
Entiteitsherkenning
Entiteitsherkenning is een AI NLP-capaciteit voor het identificeren en categoriseren van benoemde entiteiten in tekst. Leer hoe het werkt, de toepassingen in AI...
9 min lezen

Ontdek hoe AI-systemen entiteiten in tekst herkennen en verwerken. Leer over NER-modellen, transformer-architecturen en praktijktoepassingen van entiteitsbegrip.
Entiteitsbegrip is uitgegroeid tot een essentiële vaardigheid in moderne kunstmatige intelligentiesystemen. Het stelt machines in staat de belangrijkste actoren, locaties en concepten in ongestructureerde tekst te identificeren en te begrijpen. Van zoekmachines die gebruikersintentie begrijpen tot chatbots die complexe vragen over specifieke personen en organisaties kunnen beantwoorden: entiteitsherkenning vormt de basis van zinvolle interactie tussen mens en computer. Deze technische mogelijkheid is cruciaal in verschillende sectoren—financiële instellingen gebruiken het voor nalevingsmonitoring, zorgsystemen benutten het voor patiëntendossiers, en e-commerceplatforms vertrouwen erop om productvermeldingen en klantfeedback te begrijpen. Begrijpen hoe AI-systemen entiteiten extraheren en interpreteren is essentieel voor iedereen die NLP-toepassingen bouwt of inzet in productieomgevingen.
Named Entity Recognition (NER) is de NLP-taak waarbij benoemde entiteiten—specifieke, betekenisvolle informatie-eenheden—worden geïdentificeerd en geclassificeerd in tekst binnen vooraf gedefinieerde categorieën. Deze entiteiten vertegenwoordigen de concrete onderwerpen die semantisch gewicht dragen in taal: mensen die handelingen verrichten, organisaties die beslissingen nemen, locaties waar gebeurtenissen plaatsvinden, tijdsaanduidingen die gebeurtenissen verankeren, geldwaarden die transacties kwantificeren, en producten die gekocht en verkocht worden. Entiteitsclassificatie is belangrijk omdat het ruwe tekst omzet in gestructureerde kennis waarover machines kunnen redeneren en handelen; zonder dit kan een systeem niet het verschil maken tussen “Apple het bedrijf” en “apple de vrucht”, of begrijpen dat “John Smith” en “J. Smith” naar dezelfde persoon verwijzen. Het vermogen om entiteiten nauwkeurig te classificeren stelt toepassingen als kennisgrafen, informatie-extractie, vraagbeantwoording en relatieherkenning in staat.
| Entiteitstype | Definitie | Voorbeeld |
|---|---|---|
| PERSOON | Individuele mensen | “Steve Jobs”, “Marie Curie” |
| ORGANISATIE | Bedrijven, instellingen, groepen | “Microsoft”, “Verenigde Naties”, “Harvard University” |
| LOCATIE | Geografische plaatsen en regio’s | “New York”, “Amazone”, “Silicon Valley” |
| DATUM | Tijdsaanduidingen en periodes | “15 januari 2024”, “volgende dinsdag”, “Q3 2023” |
| GELD | Geldwaarden en valuta | “$50 miljoen”, “€100”, “5000 yen” |
| PRODUCT | Goederen, diensten, creaties | “iPhone 15”, “Windows 11”, “ChatGPT” |
Moderne AI-systemen verwerken entiteiten via een geavanceerde meerstappenpijplijn die begint met tokenisatie—het opdelen van ruwe tekst in losse tokens die als basis dienen voor verdere verwerking. Elk token wordt vervolgens omgezet in een numerieke representatie via woordembeddings—dichte vectoren die semantische betekenis vastleggen—die gevoed worden aan neurale netwerkarchitecturen die context en relaties begrijpen. Transformer-gebaseerde modellen, tegenwoordig de standaard in NLP, verwerken hele reeksen parallel in plaats van sequentieel, waardoor ze lange-afstandsafhankelijkheden en complexe contextuele relaties kunnen vastleggen die cruciaal zijn voor nauwkeurig entiteitsbegrip. Het self-attention mechanisme binnen Transformers stelt elk token in staat het belang van ieder ander token in de reeks dynamisch te wegen, wat leidt tot rijke contextuele representaties waarbij de betekenis van een woord gevormd wordt door zijn omgeving; daarom wordt “bank” anders begrepen in “rivierbank” dan in “spaarbank”. Voorgetrainde taalmodellen zoals BERT en GPT leren algemene taalpatronen uit enorme tekstcorpora voordat ze worden bijgeschaafd op entiteitsherkenning, waardoor ze gebruik kunnen maken van aangeleerde kennis over syntaxis, semantiek en wereldkennis. De laatste laag van entiteitsherkenningssystemen gebruikt doorgaans een sequence labeling aanpak—vaak geïmplementeerd als een Conditional Random Field (CRF) of eenvoudige classificatielaag—die entiteitslabels aan elk token toewijst op basis van de geleerde contextuele representaties. Dankzij deze architectuur kunnen AI-systemen niet alleen vaststellen welke entiteiten aanwezig zijn, maar ook hoe ze zich tot elkaar verhouden en welke rol ze spelen in de bredere tekstcontext.
