Welke AI-crawlers moet ik toegang geven? Complete gids voor 2025
Ontdek welke AI-crawlers je moet toestaan of blokkeren in je robots.txt. Uitgebreide gids over GPTBot, ClaudeBot, PerplexityBot en 25+ AI-crawlers met configura...
10 min lezen

Compleet naslagwerk over AI crawlers en bots. Identificeer GPTBot, ClaudeBot, Google-Extended en meer dan 20 andere AI-crawlers met user agents, crawl rates en blokkeringsstrategieën.
AI-crawlers verschillen fundamenteel van de traditionele zoekmachine-crawlers die je al decennia kent. Waar Googlebot en Bingbot content indexeren om gebruikers via zoekresultaten te helpen informatie te vinden, verzamelen AI-crawlers zoals GPTBot en ClaudeBot data specifiek om grote taalmodellen te trainen. Dit onderscheid is cruciaal: traditionele crawlers creëren routes voor menselijke ontdekking, terwijl AI-crawlers de kennisbanken van kunstmatige intelligentiesystemen voeden. Volgens recente gegevens is bijna 80% van al het botverkeer naar websites nu afkomstig van AI-crawlers, waarbij trainingscrawlers enorme hoeveelheden content opnemen terwijl ze nauwelijks verkeer terugsturen naar uitgevers. In tegenstelling tot traditionele crawlers die moeite hebben met dynamische JavaScript-rijke sites, gebruiken AI-crawlers geavanceerde machine learning om content contextueel te begrijpen, bijna zoals een menselijke lezer. Ze kunnen betekenis, toon en doel interpreteren zonder handmatige configuratie-updates. Dit is een sprong voorwaarts in webindexeringstechnologie die website-eigenaren ertoe aanzet hun crawlerbeheer volledig te herzien.
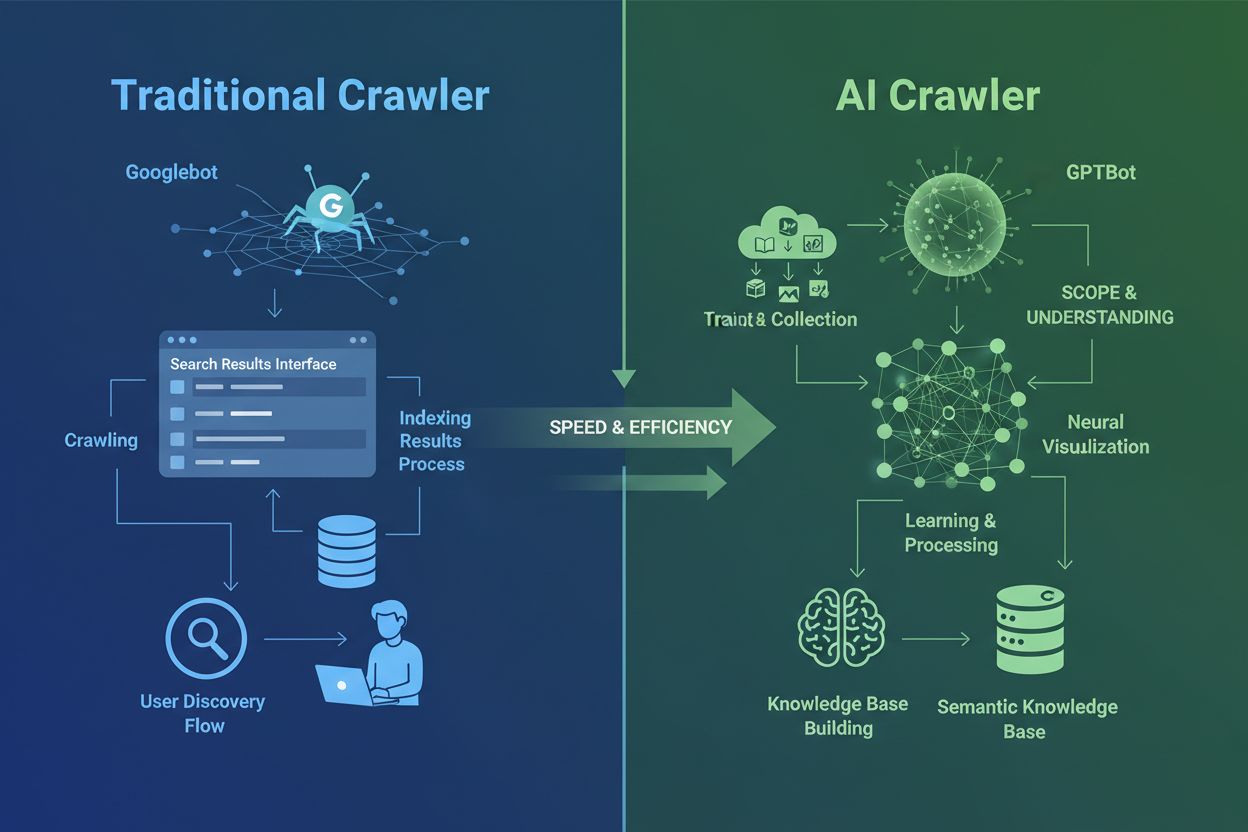
Het landschap van AI-crawlers is steeds drukker geworden nu grote technologiebedrijven hun eigen grote taalmodellen willen bouwen. OpenAI, Anthropic, Google, Meta, Amazon, Apple en Perplexity exploiteren elk meerdere gespecialiseerde crawlers, elk met hun eigen functies binnen hun respectievelijke AI-ecosystemen. Bedrijven gebruiken meerdere crawlers omdat verschillende doeleinden ander gedrag vereisen: sommige crawlers richten zich op grootschalige dataverzameling voor training, andere verzorgen realtime zoekindexering, en weer andere halen content op aanvraag als gebruikers erom vragen. Dit ecosysteem begrijpen vraagt inzicht in drie hoofdcrawlercategorieën: trainingscrawlers die data verzamelen voor modelverbetering, zoek- en citaatcrawlers die content indexeren voor AI-gestuurde zoekervaringen, en door gebruikers getriggerde fetchers die geactiveerd worden als iemand via een AI-assistent specifiek om content vraagt. De volgende tabel geeft een snel overzicht van de belangrijkste spelers:
| Bedrijf | Crawlernaam | Primair Doel | Crawl Rate | Trainingsdata |
|---|---|---|---|---|
| OpenAI | GPTBot | Modeltraining | 100 pagina’s/uur | Ja |
| OpenAI | ChatGPT-User | Realtime gebruikersverzoeken | 2400 pagina’s/uur | Nee |
