
WAF-regels voor AI-crawlers: Verder dan Robots.txt
Ontdek hoe Web Application Firewalls geavanceerde controle bieden over AI-crawlers, verder dan robots.txt. Implementeer WAF-regels om je content te beschermen t...
8 min lezen
Leer hoe je selectieve AI-crawlerblokkering implementeert om je content te beschermen tegen trainingsbots, terwijl je zichtbaarheid in AI-zoekresultaten blijft behouden. Technische strategieën voor uitgevers.
Uitgevers staan tegenwoordig voor een onmogelijke keuze: blokkeer alle AI-crawlers en verlies waardevol zoekverkeer, of sta ze allemaal toe en zie hoe je content trainingsdatasets voedt zonder compensatie. De opkomst van generatieve AI heeft een gespleten crawler-ecosysteem gecreëerd, waarbij dezelfde robots.txt-regels zonder onderscheid gelden voor zowel zoekmachines die inkomsten opleveren als trainingscrawlers die waarde onttrekken. Deze paradox heeft vooruitstrevende uitgevers gedwongen selectieve crawler-controlestrategieën te ontwikkelen die onderscheid maken tussen verschillende typen AI-bots op basis van hun daadwerkelijke impact op bedrijfsdoelstellingen.
Het AI-crawlerlandschap valt uiteen in twee duidelijke categorieën met sterk verschillende doelen en zakelijke implicaties. Trainingscrawlers — beheerd door bedrijven zoals OpenAI, Anthropic en Google — zijn ontworpen om grote hoeveelheden tekstdata te verzamelen om grote taalmodellen te bouwen en te verbeteren, terwijl zoekcrawlers content indexeren voor vindbaarheid. Trainingsbots zijn goed voor ongeveer 80% van alle AI-gerelateerde botactiviteit, maar leveren uitgevers geen directe inkomsten op, terwijl zoekcrawlers zoals Googlebot en Bingbot jaarlijks miljoenen bezoeken en advertentievertoningen genereren. Het onderscheid is belangrijk, omdat een enkele trainingscrawler evenveel bandbreedte kan verbruiken als duizenden menselijke gebruikers, terwijl zoekcrawlers zijn geoptimaliseerd voor efficiëntie en doorgaans de crawl-limieten respecteren.
| Botnaam | Operator | Primaire doel | Verkeerspotentieel |
|---|---|---|---|
| GPTBot | OpenAI | Modeltraining | Geen (data-extractie) |
| Claude Web Crawler | Anthropic | Modeltraining | Geen (data-extractie) |
| Googlebot | Zoekindexering | 243,8M bezoeken (april 2025) | |
| Bingbot | Microsoft | Zoekindexering | 45,2M bezoeken (april 2025) |
| Perplexity Bot | Perplexity AI | Zoeken + training | 12,1M bezoeken (april 2025) |
De cijfers zijn duidelijk: alleen al de crawler van ChatGPT stuurde 243,8 miljoen bezoeken naar uitgevers in april 2025, maar deze bezoeken leverden nul klikken, nul advertentievertoningen en nul inkomsten op. Ondertussen werd het verkeer van Googlebot omgezet in daadwerkelijke gebruikersinteractie en verdienkansen. Dit onderscheid begrijpen is de eerste stap naar het implementeren van een selectieve blokkeringsstrategie die je content beschermt en tegelijkertijd je zoekzichtbaarheid behoudt.
Het blindelings blokkeren van alle AI-crawlers is voor de meeste uitgevers economisch zeer nadelig. Terwijl trainingscrawlers waarde onttrekken zonder compensatie, blijven zoekcrawlers een van de meest betrouwbare verkeersbronnen in een steeds gefragmenteerder digitaal landschap. Het financiële argument voor selectief blokkeren rust op enkele belangrijke factoren:
Uitgevers die selectieve blokkeringsstrategieën implementeren, melden dat ze hun zoekverkeer behouden of zelfs verbeteren, terwijl ongeoorloofde contentextractie tot wel 85% wordt verminderd. De strategische benadering erkent dat niet alle AI-crawlers gelijk zijn, en dat een genuanceerd beleid de bedrijfsbelangen veel beter dient dan een alles-of-nietsbenadering.
Het robots.txt-bestand blijft het primaire mechanisme om crawlerrechten te communiceren en is verrassend effectief om verschillende bottypes te onderscheiden bij correcte configuratie. Dit eenvoudige tekstbestand, geplaatst in de rootmap van je website, gebruikt user-agent-richtlijnen om aan te geven welke crawlers toegang krijgen tot welke content. Voor selectieve AI-crawlercontrole kun je zoekmachines toestaan en trainingscrawlers met chirurgische precisie blokkeren.
