
トレーニングデータ
トレーニングデータは、MLモデルにパターンや関係性を学習させるためのデータセットです。高品質なトレーニングデータがAIモデルのパフォーマンスや精度、業界横断での実用性にどのように影響するかを解説します。...
1 分で読める

合成データトレーニングは、実際の人間が作成した情報ではなく、人工的に生成されたデータを使用してAIモデルをトレーニングするプロセスです。このアプローチはデータ不足に対応し、モデル開発を加速し、プライバシーを保護しつつ、モデル崩壊や幻覚など、慎重な管理や検証が必要な課題ももたらします。
合成データトレーニングは、実際の人間が作成した情報ではなく、人工的に生成されたデータを使用してAIモデルをトレーニングするプロセスです。このアプローチはデータ不足に対応し、モデル開発を加速し、プライバシーを保護しつつ、モデル崩壊や幻覚など、慎重な管理や検証が必要な課題ももたらします。
合成データトレーニングとは、実際の人間が作成した情報ではなく、人工的に生成されたデータを用いて人工知能モデルをトレーニングするプロセスを指します。従来のAIトレーニングがアンケート、観察、ウェブマイニングなどで収集される実データに依存していたのに対し、合成データは既存データから統計的パターンを学習したり、完全に新しいデータをゼロから生成したりするアルゴリズムや計算的手法によって作成されます。このトレーニング手法の根本的な転換は、現代AI開発における重要な課題――計算需要の爆発的な増加に人間が十分な実データを生成する能力が追いつかなくなった――に対応するものです。研究によれば、人間が生成するトレーニングデータは今後数年で枯渇する可能性が示唆されています。合成データトレーニングは、従来のAI開発期間の最大80%を占めるデータ収集・ラベリング・クリーニングなどの時間を必要とせず、無限に生成可能なスケーラブルで費用対効果の高い代替手段を提供します。
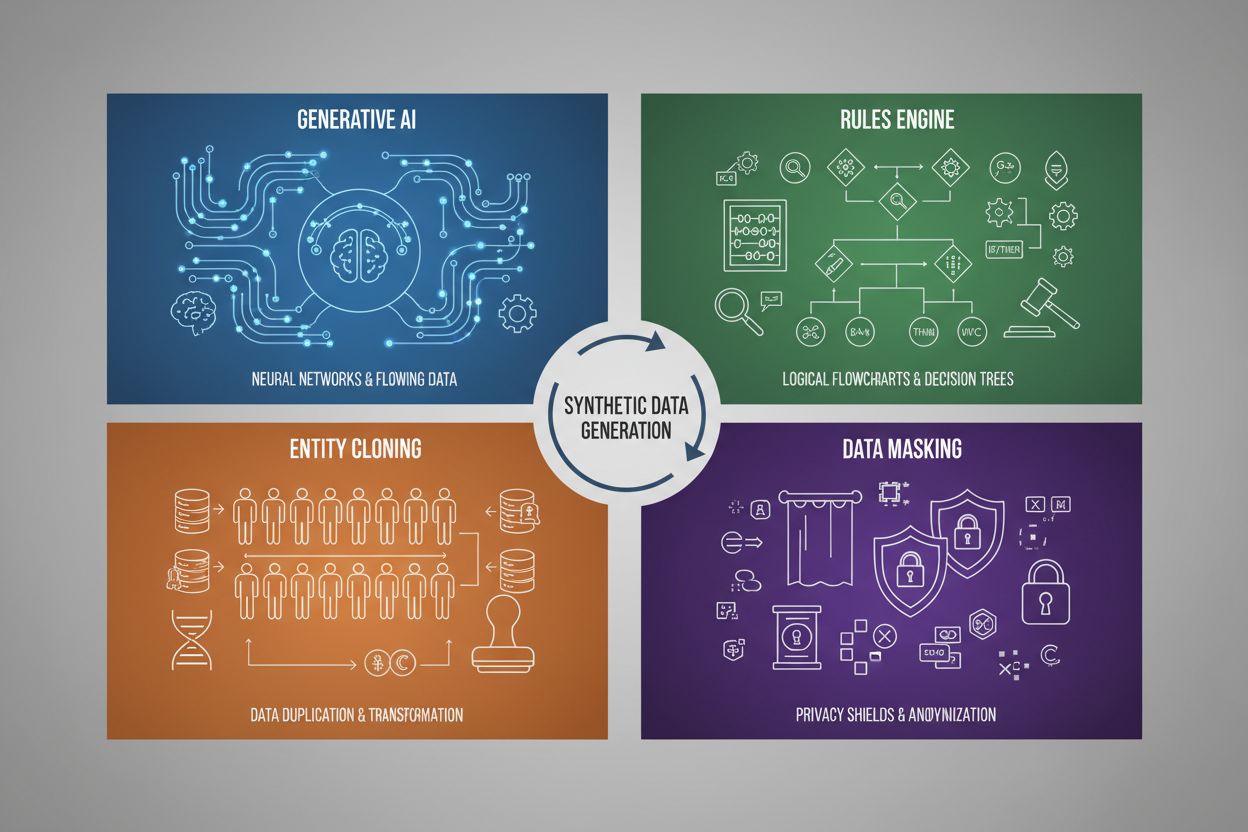
合成データ生成には主に4つの手法があり、それぞれ異なるメカニズムと用途があります。
| Technique | How It Works | Use Case |
|---|---|---|
| 生成AI(GAN、VAE、GPT) | ディープラーニングモデルを使い、実データから統計的パターンや分布を学習し、同じ統計的特性や関係性を保った新しい合成サンプルを生成します。GANは、生成器が偽データを作り、識別器が本物か評価することで、より現実的な出力を生み出します。 | ChatGPTのような大規模言語モデルのトレーニング、DALL-Eによる合成画像生成、自然言語処理タスク用の多様なテキストデータセット生成 |
| ルールエンジン | 事前に定義された論理ルールや制約を適用し、特定のビジネスロジックやドメイン知識、規制要件に従ったデータを生成します。この決定論的アプローチは、機械学習を必要とせず、既知のパターンや関係性を持つデータを作成できます。 | 金融取引データ、特定のコンプライアンス要件を持つ医療記録、既知の運用パラメータを持つ製造センサーデータ |
| エンティティクローン | 既存の実データを複製し、変換や摂動、バリエーションを加えて新しいインスタンスを作成しつつ、主要な統計的特性や関係性を維持します。データの真正性を保ちつつデータセットを拡張できる手法です。 | 規制業界での限定的なデータセットの拡張、希少疾患診断用のトレーニングデータ作成、少数派クラス例が不足しているデータセットの補強 |
| データマスキング・匿名化 | トークン化、暗号化、値の置換などの技術を用いて、個人識別情報(PII)を隠蔽しつつ、データ構造や統計的関係性を維持します。これにより、実データのプライバシーを保った合成版を作成できます。 | 医療・金融データセット、顧客行動データ、研究分野での個人情報を含むデータなど |
