トランザクショナルインテント
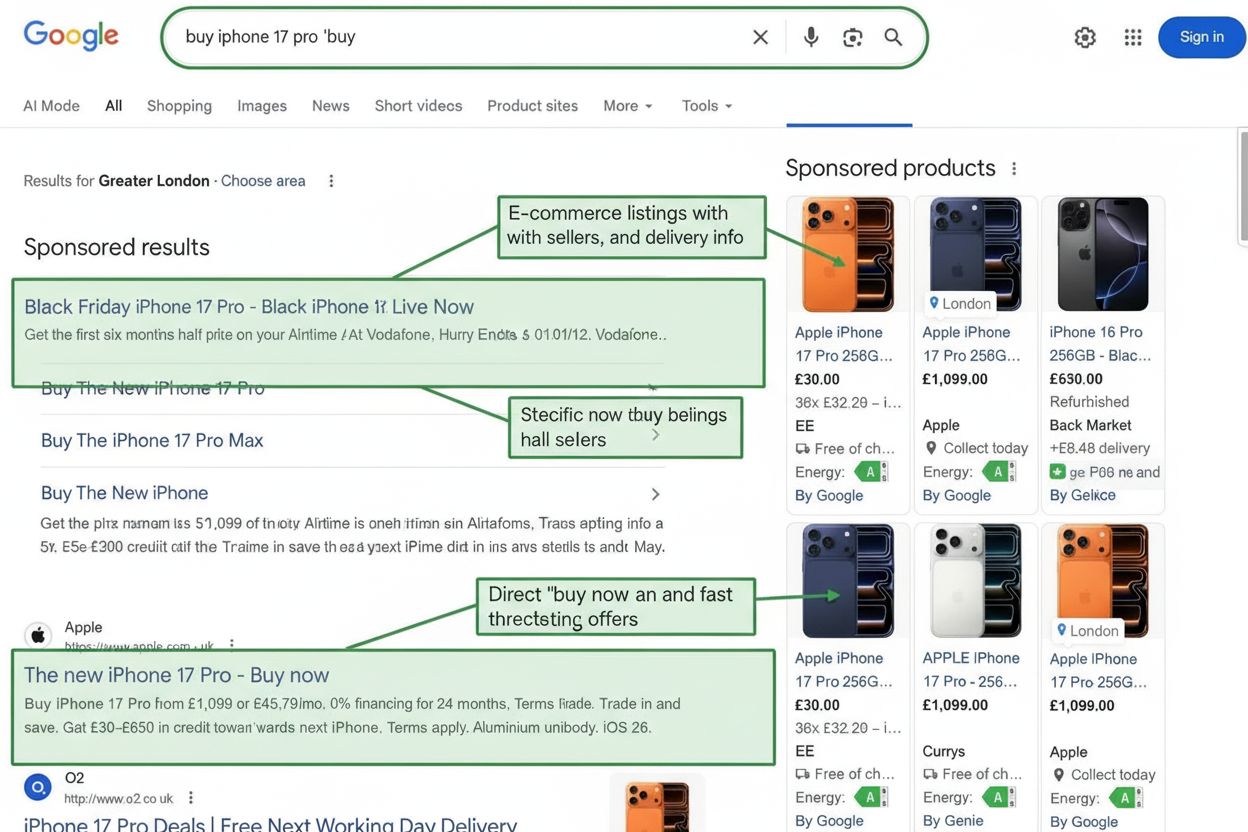
トランザクショナルインテントは、購入やアクションの意図を持つ検索を定義します。高いコンバージョンを生むトランザクショナルキーワードの特定、ターゲティング、最適化方法を学び、売上とコンバージョンを促進しましょう。...
