
構造化データ
構造化データは、検索エンジンがウェブページの内容を理解するための標準化マークアップです。JSON-LD、schema.org、マイクロデータがSEO、リッチリザルト、AIでの可視性をどう高めるのかを学びましょう。...
1 分で読める

AIシステムがコンテンツを正確に理解し、引用できるように特別に設計されたスキーママークアップ。構造化データはJSON-LDなどの標準化されたフォーマットを使用し、ページ内容について明示的なコンテキストを提供します。これにより、大規模言語モデルが情報をより確実に解析し、信頼性の高い引用が可能になります。
AIシステムがコンテンツを正確に理解し、引用できるように特別に設計されたスキーママークアップ。構造化データはJSON-LDなどの標準化されたフォーマットを使用し、ページ内容について明示的なコンテキストを提供します。これにより、大規模言語モデルが情報をより確実に解析し、信頼性の高い引用が可能になります。
AIのための構造化データとは、人工知能システムがコンテンツを正確に理解・解釈・活用できるよう、標準化されたスキーマに従って整理された機械可読な情報を指します。非構造化テキストとは異なり、意味の解読に複雑な自然言語処理が必要ですが、構造化データは情報が何を表しているかを明示的に示します。この明確さは、特に大規模言語モデルや検索エンジンなどのAIシステムが日々数十億のデータポイントを処理する中で不可欠です。schema.org、JSON-LD、microdataといった標準でコンテンツを構造化すると、AIは曖昧さなくエンティティ、関係性、属性を即座に認識できます。この構造的アプローチは、非構造化データに比べて300%高い精度でAIの理解力を実現します。AI Overviewsやその他AI生成結果での可視性を求める組織にとって、構造化データはもはや不可欠なインフラとなっています。生のコンテンツをAIが自信を持って引用・参照し、回答に組み込めるインテリジェンスに変換し、AI時代におけるデジタルコンテンツの発見性の在り方を根本から変えます。

AIシステムは、構造化データを高度なパイプラインで処理し、マークアップされたコンテンツを実用的なインテリジェンスへと変換します。AIが適切にフォーマットされた構造化データに遭遇すると、自然言語解析に比べてはるかに少ない計算コストで主要情報を即座に抽出できます。技術的な仕組みは以下の主要ステップに従います:
このプロセスにより、適切に構造化されたコンテンツはAI Overviewsで30%以上の可視性向上を実現します。構造的アプローチは、AIの回答を明示的かつ検証可能なデータに基づけることでハルシネーション(誤生成)のリスクを低減します。包括的な構造化データ戦略を実践する組織は、AIシステムによる発見・理解・プロモーションの指標で有意な改善を得ています。
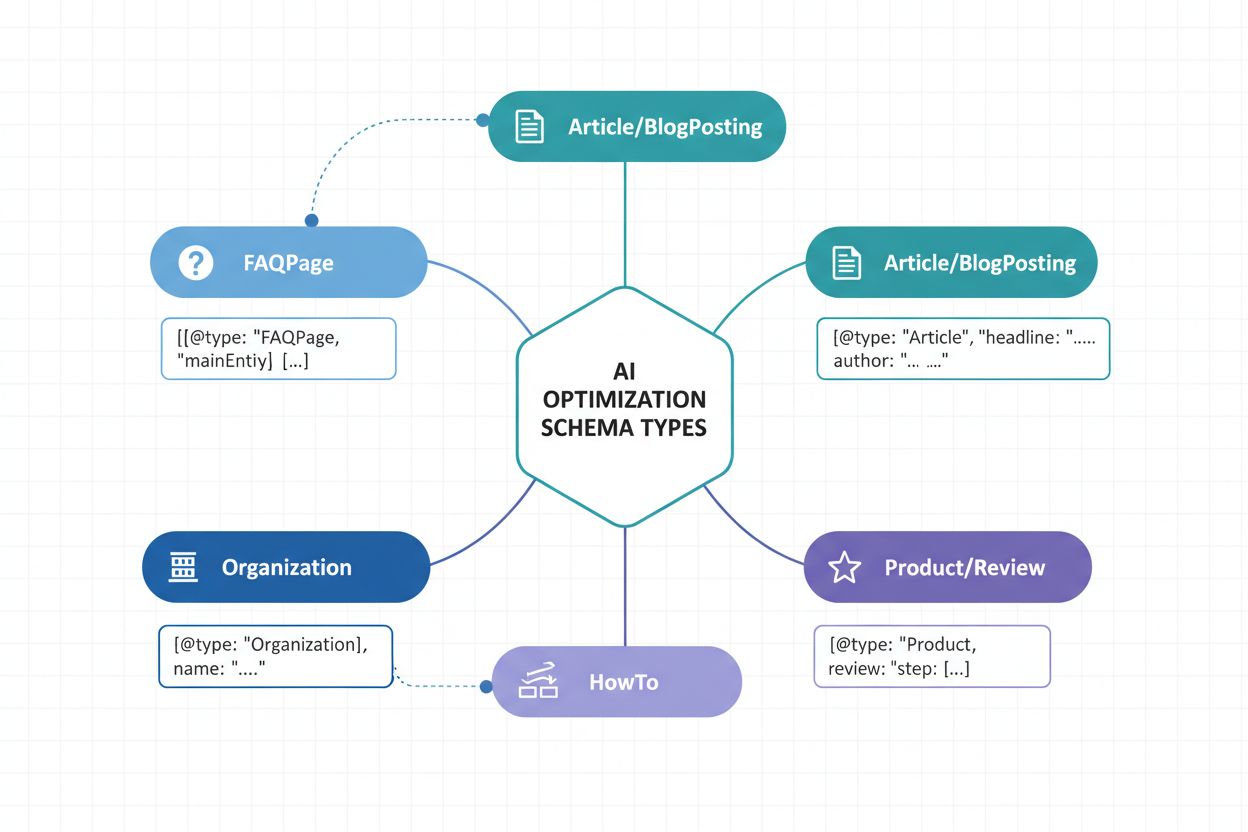
適切なスキーマタイプの実装は、AI可視性戦略の根幹です。各種コンテンツタイプには、AIシステムにその性質や価値を伝えるための特定の構造化データマークアップが必要です。AI認識を最大化するための主要スキーマタイプは以下の通りです:
Articleスキーマ — ニュース記事、ブログ、長文コンテンツに対し、見出し・著者・公開日・本文をマークアップ。AIが権威ある情報源や発行信頼性を特定するのに不可欠。
Organizationスキーマ — 企業名、ロゴ、連絡先、SNSプロフィールなどの会社情報を定義。AIが組織コンテンツを多様な文脈で正しく認識・帰属できるようにする。