| OpenAI | OAI-SearchBot | Zoekindexering | 150 pagina’s/uur | Nee |
| Anthropic | ClaudeBot | Modeltraining | 500 pagina’s/uur | Ja |
| Anthropic | Claude-User | Realtime webtoegang | <10 pagina’s/uur | Nee |
| Google-Extended | Gemini AI-training | Variabel | Ja | |
| Gemini-Deep-Research | Onderzoeksfunctie | <10 pagina’s/uur | Nee | |
| Meta | Meta-ExternalAgent | AI-modeltraining | 1100 pagina’s/uur | Ja |
| Amazon | Amazonbot | Serviceverbetering | 1050 pagina’s/uur | Ja |
| Perplexity | PerplexityBot | Zoekindexering | 150 pagina’s/uur | Nee |
| Apple | Applebot-Extended | AI-training | <10 pagina’s/uur | Ja |
| Common Crawl | CCBot | Open dataset | <10 pagina’s/uur | Ja |
OpenAI beheert drie verschillende crawlers, elk met hun eigen rol binnen het ChatGPT-ecosysteem. Deze crawlers begrijpen is essentieel omdat OpenAI’s GPTBot een van de meest agressieve en wijdverspreide AI-crawlers op het internet is:
GPTBot – OpenAI’s primaire trainingscrawler die systematisch openbare data verzamelt om GPT-modellen, waaronder ChatGPT en GPT-4o, te trainen en te verbeteren. Deze crawler werkt met ongeveer 100 pagina’s per uur en respecteert robots.txt-richtlijnen. OpenAI publiceert officiële IP-adressen op https://openai.com/gptbot.json ter verificatie.
ChatGPT-User – Deze crawler verschijnt wanneer een echte gebruiker ChatGPT gebruikt en het vraagt om een specifieke webpagina te bezoeken. Hij opereert met veel hogere snelheden (tot 2400 pagina’s/uur) omdat hij door gebruikersacties wordt getriggerd in plaats van systematische crawling. Content die via ChatGPT-User wordt benaderd wordt niet gebruikt voor modeltraining, waardoor deze waardevol is voor realtime zichtbaarheid in ChatGPT-zoekresultaten.
OAI-SearchBot – Speciaal ontworpen voor ChatGPT’s zoekfunctionaliteit, indexeert deze crawler content voor realtime zoekresultaten zonder trainingsdata te verzamelen. Hij werkt met ongeveer 150 pagina’s per uur en helpt je content verschijnen in ChatGPT-zoekresultaten wanneer gebruikers relevante vragen stellen.
De crawlers van OpenAI respecteren robots.txt-richtlijnen en werken vanaf geverifieerde IP-ranges, waardoor ze relatief eenvoudig te beheren zijn in vergelijking met minder transparante concurrenten.
Anthropic, het bedrijf achter Claude AI, beheert meerdere crawlers met verschillende doelen en mate van transparantie. Het bedrijf is minder open in documentatie dan OpenAI, maar hun crawlergedrag is goed gedocumenteerd via serverlog-analyse:
ClaudeBot – De belangrijkste trainingscrawler van Anthropic die webcontent verzamelt om de kennisbasis en mogelijkheden van Claude te verbeteren. Deze crawler werkt met ongeveer 500 pagina’s per uur en is de belangrijkste om te blokkeren als je niet wilt dat je content voor Claude’s modeltraining wordt gebruikt. De volledige user agent-string is Mozilla/5.0 AppleWebKit/537.36 (KHTML, like Gecko; compatible; ClaudeBot/1.0; +claudebot@anthropic.com).
