PerplexityのSonarアルゴリズム:リアルタイム検索モデルの解説
PerplexityのSonarアルゴリズムが、コスト効率の高いモデルでリアルタイムAI検索をどのように実現しているかを解説。Sonar、Sonar Pro、Sonar Reasoningの各バリエーションを紹介します。...
1 分で読める
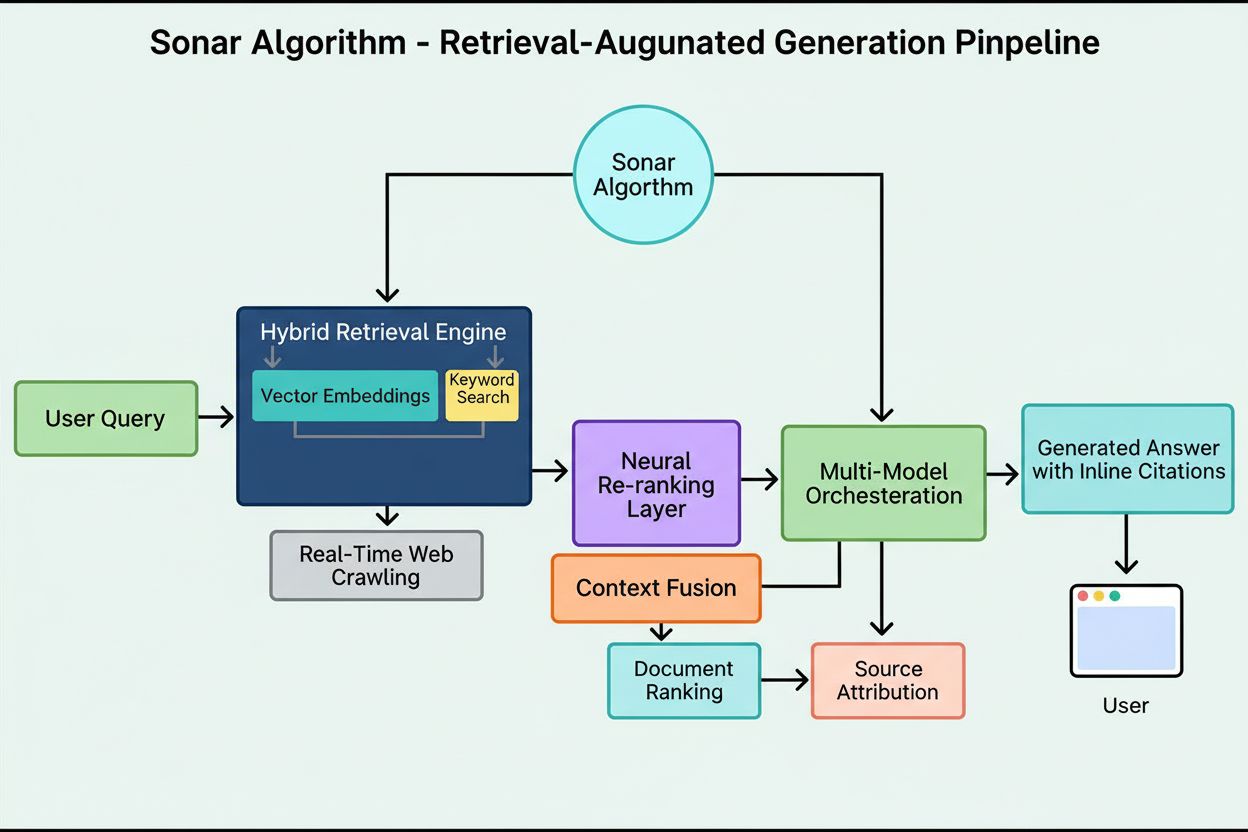
ソナーアルゴリズムは、Perplexity独自の検索拡張生成(RAG)ランキングシステムであり、ハイブリッドなセマンティック検索とキーワード検索、ニューラル再ランキングを組み合わせ、リアルタイムでWebソースを取得・ランキング・引用してAIによる回答を生成します。コンテンツの鮮度、意味的関連性、引用性を重視し、根拠のあるソース付き回答を提供しつつ、ハルシネーションを最小限に抑えます。
ソナーアルゴリズムは、Perplexity独自の検索拡張生成(RAG)ランキングシステムであり、ハイブリッドなセマンティック検索とキーワード検索、ニューラル再ランキングを組み合わせ、リアルタイムでWebソースを取得・ランキング・引用してAIによる回答を生成します。コンテンツの鮮度、意味的関連性、引用性を重視し、根拠のあるソース付き回答を提供しつつ、ハルシネーションを最小限に抑えます。
ソナーアルゴリズムは、Perplexity独自の検索拡張生成(RAG)ランキングシステムであり、ハイブリッドなセマンティック検索とキーワード検索、ニューラル再ランキング、リアルタイム引用生成を組み合わせて回答エンジンを支えています。従来の検索エンジンが結果リストにページをランキングするのに対し、ソナーはコンテンツ断片を取得し、インライン引用付きの1つの統一回答へと合成します。このアルゴリズムはコンテンツの鮮度、意味的関連性、引用性を重視し、根拠のあるソース付きの回答を提供しつつ、ハルシネーション(事実誤認)を最小限に抑えます。ソナーは、AIシステムにおける情報検索・ランキングの根本的な変化を表しており、リンク型権威シグナルから、ユーザー意図を直接満たし、合成回答で明確に引用できるかどうかという「回答中心の有用性指標」へと評価軸が移っています。この違いは、AI回答エンジンでの可視性が従来SEOとどう異なるかを理解する上で極めて重要です。ソナーはリストでの順位ではなく、抽出・合成・属性付け可能性を評価します。
ソナーアルゴリズムの登場は、AI回答エンジンにおける検索拡張生成(RAG)アーキテクチャへの業界全体のシフトを象徴しています。Perplexityが2022年末にローンチした際、同社はAI領域の重大な課題に着目しました。すなわち、ChatGPTは強力な会話能力を持っていたものの、リアルタイム情報やソース帰属ができず、ハルシネーションや古い回答の原因となっていました。Perplexityの創業チームは当初データベースクエリ翻訳ツールを開発していましたが、完全に方向転換し、ライブWeb検索とLLM合成を統合した回答エンジン開発に注力。この戦略的決断がソナーの設計に直結し、「人の閲覧用にページをランキングする」のではなく、「機械合成・引用用に断片を取得・ランキングする」ことを前提にアルゴリズムが設計されました。過去2年間でソナーはAIエコシステムで最も高度なランキングシステムの一つへと進化し、PerplexityのソナーモデルはSearch Arena Evaluationで1位から4位を独占し、GoogleやOpenAIの競合モデルを大きく凌駕しています。現在、ソナーは月間4億件以上の検索クエリを処理し、2,000億以上のユニークURLをインデックス化、毎秒数万件のインデックス更新でリアルタイム鮮度を維持しています。この規模と高度さが、AI検索時代の決定的なランキングパラダイムとしてのソナーの重要性を示しています。
