
AI検索でコンテンツに表を使うべきか?完全ガイドと最適化法
AI検索最適化において表が不可欠な理由を学びましょう。表内の構造化データがAIの理解を深め、引用されるチャンスを高め、ChatGPT、Perplexity、Google AI Overviewsでの可視性を向上させる方法を解説します。...
1 分で読める
テーブルは、情報を水平方向の行と垂直方向の列からなる2次元グリッド形式で整理する構造化データの管理方法であり、効率的なデータの保存、検索、分析を可能にします。テーブルはリレーショナルデータベース、スプレッドシート、およびデータ提示システムの基本的な構成要素であり、ユーザーが複数の次元にわたる関連情報を迅速に特定・比較できるようにします。
テーブルは、情報を水平方向の行と垂直方向の列からなる2次元グリッド形式で整理する構造化データの管理方法であり、効率的なデータの保存、検索、分析を可能にします。テーブルはリレーショナルデータベース、スプレッドシート、およびデータ提示システムの基本的な構成要素であり、ユーザーが複数の次元にわたる関連情報を迅速に特定・比較できるようにします。
テーブルとは、情報を水平方向の行と垂直方向の列からなる2次元グリッド形式に整理する基本的なデータ構造です。最も単純な形では、テーブルは関連するデータの集合を構造的に配置し、行と列の交差点ごとに1つのデータ項目(セル)が格納されます。テーブルはリレーショナルデータベース、スプレッドシート、データウェアハウス、あらゆる情報整理・検索を必要とするシステムの礎となっています。テーブルの強みは、複数の次元にまたがるデータの迅速な視覚的スキャン、論理的比較、標準化されたクエリ言語による特定情報へのプログラム的アクセスを可能にする点です。ビジネス分析、科学研究、AIモニタリングプラットフォームなど、あらゆる分野でテーブルは人間と機械の双方にとって理解しやすい構造化データ提示方式として使われています。
行と列で情報を整理するという概念は、現代コンピュータの出現より何世紀も前から存在していました。古代文明では、在庫管理や取引記録、天文観測のために表形式が用いられてきました。しかし、コンピュータにおけるテーブル構造の形式化は、1970年にEdgar F. Coddによるリレーショナルデータベース理論の開発をもって登場し、データの保存と検索の方法に革命をもたらしました。リレーショナルモデルは、データを明確な関係性を持つテーブルとして整理すべきであると定め、データベース設計の原則を根本的に変えました。1980〜1990年代にはLotus 1-2-3やMicrosoft Excelといったスプレッドシートの普及により、非技術者でも表形式データ組織を扱えるようになりました。現在、約97%の組織がデータ管理・分析にスプレッドシートを使用しており、テーブルベースのデータ組織が依然として重要であることが示されています。近年はカラムナーデータベース、NoSQLシステム、データレイクなど、従来の行指向アプローチに挑戦する新たな技術も生まれていますが、情報整理のための根本的な表形式構造は維持されています。
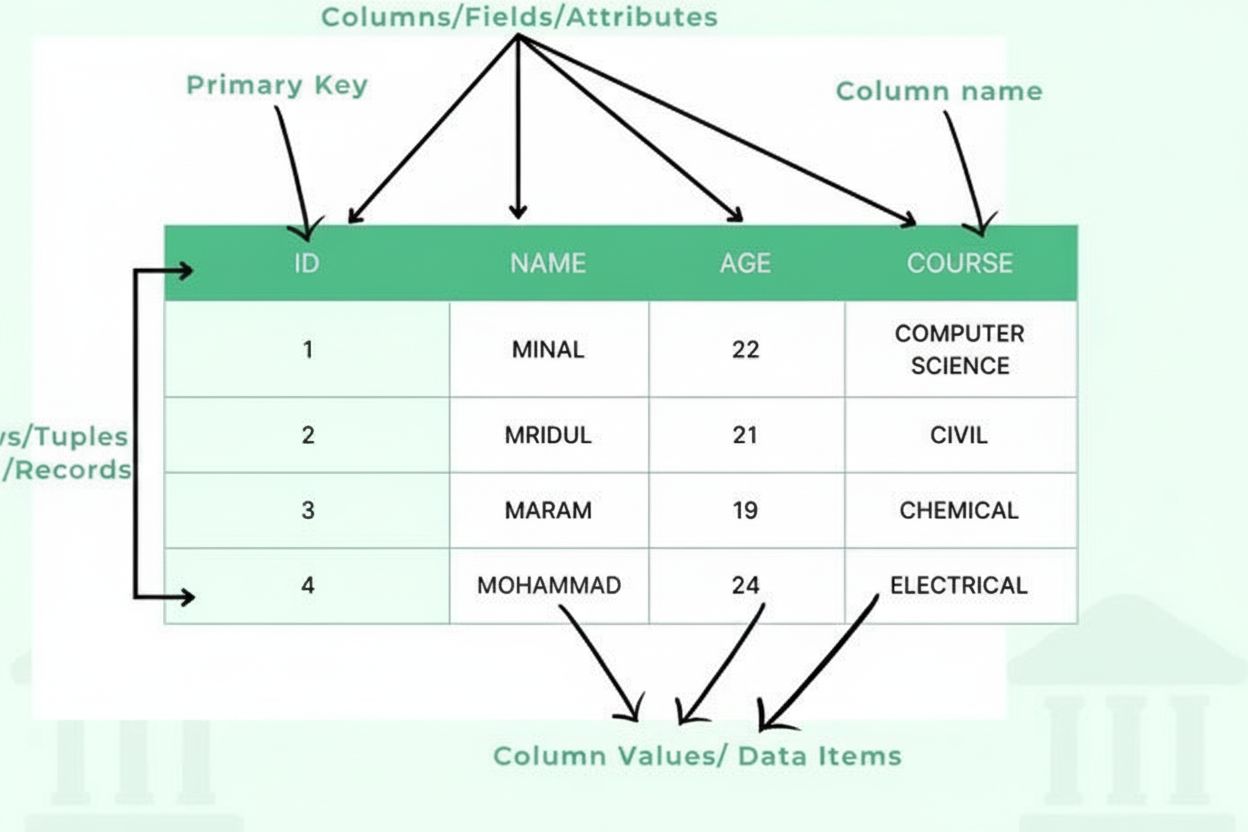
テーブルは、組織的なデータフレームワークを形成するための複数の重要な構造要素から成り立ちます。列(フィールドまたは属性)は垂直方向に並び、「顧客名」「メールアドレス」「購入日」など情報のカテゴリを示します。各列には整数、文字列、日付、少数、あるいはさらに複雑な構造など、格納できる情報の種類を指定するデータ型が定義されています。行(レコードまたはタプル)は水平方向に並び、個々のデータエントリやエンティティを表し、各行には1件分の完全なレコードが格納されます。行と列の交差点にはセルまたはデータ項目が存在し、1つの情報を格納します。列ヘッダーは各列を識別し、テーブルの最上部に表示されデータに文脈を与えます。主キーは各行を一意に識別する特別な列で、重複レコードの発生を防止します。外部キーは他のテーブルの主キーを参照し、テーブル間の関係を構築します。この階層的な構造により、データベースはデータの整合性を維持し、冗長性を防ぎ、複数の条件に基づく複雑なクエリをサポートできます。