Claude-User – Geactiveerd wanneer Claude-gebruikers realtime webtoegang aanvragen; deze crawler haalt content on-demand op met minimale volumes. Hij respecteert authenticatie en probeert geen toegangsbeperkingen te omzeilen, waardoor hij relatief onschuldig is qua belasting.
Claude-SearchBot – Ondersteunt de interne zoekmogelijkheden van Claude, helpt je content te verschijnen in Claude’s zoekresultaten als gebruikers vragen stellen. Deze crawler werkt op zeer lage volumes en dient vooral indexeringsdoeleinden in plaats van training.
Een belangrijk aandachtspunt bij Anthropics crawlers is de crawl-to-refer ratio: Cloudflare-data geeft aan dat voor elke verwijzing die Anthropic naar een website stuurt, hun crawlers al ongeveer 38.000 tot 70.000 pagina’s hebben bezocht. Deze enorme disbalans betekent dat je content veel agressiever wordt gebruikt dan het wordt vermeld, wat vragen oproept over eerlijke compensatie voor contentgebruik.
Google pakt AI-crawling heel anders aan dan concurrenten, omdat het bedrijf een strikte scheiding aanhoudt tussen zoekindexering en AI-training. Google-Extended is de specifieke crawler die data verzamelt om Gemini (voorheen Bard) en andere Google AI-producten te trainen, volledig los van de traditionele Googlebot:
De user agent-string voor Google-Extended is: Mozilla/5.0 AppleWebKit/537.36 (KHTML, like Gecko; compatible; Google-Extended/1.0. Deze scheiding is bewust en gunstig voor website-eigenaren omdat je Google-Extended via robots.txt kunt blokkeren zonder je zichtbaarheid in Google Zoeken te beïnvloeden. Google stelt officieel dat het blokkeren van Google-Extended geen effect heeft op zoekposities of opname in AI Overviews, hoewel sommige webmasters hierover zorgen melden die het waard zijn om in de gaten te houden. Gemini-Deep-Research is een andere Google-crawler die Gemini’s onderzoeksfunctie ondersteunt, werkt op zeer lage volumes en heeft minimale impact op serverresources. Een groot technisch voordeel van Google’s crawlers is hun vermogen om JavaScript uit te voeren en dynamische content te renderen, in tegenstelling tot de meeste concurrenten. Dit betekent dat Google-Extended effectief React-, Vue- en Angular-applicaties kan crawlen, terwijl OpenAI’s GPTBot en Anthropics ClaudeBot dat niet kunnen. Voor website-eigenaren met JavaScript-rijke toepassingen is dit onderscheid erg belangrijk voor AI-zichtbaarheid.
Naast de techreuzen zijn er talloze andere organisaties die AI-crawlers exploiteren die aandacht verdienen. Meta-ExternalAgent, stilletjes gelanceerd in juli 2024, scrapt webcontent voor de training van Meta’s AI-modellen en productverbetering op Facebook, Instagram en WhatsApp. Deze crawler werkt met circa 1100 pagina’s per uur en heeft, ondanks zijn agressieve gedrag, minder publieke aandacht gekregen dan concurrenten. Bytespider, in beheer van ByteDance (het moederbedrijf van TikTok), is sinds de lancering in april 2024 een van de agressiefste crawlers online. Externe monitoring suggereert dat Bytespider veel agressiever crawlt dan GPTBot of ClaudeBot, al variëren de exacte verhoudingen. Sommige rapporten geven aan dat hij robots.txt niet altijd respecteert, waardoor IP-gebaseerde blokkering betrouwbaarder is.
De crawlers van Perplexity omvatten PerplexityBot voor zoekindexering en Perplexity-User voor realtime content ophalen. Perplexity krijgt incidentele meldingen van het negeren van robots.txt, hoewel het bedrijf zelf naleving claimt. Amazonbot voedt Alexa’s vraag-en-antwoordcapaciteiten, respecteert robots.txt en werkt met circa 1050 pagina’s per uur. Applebot-Extended, geïntroduceerd in juni 2024, bepaalt hoe reeds door Applebot geïndexeerde content wordt gebruikt voor AI-training van Apple, maar crawlt niet direct webpagina’s. CCBot, in beheer van Common Crawl (een non-profit), bouwt open webarchieven die door meerdere AI-bedrijven, waaronder OpenAI, Google, Meta en Hugging Face worden gebruikt. Nieuwe crawlers van bedrijven zoals xAI (Grok), Mistral, en DeepSeek duiken op in serverlogs en geven de voortdurende uitbreiding van het AI-crawlerlandschap weer.