ソナーのランキングシステムは、精緻に設計された5段階の検索拡張生成パイプラインにより、ユーザーのクエリを根拠ある引用付き回答へと変換します。第1段階「クエリ意図解析」では、LLMを用いて単純なキーワード一致を超え、ユーザーの真の意図や文脈・ニュアンスを意味的に理解します。第2段階「ライブWeb検索」では、解析済みクエリをVespa AIを基盤とする大規模分散インデックスに投げ、リアルタイムで関連ページ・ドキュメントを取得します。この検索エンジンは密検索(ベクトル検索)と疎検索(キーワード検索)を組み合わせ、約50件の多様な候補ドキュメントを生成します。第3段階「スニペット抽出と文脈化」では、ページ全体を生成モデルに渡さず、クエリに直接関連するスニペットや段落・チャンクのみを抽出し、集約して焦点化された文脈ウィンドウを形成します。第4段階「引用付き合成回答生成」では、この厳選文脈をPerplexity独自のソナーファミリーやGPT-4・Claude等のLLMに入力し、取得情報のみに基づいた自然言語回答を生成します。重要なのは、あらゆる主張がインライン引用でソースにリンクされ、透明性と検証性が担保される点です。第5段階「会話的洗練」では、複数ターンの会話文脈を維持し、追跡質問に対し繰り返しWeb検索で回答を洗練します。このパイプラインの根本原則「取得していないことは言ってはいけない」により、ソナー搭載回答は検証可能なソースに基づき、学習データ依存型モデルと比べハルシネーションが大幅に減少します。
| 項目 | 従来検索(Google) | ソナーアルゴリズム(Perplexity) | ChatGPTランキング | Geminiランキング | Claudeランキング |
|---|---|---|---|---|---|
| 主な単位 | リンクのランキングリスト | 引用付き統合回答(1件) | コンセンサス型エンティティ言及 | E-E-A-T整合コンテンツ | 中立・事実重視ソース |
| 検索の焦点 | キーワード、リンク、ML信号 | ハイブリッド意味+キーワード検索 | 学習データ+Web閲覧 | ナレッジグラフ連携 | 憲法的安全性フィルター |
| 鮮度優先度 | QDF(Query-Deserves-Freshness) | リアルタイムWeb取得、48時間で37%増加 | 低め、学習データ依存 | 中程度、Google検索連携 | 低め、安定性重視 |
| ランキングシグナル | バックリンク、ドメイン権威、CTR | コンテンツ鮮度、意味的関連性、引用性、権威ブースト | エンティティ認識、コンセンサス言及 | E-E-A-T、会話整合、構造化データ | 透明性、検証可能な引用、中立性 |
| 引用メカニズム | 結果中のURLスニペット | ソースリンク付きインライン引用 | 暗黙的、多くは非引用 | AI Overviewsで帰属 | 明示的ソース帰属 |
| コンテンツ多様性 | サイト横断で複数結果 | 統合回答用に少数ソース選択 | 複数ソースから合成 | 複数ソースのオーバービュー | バランス・中立ソース |
| パーソナライゼーション | 微妙・主に暗黙的 | 明示的フォーカスモード(Web, Academic, Finance, Writing, Social) | 会話に基づき暗黙的 | クエリ種別に応じ暗黙的 | 最小限、一貫性重視 |
| PDF取扱い | 標準インデックス | HTMLより引用22%有利 | 標準インデックス | 標準インデックス | 標準インデックス |
| スキーママークアップの影響 | フィーチャードスニペットのFAQスキーマ | FAQスキーマで引用41%増、初回引用6時間短縮 | 直接的影響は小さい | ナレッジグラフに中程度影響 | 直接的影響は小さい |
| レイテンシ最適化 | ランキングはミリ秒 | サブ秒で検索+生成 | 合成に数秒 | 合成に数秒 | 合成に数秒 |