1 分で読める

マルチヘッド自己注意機構に基づくニューラルネットワークアーキテクチャで、逐次データを並列で処理し、ChatGPT、Claude、Perplexityのような現代の大規模言語モデルの発展を可能にします。2017年の論文「Attention is All You Need」で提案され、トランスフォーマーは事実上すべての最先端AIシステムの基盤技術となっています。
マルチヘッド自己注意機構に基づくニューラルネットワークアーキテクチャで、逐次データを並列で処理し、ChatGPT、Claude、Perplexityのような現代の大規模言語モデルの発展を可能にします。2017年の論文「Attention is All You Need」で提案され、トランスフォーマーは事実上すべての最先端AIシステムの基盤技術となっています。
トランスフォーマーアーキテクチャは、2017年にGoogleの研究者によって発表された論文「Attention is All You Need」で導入された革新的なニューラルネットワーク設計です。その本質はマルチヘッド自己注意機構にあり、これによってモデルはデータのシーケンス全体を逐次ではなく並列で処理できるようになりました。アーキテクチャは積み重ねられたエンコーダ層とデコーダ層からなり、それぞれに自己注意サブレイヤーとフィードフォワードニューラルネットワークが含まれ、残差接続とレイヤーノーマライゼーションで結ばれています。トランスフォーマーアーキテクチャは、ChatGPT、Claude、Perplexity、Google AI Overviewsなど、事実上すべての現代の**大規模言語モデル(LLM)**の基盤技術となり、過去10年で最も重要なニューラルネットワークのイノベーションといえるでしょう。
トランスフォーマーアーキテクチャの意義は、その技術的な優雅さを超えた広がりを持ちます。2017年の「Attention is All You Need」論文は20万8千件以上引用され、機械学習史上最も影響力のある論文のひとつとなっています。このアーキテクチャはAIシステムによる言語処理と理解を根本から変え、数十億のパラメータを持つモデルの登場を可能にし、高度な推論、創造的な文章生成、複雑な問題解決を実現しました。ほぼすべてトランスフォーマー技術上に築かれたエンタープライズLLM市場は2024年に67億ドルと評価され、2034年までに年平均26.1%の成長が見込まれており、現代AIインフラにおけるアーキテクチャの不可欠な重要性を示しています。
トランスフォーマーアーキテクチャの開発は、逐次データ処理のためのニューラルネットワークに関する数十年の研究の集大成であり、深層学習史における転換点です。トランスフォーマー以前は、リカレントニューラルネットワーク(RNN)やその派生系、特に長短期記憶(LSTM)ネットワークが自然言語処理タスクの主流でした。しかし、これらのアーキテクチャには根本的な限界がありました。シーケンスを一度に1要素ずつ逐次処理するため学習が遅く、長いシーケンス内の離れた要素間の依存関係を捉えるのが苦手でした。さらに、勾配消失問題によって、RNNが長距離の関係性を学習する能力が大きく制限されていました。
2014年、Bahdanauらによる注意機構の導入が突破口となり、モデルが距離に関係なく入力シーケンスの重要部分に注目できるようになりました。しかし、当初の注意機構はRNNの補助として使われていました。2017年のトランスフォーマー論文はこの概念をさらに発展させ、「Attention is All You Need」すなわち「注意のみ」でニューラルネットワークアーキテクチャ全体を構築できると提案し、再帰構造を完全に排除しました。この洞察は劇的な変化をもたらしました。逐次処理を排除することで、トランスフォーマーは大規模な並列処理を可能とし、研究者はGPUやTPUを用いてこれまでにない規模のデータで学習できるようになったのです。元論文の最大トランスフォーマーモデルは8GPUで3.5日間学習され、スケールと並列化が飛躍的な性能向上につながることを示しました。