Hieronder een uitgebreide referentietabel van geverifieerde AI-crawlers, hun doel, user agent-strings en robots.txt-blokkeringssyntax. Deze tabel wordt regelmatig bijgewerkt op basis van serverlog-analyse en officiële documentatie. Elke vermelding is geverifieerd met officiële IP-lijsten waar mogelijk:
| Crawlernaam | Bedrijf | Doel | User Agent | Crawl Rate | IP Verificatie | Robots.txt Syntax |
|---|---|---|---|---|---|---|
| GPTBot | OpenAI | Trainingsdataverzameling | Mozilla/5.0 AppleWebKit/537.36 (KHTML, like Gecko; compatible; GPTBot/1.3; +https://openai.com/gptbot) | 100/u | ✓ Officieel | User-agent: GPTBot Disallow: / |
| ChatGPT-User | OpenAI | Realtime gebruikersverzoeken | Mozilla/5.0 AppleWebKit/537.36 (KHTML, like Gecko); compatible; ChatGPT-User/1.0 | 2400/u | ✓ Officieel | User-agent: ChatGPT-User Disallow: / |
| OAI-SearchBot | OpenAI | Zoekindexering | Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36; compatible; OAI-SearchBot/1.3 | 150/u | ✓ Officieel | User-agent: OAI-SearchBot Disallow: / |
| ClaudeBot | Anthropic | Trainingsdataverzameling | Mozilla/5.0 AppleWebKit/537.36 (KHTML, like Gecko; compatible; ClaudeBot/1.0; +claudebot@anthropic.com) | 500/u | ✓ Officieel | User-agent: ClaudeBot Disallow: / |
| Claude-User | Anthropic | Realtime webtoegang | Mozilla/5.0 AppleWebKit/537.36 (KHTML, like Gecko; compatible; Claude-User/1.0) | <10/u | ✗ Niet beschikbaar | User-agent: Claude-User Disallow: / |
| Claude-SearchBot | Anthropic | Zoekindexering | Mozilla/5.0 AppleWebKit/537.36 (KHTML, like Gecko; compatible; Claude-SearchBot/1.0) | <10/u | ✗ Niet beschikbaar | User-agent: Claude-SearchBot Disallow: / |
| Google-Extended | Gemini AI-training | Mozilla/5.0 AppleWebKit/537.36 (KHTML, like Gecko; compatible; Google-Extended/1.0) | Variabel | ✓ Officieel | User-agent: Google-Extended Disallow: / | |
| Gemini-Deep-Research | Onderzoeksfunctie | Mozilla/5.0 AppleWebKit/537.36 (KHTML, like Gecko; compatible; Gemini-Deep-Research) | <10/u | ✓ Officieel | User-agent: Gemini-Deep-Research Disallow: / | |
| Bingbot | Microsoft | Bing zoeken & Copilot | Mozilla/5.0 AppleWebKit/537.36 (KHTML, like Gecko; compatible; bingbot/2.0) | 1300/u | ✓ Officieel | User-agent: Bingbot Disallow: / |
| Meta-ExternalAgent | Meta | AI-modeltraining | meta-externalagent/1.1 (+https://developers.facebook.com/docs/sharing/webmasters/crawler) | 1100/u | ✗ Niet beschikbaar | User-agent: Meta-ExternalAgent Disallow: / |
| Amazonbot | Amazon | Serviceverbetering | Mozilla/5.0 AppleWebKit/537.36 (KHTML, like Gecko; compatible; Amazonbot/0.1) | 1050/u | ✓ Officieel | User-agent: Amazonbot Disallow: / |
| Applebot-Extended | Apple | AI-training | Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/605.1.15; compatible; Applebot-Extended | <10/u | ✓ Officieel | User-agent: Applebot-Extended Disallow: / |
| PerplexityBot | Perplexity | Zoekindexering | Mozilla/5.0 AppleWebKit/537.36 (KHTML, like Gecko; compatible; PerplexityBot/1.0) | 150/u | ✓ Officieel | User-agent: PerplexityBot Disallow: / |
| Perplexity-User | Perplexity | Realtime ophalen | Mozilla/5.0 AppleWebKit/537.36 (KHTML, like Gecko; compatible; Perplexity-User/1.0) | <10/u | ✓ Officieel | User-agent: Perplexity-User Disallow: / |
| Bytespider | ByteDance | AI-training | Mozilla/5.0 (Linux; Android 5.0) AppleWebKit/537.36; compatible; Bytespider | <10/u | ✗ Niet beschikbaar | User-agent: Bytespider Disallow: / |
| CCBot | Common Crawl | Open dataset | CCBot/2.0 (https://commoncrawl.org/faq/ ) | <10/u | ✓ Officieel | User-agent: CCBot Disallow: / |
| DuckAssistBot | DuckDuckGo | AI-zoekopdrachten | DuckAssistBot/1.2; (+http://duckduckgo.com/duckassistbot.html) | 20/u | ✓ Officieel | User-agent: DuckAssistBot Disallow: / |