ソナーアルゴリズムの技術基盤は、再現率と精度の最大化を目指すハイブリッド検索エンジンです。**密検索(ベクトル検索)**は、意味埋め込みを用いてクエリ背後の概念的意味を把握し、キーワードが一致しなくても文脈的に近いドキュメントを特定します。これは、トランスフォーマ型埋め込みでクエリ・ドキュメントを高次元ベクトル空間にマッピングし、意味的に近いものをクラスタ化する仕組みです。疎検索(キーワード検索)は希少語や製品名、社内識別子、固有エンティティ等、意味の曖昧さが望ましくないケースで精度を発揮し、BM25などで厳密一致ランキングを行います。両者を統合・重複排除することで、約50件の多様な候補ドキュメントを生成し、ドメイン偏りを防ぎながら幅広い権威ソースをカバーします。初期検索後、ソナーのニューラル再ランキング層が、DeBERTa-v3クロスエンコーダ等の先進的MLモデルを用いて、語彙的関連スコア・ベクトル類似度・ドキュメント権威・鮮度・ユーザー行動・メタデータなど多様な特徴量で候補を評価。多段階ランキングにより、厳しいレイテンシ要件下でも最終的に最高品質・最適関連のソースを厳選できます。インフラ全体はVespa AI上に構築されており、Webスケールのインデックス(2,000億URL以上)、リアルタイム更新(毎秒数万件)、文書チャンク化によるきめ細かな内容把握が可能です。このアーキテクチャ選択により、Perplexityの少数精鋭エンジニアチームがRAG制御・ソナーモデル微調整・推論最適化など差別化領域に集中できます。
コンテンツ鮮度はソナーの最重要ランキングシグナルの1つです。実証研究では、最近更新されたページほど引用率が格段に高いことが示されています。24週間・120URLのA/Bテストでは、直近48時間以内に更新された記事は、古いタイムスタンプの同一内容より37%多く引用されました。この優位性は2週間後も約14%持続しました。この優遇の背景には、ソナーの設計思想があります。アルゴリズムは古いコンテンツをハルシネーションリスクが高いとみなし、新しい情報への更新を優先します。Perplexityインフラは毎秒数万件のインデックス更新を処理し、リアルタイム鮮度シグナルを可能に。MLモデルがURLの再インデックス必要性を予測し、ページ重要度や過去の更新頻度に応じて更新スケジュールを動的決定。CMSが修正タイムスタンプを再発行すれば、微細な編集でも鮮度カウントがリセットされます。出版社にとっては、週次・日次更新のニュースルーム的運用か、さもなくばエバーグリーンコンテンツの可視性が徐々に失われるという戦略的インパクトとなります。ソナー時代、コンテンツ更新速度は虚栄指標ではなく生存戦略そのものです。週次マイクロアップデート自動化やライブ変更履歴の付与、継続的最適化ワークフローを回すブランドは、静的・非更新ページに依存する競合に比べて圧倒的な引用シェアを獲得できます。
ソナーはキーワード密度よりも意味的関連性を重視し、自然で会話的な言語でユーザークエリに直接答えるコンテンツを評価します。検索システムは密ベクトル埋め込みでクエリとコンテンツを概念レベルでマッチングするため、同義語や関連表現、文脈豊かな記述を含むページは、セマンティック深度のないキーワード詰め込みページを上回ることがあります。キーワード中心から意味重視への移行は、コンテンツ戦略に大きな影響を与えます。ソナーで勝つコンテンツは、事実要約を冒頭に置き、詳細はその後に展開、説明的なH2/H3見出しや短い段落で抜粋しやすく、一次ソースへの明示的リンクや引用、鮮度を示すタイムスタンプやバージョンノートも重要です。各段落はコピー&ペースト容易な明確性とLLM可読性を持つ「意味的原子単位」として最適化されます。表・箇条書き・ラベル付きチャートなど構造化情報は特に引用されやすいです。独自分析や一次データも高く評価され、ソナーの合成エンジンは汎用的なまとめよりも独自視点・一次資料・自社データを好みます。この意味的豊かさと回答優先構造へのシフトは、キーワード配置・リンク権威重視の従来SEOからの本質的転換です。ソナー時代のコンテンツは人間閲覧でなく、機械検索・合成向けに設計されねばなりません。