トランスフォーマー論文以降、アーキテクチャの進化は急速でした。2019年にGoogleが公開したBERT(Bidirectional Encoder Representations from Transformers)は、トランスフォーマーエンコーダを大規模コーパスで事前学習し、多様な下流タスクに微調整できることを示しました。BERTの最大モデルは3億4500万パラメータを持ち、64台の専用TPUで4日間、推定7,000ドルのコストで学習されましたが、多数の言語理解ベンチマークで最先端の成績を達成しました。一方、OpenAIのGPTシリーズはデコーダのみのトランスフォーマーアーキテクチャによる言語モデリングに特化。GPT-2は15億パラメータで、言語モデリングだけでも驚くほど高性能なシステムができることを示し、GPT-3では1750億パラメータで新しい能力の発現(few-shot learningや複雑な推論など)が見られ、AIの可能性への期待を一変させました。
トランスフォーマーアーキテクチャは、効率的な並列処理と高度な文脈理解を支えるいくつかの技術要素で構成されています。入力埋め込み層は、離散的なトークン(単語やサブワード単位)を連続値ベクトル(通常512次元以上)に変換します。さらに位置エンコーディングでそれぞれのトークンの順番情報をサイン・コサイン関数によって加味します。これは、RNNが再帰構造で順序を自然に保持できるのに対し、トランスフォーマーは全トークンを同時に処理するため、語順や距離の明示的な信号が必要となるからです。
自己注意機構は、従来のニューラルネットワーク設計とトランスフォーマーを分ける革新点です。入力シーケンスの各トークンごとに、クエリベクトル(そのトークンが何を求めているか)、キーベクトル(各トークンがどんな情報を持つか)、バリューベクトル(伝搬したい実際の情報)を計算します。クエリと全てのキー間の類似度をドット積で算出し、ソフトマックスで正規化して注意重みを得ます。この重みでバリューベクトルの加重和を計算し、各トークンが他のトークンから必要な情報だけを集められる仕組みです。これにより文脈や関係性の理解が可能となります。
マルチヘッドアテンションはこの概念をさらに拡張し、通常8、12、16個程度の並列注意機構を同時に走らせます。各ヘッドはクエリ・キー・バリューの異なる線形射影上で動作し、異なる関係やパターンを捉えます。例えば、あるヘッドは構文的関係、他のヘッドは意味的関係や長距離依存に注目するなどです。すべてのヘッドの出力を連結し線形変換することで、豊かな文脈情報を獲得します。研究により各ヘッドが異なる言語現象に特化して学習することが分かっています。
エンコーダ・デコーダ構造は、これらの注意機構を階層的な処理パイプラインとして組織化します。エンコーダは複数の層(通常6層以上)からなり、各層にマルチヘッド自己注意サブレイヤーと位置ごとのフィードフォワードネットワークを持ちます。残差接続を各サブレイヤーの周囲に配置することで、勾配がネットワーク全体に直接流れやすくなり、安定してより深いアーキテクチャが可能になっています。レイヤーノーマライゼーションも各サブレイヤー後に施され、アクティベーションのスケールを均一化します。デコーダはエンコーダに加えてエンコーダ-デコーダアテンション層を持ち、出力トークン生成時に入力の関連部分に注目できるようにしています。GPTのようなデコーダのみのアーキテクチャでは、過去の出力トークンに基づき自動回帰的に次のトークンを生成します。
| 側面 | トランスフォーマーアーキテクチャ | RNN/LSTM | 畳み込みニューラルネットワーク(CNN) |
|---|---|---|---|
| 処理方法 | 注意機構によるシーケンス全体の並列処理 | 逐次処理、1要素ずつ | 固定サイズウィンドウでの局所畳み込み演算 |
| 長距離依存性 | 優秀:注意で遠距離トークンも直接接続 | 弱い:勾配消失・逐次処理の制約あり | 限定的:多層でレセプティブフィールド拡大必要 |
| 学習速度 | 非常に高速:GPU/TPUで大規模並列化 | 遅い:逐次処理で並列化困難 | 固定長入力なら速い:可変長は不向き |
| メモリ要件 | 高い:注意機構でシーケンス長二乗に比例 | 低め:シーケンス長に線形 | 中程度:カーネルサイズ・深さによる |
| スケーラビリティ | 優秀:数十億パラメータまで拡張可能 | 限定的:大規模モデルの学習困難 | 画像には良いがシーケンスには不向き |
| 主な用途 | 言語モデル、機械翻訳、テキスト生成 | 時系列、逐次予測(現在は稀) | 画像分類、物体検出、コンピュータビジョン |