| Diffbot | Diffbot | Data-extractie | Mozilla/5.0 (Windows; U; Windows NT 5.1; en-US; rv:1.9.1.2) Gecko/20090729 Firefox/3.5.2 Diffbot/0.1 | <10/u | ✗ Niet beschikbaar | User-agent: Diffbot Disallow: / |
| MistralAI-User | Mistral | Realtime ophalen | Mozilla/5.0 AppleWebKit/537.36 (KHTML, like Gecko; compatible; MistralAI-User/1.0) | <10/u | ✗ Niet beschikbaar | User-agent: MistralAI-User Disallow: / |
| ICC-Crawler | NICT | AI/ML-training | ICC-Crawler/3.0 (Mozilla-compatible; https://ucri.nict.go.jp/en/icccrawler.html ) | <10/u | ✗ Niet beschikbaar | User-agent: ICC-Crawler Disallow: / |
Niet alle AI-crawlers dienen hetzelfde doel en deze verschillen begrijpen is essentieel voor weloverwogen blokkeerlbeslissingen. Trainingscrawlers zijn goed voor ongeveer 80% van al het AI-botverkeer en verzamelen content specifiek voor trainingsdatasets van grote taalmodellen. Zodra je content in zo’n trainingsdataset komt, wordt het onderdeel van de permanente kennisbasis van het model, wat de noodzaak voor gebruikers kan verminderen om je site te bezoeken voor antwoorden. Trainingscrawlers zoals GPTBot, ClaudeBot en Meta-ExternalAgent werken in hoge volumes en met systematische patronen, terwijl ze minimaal tot geen verkeer terugsturen naar uitgevers.
Zoek- en citaatcrawlers indexeren content voor AI-gestuurde zoekervaringen en kunnen daadwerkelijk verkeer aanleveren via citaties. Als gebruikers vragen stellen in ChatGPT of Perplexity, helpen deze crawlers relevante bronnen naar voren te halen. In tegenstelling tot trainingscrawlers werken zoekcrawlers zoals OAI-SearchBot en PerplexityBot met een gematigd volume en retrievalgericht gedrag en bevatten ze soms bronvermelding en links. Door gebruikers getriggerde fetchers worden alleen actief als gebruikers via AI-assistenten specifiek om content vragen. Als iemand een URL plakt in ChatGPT of Perplexity vraagt om een bepaalde pagina te analyseren, halen deze fetchers de content on-demand op. User-triggered fetchers werken op zeer laag volume met incidentele verzoeken in plaats van geautomatiseerde systematische crawling, en de meeste AI-bedrijven bevestigen dat deze niet voor modeltraining worden gebruikt. Deze categorieën begrijpen helpt je strategisch beslissen welke crawlers je toestaat en welke je blokkeert, passend bij je bedrijfsprioriteiten.
De eerste stap in het beheren van AI-crawlers is weten welke je website daadwerkelijk bezoeken. Je servertoeganglogs bevatten gedetailleerde gegevens van elke aanvraag, inclusief de user agent-string die de crawler identificeert. De meeste hosting control panels bieden log-analysetools, maar je kunt ook direct de ruwe logs raadplegen. Voor Apache-servers vind je logs meestal in /var/log/apache2/access.log, terwijl Nginx-logs vaak in /var/log/nginx/access.log staan. Je kunt deze logs filteren met grep om crawleractiviteit te vinden:
grep -i "gptbot\|claudebot\|google-extended\|bytespider" /var/log/apache2/access.log | head -20
Dit commando toont de 20 meest recente verzoeken van grote AI-crawlers. Google Search Console biedt crawlerstatistieken voor Google’s bots, al toont het alleen Google’s crawlers. Cloudflare Radar geeft globale inzichten in AI-botverkeer en helpt vaststellen welke crawlers het meest actief zijn. Om te controleren of een crawler legitiem is of gespoofd, check je het request-IP-adres met officiële IP-lijsten van grote bedrijven. OpenAI publiceert geverifieerde IP’s op https://openai.com/gptbot.json, Amazon op https://developer.amazon.com/amazonbot/ip-addresses/, en anderen houden vergelijkbare lijsten bij. Een nep-crawler die een legitieme user agent nabootst vanaf een niet-geverifieerd IP-adres moet je direct blokkeren, aangezien dit waarschijnlijk op kwaadaardig scrapen duidt.