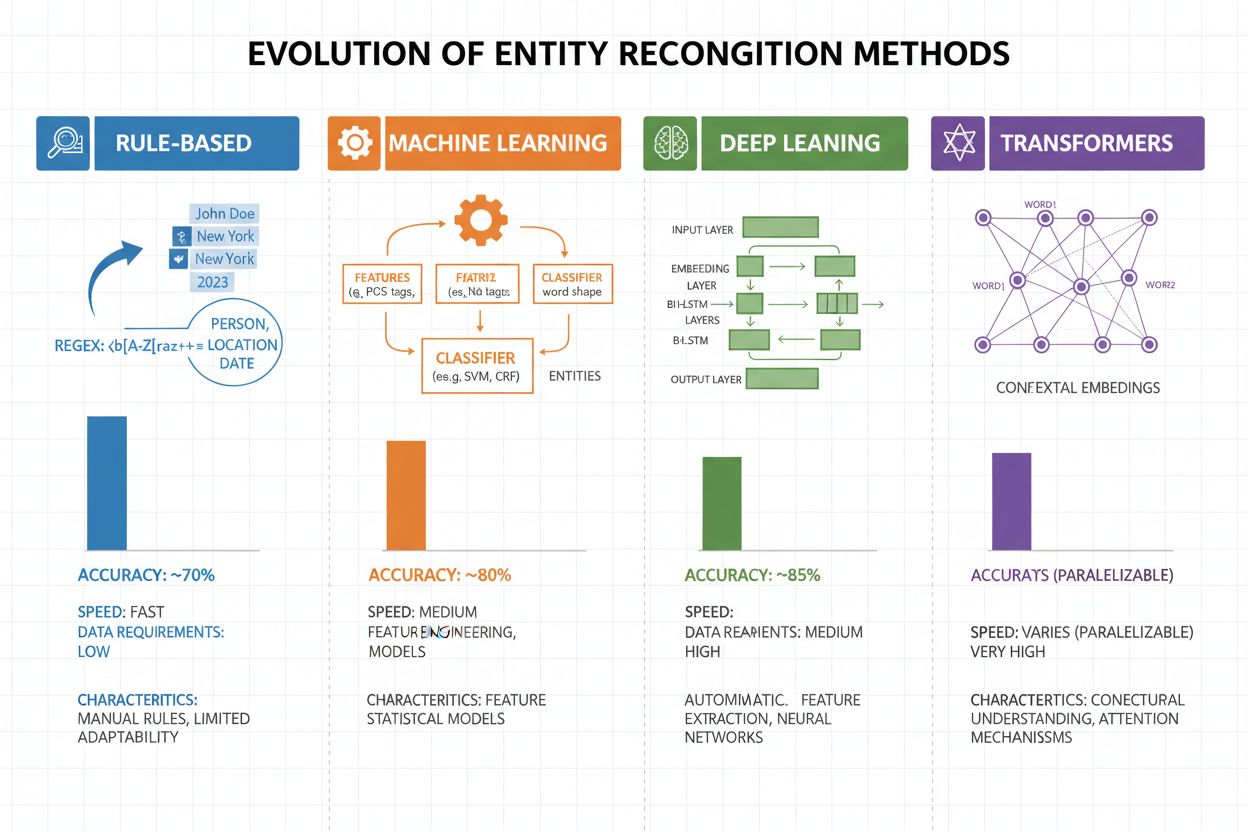
Entiteitsherkenning is in de afgelopen twee decennia sterk geëvolueerd, van eenvoudige regelgebaseerde benaderingen tot geavanceerde neurale architecturen. Vroege systemen vertrouwden op handgemaakte regels en woordenlijsten—middels reguliere expressies en patroonherkenning werden entiteiten geïdentificeerd. Deze methoden waren interpreteerbaar en hadden weinig trainingsdata nodig, maar generaliseerden slecht en waren onderhoudsintensief. Met de komst van machine learning ontstonden supervised benaderingen zoals Support Vector Machines (SVM) en Conditional Random Fields (CRF), die van gelabelde data leerden via feature engineering en de nauwkeurigheid aanzienlijk verbeterden, al moesten domeinexperts nog steeds betekenisvolle features ontwerpen. Deep learning-methoden, met name LSTMs en BiLSTMs, automatiseerden feature-extractie door direct uit ruwe tekst representaties te leren, met aanzienlijk hogere nauwkeurigheid als gevolg, maar vereisten grotere gelabelde datasets. Transformer-gebaseerde modellen zoals BERT en RoBERTa brachten een revolutie teweeg door self-attention te gebruiken om lange-afstandsafhankelijkheden en contextuele nuances te vatten, waarmee ze state-of-the-art resultaten behaalden (BERT haalde 90,9% F1 op CoNLL-2003) en transfer learning op grote schaal mogelijk maakten. De balans tussen complexiteit en nauwkeurigheid is hierdoor sterk verschoven: regelgebaseerde systemen zijn bruikbaar bij beperkte resources of in niche-domeinen, maar transformer-modellen domineren nu waar voldoende rekenkracht en gelabelde data beschikbaar zijn, met lichtere alternatieven als DistilBERT voor productieomgevingen met latency-eisen.