| 勾配伝播 | 安定:残差接続で深層も学習可能 | 問題あり:勾配消失・爆発しやすい | 安定:局所接続で勾配伝播しやすい |
| 位置情報 | 明示的な位置エンコーディング必須 | 逐次処理で暗黙的に保持 | 空間構造で暗黙的に保持 |
| 最先端LLM | GPT、Claude、Llama、Granite、Perplexity | 現在はほぼ使われない | 言語モデリングには利用されない |
トランスフォーマーアーキテクチャと現代の大規模言語モデル(LLM)は密接不可分な関係にあります。過去5年間に発表された主要なLLM(OpenAIのGPT-4、AnthropicのClaude、MetaのLlama、GoogleのGemini、IBMのGranite、PerplexityのAIモデルなど)はすべてトランスフォーマーアーキテクチャを基盤としています。モデルサイズや学習データの両面で効率的にスケールできるこのアーキテクチャのおかげで、現代AIシステムの特徴的な能力が実現されました。パラメータ数が数百万から数十億、さらに数千億へと増えても、トランスフォーマーの並列化と注意機構により、学習時間が比例して増加することなくスケールできます。
ほとんどの現代LLMが採用する自動回帰デコーディングは、まさにトランスフォーマーデコーダアーキテクチャの応用です。テキスト生成時、モデルは入力プロンプトをエンコーダ(またはデコーダのみの場合は全デコーダ)で処理し、出力トークンを1つずつ生成します。各トークン生成時に全語彙に対する確率分布をソフトマックスで計算し、最も確率の高いトークンを選択(または温度パラメータに応じてサンプリング)します。この処理を数百回・数千回と繰り返すことで、一貫性ある長文が生成されます。自己注意機構によって生成文全体の文脈が保たれ、登場人物やテーマ、論理展開が一貫した長文生成が可能です。
大規模トランスフォーマーモデルで観測される新たな能力の発現(few-shot learningやchain-of-thought reasoning、in-context learningなど)は、トランスフォーマーアーキテクチャの設計そのものの結果です。マルチヘッドアテンションの多様な関係性把握力、大規模なパラメータ数、多様なデータでの学習によって、明示的に訓練されていないタスクもこなせるようになります。例えばGPT-3は、言語モデリングだけで学習されているにも関わらず、計算問題やコード生成、クイズ回答なども可能です。こうした性質により、トランスフォーマー型LLMは現代AI革命の基盤となり、対話AIやコンテンツ生成、コード生成、科学研究支援など幅広い用途で活用されています。
自己注意機構は、トランスフォーマーを従来手法と根本的に差別化し、その優れた性能を生み出す設計上の核です。自己注意の理解には、言語の曖昧な代名詞解釈の課題が参考になります。例えば「The trophy doesn’t fit in the suitcase because it is too large.」という文で “it” がどちらを指すかは文脈次第です。トランスフォーマーモデルは、こうした曖昧さを単語間の関係性を理解して解決しなければなりません。
自己注意は、各トークンの埋め込みを学習済みの重み行列WQでクエリベクトルに、WKでキーベクトルに、WVでバリューベクトルにそれぞれ変換します。クエリとキーのドット積をキー次元(通常√64≒8)で正規化し、ソフトマックスで注意重みとします。最終的に各トークンの出力は全バリューベクトルの加重和で計算されます。これにより、各トークンが他の全トークンから選択的に情報を集約できるのです。
この自己注意の数式は、行列演算としても簡潔に表せます:Attention(Q, K, V) = softmax(QK^T / √d_k)V。Q、K、Vはそれぞれ全トークン分のクエリ・キー・バリューベクトルの行列です。この行列演算によりGPUによる高速並列計算が可能となり、512トークンのシーケンスをRNNの1トークンとほぼ同じ時間で処理できるほど高速化します。こうした計算効率と長距離依存の把握力がトランスフォーマーが言語モデリングで主流となった理由です。