Het robots.txt-bestand is je belangrijkste hulpmiddel om crawler-toegang te beheren. Dit eenvoudige tekstbestand, geplaatst in de root van je website, vertelt crawlers welke delen van je site ze mogen bezoeken. Om specifieke AI-crawlers te blokkeren, voeg je regels toe als:
# Blokkeer OpenAI's GPTBot
User-agent: GPTBot
Disallow: /
# Blokkeer Anthropics ClaudeBot
User-agent: ClaudeBot
Disallow: /
# Blokkeer Google's AI-training (niet zoeken)
User-agent: Google-Extended
Disallow: /
# Blokkeer Common Crawl
User-agent: CCBot
Disallow: /
Je kunt crawlers ook toestaan, maar met een crawl-delay om serveroverbelasting te voorkomen:
User-agent: GPTBot
Crawl-delay: 10
Disallow: /private/
Dit vertelt GPTBot om 10 seconden te wachten tussen aanvragen en uit je privé-map te blijven. Voor een gebalanceerde aanpak die zoekcrawlers toestaat en trainingscrawlers blokkeert:
# Sta traditionele zoekmachines toe
User-agent: Googlebot
Allow: /
User-agent: Bingbot
Allow: /
# Blokkeer alle AI-trainingscrawlers
User-agent: GPTBot
User-agent: ClaudeBot
User-agent: CCBot
User-agent: Google-Extended
User-agent: Bytespider
User-agent: Meta-ExternalAgent
Disallow: /
# Sta AI-zoekcrawlers toe
User-agent: OAI-SearchBot
Allow: /
User-agent: PerplexityBot
Allow: /
De meeste betrouwbare AI-crawlers respecteren robots.txt, al negeren sommige agressieve crawlers hem volledig. Daarom is robots.txt alleen niet voldoende voor volledige bescherming.
Robots.txt is adviserend en niet afdwingbaar, wat betekent dat crawlers je instructies kunnen negeren als ze dat willen. Voor sterkere bescherming tegen crawlers die robots.txt negeren, implementeer je IP-gebaseerde blokkering op serverniveau. Dit is betrouwbaarder, omdat een IP-adres moeilijker te spoofen is dan een user agent-string. Je kunt geverifieerde IP’s van officiële bronnen toelaten en alle andere verzoeken die zich voordoen als AI-crawler blokkeren.
Voor Apache-servers kun je .htaccess-regels gebruiken om crawlers op serverniveau te blokkeren:
<IfModule mod_rewrite.c>
RewriteEngine On
RewriteCond %{HTTP_USER_AGENT} (GPTBot|ClaudeBot|anthropic-ai|Bytespider|CCBot) [NC]
RewriteRule .* - [F,L]
</IfModule>
Dit geeft een 403 Forbidden-respons aan overeenkomende user agents, ongeacht robots.txt. Firewallregels bieden een extra laag door geverifieerde IP-ranges van officiële bronnen toe te laten. De meeste webapplicatiefirewalls en hostingproviders laten je regels instellen die verzoeken van geverifieerde IP’s toestaan en andere blokkeren. HTML-meta-tags bieden gedetailleerde controle op paginaniveau. Amazon en sommige andere crawlers respecteren de noarchive-directive:
<meta name="robots" content="noarchive">
Dit vertelt crawlers de pagina niet te gebruiken voor modeltraining, terwijl andere indexering mogelijk wel wordt toegestaan. Kies je blokkeringsmethode op basis van je technische mogelijkheden en de crawlers die je wilt blokkeren. IP-gebaseerde blokkering is het betrouwbaarst maar vraagt meer technische kennis; robots.txt is het makkelijkst maar minder effectief tegen niet-nalevende crawlers.
Blokkades instellen is slechts de helft van het verhaal; je moet ook controleren of ze werken. Regelmatige monitoring helpt om problemen vroeg te signaleren en nieuwe crawlers te ontdekken. Controleer je serverlogs wekelijks op ongewoon botverkeer, let op user agent-strings met “bot”, “crawler”, “spider” of bedrijfsnamen als “GPT”, “Claude” of “Perplexity.” Stel meldingen in bij plotselinge stijgingen in botverkeer die kunnen wijzen op nieuwe of agressieve crawlers. Google Search Console toont crawlstatistieken voor Google’s bots, waarmee je Googlebot en Google-Extended activiteit kunt monitoren. Cloudflare Radar geeft wereldwijde inzichten in AI-crawlerverkeer en helpt nieuwe crawlers op te sporen.
Om te controleren of je robots.txt-blokkades werken, open je het robots.txt-bestand direct op jouwsite.com/robots.txt en kijk je of alle user agents en instructies correct zijn. Voor serverniveau-blokkades check je je toeganglogs op verzoeken van geblokkeerde crawlers. Zie je toch verzoeken van geblokkeerde crawlers, dan negeren zij je instructies of spoofen ze hun user agent. Test je implementatie door crawlertoegang te controleren in je analytics en serverlogs. Kwartaalreviews zijn essentieel omdat het AI-crawlerlandschap snel verandert. Nieuwe crawlers verschijnen regelmatig, bestaande crawlers wijzigen hun user agents, en bedrijven introduceren nieuwe bots zonder aankondiging. Plan regelmatige reviews van je blocklist om aanvullingen te signaleren en je implementatie actueel te houden.