合成データトレーニングは、従来多大なリソースと時間を要していたデータ収集・アノテーション・クリーニングプロセスを排除することで、コストを大幅に削減します。組織は必要に応じて無限のトレーニングサンプルを生成でき、モデル開発サイクルを劇的に加速し、実世界のデータ収集を待たずに迅速な反復・実験が可能になります。また、データ補強機能が強力で、限られたデータセットを拡張し、クラス不均衡問題(実データで特定カテゴリが過小代表されている状態)を解決するバランスの取れたトレーニングセット作成を可能にします。合成データは、医用画像、希少疾患診断、自動運転車のテストなど、実データの収集が高額あるいは倫理的に困難な特殊領域におけるデータ不足問題の解消にも特に有効です。プライバシー保護も大きな利点で、合成データは機微な個人情報を公開せずに生成できるため、医療記録・金融データ・規制対象情報でのモデル学習に最適です。さらに、合成データを使うことで、開発者が意図的にバランスの取れた多様なデータセットを作成し、実社会データに存在する差別的パターンを打ち消す体系的なバイアス削減も可能です。たとえば、トレーニング画像で多様な人口属性を生成することで、採用・融資・刑事司法分野でAIモデルが性別や人種のステレオタイプを助長するのを防げます。
有望である一方、合成データトレーニングには、慎重に管理しなければモデル性能を損なう深刻な技術的・実務的課題もあります。特に重要なのがモデル崩壊です。これは、AIモデルが合成データのみで広範囲にトレーニングされた場合、出力の品質・正確性・一貫性が著しく低下する現象です。合成データは実データと統計的には類似していますが、本物の人間が生成した情報にある微妙な複雑さや端的なケースが欠如しているため、AIモデルがAI生成コンテンツでトレーニングされると、エラーやアーティファクトが増幅され、世代ごとに合成データの品質が低下するという複合的な問題が生じます。
主な課題は以下の通りです:
これらの課題は、合成データだけでは実データを置き換えることができない理由を強調しています。むしろ、厳格な品質保証と人による監督のもと、実データの補完として慎重に統合する必要があります。
合成データがAIモデルトレーニングでますます普及する中、ブランドはAI生成出力や引用における正確かつ好意的な表現を確保するという新たな課題に直面しています。大規模言語モデルや生成AIシステムが合成データでトレーニングされると、そのデータの品質や特徴がブランドがAI検索結果やチャットボットの応答、自動コンテンツ生成でどのように記述・推奨・引用されるかに直接影響します。合成データに古い情報や競合バイアス、不正確なブランド記述が含まれると、それがAIモデルに組み込まれ、数百万件のユーザーインタラクションにわたって誤ったブランド表現が持続するという深刻なブランドセーフティ問題を引き起こします。AmICited.comのようなプラットフォームでAIシステム内のブランドプレゼンスを監視する組織にとって、モデル学習における合成データの役割を理解することは不可欠です――AIの引用や言及が実データ由来か、合成データ由来かを可視化することで、信頼性や正確性への影響を把握できます。AIトレーニングにおける合成データ利用の透明性ギャップは説明責任の課題を生み、企業は自社ブランド情報が合成データセットでどのように再現されているか容易に確認できません。先進的なブランドはAIモニタリングや引用トラッキングを優先し、AIトレーニングでの合成データ利用開示を求める透明性基準を提唱し、実データ・合成データ両方でトレーニングされたAIシステム全体で自社ブランドがどのように表現されているか洞察を得られるプラットフォームを活用すべきです。2030年までに合成データが主流のトレーニング手法となるにつれ、ブランドモニタリングは従来のメディアトラッキングからAI引用インテリジェンスに移行し、生成AIシステム全体でブランド表現を追跡するプラットフォームが、ブランドの一貫性とAI主導の情報エコシステムにおける正確なブランドボイスの保護に不可欠となります。
