
品質評価者ガイドライン
Googleの品質評価者ガイドラインについて学びましょう。16,000人以上の評価者が検索品質、E-E-A-Tシグナルを評価し、それが検索アルゴリズムの改善にどのように影響するかを解説します。...
1 分で読める
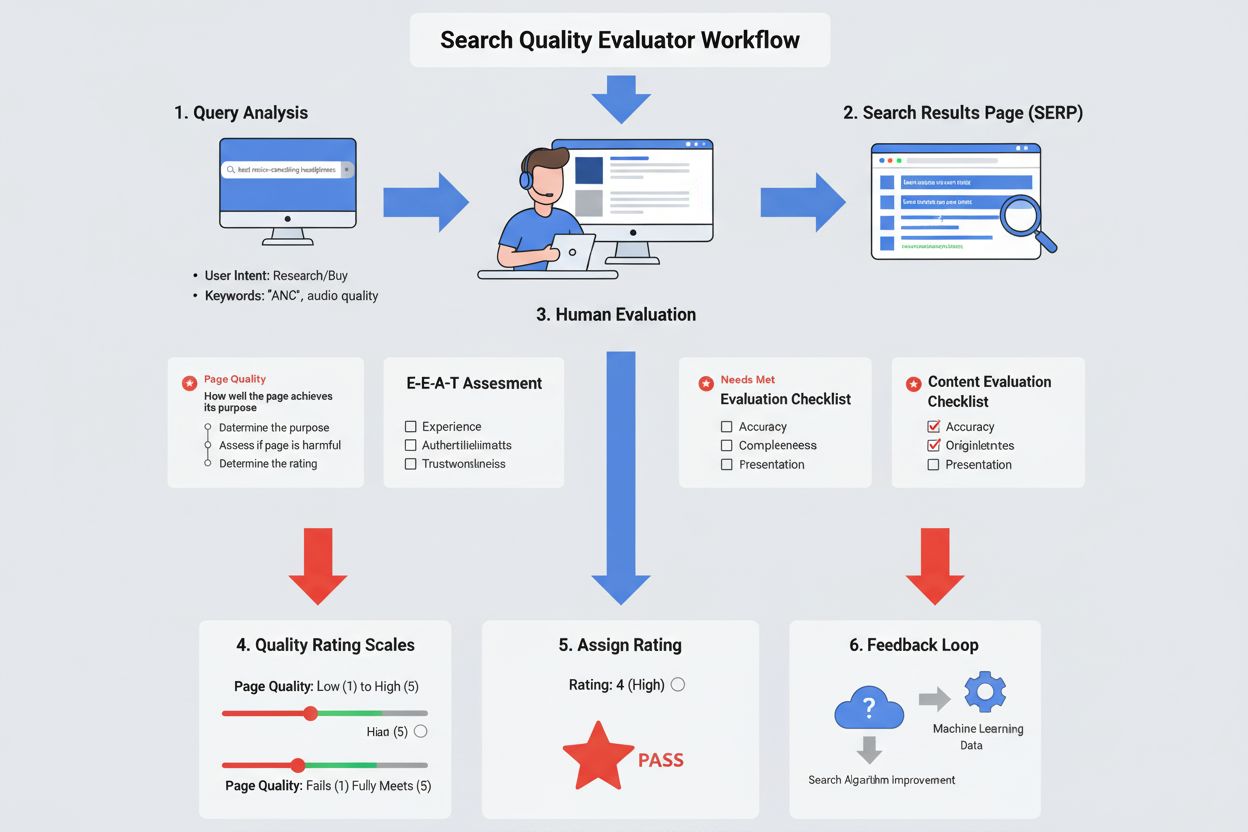
検索品質評価者は、Google(通常はサードパーティの契約会社を通じて雇用される)によって採用された人間のレビュー担当者で、確立されたガイドラインに基づき検索結果の品質と関連性を評価します。これらの評価者は、E-E-A-T(経験、専門性、権威性、信頼性)、コンテンツ品質、ユーザー意図の満足度などの基準で検索結果を評価し、Googleが検索アルゴリズムのパフォーマンスを測定・改善するのを支援します。
検索品質評価者は、Google(通常はサードパーティの契約会社を通じて雇用される)によって採用された人間のレビュー担当者で、確立されたガイドラインに基づき検索結果の品質と関連性を評価します。これらの評価者は、E-E-A-T(経験、専門性、権威性、信頼性)、コンテンツ品質、ユーザー意図の満足度などの基準で検索結果を評価し、Googleが検索アルゴリズムのパフォーマンスを測定・改善するのを支援します。
検索品質評価者とは、Google(通常はサードパーティ契約会社を通じて雇用される)によって採用された人間のレビュー担当者で、検索結果の品質・関連性・有用性を体系的に評価します。世界に約16,000人存在し、標準化されたガイドラインを用いて、コンテンツ品質、ユーザー意図の満足度、E-E-A-T原則(経験、専門性、権威性、信頼性)など多面的に検索結果を評価します。彼らの主な役割はランキングを直接決めることではなく、Googleが検索アルゴリズムによって各地域・言語で有益で権威ある信頼できる情報を適切に届けられているかを測定するための人間によるフィードバックを提供することです。検索品質評価者は、人間の判断と機械学習の橋渡し役として、Googleの自動化システムが実際のユーザーニーズ・期待と合致しているかを保証する重要な存在です。
Googleは2005年に検索品質評価プログラムを開始し、当初は少数の評価者による運用でした。約20年を経て、現在では数千人規模の人間レビュー担当者が関わる高度な品質保証メカニズムへと進化しています。2022年8月、Googleは初めてこのプログラムの存在と概要を公式文書で公開し、評価者の役割や業務内容を明示しました。これは、従来秘密裏に運用されてきたプログラムの大きな転換点でした。以降もガイドラインの拡充と改訂が続き、2023年11月や2025年1月などに大規模な更新が実施され、コンテンツ品質・AI生成コンテンツ・スパム検出・ユーザー満足度などのGoogleの優先課題の変化を反映しています。Googleの公式発表によれば、2023年だけで719,326回以上の検索品質テストを実施し、検索品質基準の維持にこの評価プロセスがいかに重要かが示されています。