Naast het beheren van crawler-toegang is het minstens zo belangrijk om te weten hoe AI-systemen je content daadwerkelijk citeren en vermelden. AmICited.com biedt uitgebreide monitoring van hoe je merk en content verschijnen in AI-gegenereerde antwoorden op ChatGPT, Perplexity, Google Gemini en andere AI-platforms. In plaats van alleen maar crawlers te blokkeren, helpt AmICited.com je het échte effect van AI-crawlers op je zichtbaarheid en autoriteit te begrijpen. Het platform volgt welke AI-systemen je content aanhalen, hoe vaak je merk in AI-antwoorden verschijnt en hoe deze zichtbaarheid zich vertaalt naar verkeer en autoriteit. Door je AI-citaties te monitoren, kun je onderbouwde keuzes maken over welke crawlers je toestaat op basis van daadwerkelijke zichtbaarheid en niet alleen aannames. AmICited.com sluit aan op je totale contentstrategie en laat zien welke onderwerpen en contenttypen de meeste AI-citaties opleveren. Deze datagedreven aanpak helpt je je content te optimaliseren voor AI-ontdekking en beschermt tegelijkertijd je waardevolle intellectuele eigendom. Inzicht in je AI-citatiemetrics stelt je in staat strategische beslissingen te nemen over crawler-toegang die passen bij je bedrijfsdoelen.
Beslissen of je AI-crawlers toestaat of blokkeert hangt volledig af van je specifieke zakelijke situatie en prioriteiten. Sta AI-crawlers toe als: je een nieuwssite of blog runt waar zichtbaarheid in AI-antwoorden veel verkeer oplevert, je bedrijf baat heeft bij het genoemd worden als bron in AI-gegenereerde antwoorden, je wilt meedoen aan AI-training om invloed uit te oefenen op hoe modellen jouw sector begrijpen, of je het goed vindt dat je content wordt gebruikt voor AI-ontwikkeling. Nieuwssites, educatieve contentmakers en thought leaders profiteren vaak van AI-zichtbaarheid omdat citaties verkeer en autoriteit opleveren.
Blokkeer AI-crawlers als: je over eigen content of bedrijfsgeheimen beschikt die je wilt beschermen, je serverresources beperkt zijn en geen agressieve crawling aankunnen, je je zorgen maakt over contentgebruik zonder vergoeding, je regie wilt houden over het gebruik van je intellectuele eigendom, of je performanceproblemen hebt gehad door botverkeer. E-commercesites met productinformatie, SaaS-bedrijven met eigen documentatie en uitgevers met betaalde content kiezen vaak voor het blokkeren van trainingscrawlers. De belangrijkste afweging is tussen contentbescherming en zichtbaarheid op AI-gestuurde ontdekplatformen. Het blokkeren van trainingscrawlers beschermt je content maar kan je zichtbaarheid in AI-antwoorden verminderen. Het blokkeren van zoekcrawlers kan je zichtbaarheid in AI-zoekresultaten verkleinen. Veel uitgevers kiezen voor selectief blokkeren: zoek- en citaatcrawlers zoals OAI-SearchBot en PerplexityBot toestaan, maar agressieve trainingscrawlers zoals GPTBot en ClaudeBot blokkeren. Zo balanceer je zichtbaarheid in AI-zoekresultaten met bescherming tegen onbeperkte dataverzameling. Je keuze moet passen bij je businessmodel, contentstrategie en beschikbare resources.
Het AI-crawlerlandschap blijft snel groeien nu nieuwe bedrijven toetreden en bestaande spelers extra bots lanceren. xAI’s Grok-crawler is opgedoken in serverlogs nu het bedrijf zijn AI-platform opschaalt. Mistral’s MistralAI-User crawler ondersteunt realtime content ophalen voor de Mistral AI-assistent. DeepSeek’s DeepSeekBot vertegenwoordigt opkomende concurrentie van Chinese AI-bedrijven. Browsergebaseerde AI-agenten zoals OpenAI’s Operator en vergelijkbare producten vormen een nieuwe uitdaging: ze gebruiken geen herkenbare user agents en verschijnen als normale Chrome-verkeer, waardoor traditionele blokkering onmogelijk is. Deze agentic browsers zijn de volgende stap in de evolutie van AI-crawlers, omdat ze kunnen interacteren met websites als menselijke gebruikers, inclusief het uitvoeren van JavaScript en navigeren door complexe interfaces.