公開PDFはソナーランキングで見落とされがちな大きな強みです。実証テストでは、コンテンツのPDF版はHTML版より引用頻度で約22%有利でした。これは、ソナーのクローラーがPDFをHTMLより好意的に扱うことに起因します。PDFはクッキーバナー、JavaScript描画、ペイウォール認証などHTML特有の障害がなく、クローラーが安定して全文抽出できます。出版社は、PDFを公開ディレクトリに配置し、内容を反映した意味的ファイル名を付与し、HTMLヘッドに<link rel="alternate" type="application/pdf">でカノニカル指定することで、この利点を最大化できます。これは「LLMハニートラップ」と呼ばれ、競合のトラッキングスクリプトでは検出困難な高可視性資産となります。B2B企業、SaaSベンダー、研究志向組織では、ホワイトペーパー・調査レポート・技術資料をPDFで発信することで、ソナーでの引用率を劇的に高められます。PDFを「おまけ」ではなくカノニカルな本命コピーとみなし、HTML版以上の最適化を施すことがカギです。特にエンタープライズ系コンテンツでは、PDFの方が構造化・権威性が高いことが多く、効果絶大です。
JSON-LD FAQスキーママークアップはソナー引用率を大幅に強化します。3つ以上のFAQブロックを持つページは、スキーマなしコントロールページに比べ41%多く引用されます。この顕著な効果は、ソナーが構造化かつチャンク単位のコンテンツを好み、その取得・合成ロジックとFAQスキーマが完全に一致するためです。FAQスキーマは独立したQ&A単位を提供し、アルゴリズムによる抽出・ランキング・引用が容易です。従来SEOでのFAQスキーマは「おまけ」でしたが、ソナーでは中核的ランキング要素です。FAQ質問自体がアンカーテキストとして引用されることが多く、LLMが段落途中を要約する際の文脈逸脱リスクを下げられます。また、初回引用までの時間も約6時間短縮され、ソナーパーサーが構造化Q&Aをランキング初期段階で優先していることが示唆されます。出版社の最適化戦略は明確です:「折りたたみ後」に3~5個のターゲットFAQブロックを埋め込み、実際の検索ユーザーの会話的クエリを模した質問文を用いること。質問はロングテール検索表現やソナー想定クエリと意味的に対称にし、回答は簡潔・事実重視・直接的にし、冗長な宣伝文句は避けます。SaaS・クリニック・士業などFAQが自然にユーザー意図やソナーの合成要求と合致する業種で特に効果的です。
ソナーランキングシステムは複数シグナルを統合した一元的引用フレームワークを採用し、研究では引用候補選定・頻度に影響する主な8要素が特定されています。第一に、質問への意味的関連性が検索で支配的で、自然言語で明確に答えているコンテンツが優先されます。第二に、権威と信頼性が重要で、Perplexityがパートナー契約する出版社や、学術機関・専門家等のソースがアルゴリズム的に優遇されます。第三に、鮮度が特に重視され、前述の通り直近更新で引用37%増。第四に、多様性・カバレッジが評価され、単一ソース回答より複数高品質ソースの組み合わせを好み、相互検証でハルシネーションリスクを下げます。第五に、モード・スコープがソナーの検索対象インデックスを決定し、Academic・Finance・Writing・Social等のフォーカスモードでソース種別が絞られ、Web・Org Files・Web+Org Files・None等のソースセレクターで外部Web・内部文書等からの取得が制御されます。第六に、引用性・アクセシビリティが不可欠で、PerplexityBotがクロール・インデックスできることが引用のしやすさに直結し、robots.txt準拠やページ速度も重要です。第七に、APIによるカスタムソースフィルターで、エンタープライズ用途ではドメイン制約や優先設定ができ、ホワイトリスト内でランキングが変動します。第八に、会話文脈が追跡質問に影響し、進化する意図に合致するページが一般的参照より優遇されます。これら要素の総合最適化が必要で、従来のバックリンクやキーワード密度単独では対応できません。