マルチヘッドアテンションは、自己注意機構をさらに発展させ、複数並列の注意計算を行い、それぞれが異なる関係性を学習します。典型的なトランスフォーマーでは8個の注意ヘッドを用い、入力埋め込みを8つの異なる表現サブスペースに線形射影し、各サブスペースごとに独立して注意計算を行います。出力は全ヘッド分を連結・線形変換して最終的なマルチヘッドアテンション出力とします。これにより、モデルは異なる位置・異なる表現空間で同時に情報に注目できます。
トランスフォーマーの学習済みモデルを解析した研究では、ヘッドごとに構文的関係(例:動詞と主語・目的語)や意味的関係、長距離依存性、あるいはトークン自身への注目(恒等写像的動作)など、それぞれ異なる言語現象に特化していることが分かっています。これは明示的な指示なしに自然発生的に生じる現象であり、マルチヘッド構造が多様かつ補完的な表現学習に優れている証拠です。
注意ヘッド数は重要なハイパーパラメータで、大規模モデルでは16や32などより多くのヘッドを利用し、より多様な関係性把握を可能にしています。ただし計算全体の次元数は通常一定なので、ヘッド数が増えると1ヘッドあたりの次元が減ります。これは多様性と計算効率のバランスを取る設計です。マルチヘッド方式はBERTやGPT、ビジョン・オーディオ・マルチモーダル向けの特殊なトランスフォーマーにも標準搭載されています。
元論文「Attention is All You Need」で提案されたエンコーダ・デコーダ構造は、機械翻訳などシーケンス変換タスクに最適化されています。エンコーダは入力シーケンスを文脈豊かな表現列に変換します。各エンコーダ層はマルチヘッド自己注意サブレイヤーと位置ごとのフィードフォワードネットワークからなり、残差接続(スキップ接続)でそれぞれの入力を出力に加算します。これは画像認識のResNetから着想を得ており、非常に深いネットワークでも勾配が伝播しやすくなり学習が安定します。
デコーダは、エンコーダ出力とそれまでに生成したトークン情報を使い、出力シーケンスを1トークンずつ生成します。各デコーダ層はマスク付き自己注意サブレイヤー(未来トークン参照の防止)、エンコーダ-デコーダ注意サブレイヤー、位置ごとのフィードフォワードネットワークで構成されます。自己注意サブレイヤーのマスキングにより、i番目の予測はi未満のトークンのみ参照できるという自動回帰構造が実現されます。
エンコーダ・デコーダ構造は、入力・出力の構造や長さが異なる機械翻訳、要約、質問応答などに特に有効です。しかし、現代のGPTなどLLMではデコーダのみの構造が主流となっています。これはモデルの複雑さを減らし、自己注意のみで入力と出力の両方をうまく処理できるためです。
トランスフォーマーアーキテクチャで重要な課題のひとつが、シーケンス内のトークン順序の表現です。RNNは構造上順序が保持されますが、トランスフォーマーは全トークンを同時処理するため、位置情報がなければ「The cat sat on the mat」と「mat the on sat cat The」を区別できません。これを解決するのが位置エンコーディングです。
元論文ではサイン・コサインの正弦波位置エンコーディングを採用し、位置pos・次元iごとに以下のように計算します:
低次元ほどゆっくり変化し長距離関係を、高次元ほど急速に変化し詳細な位置情報を表現します。これにより、学習時より長いシーケンスへの汎化性や、滑らかな位置遷移、相対位置関係の学習が可能です。位置エンコーディングベクトルは第1注意層前にトークン埋め込みに加算され、モデルは学習を通じてこの情報を利用します。
他にも相対位置表現(トークン間距離を符号化)や回転位置埋め込み(RoPE)(位置に応じてベクトルを回転)などの方式が提案されており、特に長大シーケンスやより長い入力での微調整時に効果を発揮します。位置エンコーディングの選択は性能に大きく影響し、現在も最適化の研究が続いています。
トランスフォーマーアーキテクチャを理解することは、ChatGPT、Claude、Perplexity、Google AI Overviewsなど現代AIシステムがどのように応答を生成しているかを把握するうえで不可欠です。これらのシステムはすべてトランスフォーマー技術上に構築されており、自己注意層
トランスフォーマーアーキテクチャは自己注意を利用して全てのシーケンスを並列処理しますが、RNNやLSTMはシーケンスを一度に1要素ずつ逐次処理します。この並列化によってトランスフォーマーは学習が大幅に高速化し、離れた単語やトークン間の長距離依存関係をより良く捉えることができます。また、RNNが抱えていた勾配消失問題も回避でき、より長いシーケンスから効果的に学習できます。
