこともあります。大規模なナレッジベースや高頻度クエリ処理では、検索・埋め込み生成・リランキングの計算コストが増大します。LLMの文脈ウィンドウ制限により、取り込める情報量が限られ、関連パッセージの取捨選択や要約が必要です。ナレッジベースの鮮度・一貫性維持も、頻繁な情報更新や複数ソースの統合時に運用上の課題となります。RAG性能評価には、従来型の正解率だけでなく、検索精度・回答の関連性・引用の正確性など多面的な指標が必要で、自動評価も難しい場合があります。
RAGは、LLMの精度・関連性を高めるための複数手法の中のひとつであり、それぞれに異なるトレードオフがあります。ファインチューニングは、ドメイン固有データでLLMを再学習し深いカスタマイズを実現しますが、大規模な計算資源やラベル付きデータ、情報更新ごとの再学習が必要です。プロンプトエンジニアリングは、モデル重みを変えず指示や文脈を最適化する柔軟・低コストな手法ですが、学習データと文脈ウィンドウに制約されます。インコンテキストラーニングは、プロンプト内に数例を示して素早く適応できますが、トークン消費や例示選定の難しさもあります。RAGはこれらの中間的立場で、モデル再学習なしで動的な最新情報参照・出典付き回答・多様な知識領域へのスケーラブルな対応を実現しますが、検索インフラ導入や検索エラーなど追加の複雑さも生じます。最適解は多くの場合、RAG・ファインチューニング・プロンプト設計など複数手法の組み合わせで得られます。
実運用レベルのRAGパイプライン構築には、データ準備・アーキテクチャ設計・運用設計の体系的な計画が必要です。まずナレッジベース準備として、関連ドキュメントの収集・フォーマット統一・適切なサイズへの分割(文脈保持と検索精度のバランス)が求められます。次に、埋め込みモデル・ベクターデータベースを性能・レイテンシ・スケーラビリティ要件(埋め込み次元数、クエリスループット、保存容量等)から選定します。検索アルゴリズム(キーワード・セマンティック・ハイブリッド)、リランキング、結果の絞り込み方も設計し、LLMとの連携や検索文脈を反映したプロンプトテンプレートを定義します。評価には検索品質(精度・再現率・MRR)、生成品質(関連性・一貫性・事実性)、システム全体のパフォーマンス指標を用います。運用では検索精度・生成品質の監視、失敗パターンのフィードバックループ、ナレッジベースの更新・保守プロセスの確立が不可欠です。最終的にはユーザーの利用分析や失敗事例の特定を通じ、検索・リランキング・プロンプト設計の継続的な最適化を進めます。
RAGパイプラインは、AmICited.comのような現代のAI監視プラットフォームの基盤技術であり、AI生成コンテンツの情報源や正確性を追跡するうえで不可欠です。RAGシステムは、検索・引用したソースを明確に記録することで、監視プラットフォームが主張の検証・事実性評価・ハルシネーションや誤引用の特定を可能にします。この引用機能は、AIの透明性における重要なギャップを埋めるもので、ユーザーや監査者が回答を原典まで追跡し、独立した検証ができるようになり、AI生成コンテンツへの信頼構築につながります。AIツールを利用するコンテンツ制作者・組織にとっても、どの情報がどの回答に寄与したかの可視化は、出典明記やコンテンツガバナンスの遵守支援に役立ちます。RAGの検索機構は、関連度スコアやドキュメント順位、検索信頼度などのリッチなメタデータを生成し、監視システム側で信頼性評価や知識ドメイン外でのAI挙動把握に利用できます。RAGと監視プラットフォームの統合により、AIが権威的なソースから乖離していく「引用ドリフト」の検知や、情報源の品質・多様性に関するポリシー遵守の強化も実現します。AIが社会インフラに組み込まれる中、RAGパイプラインと包括的監視の組み合わせは、AI生成情報の説明責任を生み出し、ユーザー・組織・情報エコシステム全体を誤情報から守る仕組みとなります。
RAGとファインチューニングは、LLMの性能向上における補完的なアプローチです。RAGはクエリごとに外部ドキュメントを検索し、モデル自体を変更せずにリアルタイムでデータへアクセス・更新できます。ファインチューニングはドメイン固有データでモデルを再学習させ、より深いカスタマイズを可能にしますが、情報更新時には大きな計算資源と手動作業が必要です。多くの組織が両技術を組み合わせて最適な結果を得ています。
RAGは、LLMの応答を検索した事実ベースのドキュメントに基づけることでハルシネーションを抑制します。学習データだけに頼らず、生成前に関連ソースを検索し、モデルに具体的な証拠を提供します。この手法により、回答がモデルの学習パターンでなく実際の情報に基づくものとなり、事実性が大幅に向上し、誤情報や誤解を減らします。
ベクター埋め込みは、テキストの意味を多次元空間で数値的に表現したものです。RAGシステムはこれによりセマンティック検索が可能となり、異なる語彙でも意味が近いドキュメントを見つけられます。埋め込みはキーワード一致を超えた概念的な関係の理解を可能とし、検索の関連性向上とより正確な回答生成に不可欠です。
はい、RAGパイプラインは継続的なデータ取り込み・インデックス化によりリアルタイムデータを取り込めます。自動パイプラインを構築して新しいドキュメントでベクターデータベースを定期更新し、常に最新のナレッジベースを保てます。この機能により、ニュース分析や価格情報・市場監視など、モデル再学習なしで最新情報が必要な応用にも最適です。
セマンティック検索は、ベクター埋め込みを用いて意味的な類似性からドキュメントを検索する技術です。RAGは、セマンティック検索に加えてLLM生成を統合し、検索したドキュメントに基づいた回答を生成する完全なパイプラインです。セマンティック検索が関連情報の発見に特化するのに対し、RAGは検索結果を引用しつつ一貫した応答を生成する機能を加えています。
RAGシステムは、複数の仕組みで引用元を選択します。検索アルゴリズムで関連ドキュメントを探し、リランキングモデルで最も関連性の高い結果を優先し、さらに引用が主張を裏付けているか検証します。中には『書きながら引用』型で検索ソースに裏付けがある場合のみ主張を行うものや、生成後に引用を検証し裏付けのない主張を除去するものも存在します。
主な課題は、ナレッジベースの鮮度と品質の維持、多様なコンテンツタイプでの検索精度最適化、大規模運用時の計算コスト管理、埋め込みモデルがうまく理解できない専門用語への対応、包括的な指標によるシステム性能評価です。また、LLMの文脈ウィンドウ制約や、情報更新に伴う関連性維持にも注意が必要です。
AmICitedは、ChatGPT、Perplexity、Google AI OverviewsなどのAIシステムがRAGパイプラインを通じてどのようにコンテンツを検索・引用しているかを追跡します。どのソースが引用に選ばれ、ブランド名がAI回答にどれだけ登場し、引用が正確かどうかを監視します。これにより、AI検索における自社のプレゼンスや、コンテンツの適切な帰属を可視化できます。
RAGがLLMと外部データソースを組み合わせて正確なAI応答を生成する仕組みを解説。5段階のプロセス、構成要素、ChatGPTやPerplexityなどのAIシステムで重要な理由を理解します。...
AI検索におけるRAG(リトリーバル拡張生成)とは何かを学びましょう。RAGが精度を向上させ、幻覚を減らし、ChatGPT、Perplexity、Google AIの基盤となる仕組みを解説します。...

検索拡張生成(RAG)がAIの引用をどのように変革し、ChatGPT、Perplexity、Google AI Overviewsなどで正確な出典明記と根拠ある回答を実現するかを解説します。...