検索品質評価者は、Googleの検索品質理解に直接寄与する多様な評価業務を担当します。主な責務は、ページがその目的をどれだけ達成しているかを評価するページ品質評価、検索結果がユーザー意図をどの程度満たしているかを判断するNeeds Met評価、2種類の検索結果を比較してどちらが優れているかを示すサイドバイサイド実験の実施などです。評価者はメインコンテンツの質、ウェブサイトや作成者の評判、広告の有無や目立ち具合、全体的なユーザー体験など様々な観点からページを調査します。独立したレビューや報道、専門家の意見を検索し、ウェブサイト・作成者の評判調査も行います。また、スパム・有害情報・欺瞞的手法・努力の少ないAI生成コンテンツなど問題のあるコンテンツの特定と報告も担います。各評価業務には、クエリの分析、ユーザー意図の把握、内容の正確性の確認、ユーザーニーズへの適合性判断といった綿密な分析が求められます。
| 観点 | 検索品質評価者 | SEO専門家 | コンテンツモデレーター | アルゴリズムエンジニア |
|---|---|---|---|---|
| 主な機能 | 検索結果の品質・ユーザー満足度の評価 | ウェブサイトの検索可視性最適化 | ポリシー違反コンテンツの審査 | ランキングアルゴリズムの設計・改善 |
| 雇用形態 | サードパーティ契約社員(短期・一時的) | ウェブサイト運営者/代理店社員 | プラットフォーム社員(常勤) | Google社員(常勤) |
| 意思決定権 | 採点・フィードバック提供のみ、ランキング制御権なし | 最適化を通じてランキングに影響 | 違反コンテンツの削除・報告 | アルゴリズム要因の制御 |
| 業務範囲 | サンプルクエリ・検索結果の評価 | 特定サイト・ページの最適化 | ユーザー生成コンテンツの監視 | 全体的なシステム改善 |
| ランキングへの影響 | 間接的(総合評価でアルゴリズム改善) | 直接的(最適化で可視性向上) | 間接的(有害コンテンツの削除) | 直接的(アルゴリズムがランキング決定) |
| 主な評価指標 | ページ品質・Needs Met・E-E-A-T評価 | キーワード順位・自然流入 | コンテンツ違反・ユーザー通報 | アルゴリズム性能・関連性スコア |
| トレーニング要件 | ガイドライン試験・地域専門性 | SEO知識・業界経験 | ポリシー研修・コンテンツガイドライン | 情報工学・機械学習 |
| 通常の業務量 | 1日50~100件以上の評価 | 継続的な最適化プロジェクト | 絶え間ないコンテンツ審査 | アルゴリズム開発サイクル |
E-E-A-Tフレームワークは、検索品質評価者がコンテンツの信頼性と品質を判定する際の中核となる基準です。**経験(Experience)**は、作成者の実体験や現場経験を指します(例:実際に製品を使ったレビューは推測よりも重視される)。**専門性(Expertise)**は、トピックに関連する知識・スキル・正式な訓練を意味します。医療情報は医療従事者、金融アドバイスは有資格の専門家が発信すべきです。**権威性(Authoritativeness)**は、作成者またはサイトがその分野で信頼される情報源かどうかを評価します(例:政府公式サイトは政府情報、老舗報道機関はニュース報道で権威性が高い)。**信頼性(Trustworthiness)**はページが正確・誠実・安全・信頼できるかを判断します。特に、信頼性はE-E-A-Tの中で最も重要であり、どれほど経験・専門性・権威性があっても信頼できないページはE-E-A-Tが低いとみなされます。YMYL分野(健康、金融、法律、公共情報など)は誤情報がユーザーの健康・経済・安全に直結するため、評価者は大幅に高いE-E-A-T基準を適用します。
