
AIコンテンツライセンス
AIシステムが著作権保護されたコンテンツをどのように利用するかを規定するAIコンテンツライセンス契約について学びましょう。ライセンスの種類、主要な構成要素、プラットフォーム、クリエイター向けベストプラクティスを解説します。...
1 分で読める
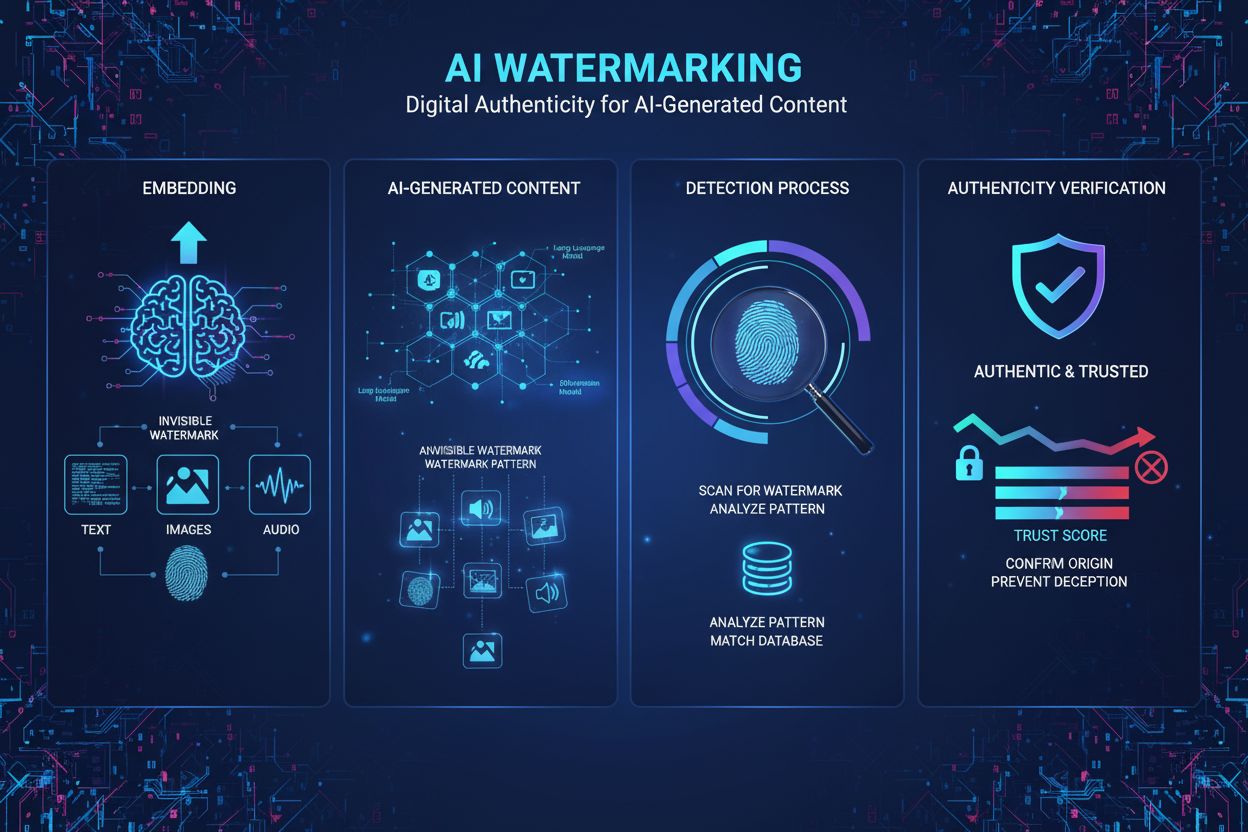
AIコンテンツのウォーターマークは、AIが生成したテキスト、画像、音声、または動画に、不可視または可視のデジタルマーカーを埋め込むことで、そのコンテンツが機械によって作成されたものであることを識別・認証するプロセスです。これらのウォーターマークはデジタル指紋として機能し、さまざまなプラットフォームやアプリケーションにおいてAI生成コンテンツの検出、検証、追跡を可能にします。
AIコンテンツのウォーターマークは、AIが生成したテキスト、画像、音声、または動画に、不可視または可視のデジタルマーカーを埋め込むことで、そのコンテンツが機械によって作成されたものであることを識別・認証するプロセスです。これらのウォーターマークはデジタル指紋として機能し、さまざまなプラットフォームやアプリケーションにおいてAI生成コンテンツの検出、検証、追跡を可能にします。
AIコンテンツのウォーターマークとは、AIが生成した素材にデジタルマーカー、パターン、署名などを埋め込んで、その出所を識別・認証・追跡するプロセスを指します。これらのウォーターマークはデジタル指紋として機能し、テキスト・画像・音声・動画などの形式において、機械生成と人間執筆のコンテンツを区別します。AIコンテンツのウォーターマークの主な目的は、コンテンツの出所に透明性を持たせ、偽情報の対策、知的財産の保護、急速に拡大する生成AIの分野で説明責任を担保することです。従来の物理的な文書や画像の可視ウォーターマークとは異なり、現代のAIウォーターマーク技術は多くの場合、専用アルゴリズムでのみ検出可能な不可視パターンを用いることで、品質を保ちながら高い認証能力を維持します。
ウォーターマークの概念は、もともと銀行券や文書の偽造防止策として物理世界で発展しました。デジタルメディアが普及する中で、1990年代から2000年代にかけて画像・音声・動画向けのウォーターマーク技術が研究されました。しかし、2022〜2023年にChatGPT、DALL-E、Midjourneyなどの高度な生成AIモデルが登場したことで、標準化されたAIコンテンツ認証手法の緊急性が高まりました。AIによるリアルな合成コンテンツの急増を受けて、各国政府・テクノロジー企業・市民社会組織はウォーターマークを重要な安全策と位置づけるようになりました。Brookings Institutionの調査によれば、企業の78%以上が合成メディアリスク管理のためにAI主導のコンテンツ監視ツールの重要性を認識しています。EU AI法は2024年3月に正式採択され、AIコンテンツのウォーターマークを義務付けた最初の主要規制枠組みとなり、AIシステム提供者に出力のAI生成マーキングを求めています。この規制の流れによりウォーターマーク技術の研究開発が加速し、Google DeepMind、OpenAI、Metaなどが高信頼なウォーターマークソリューションに多額の投資を行っています。
AIウォーターマークの技術的アプローチは大きく分けて可視ウォーターマークと不可視ウォーターマークの2つがあります。可視ウォーターマークは、DALL-Eが生成画像に配置する5色の四角形や、ChatGPTの「OpenAIによってトレーニングされた言語モデルです」といったラベルなど、目に見えるマーカーやロゴ、テキストが該当します。実装は容易ですが、簡単な編集で容易に除去可能です。一方、不可視ウォーターマークは人間の知覚では判別できない微細なパターンを埋め込み、専用アルゴリズムでのみ検出します。