Transformer-gebaseerde modellen hebben entiteitsherkenning fundamenteel veranderd door sequentiële verwerking te vervangen door parallelle self-attention mechanismen die alle tokens in een zin tegelijk overwegen, en zo rijkere context begrijpen dan eerdere architecturen. BERT en varianten (RoBERTa, DistilBERT, ALBERT) gebruiken bidirectionele pre-training op enorme onbevangen corpora, waardoor universele taalrepresentaties worden geleerd die zowel syntactische als semantische informatie bevatten, voordat ze worden bijgeschaafd op NER-taken met relatief weinig gelabelde data. Het pre-training en fine-tuning paradigma is bijzonder krachtig voor entiteitsherkenning: modellen die op miljarden tokens zijn voorgetraind, ontwikkelen robuuste taal- en entiteitspatronen die met slechts duizenden gelabelde voorbeelden kunnen worden aangepast aan specifieke domeinen—veel minder data dan bij training vanaf nul. Transformers blinken uit in entiteitsbegrip dankzij hun multi-head attention mechanisme, waarbij verschillende attention heads kunnen specialiseren op verschillende typen entiteitsrelaties—sommige richten zich op syntactische grenzen, andere op semantische verbanden tussen entiteiten en hun context. Meertalige entiteitsherkenning is getransformeerd door modellen als mBERT en XLM-RoBERTa, die op meer dan 100 talen tegelijk zijn voorgetraind, waardoor zero-shot en few-shot transfer mogelijk is naar talen met weinig resources en cross-linguale entiteitskoppeling. Opkomende modellen zoals GLiNER (Generalist Language Model for Instruction-based Named Entity Recognition) gaan nog verder door instructiegebaseerde entiteitsherkenning mogelijk te maken, waarbij modellen willekeurige entiteitstypen kunnen identificeren op basis van natuurlijke taalprompts zonder taak-specifieke fine-tuning—een verschuiving naar flexibelere en generaliseerbare entiteitsbegripsystemen.