検索品質評価者は5段階のページ品質評価スケールを使用します。「最低」から「最高」までで、「低」「中」「高」が中間に位置します。最低評価は有害な目的、欺瞞的・信頼できない情報、スパム的特徴を持つページに与えられます。低評価はE-E-A-Tが不十分、手抜きコンテンツ、誤解を招くタイトル、広告が多すぎる場合などです。中品質ページは目的を達成するが特に優れた特徴がなく、インターネット上の大多数のページが該当します。高品質ページは努力・独自性・才能・スキルが顕著で、評判が良く、トピックにふさわしい高いE-E-A-Tを持っています。最高品質ページは非常に高いE-E-A-T、極めて良好な評判、卓越した努力や独自性を示す例外的なコンテンツです。評価プロセスは、まずページの目的を理解し、目的が有害・欺瞞的でないかを判断し、ページがどれほど目的を達成し品質基準を満たしているかで評価を決定するという3段階で進みます。このプロセスにより、世界中の何千人もの評価者間で一貫性ある原則的な評価が実現します。
ページ品質の評価に加え、検索品質評価者は検索結果がユーザー意図をどれだけ満たしているかをNeeds Met(NM)評価スケールで判定します。このスケールは5つの主な評価を含みます:特定の明確なクエリを完全に満たすFully Meets(FullyM)(通常は特定サイトへのナビゲーションクエリ)、とても役立つ結果のHighly Meets(HM)、それなりに役立つModerately Meets(MM)、わずかに役立つSlightly Meets(SM)、全くニーズを満たさないまたは無関係なFails to Meet(FailsM)です。評価者はまずユーザー意図をクエリ分析やユーザーの位置情報、クエリの多義性などから判断し、結果が実際にその意図を満たしているかどうかを評価します。鮮度(情報が新しいか)、正確性(主張が事実か)、関連性(クエリに直接答えているか)なども考慮します。この2重評価システム(ページ品質+Needs Met)は、ページ自体の品質とユーザーのクエリに対する実用的有用性の双方にGoogleがフィードバックを得る仕組みです。
検索品質評価者は、コンテンツの品質・関連性を多角的に評価します。メインコンテンツ(MC)がページ目的に直接役立っているか、どれほど努力・独自性・才能・スキルが注がれているかを判断します。補助コンテンツ(SC)(ナビゲーションリンクなど直接目的に寄与しないがユーザー体験を高める要素)も特定します。広告やマネタイズの有無・目立ち方も評価し、広告自体は許容されるものの、メインコンテンツを覆い隠したり邪魔する場合はマイナス評価となります。ウェブサイトや作成者の評判は、独立したレビュー・報道・専門家意見・顧客評価などから調査します。作成者の資格や専門性は、学歴・職歴・過去の実績で確認します。内容の正確性は、特にYMYL分野で信頼できる情報源との照合を重視します。ページ設計・ユーザー体験は、コンテンツのアクセスしやすさや広告・余分な要素の影響を評価します。さらに、コピー・言い換えのみの手抜き、努力の少ないAI生成、誤解を招くタイトル、欺瞞的デザイン、専門家の一般的見解と矛盾する内容など問題のあるパターンも識別します。