従来のAIトレーニングは、アンケート調査、観察、ウェブマイニングなどで人間から収集された実世界データに依存しており、時間がかかり、ますます希少になっています。合成データトレーニングは、既存データから統計的パターンを学習するアルゴリズムや、完全に新しいデータを生成するアルゴリズムによって人工的に生成されたデータを使用します。合成データは必要に応じて無限に生成できるため、開発時間やコストを大幅に削減し、プライバシーの問題にも対応します。
主な4つの手法は、1)生成AI(GAN、VAE、GPTモデルを使用してデータパターンを学習・再現)、2)ルールエンジン(事前に定義されたビジネスロジックや制約を適用)、3)エンティティクローン(統計的特性を維持しつつ既存データを複製・変化)、4)データマスキング(データ構造を維持しつつ機微情報を匿名化)です。それぞれ用途が異なり、独自の利点があります。
モデル崩壊は、AIモデルが合成データのみで広範囲にトレーニングされた時に、出力の品質や正確性が著しく劣化する現象です。合成データは統計的には実データに似ていますが、実際の情報にある微妙な複雑さや端的なケースが欠如しています。AI生成コンテンツでトレーニングすると、エラーやアーティファクトが増幅され、世代ごとに品質が低下し、最終的には使い物にならない出力となる複合的な問題が生じます。
AIモデルが合成データでトレーニングされる場合、その合成データの品質や特徴が、ブランドがAI出力でどのように記述・推奨・引用されるかに直接影響します。古い情報や競合他社のバイアスを含む低品質の合成データがAIモデルに埋め込まれると、数百万回のユーザーインタラクションの中でブランドの誤った表現が持続することがあります。これはブランドセーフティの懸念となり、AIトレーニングで合成データの使用状況の監視と透明性が求められます。
いいえ、合成データは実データの補完として活用すべきであり、置き換えるものではありません。コストやスピード、プライバシーの面で大きな利点がありますが、本物の人間が生成したデータの複雑さや多様性、端的なケースを完全に再現することはできません。最も効果的なのは、合成データと実データを組み合わせ、厳格な品質管理と人による監督のもとでモデルの正確性と信頼性を確保する方法です。
合成データは元のデータセットから実際の値を含まず、実在個人との一対一の関係がないため、優れたプライバシー保護を提供します。従来のデータマスキングや匿名化技術は再識別のリスクが残りますが、合成データは学習したパターンに基づいて完全にゼロから生成されます。これにより、医療記録、金融データ、個人行動情報など、実際の個人データを漏らすことなくモデルをトレーニングするのに最適です。
合成データは、開発者が意図的にバランスの取れた多様なデータセットを作成することで、実世界データに存在する差別的パターンを打ち消す体系的なバイアス削減を可能にします。たとえば、トレーニング画像で多様な人口属性を生成することで、AIモデルによる性別や人種のステレオタイプの助長を防ぐことができます。これは、採用や融資、刑事司法など、バイアスが深刻な影響を及ぼす分野で特に有効です。
2030年までに合成データが主流のトレーニング手法となる中で、ブランドは自社情報がAIシステムでどのように表現されるかを理解する必要があります。合成データの品質は、AI出力でのブランドの引用や言及に直接影響します。ブランドは、AIシステム全体での自社の存在感を監視し、合成データの使用開示を求める透明性基準を提唱し、AmICited.comのようなプラットフォームを利用してブランド表現を追跡し、誤表現を早期発見できるようにするべきです。
トレーニングデータは、MLモデルにパターンや関係性を学習させるためのデータセットです。高品質なトレーニングデータがAIモデルのパフォーマンスや精度、業界横断での実用性にどのように影響するかを解説します。...