Productスキーマ — 名前・説明・価格・在庫・レビューなど製品情報を構造化。AIショッピングアシスタントや商品推薦システムの可視性に必須。
LocalBusinessスキーマ — 事業所の場所・営業時間・連絡先・サービス内容をマークアップ。ローカルAIクエリや位置情報ベースのAI Overviewsで特に重要。
BreadcrumbListスキーマ — サイトナビゲーション階層を定義し、AIがサイト構造やページ間の関係性を理解できるようにする。
FAQPageスキーマ — 質問とその回答を構造化し、AIがQ&Aコンテンツを直接抽出・引用できるようにする。
NewsArticle・BlogPostingスキーマ — 記事カテゴリをAIに伝える特殊なタイプで、分類精度や関連性マッチングを向上。
Eventスキーマ — 日付・場所・説明・登録情報などイベント詳細をマークアップし、AIによるイベント発見やカレンダー統合に不可欠。
現在、4,500万ドメインがschema.orgマークアップを採用しており、世界のドメイン全体の**12.4%**を占めます。複数のスキーマタイプを同時に実装する組織は、AIシステムによるコンテンツエコシステムの文脈理解が深まり、複利的な可視性向上を実現しています。
構造化データを成功裏に実装するには、戦略的計画と技術的精度が必要です。AI可視性の最大化とデータ正確性確保のため、次のベストプラクティスを守りましょう:
記事用の実践的なJSON-LD例:
{
"@context": "https://schema.org",
"@type": "Article",
"headline": "AIのための構造化データ:戦略的実装ガイド",
"author": {
"@type": "Person",
"name": "Content Author"
},
"datePublished": "2024-01-15",
"image": "https://example.com/image.jpg",
"articleBody": "Full article text here...",
"publisher": {
"@type": "Organization",
"name": "Your Organization",
"logo": "https://example.com/logo.png"
}
}
正しく実装すれば、従来検索のリッチリザルトから35%のCTR向上が得られ、AI Overviewsが主な発見チャネルとなることでさらなる利点が生まれます。AmICited.comのようなソリューションでパフォーマンスを継続的に監視することで、どのコンテンツタイプやスキーマ実装がAI可視性を最大化しているか特定でき、競争優位を得られます。
構造化データとllms.txtはAIによる発見性を高める手段ですが、根本的に異なる仕組みで機能します。構造化データは(schema.orgやJSON-LDなどの)標準スキーマをHTML内に埋め込み、特定のコンテンツ要素に明示的なセマンティック意味を付与します。この方法はWebページに直接組み込まれるため、検索エンジンやAIシステムがクロール時に即座に情報を利用できます。記事・製品・イベント・組織などを細かくマークアップでき、AIは正確な関係性や属性を理解可能です。
llms.txtは対照的に、Webサイトのルートディレクトリに設置されるテキストファイルで、大規模言語モデルへの指示やガイドラインを記述します。AIシステムがコンテンツをどのように扱い・引用すべきかの指針をマニフェストファイルとして伝えます。llms.txtは利用権や帰属の高次なガイダンスは提供しますが、構造化データほどセマンティックな精度はありません。構造化データは「このコンテンツは何か?」に機械可読で答え、llms.txtは「このコンテンツをどう利用すべきか?」の指針を与えます。