Ondanks grote vooruitgang ondervinden entiteitsherkenningssystemen in de praktijk nog steeds hardnekkige problemen, waarvan ambiguïteit en contextgevoeligheid het lastigst zijn—het woord “Apple” vraagt om begrip of het de vrucht of het technologiebedrijf betreft, afhankelijk van de context, en zelfs de beste modellen worstelen met dergelijke semantische disambiguatie in vage of ruisende tekst. Out-of-vocabulary (OOV) entiteiten vormen een fundamentele uitdaging: modellen die getraind zijn op standaarddatasets komen zelden zeldzame entiteiten, nieuwe eigennamen of spelfouten tegen, waardoor ze deze vaak verkeerd classificeren of helemaal niet herkennen. Domeinaanpassing blijft problematisch omdat modellen die op nieuws zijn getraind (zoals CoNLL-2003) vaak slecht presteren op biomedische, juridische of social media-teksten, waar entiteitsverdelingen en taalpatronen sterk verschillen, waardoor dure herannotatie en fine-tuning per domein nodig zijn. Fouten in grensdetectie—waarbij systemen wel de entiteit vinden, maar het begin- of eindpunt niet goed bepalen—komen veel voor bij meerwoordige entiteiten en geneste structuren, zoals het onderscheid tussen “New York City” en “New York” of het herkennen van entiteiten als “Chief Executive Officer of Apple Inc.” Meertalige complexiteit verergert deze uitdagingen, aangezien verschillende talen andere hoofdletterregels, morfologie en naamgevingspatronen kennen, waardoor modellen getraind op Engels vaak falen bij toepassing op andere talen. Dataschaarste voor gespecialiseerde domeinen als zeldzame ziektes, nieuwe technologieën of bedrijfsjargon vormt een knelpunt, omdat handmatige annotatie kostbaar is en men moet kiezen tussen lagere nauwkeurigheid of zware investeringen in domeinspecifieke data.
Entiteitsbegrip is onmisbaar geworden in alle sectoren en verandert de manier waarop organisaties waarde halen uit ongestructureerde tekst. In informatie-extractie en de bouw van kennisgrafen maakt entiteitsherkenning het mogelijk gestructureerde databases automatisch te vullen op basis van documenten, wat zoekmachines en aanbevelingssystemen voedt die relaties tussen personen, plaatsen en concepten begrijpen. Zorgorganisaties gebruiken entiteitsbegrip om geneesmiddelennamen, doseringen, symptomen en patiëntkenmerken uit klinische notities te halen, wat klinische besluitvorming verbetert en farmacovigilantie op schaal mogelijk maakt. Financiële instellingen extraheren aandelen-symbolen, geldwaarden en marktevenementen uit nieuws en rapportages, zodat algoritmische handel en risicoplatformen real-time kunnen reageren op marktinformatie. Juridische technologiebedrijven identificeren automatisch partijen, data, verplichtingen en aansprakelijkheidsclausules in contracten, waardoor de tijd voor documentreview van weken naar uren gaat. Klantenservice- en chatbotplatforms halen gebruikersintenties en relevante context—zoals ordernummers, productnamen en probleemtypes—uit tekst, waardoor betere routering en snellere afhandeling mogelijk is. E-commerceplatforms herkennen productnamen, merken, kenmerken en specificaties in klantreviews en zoekopdrachten, wat productontdekking en personalisatie verbetert. Contentaanbevelingssystemen gebruiken entiteitsherkenning om te begrijpen met welke entiteiten gebruikers interacteren, waardoor geavanceerdere aanbevelingen mogelijk worden die betrokkenheid en omzet stimuleren.
Het bouwen van een productiegericht entiteitsbegripsysteem vereist zorgvuldige aandacht voor datavoorbereiding, modelkeuze en evaluatie. Begin met hoogwaardige geannoteerde data: stel duidelijke entiteitstype-definities op, gebruik overeenstemmingsmaten tussen annotatoren voor consistentie, en streef naar ten minste 500-1000 gelabelde voorbeelden per entiteitstype, hoewel sommige domeinen meer vereisen. Modelkeuze hangt af van de context: regelgebaseerde systemen bieden interpretatie en lage latency voor goed gedefinieerde domeinen, traditionele ML-modellen (CRF, SVM) presteren goed bij matige datahoeveelheden, terwijl transformer-gebaseerde modellen (BERT, RoBERTa) de hoogste nauwkeurigheid bieden maar meer rekenkracht en data vragen. Trainings- en fine-tuningstrategieën moeten data-augmentatie bevatten om onbalans te compenseren, cross-validatie om overfitting te voorkomen, en zorgvuldige hyperparameter-tuning. Evalueer het systeem met precisie (correcte entiteiten gevonden), recall (gevonden entiteiten versus alle echte entiteiten) en F1-score (harmonisch gemiddelde), met aparte scores per entiteitstype om zwakke plekken te identificeren. Overwegingen voor deployment zijn latency (batch vs. real-time), schaalbaarheid en integratie met bestaande datapijplijnen, terwijl na livegang monitoring nodig is op prestatieverloop, false positives en gebruikersfeedback om retraining te starten.