ソナーアルゴリズムはLLM推論・検索技術の進化に応じ急速に進化しています。Perplexity公式エンジニアブログでは、推測的デコーディング(複数トークン同時予測でレイテンシ半減)の導入が強調されています。生成ループが高速化することで、各クエリでより鮮度の高い検索セットを活用でき、古いページが競争できる時間窓がますます短縮されます。噂のSonar-Reasoning-ProモデルはすでにGemini 2.0 FlashやGPT-4o Searchをアリーナ評価
**ソナーアルゴリズム**は、Perplexityが自社開発したランキングシステムであり、回答エンジンを支えています。これはGoogleのような従来型検索エンジンとは根本的に異なります。Googleが「青いリンク」のリストとしてページをランキングするのに対し、ソナーはコンテンツの断片を統合し、インライン引用付きの1つの統一回答として合成・提示します。ソナーは検索拡張生成(RAG)を採用し、ハイブリッド検索(ベクトル埋め込み+キーワードマッチ)、ニューラル再ランキング、リアルタイムWeb取得を組み合わせて、検証可能なソースに基づいた回答を構築します。このアプローチは、従来のSEOシグナル(バックリンクなど)よりも意味的関連性やコンテンツ鮮度を重視し、リンク型権威主義とは異なる、AI合成最適化型の新しいランキングパラダイムとなっています。
ソナーは**ハイブリッド検索エンジン**を実装しており、密検索(意味埋め込みを使ったベクトル検索)と疎検索(BM25などによるキーワード検索)という2つの補完的手法を組み合わせています。密検索は概念的意味や文脈を捉え、キーワードが正確に一致しなくても意味的に近いコンテンツを発見できます。疎検索は、意味の曖昧さが望ましくない希少語や製品名、固有識別子などに対して精度を発揮します。これら2つの検索結果を統合・重複排除し、約50件の多様な候補ドキュメントを生成。これによりドメイン偏重を防ぎ、幅広いカバレッジを確保します。このハイブリッド方式は、単一手法よりも再現率・関連性精度の両面で優れています。
ソナーの主なランキング要因は次のとおりです:(1) **コンテンツ鮮度** – 更新・公開直後48時間は37%多く引用されます;(2) **意味的関連性** – クエリに自然言語で直接答える明確さが重視され、キーワード密度よりも優先されます;(3) **権威と信頼性** – 大手出版社・学術機関・報道機関のソースはアルゴリズム的に優遇されます;(4) **引用性** – 見出しや表、段落など構造化され、引用しやすいコンテンツが有利です;(5) **多様性** – 単一ソース回答よりも複数の高品質ソースを優先;(6) **技術的アクセシビリティ** – PerplexityBotによるクロール可能性や高速表示も必要です。