両者を組み合わせるのが最適戦略です:構造化データがAIによる正確な理解と引用を保証し、llms.txtが利用方針や帰属要件を明確にします。両方を導入した組織は、そうでない組織より36%高い確率でAI生成サマリーに掲載されます。構造化データがAI理解の土台を担い、llms.txtが適切な利用・帰属を推進するガバナンス枠組みを提供します。
構造化データの効果測定には、AIがコンテンツをどのように発見・理解・引用しているかを示す特定指標の追跡が必要です。組織がモニタリングすべき主要KPIは:
AmICited.comはAI引用パフォーマンスの専門モニタリングを提供し、構造化データ投資が実際に可視性や帰属にどう結びついているか可視化します。どのコンテンツがAIに引用され、どんなクエリで引き出され、競合と比べてどれほど引用頻度が高いかを把握できます。このデータ主導のアプローチによって、構造化データの実装が理論上のベストプラクティスから、測定可能なビジネスインパクトへと変わります。
包括的な構造化データ戦略を持つ組織では、AIによる回答の93%がクリックなしで完結するため、引用可視性がトラフィック獲得の新たな生命線となります。引用パフォーマンスの計測は、構造化データ投資のリターンを定量化し、AI発見性やブランド帰属の向上へとつながります。
構造化データの実装成功には、段階的かつ価値を段階的に積み上げるアプローチが不可欠です。組織は次のようなタイムラインで実装を進めましょう:
第1フェーズ:基盤構築(1~2か月)
第2フェーズ:拡大(3~4か月)
第3フェーズ:最適化(5~6か月)
第4フェーズ:戦略統合(7か月以降)
このタイムラインにより、2~3か月内に有意なAI可視性向上を実現しつつ、企業規模での包括的な構造化データ基盤構築を目指せます。早期導入組織は、AI Overviewsが主流チャネルとなる中で競争優位を確立できます。
**構造化データは、任意のSEO強化策からAI時代の必須戦略インフラへと進化しました。**AIシステムが情報発見の仲介役になる中、構造化データが不十分な組織は可視性で体系的な不利を被ります。従来の検索はユーザーがWebサイトへクリックすることを前提にしていましたが、AI Overviewsは直接質問に回答するため、引用可視性が新たな競争領域となりました。
構造化データを戦略的に導入することで、組織は複数のAIプラットフォームや新興チャネルで長期的な成功を手にできます。このインフラ投資は即時的なAI可視性を超え、コンテンツ管理の効率化、パーソナライズの強化、音声検索最適化、将来のAIアプリケーション向けデータ資産の創出など多くのメリットをもたらします。包括的な基盤を早期に築いた組織は、AIシステムが構造化コンテンツを優先する流れの中で複利的な優位性を得ます。
早期導入の競争優位は計り知れません。今後ますます多くの組織が構造化データの重要性を認識することで、可視性を得るためには導入が最低条件となります。今構造化データ基盤を確立した組織が、AI生成結果をリードしていきます。導入を遅らせる組織は、AIがマークアップ充実サイトを優先学習するほど可視性獲得が困難に。構造化データは単なる技術的実装ではなく、AIが仲介する情報環境で「発見され・引用され続ける」ための根本的な戦略的コミットメントなのです。