AI生成画像では、メリーランド大学のツリーリングウォーターマークのように、拡散過程前の初期ノイズにパターンを埋め込むことで、トリミングや回転、フィルタに強い耐性を持たせます。AI生成テキストでは、統計的ウォーターマークが有望な手法で、言語モデルが特定トークン(「グリーントークン」)を好み、他のトークン(「レッドトークン」)を避けるように生成を制御します。これにより、検出アルゴリズムが高精度で識別可能な統計的に異常な単語配列を作ります。音声ウォーターマークは、画像同様に人間の聴覚範囲外(20Hz未満や20,000Hz超)にパターンを埋め込みます。Google DeepMindのSynthIDは、生成・検出モデルを共同訓練することで、変換耐性と品質維持を両立した現代ウォーターマークの代表例です。
| ウォーターマーク方式 | コンテンツ種別 | 耐性 | 品質への影響 | モデルアクセス必要性 | 検出性 |
|---|---|---|---|---|---|
| 可視ウォーターマーク | 画像・動画 | 非常に低い | なし | 不要 | 高い(人間) |
| 統計的ウォーターマーク | テキスト・画像 | 高い | 最小限 | 必要 | 高い(アルゴリズム) |
| 機械学習ベース | 画像・音声 | 高い | 最小限 | 必要 | 高い(アルゴリズム) |
| ツリーリングウォーターマーク | 画像 | 非常に高い | なし | 必要 | 高い(アルゴリズム) |
| コンテンツ出所証明(C2PA) | 全メディア | 中程度 | なし | 不要 | 中程度(メタデータ) |
| 事後検出 | 全メディア | 低い | N/A | 不要 | 低い(信頼性低) |
統計的ウォーターマークは、AI生成テキストの認証に最も現実的な技術であり、画像や音声のような多次元空間を持たないテキスト特有の課題に対応します。生成時に言語モデルが開発者のみが知る暗号鍵に基づき、特定トークンを好んで選択し、他を避けるようランダム性を調整します。検出時は生成テキストから検出されたトークンパターンが偶然現れる確率を計算し、統計的にありえない場合はウォーターマークの存在を示します。メリーランド大学やOpenAIの研究により、テキスト品質を維持しつつ高精度な検出が可能であることが証明されています。ただし、統計的ウォーターマークにも限界があり、数学的解答や歴史的事実など生成自由度が低い場合は効果が下がり、翻訳や大幅な書き換えで検出信頼度が低下します。SynthID TextはHugging Face Transformers v4.46.0+で利用可能となり、暗号鍵やn-gram長などのパラメータを調整して実用的なウォーターマークを提供します。
AI生成画像は多次元空間を活かした高度なウォーターマークが可能です。ツリーリングウォーターマークは、拡散処理前の初期画像にパターンを埋め込むことで、トリミング・ぼかし・回転などの変換にも耐える一方、画質劣化がありません。MetaやGoogleの機械学習ベースのウォーターマークは、ニューラルネットワークで不可視パターンの埋め込みと検出を行い、未加工画像で96%以上の検出精度とピクセル単位攻撃への耐性を両立します。音声ウォーターマークも同様に知覚外の周波数帯にパターンを埋め込みます。Meta開発のAudioSealは生成器・検出器を共同訓練し、自然な音声変換にも耐性を持たせつつ、知覚的損失を用いて元音声との聞き分けができない品質を維持します。これらの手法は、不可視ウォーターマークでも耐性と品質維持が両立可能であることを示していますが、モデルへのアクセスが埋め込みには不可欠です。