Hier is een praktisch voorbeeld dat trainingscrawlers blokkeert en zoekmachines toestaat:
# OpenAI's GPTBot blokkeren
User-agent: GPTBot
Disallow: /
# Anthropic's Claude crawler blokkeren
User-agent: Claude-Web
Disallow: /
# Andere trainingscrawlers blokkeren
User-agent: CCBot
Disallow: /
User-agent: anthropic-ai
Disallow: /
# Zoekmachines toestaan
User-agent: Googlebot
Allow: /
User-agent: Bingbot
Allow: /
User-agent: *
Disallow: /admin/
Disallow: /private/
Deze aanpak geeft duidelijke instructies aan goedgedragende crawlers en behoudt de vindbaarheid van je site in zoekresultaten. Robots.txt is echter in de basis een vrijwillige standaard — het hangt af van de crawleroperatoren of ze je richtlijnen respecteren. Voor uitgevers die zich zorgen maken over naleving zijn extra handhavingslagen noodzakelijk.
Robots.txt alleen biedt geen garantie op naleving, omdat ongeveer 13% van de AI-crawlers robots.txt volledig negeert, hetzij uit onachtzaamheid, hetzij opzettelijk. Handhaving op serverniveau via je webserver of applicatielaag biedt een technische vangnet die ongeoorloofde toegang blokkeert, ongeacht het crawlergedrag. Deze aanpak blokkeert verzoeken op HTTP-niveau voordat ze veel bandbreedte of resources verbruiken.
Server-level blokkeren met Nginx is eenvoudig en zeer effectief:
# In je Nginx serverblok
location / {
# Trainingscrawlers op serverniveau blokkeren
if ($http_user_agent ~* (GPTBot|Claude-Web|CCBot|anthropic-ai|Omgili)) {
return 403;
}
# Blokkeren op IP-reeksen indien nodig (voor crawlers die user agents spoofen)
if ($remote_addr ~* "^(192\.0\.2\.|198\.51\.100\.)") {
return 403;
}
# Normale verwerking van verzoeken
proxy_pass http://backend;
}
Deze configuratie geeft een 403 Forbidden-respons aan geblokkeerde crawlers, verbruikt minimale serverresources en communiceert duidelijk dat toegang wordt geweigerd. Gecombineerd met robots.txt creëert server-level handhaving een tweelaagse verdediging die zowel goed- als kwaadwillende crawlers vangt. Het percentage dat robots.txt omzeilt, zakt naar vrijwel nul bij correcte serverregels.
Content Delivery Networks en Web Application Firewalls bieden een extra handhavingslaag die werkt nog vóór verzoeken je originservers bereiken. Diensten zoals Cloudflare, Akamai en AWS WAF laten je regels aanmaken om specifieke user agents of IP-reeksen aan de rand te blokkeren, zodat malafide of ongewenste crawlers je infrastructuur niet belasten. Deze diensten onderhouden up-to-date lijsten van bekende trainingscrawler-IP’s en user agents en blokkeren ze automatisch, zonder handmatige configuratie.
CDN-controles bieden verschillende voordelen boven serverhandhaving: ze verminderen de belasting van je originservers, bieden geografische blokkering en geven realtime analyses van geblokkeerde verzoeken. Veel CDN-aanbieders bieden nu standaard AI-specifieke blokkeringsregels, als antwoord op de bezorgdheid van uitgevers over ongeoorloofde data-extractie voor training. Voor uitgevers die Cloudflare gebruiken, biedt de optie “AI Crawlers blokkeren” in de beveiligingsinstellingen met één klik bescherming tegen grote trainingscrawlers, terwijl zoekmachineverkeer behouden blijft.
Effectief selectief blokkeren vereist een systematische aanpak voor het classificeren van crawlers op basis van hun zakelijke impact en betrouwbaarheid. In plaats van alle AI-crawlers hetzelfde te behandelen, kunnen uitgevers een drielagig kader invoeren dat de werkelijke waarde en het risico van elke crawler weerspiegelt. Dit kader maakt genuanceerde beslissingen mogelijk die contentbescherming en zakelijke kansen in balans brengen.