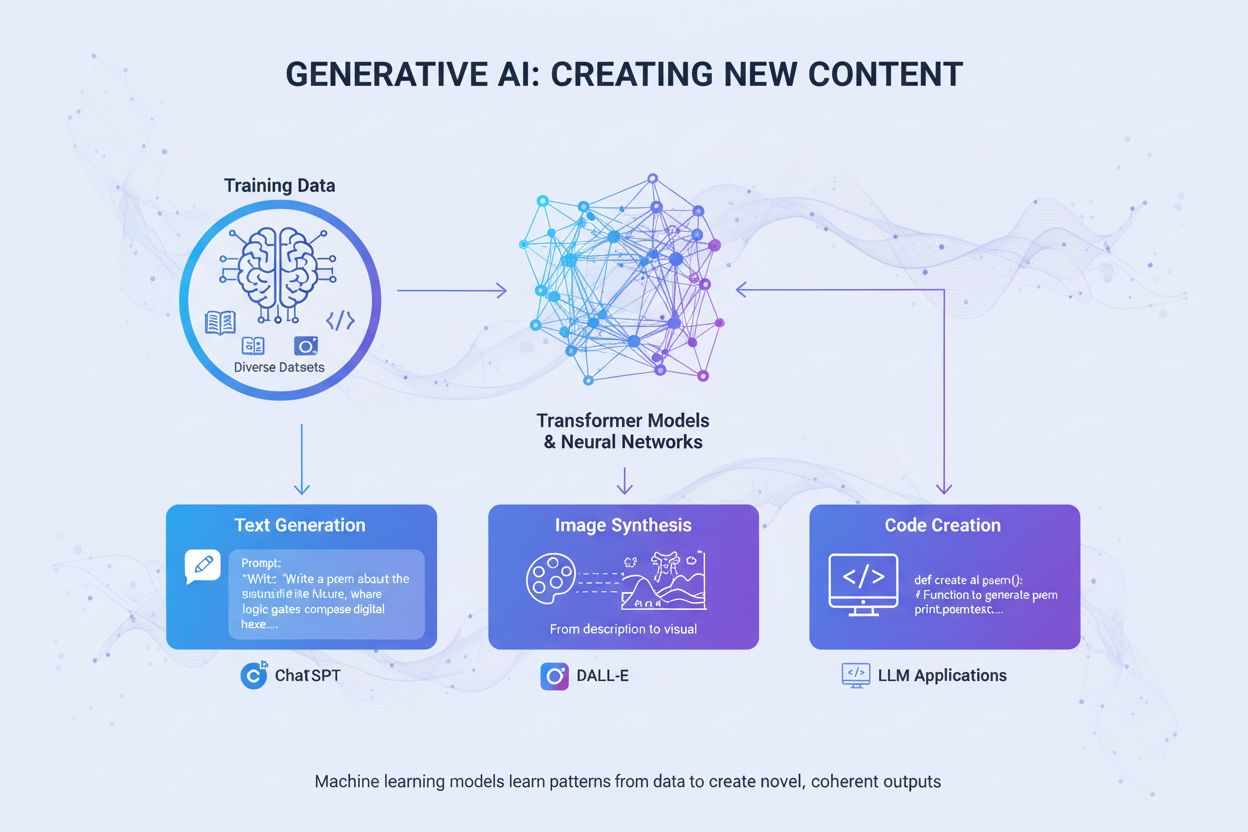
生成AIはニューラルネットワークでトレーニングデータから新しいコンテンツを創出します。仕組みやChatGPT・DALL-Eでの応用、ブランドのAI可視性監視がなぜ重要かを解説。...

AIトレーニングデータへの掲載を目指したコンテンツ最適化の方法を学びましょう。正しいコンテンツ構造、ライセンス設定、オーソリティ構築を通じて、ChatGPT・Gemini・PerplexityなどのAIシステムによるウェブサイト発見性を高めるベストプラクティスを紹介します。...