AIコンテンツのウォーターマークに関する規制環境は急速に進化しており、複数の法域で義務化が進んでいます。EU AI法は2024年3月正式採択の総合的な法制度で、全ての生成AIシステム提供者にAI生成コンテンツへのマーキングを義務付けます。カリフォルニア州のAI透明化法(SB 942)は2026年1月1日施行で、該当AI提供者に無料のAIコンテンツ検出ツールの公開提供を義務付け、ウォーターマークまたは同等の認証手段が実質的に必須となります。米国国防認可法(NDAA)2024年度版はウォーターマーク技術評価コンテストや「業界オープン技術標準」に基づく出所情報埋め込みのパイロット事業を国防総省に指示しています。さらに、ホワイトハウスのAI大統領令も商務省にAI生成コンテンツのラベリング基準策定を指示しています。これらの規制は、AIウォーターマークが透明性・説明責任・消費者保護に不可欠であるとの国際的合意を反映しています。一方、オープンソースモデルや国際協調、普遍的なウォーターマーク標準の技術的実現可能性など、実装上の課題も残されています。
技術進展にもかかわらず、AIウォーターマークには実効性を制約する大きな課題があります。ウォーターマーク除去は、テキストの言い換え、画像のトリミングやフィルタ、翻訳、敵対的改変など様々な手法で達成可能です。デューク大学の研究では、機械学習ベース検出器に対する概念実証攻撃が示され、最先端手法でも執拗な攻撃者には脆弱であることが明らかになっています。非普遍性問題も深刻で、ウォーターマーク検出器はモデルごとに異なり、各AI企業の個別検出サービスを利用する必要があります。中央レジストリや標準化プロトコルがなければ、AI生成確認は非効率かつ場当たり的な作業となります。特にテキストでの誤検出率(人間作成をAI生成と誤判定・逆も同様)は依然として課題で、軽微な改変でも検出精度が低下します。オープンソースモデル対応もガバナンス上の課題で、ダウンロード後のコード除去でウォーターマークが無効になります。品質劣化も問題で、ウォーターマーク埋め込みのためモデル出力を強制すると生成品質や柔軟性が損なわれることがあります。ウォーターマークにユーザー識別情報が含まれる場合のプライバシー影響も慎重な政策策定が必要です。さらに、コンテンツが短い場合や大幅に改変された場合は検出信頼度が大幅に低下し、一部用途では有用性が制限されます。
AIウォーターマークの今後は、技術革新・規制調和・検出/検証インフラの整備にかかっています。検出手法の公開に耐える公開型ウォーターマークの研究が進展しており、第三者サービスの信頼不要な分散型検証も視野に入ります。ICANNなどの標準化団体や業界コンソーシアム主導で普遍的ウォーターマークプロトコルが制定されれば、断片化が解消されクロスプラットフォーム検出が効率化します。C2PAのようなコンテンツ出所証明標準との統合も進み、ウォーターマークとメタデータによる多層認証が可能となります。翻訳や言い換えでも検出可能な耐変換性ウォーターマークの開発も進行中で、多言語認証用途に期待されています。ブロックチェーン型検証システムによる検出記録の不可逆性・信頼性向上も将来的に有望です。生成AIの進化に合わせてウォーターマーク技術も進化が必要で、巧妙な回避に対応する新手法の開発が求められます。EU AI法やカリフォルニア州法の規制モメンタムは、世界的な標準導入と高耐性技術の市場インセンティブを生み出すでしょう。ただし、ウォーターマークは主に商用主要モデル由来のAIコンテンツ管理にとどまり、即時検出が求められるハイリスク用途では限界があることも現実的に認識すべきです。AmICitedのようなAIコンテンツモニタリングプラットフォームとウォーターマーク基盤の統合により、企業はAI応答でのブランド帰属を追跡し、引用時の正当な認識を確保できます。今後は自動ウォーターマーク検出と人手検証の連携による、ジャーナリズム・法廷・学術分野など重要用途での人間とAIの協働認証が重視されるでしょう。
可視ウォーターマークはロゴやテキストラベルのように人間が容易に認識できるもので、画像や音声クリップに追加されますが、簡単に削除や偽造が可能です。一方、不可視ウォーターマークは人間には知覚できない微細なパターンを埋め込むもので、専用のアルゴリズムでのみ検出可能です。そのため、改ざんや除去に対してはるかに強固であり、コンテンツの品質を保ちながら認証強度を高めるため、AIコンテンツの認証には不可視ウォーターマークが一般的に好まれます。