Het ecosysteem van entiteitsbegriptools biedt oplossingen voor elke schaal en use case. Open-source bibliotheken zoals spaCy leveren productieklare NER-pijplijnen met indrukwekkende prestaties (89,22% F1 op standaardbenchmarks) en uitstekende documentatie—ideaal voor teams met ML-kennis; NLTK is waardevol voor educatie en basis-NER; en Hugging Face Transformers biedt toegang tot state-of-the-art voorgetrainde modellen die met minimale code kunnen worden bijgeschaafd aan specifieke domeinen. Cloudgebaseerde managed services nemen infrastructuurzorgen weg: Google Cloud Natural Language API, AWS Comprehend en IBM Watson NLP bieden voorgetrainde entiteitsherkenning met ondersteuning voor meerdere talen en entiteitstypen, automatisch schaalbaar en naadloos te integreren met datapijplijnen. Gespecialiseerde frameworks zoals Flair (gebaseerd op PyTorch, uitstekend voor sequence labeling) en DeepPavlov (pre-trained modellen voor meerdere talen en domeinen) zijn geschikt voor onderzoekers en teams die meer maatwerk willen dan standaardbibliotheken. De keuze tussen zelf bouwen of bestaande tools gebruiken hangt af van datagevoeligheid (on-premise vs. cloud), gewenste nauwkeurigheid, domeinspecificiteit en teamexpertise: gebruik managed APIs voor algemene toepassingen met standaard entiteiten, open-source voor domeinspecifiek maatwerk met interne data, en bouw alleen zelf als bestaande oplossingen niet aan de eisen voldoen qua nauwkeurigheid of latency.
De toekomst van entiteitsbegrip wordt gevormd door grote taalmodellen die ongekende flexibiliteit en prestaties brengen. Modellen als GPT-4 en Claude tonen indrukwekkende few-shot en zero-shot entiteitsherkenning, waarmee organisaties aangepaste entiteitstypen kunnen identificeren op basis van slechts enkele voorbeelden of zelfs natuurlijke taalbeschrijvingen, wat de annotatielast enorm vermindert en de time-to-value versnelt. Multimodaal entiteitsbegrip komt op als nieuw terrein, waarbij tekst, afbeeldingen en gestructureerde data worden gecombineerd om entiteiten te herkennen in documenten, facturen en webpagina’s met rijkere context—essentieel voor toepassingen als automatische documentverwerking en visuele zoektoepassingen. Verbeteringen in real-time verwerking, mogelijk gemaakt door modeldistillatie en edge deployment, maken geavanceerde entiteitsherkenning haalbaar op mobiele apparaten en IoT-systemen, wat nieuwe toepassingen opent in augmented reality, real-time vertaling en autonome systemen. Voortgang in domeinspecifieke fine-tuning resulteert in gespecialiseerde modellen voor biomedische, juridische en financiële sectoren die generieke modellen ver overtreffen, met technieken als domeinadaptieve pre-training en transfer learning die dit steeds toegankelijker maken. Naarmate deze technologieën volwassen worden, zal entiteitsbegrip een onzichtbare fundamentlaag worden in AI-systemen, waarmee machines de wereld mensachtig semantisch begrijpen en mogelijkheden openen die we nu nog nauwelijks kunnen voorstellen.
Nu AI-systemen zoals ChatGPT, Perplexity en Google AI Overviews steeds meer worden geïntegreerd in de manier waarop informatie wordt gevonden en geconsumeerd, wordt het essentieel om te begrijpen hoe deze systemen entiteiten—waaronder jouw merk—herkennen en benoemen. Entiteitsbegrip is het mechanisme waarmee AI-systemen bedrijven, producten, mensen en concepten identificeren en verwerken. Door te monitoren hoe AI-systemen jouw merk als entiteit herkennen en benoemen, krijg je inzicht in:
Dit is precies wat AmICited monitort—het volgen van hoe AI-systemen jouw merk als entiteit herkennen en benoemen op meerdere AI-platforms. Door entiteitsherkenning te begrijpen, krijg je beter inzicht in hoe AI-systemen jouw bedrijf waarnemen en communiceren.