2025年1月のSearch Quality Rater Guidelines更新以降、評価者はコンテンツが自動または生成AIツールで作成されているかも具体的に評価します。メインコンテンツが「自動またはAI生成」で「ほとんど努力・独自性・付加価値がない」場合は最低評価となります。評価者は、ほとんど変更のない言い換え、汎用的な言語パターン、独自性のない既知情報、Wikipediaなど既存ソースとの高い一致率、「As an AI language model.」のような特徴的なフレーズなどAI生成の兆候を見極めます。ただし、生成AI自体が問題なのではなく、十分な人間の努力・独自要素・本当の価値が追加されている場合は問題とされません。AIは人間の創造性を高める道具にもなりえますが、「手抜き・低品質コンテンツの大量生成に使われる場合」が問題視されます。これはGoogleがスケールされたコンテンツ濫用(人間の監修や編集がほぼない低品質コンテンツの大量生成)を重要課題と認識していることの表れです。
検索品質評価者はランキングを直接制御しませんが、その作業はアルゴリズムの進化・改善に大きな間接的影響を及ぼします。Googleは何千人もの評価者による総合評価を使い、ランキングシステムの効果測定や、アルゴリズムが品質の高い結果を提供できているかを判断します。評価者がある種の結果を一貫して低品質と判断した場合、エンジニアチームにアルゴリズムの調整が必要であると示唆されます。また、評価者が示す良い例・悪い例は、Googleの機械学習システムが品質シグナルをより正確に認識するための訓練データにもなります。2023年だけで719,326回以上の品質テスト、4,000件超の改善が評価者のフィードバックをもとに実施されました。さらに16,871件の実際のトラフィック実験、124,942件のサイドバイサイド実験が品質評価者を交えて行われています。このデータ駆動型のアプローチにより、機械学習アルゴリズムの改善が人間の「本当の品質評価」に基づいて行われます。人間評価者と機械学習のフィードバックループにより、アルゴリズムは人間専門家が認める高品質コンテンツの特徴を学び続けられるのです。
検索品質評価者はGoogleが直接雇用するのではなく、サードパーティ契約会社のネットワークを通じて採用されます。採用基準は厳格で、評価言語と地域への精通、検索エンジン利用への慣れ、現地ユーザーのニーズ・文化基準を代表できる能力が求められます。候補者はGoogleのSearch Quality Rater Guidelinesに関する包括的テストに合格しなければなりません。このガイドラインは現在160ページ超に及び、ページ品質評価、ユーザー意図理解、E-E-A-T評価、スパム・有害情報判定、検索結果の関連性評価など詳細な基準と豊富な事例を含み、一貫した運用を保証します。評価者は短期契約で働き、契約更新はあり得るものの原則として無期限の継続はしません。これは利害衝突や評価システム操作のリスクを防ぐためです。また、評価は個人的な意見・好み・宗教信条・政治的見解に基づいてはならず、ガイドラインの客観的運用と地域文化基準の反映のみが許容されます。この客観性とガイドライン遵守の徹底が、個人のバイアスではなく本当の品質評価を実現しています。
検索品質評価者の役割については多くの誤解があります。1つ目の誤解:評価者がランキングやペナルティを直接決定している。実際は:評価者はアルゴリズムの効果測定のためのフィードバックを提供するだけで、個々の評価が特定ページの順位に直接影響しません。2つ目の誤解:高いページ品質評価は高い検索順位を保証する。実際は:ページ品質は数ある評価要素の一つにすぎず、ユーザー意図との一致や他ページとの比較なども重要です。3つ目の誤解:E-E-A-Tはランキング要因である。