テキスト用の統計的ウォーターマークは、生成時に言語モデルのトークン選択を微妙に制御します。モデル開発者が暗号方式を使って「サイコロを仕込む」ことで、特定の「グリーントークン」を優先し「レッドトークン」を避けるようにします。検出アルゴリズムは生成されたテキストを解析し、特定トークンが統計的に異常な頻度で現れるかどうかを判断し、ウォーターマークの有無を特定します。この手法はテキスト品質を維持しつつ、検出可能な指紋を埋め込むことができます。
主な課題は、軽微な編集や変換によるウォーターマークの除去が容易であること、異なるAIモデル間で普遍的な検出ができないこと、またテキストへのウォーターマークが画像や音声より困難であることです。さらに、ウォーターマークはAIモデル開発者の協力が必要であり、オープンソースモデルでは非対応、また慎重に実装しないとコンテンツ品質が低下する可能性があります。検出時の誤検出や見逃しも重大な技術的課題です。
2024年3月に正式採択されたEU AI法は、AIシステム提供者に対し、出力結果をAI生成コンテンツとしてマーキングすることを求めています。カリフォルニア州AI透明化法(SB 942)は2026年1月1日より施行され、対象AI提供者に無料のパブリック検出ツールの提供を義務付けます。また、米国国防認可法(NDAA)2024年度版には、ウォーターマーク技術の評価とコンテンツ出所の業界標準策定に関する規定が含まれています。
ウォーターマークは識別パターンをAI生成コンテンツ自体に直接埋め込み、コンテンツがコピーや改変されても残る恒久的なデジタル指紋を作ります。一方、C2PA標準などのコンテンツ出所証明は、コンテンツの由来や改変履歴をファイルのメタデータとして別途管理します。ウォーターマークは回避に強いですがモデル開発者の協力が必要、出所証明は実装が容易ですがメタデータが失われると無効になります。
SynthIDはGoogle DeepMindのテクノロジーで、画像・音声・テキスト・動画に直接デジタルウォーターマークを埋め込むことでAI生成物を識別します。テキストの場合、SynthIDはロジットプロセッサを使い、モデルの生成パイプラインを拡張してウォーターマーク情報を品質を損なわずにエンコードします。埋め込みと検出の両方に機械学習モデルを用いることで、一般的な攻撃にも強く、コンテンツの忠実度を維持します。
はい、意図的な攻撃者であればテキストの言い換えや画像のトリミング・フィルタリング、言語翻訳など様々な手法でウォーターマークを回避・除去できます。ただし、高度なウォーターマークの除去には技術的知識や方式の理解が必要です。統計的ウォーターマークは従来手法より強固ですが、最先端のウォーターマークにも概念実証レベルの攻撃が報告されており、万能な手法は存在しません。
ChatGPT、Perplexity、その他のプラットフォームでAIチャットボットがブランドを言及する方法を追跡します。AI存在感を向上させるための実用的なインサイトを取得します。
AIシステムが著作権保護されたコンテンツをどのように利用するかを規定するAIコンテンツライセンス契約について学びましょう。ライセンスの種類、主要な構成要素、プラットフォーム、クリエイター向けベストプラクティスを解説します。...

AIコンテンツ検出とは何か、検出ツールが機械学習や自然言語処理を使用してどのように機能するのか、ブランドモニタリング・教育・コンテンツの信頼性検証になぜ重要なのかを学びましょう。...
AIコンテンツ生成とは何か、どのように機能するか、その利点と課題、AIプラットフォームの可視性に最適化されたマーケティングコンテンツを作成するためのAIツールのベストプラクティスを学びましょう。...
クッキーの同意
閲覧体験を向上させ、トラフィックを分析するためにクッキーを使用します。 See our privacy policy.