De toekomst van AI-crawlers zal waarschijnlijk meer verfijning, gedetailleerdere beheermechanismen en mogelijk nieuwe standaarden brengen voor het beheren van AI-toegang tot content. Blijf op de hoogte van opkomende crawlers, want nieuwe bots verschijnen continu en bestaande crawlers veranderen hun gedrag. Houd branchebronnen in de gaten zoals het ai.robots.txt-project op GitHub , dat een community-onderhouden lijst van bekende AI-crawlers bijhoudt. Controleer je serverlogs regelmatig op onbekende user agent-strings. Abonneer je op updates van grote AI-bedrijven over hun crawlergedrag en IP-ranges. Het AI-crawlerlandschap blijft zich ontwikkelen en jouw crawlerstrategie moet meeveranderen. Regelmatige monitoring, kwartaalreviews en op de hoogte blijven van brancheontwikkelingen zorgen ervoor dat je de regie houdt over hoe AI-systemen toegang krijgen tot en gebruikmaken van jouw content.
AI-crawlers zoals GPTBot en ClaudeBot verzamelen content specifiek om grote taalmodellen te trainen, terwijl zoekmachine-crawlers zoals Googlebot content indexeren zodat mensen deze via zoekresultaten kunnen vinden. AI-crawlers voeden de kennisbanken van AI-systemen, terwijl zoek-crawlers gebruikers helpen om jouw content te ontdekken. Het belangrijkste verschil is het doel: trainen versus ophalen.
Nee, het blokkeren van AI-crawlers heeft geen negatieve invloed op je traditionele zoekresultaten. AI-crawlers zoals GPTBot en ClaudeBot staan volledig los van zoekmachine-crawlers zoals Googlebot. Je kunt Google-Extended (voor AI-training) blokkeren terwijl je Googlebot (voor zoeken) toestaat. Elke crawler heeft een ander doel en het blokkeren van de één heeft geen effect op de ander.
Bekijk je server toeganglogs om te zien welke user agents je site bezoeken. Zoek naar botnamen zoals GPTBot, ClaudeBot, CCBot en Bytespider in de user agent-strings. De meeste hosting control panels bieden log-analysetools. Je kunt ook Google Search Console gebruiken om crawl-activiteit te monitoren, al toont deze alleen Google's crawlers.
Niet alle AI-crawlers volgen robots.txt in gelijke mate. OpenAI's GPTBot, Anthropic's ClaudeBot en Google-Extended volgen over het algemeen robots.txt-regels. Bytespider en PerplexityBot hebben meldingen ontvangen dat zij robots.txt mogelijk niet consequent respecteren. Voor crawlers die robots.txt negeren, moet je IP-gebaseerde blokkering op serverniveau toepassen via je firewall of .htaccess-bestand.
Dit hangt af van je doelen. Blokkeer trainingscrawlers als je over eigen content beschikt of beperkte servercapaciteit hebt. Sta zoek-crawlers toe als je zichtbaar wilt zijn in AI-gestuurde zoekresultaten en chatbots, wat verkeer kan opleveren en je autoriteit kan vergroten. Veel bedrijven kiezen voor een selectieve aanpak door specifieke crawlers toe te staan en agressieve zoals Bytespider te blokkeren.
Nieuwe AI-crawlers verschijnen regelmatig, dus controleer en update je blocklist minimaal elk kwartaal. Houd bronnen bij zoals het ai.robots.txt-project op GitHub voor community-onderhouden lijsten. Check je serverlogs maandelijks om nieuwe crawlers te identificeren die niet in je huidige configuratie staan. Het AI-crawlerlandschap verandert snel en je strategie moet daarin meegroeien.
Ja, controleer het IP-adres van de aanvraag met officiële IP-lijsten van grote bedrijven. OpenAI publiceert geverifieerde IP's op https://openai.com/gptbot.json, Amazon op https://developer.amazon.com/amazonbot/ip-addresses/, en andere bedrijven houden vergelijkbare lijsten bij. Een crawler die een legitieme user agent nabootst vanaf een niet-geverifieerd IP-adres moet je direct blokkeren, want dit duidt waarschijnlijk op kwaadaardig scrapen.
AI-crawlers kunnen veel bandbreedte en serverresources verbruiken. Bytespider en Meta-ExternalAgent behoren tot de meest agressieve crawlers. Sommige uitgevers melden dat ze het bandbreedteverbruik van 800GB naar 200GB per dag hebben teruggebracht door AI-crawlers te blokkeren, wat ongeveer €1.500 per maand bespaart. Monitor je serverresources tijdens piek-crawltijden en voer indien nodig rate limiting in voor agressieve bots.
Volg welke AI-crawlers jouw content aanhalen en optimaliseer je zichtbaarheid op ChatGPT, Perplexity, Google Gemini en meer.
Ontdek welke AI-crawlers je moet toestaan of blokkeren in je robots.txt. Uitgebreide gids over GPTBot, ClaudeBot, PerplexityBot en 25+ AI-crawlers met configura...
Leer hoe je AI-bots zoals GPTBot, PerplexityBot en ClaudeBot toestaat om je site te crawlen. Configureer robots.txt, stel llms.txt in en optimaliseer voor AI-zi...
Ontdek hoe AI-zoekcrawlers de crawl-frequentie voor je website bepalen. Kom erachter hoe ChatGPT, Perplexity en andere AI-engines content anders crawlen dan Goo...