実際は:E-E-A-Tは評価者が信頼性判定に使う枠組みで、GoogleのアルゴリズムがE-E-A-T原則と一致することはあっても、E-E-A-T自体が直接的なランキングシグナルではありません。4つ目の誤解:評価者は誘導・操作されうる。実際は:短期契約・包括的ガイドライン・品質保証プロセスにより、評価システムの操作リスクは低く抑えられています。5つ目の誤解:AI生成コンテンツはすべて最低評価となる。実際は:人間による大きな努力や独自性、付加価値が加えられたAI生成コンテンツは最低評価とならないこともあり、問題なのは「努力の少ない低品質AI生成の大量生産」です。
Googleが検索品質維持で直面する新たな課題に伴い、検索品質評価者の役割も進化し続けています。AI生成コンテンツの増加を受け、GoogleはガイドラインでAIについて明確に言及し、評価者に手抜きAI生成の識別を訓練しています。また、Google AIオーバービューのようなAI主導の検索インターフェースや、ChatGPT・ClaudeなどのAIチャットボットとの競争が、Googleにとって「人間評価による品質保証」の重要性を高めています。今後はより高度なAI検出手法や、画像・動画・音声などマルチモーダルコンテンツ評価、地域・文化的関連性の強化などが発展する可能性があります。コンテンツ制作者・ウェブサイト運営者は、検索品質評価者の評価基準を理解することがますます重要になっています。E-E-A-T、オリジナルコンテンツ、ユーザーファースト設計、真の専門性の重視は、持続的なSEO成功には「本物の品質」が不可欠であることを示唆しています。努力の少ないAI生成やコピー、欺瞞的手法への警告も明記されており、Googleが本物の価値あるコンテンツ創出を重視していることが分かります。組織は、独自調査による専門性の証明、良質なコンテンツと良好な評判による権威性の構築、透明性と正確性による信頼性の確保に注力すべきです。
検索品質評価者は、Googleのアルゴリズム検索における極めて重要な「人間の要素」を体現しています。機械学習や人工知能がいくら進歩しても、品質・関連性・信頼性の評価には人間の判断が不可欠であることを示しています。世界各地・多様な言語の約16,000人もの評価者が、Googleの検索結果が多様なユーザーニーズや文化的背景を反映することを保証しています。ページ品質やユーザー満足度の体系的なフィードバックを通じて、Googleはアルゴリズムを継続的に改善し、より有益・権威ある・信頼できる情報を提供できるよう努めています。Googleの評価基準を理解したいすべての人にとって(制作者・SEO担当者・一般ユーザー問わず)、検索品質評価者の役割と評価手法を知ることは、「Googleが何を品質とみなすか」「検索エンジンがユーザーのためにどう進化しているか」を知る貴重な手がかりとなります。AI生成コンテンツの普及、新たな検索インターフェース、ユーザー期待の変化などデジタル環境が進化する中で、検索品質評価者の人間的判断が検索結果の健全性・有用性を守るうえで一層重要になるでしょう。
いいえ。検索品質評価者はランキングを直接決定したり、ウェブサイトにペナルティを与えたりすることはありません。評価者の採点はGoogleがアルゴリズムの効果を測定するためのフィードバックとして使われます。何千人もの評価者による総合的な評価がGoogleのシステム改善に役立っていますが、個々の評価が特定ページの検索順位に直接影響することはありません。