構造化データはGoogleのランキングに直接影響を与えるわけではありませんが、リッチスニペットによって検索結果の見た目を大幅に改善し、クリック率を最大35%向上させます。AIシステムにおいては、構造化データがAI生成回答でコンテンツが引用されるかどうかにより直接的な影響を及ぼします。
はい、AIシステムは学習時とリアルタイムのクエリ処理時の両方で構造化データを処理します。OpenAIは公式声明を出していませんが、GPTBotや他のAIクローラーがJSON-LDマークアップを解析している証拠があります。Microsoftは、BingのAIシステムがスキーママークアップを利用してコンテンツ理解を向上させていることを公式に認めています。
JSON-LDが推奨されるフォーマットです。HTMLコンテンツからスキーマを分離でき、実装や大規模運用が簡単です。Googleも明確にJSON-LDを推奨しており、MicrodataやRDFaよりも実装ミスが少なくて済みます。
リッチスニペットは実装後1~4週間で表示されることがあります。CTRの改善は多くの場合2週間以内に測定可能です。AIによる引用の改善は、基盤構築の効果が現れるまで4~8週間、その後3~6か月で権威性の向上が積み重なります。
まずはスキーママークアップを優先してください—これは実績があり幅広くサポートされています。llms.txtはまだ発展途上の標準であり、AIクローラーによる採用は限定的です。もし開発者向けの企業でドキュメントが多い場合、将来のためにllms.txtを作成しておくのもよいでしょう。
ホームページにはOrganizationスキーマ(sameAsプロパティ付き)、主要なコンテンツページにはArticleスキーマを。次にFAQPageスキーマ—AIでの抽出に最も直接的に役立ちます。その後、ガイドにはHowToスキーマ、商品ページにはSoftwareApplicationスキーマを追加しましょう。
誤ったマークアップのみがパフォーマンスに悪影響を及ぼします。Googleのガイドラインは明確です:表示されるコンテンツに合った関連スキーマタイプを使い、価格や日付の正確性を保ち、ユーザーが見られない内容はマークアップしないでください。公開前に必ずGoogleのリッチリザルトテストで検証しましょう。
構造化データは、情報が何を表しているかをAIシステムが理解するための明示的なコンテキストを提供します。この明確さにより、AIは自信を持ってコンテンツを抽出・引用できます。ナレッジグラフを活用したLLMは、非構造化データのみに頼る場合と比べて精度が300%向上します。
ChatGPT、Perplexity、Google AI Overviews、その他のプラットフォームでAIシステムがあなたのコンテンツをどのように引用しているかを追跡。AIでの存在感をリアルタイムで把握しましょう。
構造化データは、検索エンジンがウェブページの内容を理解するための標準化マークアップです。JSON-LD、schema.org、マイクロデータがSEO、リッチリザルト、AIでの可視性をどう高めるのかを学びましょう。...

AI抽出のための統計データの提示方法を学びましょう。データフォーマットのベストプラクティスやJSONとCSVの違い、LLMやAIモデル向けにデータをAI対応させる方法をご紹介します。...
AIクローラーが構造化データをどのように処理するかを学びましょう。ChatGPT、Perplexity、Claude、Google AI Overviewsでの可視性のために、JSON-LDの実装方法がなぜ重要なのかを解説します。...
クッキーの同意
閲覧体験を向上させ、トラフィックを分析するためにクッキーを使用します。 See our privacy policy.