| 側面 | 行指向テーブル | 列指向テーブル | ハイブリッドアプローチ |
|---|---|---|---|
| 保存方法 | 完全なレコードごとにデータを保存・アクセス | 個々の列ごとにデータを保存・アクセス | 両者の利点を併せ持つ |
| クエリ性能 | 完全なレコード取得のトランザクションクエリに最適化 | 特定列の分析クエリに最適化 | 混在ワークロードでバランス良好 |
| 用途 | OLTP(オンライントランザクション処理)、業務処理 | OLAP(オンライン分析処理)、データウェアハウス | リアルタイム分析、オペレーショナルインテリジェンス |
| データベース例 | MySQL、PostgreSQL、Oracle、SQL Server | Vertica、Cassandra、HBase、Parquet | Snowflake、BigQuery、Apache Iceberg |
| 圧縮効率 | データの多様性のため圧縮率は低い | 類似値の多い列で高圧縮率 | 特定パターンに最適な圧縮 |
| 書き込み性能 | 完全なレコードで高速書き込み | 列ごと更新が必要なため遅い | 書き込み性能がバランス良好 |
| スケーラビリティ | トランザクション数に強いスケーラビリティ | データ量・クエリ複雑性に強いスケーラビリティ | 両側面でスケーラブル |
リレーショナルデータベース管理システム(RDBMS)において、テーブルはあらかじめ定義されたスキーマに従う行の集合として実装されます。スキーマはテーブルの構造(列名、データ型、制約、関係性)を定義します。データがテーブルに挿入される際、データベース管理システムは各値が列のデータ型や制約に合致しているかを検証します。例えば、INTEGER型の列には文字列は許されず、NOT NULLの列には空エントリは不可です。インデックスは頻繁に検索される列に作成され、テーブル全体を走査することなく特定の行を迅速に特定できるようにします。正規化は冗長性を最小化しデータ整合性を高める設計原則で、情報を関連する複数のテーブルに分割し、キーで接続します。現代のデータベースはトランザクションをサポートし、複数操作の同時成功または同時失敗を保証し、障害時も一貫性を保ちます。データベースエンジンのクエリオプティマイザは、SQLクエリを解析してインデックスやテーブル統計情報を考慮し、最適なデータアクセス方法を決定します。
テーブルは、構造化データをデジタル・印刷両方でユーザーに提示する主要な手段です。ビジネスインテリジェンスおよび分析アプリケーションでは、テーブルが集計指標、業績指標、詳細な取引記録などを表示し、意思決定者が複雑なデータセットを一目で把握できるようにします。83%のビジネスプロフェッショナルが情報分析の主要ツールとしてデータテーブルを利用しているとの調査もあります。ウェブサイトのHTMLテーブルは、<table>、<tr>(行)、<td>(データ)、<th>(ヘッダー)などのセマンティックマークアップで、視覚表示とプログラム的解釈の両方に対応します。Microsoft ExcelやGoogle Sheets、LibreOffice Calcなどのスプレッドシートは、数式、条件付き書式、ピボットテーブルなどの機能拡張により、ユーザーが計算や動的なデータ再編成を行えるようにします。データ可視化のベストプラクティスでは、正確な値の重要性が高い場合、個々のレコードの複数属性を比較する場合、ルックアップや計算が必要な場合にはテーブルの使用が推奨されています。W3Cウェブアクセシビリティ・イニシアチブは、明確なヘッダーと適切なマークアップによる構造化テーブルが、特にスクリーンリーダー利用者のためにデータアクセシビリティ確保の要であると強調しています。