**鮮度はソナーの最重要ランキングシグナルの1つ**で、特に時事性の高いトピックで顕著です。Perplexityのインフラは毎秒数万件のインデックス更新リクエストを処理し、最新の情報が即時反映されるようにしています。MLモデルがURLの再インデックス必要性を予測し、重要度や更新頻度に基づいて更新スケジュールを決定します。実験では、直近48時間以内の更新コンテンツは古いタイムスタンプの同一内容より37%多く引用され、この優位性は2週間後も14%残りました。わずかな修正でも鮮度カウントがリセットされるため、ソナーでの可視性維持には継続的な最適化が必須です。
**PDFはソナーランキングシステムで大きな優位性があり**、同一内容のHTMLよりも引用頻度で22%上回ることが多いです。ソナーのクローラーはPDFを好意的に扱います。PDFにはクッキーバナー、ペイウォール、JavaScript描画問題などHTML特有の障害が少ないためです。公開ディレクトリへのPDF配置、意味的なファイル名の付与、HTMLヘッド内に``を設置しカノニカル指定することでPDFの可視性を最適化できます。これは「LLMハニートラップ」とも呼ばれ、競合のトラッキングスクリプトでは検知しにくい戦略的資産となります。
**JSON-LD FAQスキーマはソナーの引用率を大幅に向上させます**。FAQブロックが3つ以上あるページは、スキーマなしのコントロールページと比べて41%多く引用されます。FAQマークアップは、ソナーのチャンク単位検索ロジックと完全に一致し、アルゴリズムが抽出・引用しやすい独立したQ&A単位を提供します。また、FAQ質問自体がアンカーテキストとして引用されることが多く、LLMが段落途中を要約する際の文脈逸脱リスクを下げます。初回引用までの時間も約6時間短縮され、ソナーのパーサーが構造化Q&Aを早期に優先していることが示唆されます。
ソナーは**3段階の検索拡張生成(RAG)パイプライン**を実装し、検証済みの外部知識による回答の根拠付けを実現しています。第1段階でハイブリッド検索により関連ドキュメントを取得し、第2段階で最も関連性の高いスニペットを抽出・文脈化、第3段階で与えられた文脈からのみ回答を合成し、「取得していないことは言ってはいけない」という厳格な原則を徹底します。この構成により検索と生成が密接に結合され、すべての主張がソースに遡れるようになります。インライン引用で生成テキストとソースをリンクさせ、ユーザー検証を可能に。こうした根拠付けは、学習データ依存型モデルに比べハルシネーションを大幅に低減し、ソナーの回答をより事実ベースで信頼性の高いものにしています。
ChatGPTは**エンティティ認識と学習データ内のコンセンサス重視**、Geminiは**E-E-A-Tシグナルと会話整合性**、Claudeは**憲法的安全性と中立性**を重視しています。一方、ソナーは**リアルタイム鮮度と意味的深さ**を独自に最優先します。ソナーの3層機械学習再ランカーは従来検索より厳しい品質フィルターを適用し、基準未達の場合は結果全体を破棄します。ChatGPTが学習データ依存なのに対し、ソナーは毎回ライブWeb検索を行い、常に最新情報を反映。Geminiのナレッジグラフ一体化とは異なり、ソナーは段落単位の意味的関連性を重視し、Claudeの中立性重視とも違って大手出版社による権威ブーストも受け入れます。
ChatGPT、Perplexity、その他のプラットフォームでAIチャットボットがブランドを言及する方法を追跡します。AI存在感を向上させるための実用的なインサイトを取得します。
PerplexityのSonarアルゴリズムが、コスト効率の高いモデルでリアルタイムAI検索をどのように実現しているかを解説。Sonar、Sonar Pro、Sonar Reasoningの各バリエーションを紹介します。...
PerplexityのSonarアルゴリズムとその最適化方法に関するコミュニティディスカッション。Googleとの最適化の違いについてSEOの専門家による実体験を共有。...
Perplexityのライブサーチ技術がどのようにリアルタイムでウェブから情報を取得し、出典付きの回答を生成するかを理解しましょう。Perplexityの検索機能の技術的プロセスを学べます。...
クッキーの同意
閲覧体験を向上させ、トラフィックを分析するためにクッキーを使用します。 See our privacy policy.