自己注意は、入力シーケンスの各トークンごとに3つのベクトル(クエリ、キー、バリュー)を計算します。あるトークンのクエリベクトルを全トークンのキーベクトルと比較して関連度スコアを算出し、それをソフトマックスで正規化します。得られた重みをバリューベクトルに適用し、文脈に応じた表現を作ります。これにより各トークンがシーケンス内の他の関連トークンに「注意を向ける」ことができ、文脈や関係性の理解を可能にします。
主な構成要素は以下の通りです:(1)トークンとその位置情報を表す入力埋め込みと位置エンコーディング、(2)複数の表現サブスペースで注意を計算するマルチヘッド自己注意層、(3)各位置に独立して適用されるフィードフォワードニューラルネットワーク、(4)入力シーケンスを処理するエンコーダースタック、(5)出力シーケンスを生成するデコーダースタック、(6)学習安定性のための残差接続とレイヤーノーマライゼーション。これらが連携し、効率的な並列処理と文脈理解を実現します。
トランスフォーマーアーキテクチャは、シーケンス全体を並列処理することで、逐次処理のRNNと比べて学習時間を劇的に短縮できます。自己注意によって長距離依存関係もより強力に捉え、文書全体の文脈理解が可能です。また、より大規模なデータセットやパラメータ数に効率的にスケールでき、数十億パラメータのモデルで現れる新たな能力の発現にも不可欠となっています。
マルチヘッドアテンションは、通常8個や16個といった複数の並列注意機構を同時に走らせ、それぞれが異なる表現サブスペースで動作します。各ヘッドはデータ内の異なる関係やパターンに注目し、すべてのヘッドの出力を連結・線形変換することで多様な文脈情報を捉えられます。この仕組みにより、複雑な関係性の理解・性能向上が実現されています。
位置エンコーディングは、サイン・コサイン関数を用いて異なる周波数でトークンの位置情報を入力埋め込みに加算します。トランスフォーマーはRNNと異なり全トークンを並列処理するため、語順を理解するには明示的な位置情報が必要です。位置エンコーディングベクトルをトークン埋め込みに加えた上で処理することで、モデルは位置が意味に与える影響を学習し、学習時より長いシーケンスへの汎化も可能にします。
エンコーダは入力シーケンスを多層の自己注意・フィードフォワードネットワークで文脈豊かな表現に変換します。デコーダは出力シーケンスを1トークンずつ生成し、エンコーダ-デコーダアテンションで入力の関連部分に注目します。この構造は機械翻訳などのシーケンス変換タスクに特に有効ですが、現代のLLMではテキスト生成タスクにはデコーダのみの構造が一般的です。
トランスフォーマーアーキテクチャはChatGPT、Claude、Perplexity、Google AI Overviewsなどのプラットフォームで応答を生成するAIシステムの基盤です。トランスフォーマーがテキストをどのように処理・生成するかを理解することは、ブランドやドメインがAI生成応答でどこに現れるかを追跡するAmICitedのようなAIモニタリングプラットフォームにとって非常に重要です。文脈理解と一貫性あるテキスト生成能力が、AI出力内でのブランドの言及や表現に直接影響します。
ChatGPT、Perplexity、その他のプラットフォームでAIチャットボットがブランドを言及する方法を追跡します。AI存在感を向上させるための実用的なインサイトを取得します。
トランザクショナルインテントは、購入やアクションの意図を持つ検索を定義します。高いコンバージョンを生むトランザクショナルキーワードの特定、ターゲティング、最適化方法を学び、売上とコンバージョンを促進しましょう。...

トラストシグナルは、ユーザーとAIシステムのためにブランドの信頼性を確立する信用指標です。認証バッジ、推薦文、セキュリティ要素がコンバージョンとAI引用をどのように高めるかを学びましょう。...

AIシステムにおけるトランザクショナル検索インテントを理解しましょう。ChatGPTやPerplexityなどのAI検索エンジンで、ユーザーがアクションを起こす・購入を決断する際にどのようにAIとやり取りするかを学べます。...