AmICitedのようなAIモニタリングプラットフォームでは、テーブルが異なるAIシステムでコンテンツがどのように登場しているかのデータを整理・提示する上で重要な役割を担います。モニタリングテーブルは、引用頻度、出現日、AIプラットフォーム(ChatGPT、Perplexity、Google AI Overviews、Claude)といった情報、ドメインやURLの参照状況などの指標を追跡します。これにより、組織はAI生成応答におけるブランド可視性を把握し、AIシステムごとの引用傾向の違いを分析できます。モニタリングテーブルの構造化特性により、引用データのフィルタリング・ソート・集計が可能となり、「どのURLがPerplexityで最も頻繁に登場しているか」「過去1か月で引用率はどう変化したか」といった質問にも容易に答えられます。モニタリングシステムのデータテーブルは、AIプラットフォーム間の引用パターン比較、時系列での引用増減分析、どのコンテンツタイプがAI参照を多く受けているかの特定など、多次元での比較も可能です。モニタリングデータはテーブルからレポート、ダッシュボード、さらなる分析ツールへとエクスポートできるため、AI生成コンテンツにおける存在感の最適化を目指す組織にとってテーブルは不可欠です。
効果的なテーブル設計には、構造、命名規則、データ組織原則の慎重な検討が必要です。列名は中身を正確に表す明確で記述的な識別子を使い、省略形や曖昧な記載は避けましょう。データ型の選択は非常に重要で、適切な型を選ぶことで不正データの入力防止や正しいソート・比較操作が可能になります。主キーの定義で各行を一意に識別し、データ整合性や他テーブルとの関係性構築を保証します。正規化は情報を関連テーブルに分けて冗長性を排除します。インデックス戦略はクエリ性能と更新時のオーバーヘッドのバランスを考えて設計します。テーブル構造・列定義・データ型・制約・関係性のドキュメント化は長期的な保守性に不可欠です。アクセス制御でセンシティブなテーブルデータの不正アクセス防止を行いましょう。パフォーマンス最適化ではクエリ実行時間の監視やテーブル構造・インデックス・クエリの調整を行います。バックアップとリカバリ手順の確立でデータ損失や破損からテーブルを守りましょう。
テーブルベースのデータ組織は、基本原則を維持しつつ、より複雑なデータ要件に対応する形で進化し続けています。Apache ParquetやORCなどのカラムナーストレージ形式はビッグデータ環境で標準となり、分析ワークロードに最適化されたテーブル構造を実現しています。JSONやXMLのような半構造化データもテーブル列内に格納できるようになり、テーブルが構造化データと柔軟なデータの両方に対応可能となっています。機械学習の統合により、利用パターンに基づく自動的なテーブル構造最適化やクエリ実行の自動最適化も進んでいます。リアルタイム分析プラットフォームは、従来のバッチ処理を超え、ストリーミングデータや継続的更新への対応を拡張しています。クラウドネイティブデータベースは、分散コンピューティングを活用したテーブル実装を再設計し、地理的に分散した複数サーバーへのスケールアウトを可能にしています。データガバナンスフレームワークは、テーブルのメタデータ、系統管理、品質指標への重視を高め、データ信頼性確保を推進しています。AI活用型データプラットフォームの台頭により、テーブルは機械学習モデルのトレーニングデータとしての構造的ソースとなると同時に、高品質な学習データ設計のあり方にも新たな課題を投げかけています。今後もデータ量の爆発的増加が続く中で、テーブルは情報の整理・クエリ・分析の基盤であり続け、性能・スケーラビリティ・現代的データ技術との統合に向けたイノベーションが進むでしょう。