E-E-A-Tは「経験(Experience)」「専門性(Expertise)」「権威性(Authoritativeness)」「信頼性(Trustworthiness)」の略です。検索品質評価者は、コンテンツ作成者やウェブサイトがそれぞれのトピックで信頼できる情報源であるかどうかを、この4つの観点から評価します。E-E-A-Tは特に、健康・金融・法律などユーザーの生活に重大な影響を与えるYMYL(Your Money or Your Life)分野で重要視されます。評価者は作成者の資格やウェブサイトの評判、コンテンツ品質を調査し、E-E-A-Tのレベルを判断します。
Googleは世界中で約16,000人の検索品質評価者を、サードパーティの契約会社を通じて雇用しています。評価者は多様な視点や文化的理解を確保するため、地域や言語ごとに分布しています。正確な人数は運用状況により変動し、評価者は通常短期契約で働き、契約更新はあり得ますが、無期限に続くことは一般的にありません。
検索品質評価者は主に2つの評価システムを使います:ページ品質(PQ)評価はページが目的をどれだけ達成しているかを示し、「最低」から「最高」までの尺度で評価します。Needs Met(NM)評価は検索結果がユーザーの意図をどれだけ満たしているかを、「Fails to Meet」から「Fully Meets」までの尺度で判断します。これらの評価は、Googleが検索結果がユーザーの期待と権威性・信頼性を満たしているかを把握するのに役立ちます。
YMYLは「Your Money or Your Life」の略で、健康、経済的安定、安全、幸福に大きな影響を与える可能性のあるトピックを指します。YMYL分野のページは、不正確または信頼できない情報が実害につながる恐れがあるため、より厳格な品質評価基準が適用されます。医療、金融、法律、公共情報などが例です。評価者はYMYLコンテンツに対してより高いE-E-A-T基準と、専門性を示す強い証拠を求めます。
2025年1月時点で、Googleのガイドラインは自動または生成AIツールで作成されたメインコンテンツについて、努力や独自性、付加価値が不足している場合は「最低」品質と評価するよう評価者に指示しています。評価者は、わずかな言い換えや汎用的な言語パターン、「AI言語モデルとして~」のようなフレーズなど、AI生成の兆候を確認します。ただし、人間による大きな努力や独自の要素が加えられた場合は、「最低」評価とならないこともあります。
検索品質評価者は、GoogleのSearch Quality Rater Guidelines(検索品質評価ガイドライン)に関する包括的な試験に合格しなければなりません。このガイドラインは160ページ以上に及び、ページ品質の評価基準、ユーザー意図の理解、E-E-A-Tの評価、スパム・有害コンテンツの特定、検索結果の関連性評価など詳細に解説しています。評価者は担当言語と地域の熟知度も求められ、現地ユーザーのニーズや文化的基準を正確に反映できなければなりません。
ChatGPT、Perplexity、その他のプラットフォームでAIチャットボットがブランドを言及する方法を追跡します。AI存在感を向上させるための実用的なインサイトを取得します。
Googleの品質評価者ガイドラインについて学びましょう。16,000人以上の評価者が検索品質、E-E-A-Tシグナルを評価し、それが検索アルゴリズムの改善にどのように影響するかを解説します。...