Entiteitsherkenning (NER) identificeert en classificeert entiteiten in tekst (bijv. 'Apple' als ORGANISATIE), terwijl entiteitskoppeling die entiteiten verbindt met kennisbanken of canonieke referenties (bijv. het koppelen van 'Apple' aan de Wikipedia-pagina van Apple Inc.). Entiteitsherkenning is de eerste stap; entiteitskoppeling voegt semantische onderbouwing toe.
State-of-the-art transformer-gebaseerde modellen zoals BERT behalen een F1-score van 90,9% op standaard benchmarks zoals CoNLL-2003. De nauwkeurigheid varieert echter sterk per domein—modellen getraind op nieuws presteren slecht op biomedische of social media-teksten. De nauwkeurigheid in de praktijk hangt sterk af van domeinaanpassing en datakwaliteit.
Ja, meertalige modellen zoals mBERT en XLM-RoBERTa ondersteunen meer dan 100 talen tegelijk. De prestaties verschillen echter per taal vanwege verschillen in hoofdlettergebruik, morfologie en beschikbare trainingsdata. Taal-specifieke modellen presteren doorgaans beter dan meertalige modellen bij kritische toepassingen.
Regelgebaseerde systemen gebruiken handgemaakte patronen en woordenlijsten (snel, interpreteerbaar, maar kwetsbaar). ML-gebaseerde systemen leren van gelabelde data (flexibeler, betere generalisatie, maar vereisen trainingsdata en feature engineering). Moderne deep learning-methoden automatiseren feature-extractie en behalen superieure nauwkeurigheid.
Regelgebaseerde systemen hebben alleen patroondefinities nodig. Traditionele ML-modellen vereisen 300-500 gelabelde voorbeelden. Transformer-gebaseerde modellen werken met 800+ voorbeelden, maar profiteren van transfer learning—voorgetrainde modellen behalen goede resultaten met slechts 100-200 domeinspecifieke voorbeelden via fine-tuning.
Belangrijke uitdagingen zijn: ambiguïteit (hetzelfde woord met verschillende betekenissen), out-of-vocabulary entiteiten, domeinaanpassing (modellen getraind op het ene domein falen in het andere), fouten in grensdetectie, meertalige complexiteit, en dataschaarste voor gespecialiseerde domeinen. Dit vereist zorgvuldige systeembouw en domeinspecifieke afstemming.
Context is cruciaal—'bank' betekent iets anders in 'rivierbank' dan in 'spaarbank'. Moderne transformers gebruiken self-attention om context van omringende tokens te wegen, waardoor ze entiteiten kunnen disambigueren op basis van linguïstische en semantische context. Slechte contextverwerking is een belangrijke bron van fouten in entiteitsherkenning.
Toekomstige ontwikkelingen zijn onder meer: grote taalmodellen die zero-shot entiteitsherkenning mogelijk maken, multimodaal begrip dat tekst en afbeeldingen combineert, real-time verwerking op edge-apparaten, en vooruitgang in domeinspecifieke fine-tuning. Entiteitsbegrip zal een onzichtbare fundamentlaag worden die machines in staat stelt de wereld te begrijpen met mensachtig semantisch inzicht.
AmICited volgt entiteitsvermeldingen in AI-systemen zoals ChatGPT, Perplexity en Google AI Overviews. Begrijp hoe AI jouw merk in real-time begrijpt en benoemt.
Entiteitsherkenning is een AI NLP-capaciteit voor het identificeren en categoriseren van benoemde entiteiten in tekst. Leer hoe het werkt, de toepassingen in AI...

Ontdek hoe AI-systemen relaties tussen entiteiten in tekst identificeren, extraheren en begrijpen. Leer technieken voor extractie van entiteitsrelaties, NLP-met...
Ontdek wat entiteitsoptimalisatie voor AI is, hoe het werkt en waarom het cruciaal is voor zichtbaarheid in ChatGPT, Perplexity en andere AI-zoekmachines. Compl...