行はデータの水平方向の並びであり、単一のレコードやエンティティを表します。一方、列は垂直方向の並びで、すべてのレコードに共通する特定の属性やフィールドを表します。データベーステーブルでは、各行が1つのエンティティ(例えば顧客)についての完全な情報を持ち、各列は1種類の情報(例えば顧客名やメールアドレス)を格納します。行と列が組み合わさることで、テーブルの2次元構造が形成されます。
テーブルはリレーショナルデータベースにおける基本的な組織構造であり、効率的なデータの保存、検索、操作を可能にします。テーブルは構造化スキーマを通じてデータの整合性を保ち、複数次元にわたる複雑なクエリをサポートし、主キーや外部キーを用いて異なるデータエンティティ間の関係性を実現します。これにより、膨大なレコードを計算効率的かつ論理的に整理し、ビジネス上意味のある形で運用できるのです。
テーブルは、データ型やカテゴリを定義する列(フィールド/属性)、個々のデータエントリを収める行(レコード/タプル)、各列を識別するヘッダー、実際の値を格納するデータ項目(セル)、各行を一意に識別する主キー、他のテーブルとの関係を持たせる外部キーなど、いくつかの重要な構成要素から成り立ちます。これらの要素がデータの組織化と整合性維持に重要な役割を果たします。
AmICitedのようなAIモニタリングプラットフォームでは、テーブルはAIモデルの出現状況、引用、ブランド言及などのデータを整理・提示するために不可欠です。テーブルにより、AI応答内でコンテンツがいつ・どこで現れたかの構造化データを表示でき、指標の追跡、プラットフォーム間のパフォーマンス比較、特定ドメインやURLの参照傾向の特定が容易になります。
行指向データベース(従来型リレーショナルデータベースなど)は、完全なレコード単位でデータを保存・アクセスするため、1つのエンティティの全情報を必要とするトランザクションに効率的です。列指向データベースは、列単位でデータを保存するため、多数のレコードにまたがる特定属性の分析クエリが高速です。どちらを選ぶかは、主な用途がトランザクション処理か分析クエリかによって決まります。
アクセシブルなテーブルには、ヘッダー用の`
テーブルの列には、整数、浮動小数点数、文字列/テキスト、日付や時刻、ブール値、さらにJSONやXMLのような複雑な型まで、様々なデータ型を格納できます。各列には定義されたデータ型があり、入力できる値を制約することでデータの一貫性を保ち、正しいソートや比較操作を可能にします。一部のデータベースでは地理情報、配列、ユーザー定義型などの特殊な型もサポートしています。
ChatGPT、Perplexity、その他のプラットフォームでAIチャットボットがブランドを言及する方法を追跡します。AI存在感を向上させるための実用的なインサイトを取得します。
AI検索最適化において表が不可欠な理由を学びましょう。表内の構造化データがAIの理解を深め、引用されるチャンスを高め、ChatGPT、Perplexity、Google AI Overviewsでの可視性を向上させる方法を解説します。...

テーブルやリスト、構造化データがコンテンツのAI検索結果での可視性をどのように高めるかを学びましょう。Google AI OverviewsやPerplexityなどのLLM・AIシステム向けコンテンツ最適化のベストプラクティスをご紹介します。...
構造化データは、検索エンジンがウェブページの内容を理解するための標準化マークアップです。JSON-LD、schema.org、マイクロデータがSEO、リッチリザルト、AIでの可視性をどう高めるのかを学びましょう。...
クッキーの同意
閲覧体験を向上させ、トラフィックを分析するためにクッキーを使用します。 See our privacy policy.