ページ品質評価は、E-E-A-Tやコンテンツの独自性、ユーザー満足度を通じてウェブページの品質を評価するGoogleのフレームワークです。評価基準やスケールについて学びましょう。...
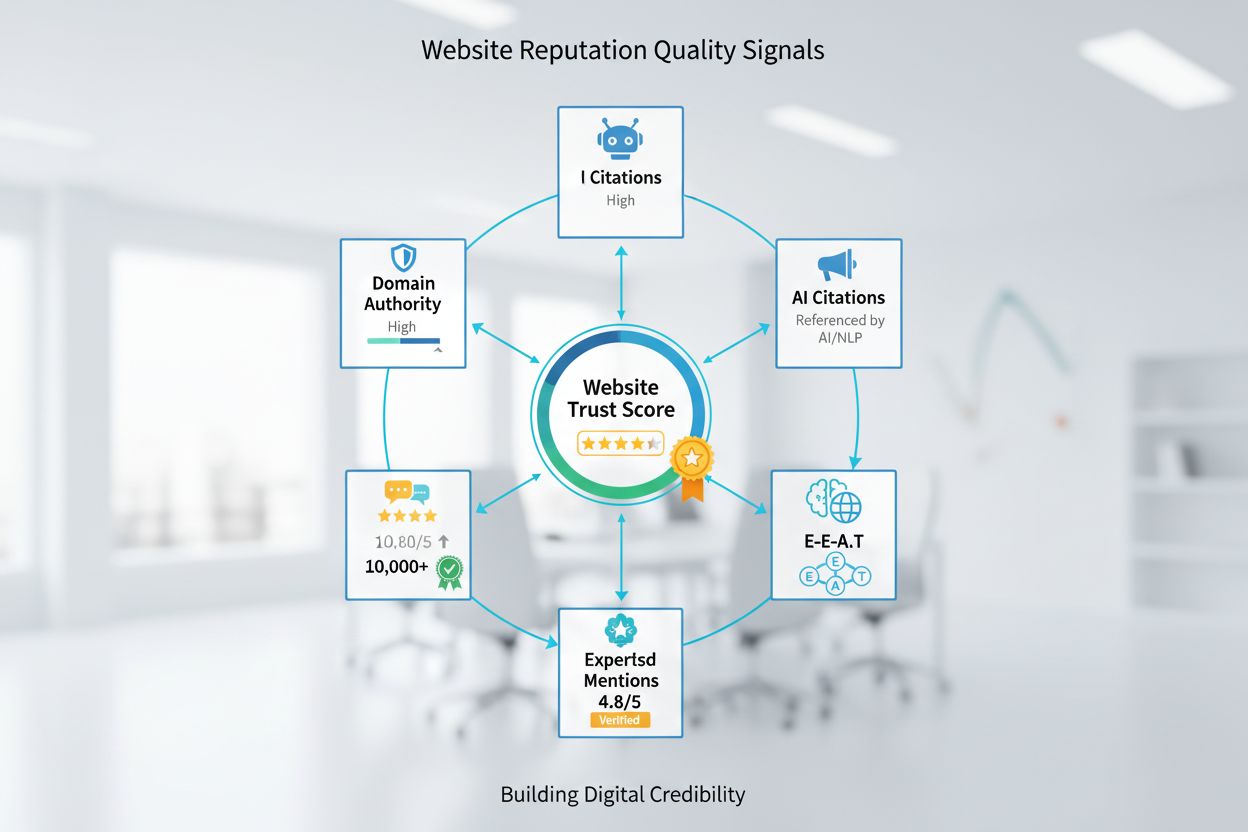
ウェブサイトの評判は、サイトの品質と信頼性に関する集合的な評価です。ドメインオーソリティ、レビュー、E-E-A-T、AIでの引用がオンラインでの信頼性や検索順位にどう影響するかを学びましょう。...
クッキーの同意
閲覧体験を向上させ、トラフィックを分析するためにクッキーを使用します。 See our privacy policy.