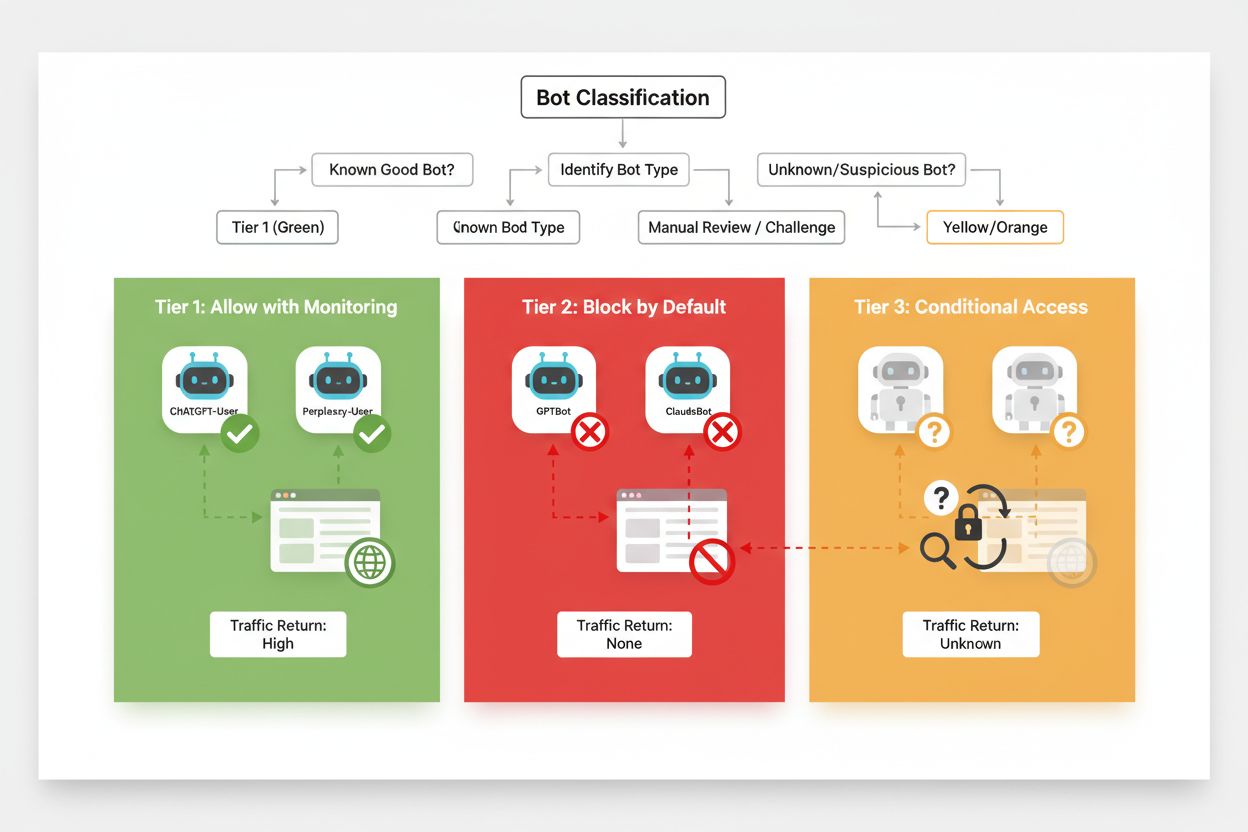
| Laag | Classificatie | Voorbeelden | Actie |
|---|---|---|---|
| Laag 1: Inkomstenbronnen | Zoekmachines en grote referralbronnen | Googlebot, Bingbot, Perplexity Bot | Volledige toegang toestaan; optimaliseren voor crawlbaarheid |
| Laag 2: Neutraal/Onbewezen | Nieuwe of opkomende crawlers met onduidelijke intenties | Kleine AI-startups, onderzoeksbots | Goed monitoren; toestaan met crawl-limieten |
| Laag 3: Waardeonttrekkers | Trainingscrawlers zonder direct voordeel | GPTBot, Claude-Web, CCBot | Volledig blokkeren; afdwingen op meerdere lagen |
Het implementeren van dit kader vereist voortdurend onderzoek naar nieuwe crawlers en hun businessmodellen. Uitgevers zouden hun toegangslogs regelmatig moeten controleren om nieuwe bots te identificeren, de voorwaarden van operatoren en compensatiebeleid te onderzoeken, en de classificaties daarop aan te passen. Een crawler die als Laag 3 start, kan naar Laag 2 opschuiven als de operator inkomsten gaat delen, terwijl een eerder vertrouwde crawler naar Laag 3 kan zakken als deze crawl-limieten of robots.txt gaat schenden.
Selectief blokkeren is geen ‘set and forget’-configuratie — het vereist voortdurende monitoring en bijstelling naarmate het crawler-ecosysteem evolueert. Uitgevers moeten uitgebreide logging en analyse implementeren om te volgen welke crawlers hun content bezoeken, hoeveel bandbreedte ze verbruiken en of ze ingestelde restricties respecteren. Deze data informeren strategische beslissingen over welke crawlers je toestaat, blokkeert of beperkt.
Analyse van je toegangslogs onthult crawlpatronen die beleidsaanpassingen ondersteunen:
# Alle AI-crawlers identificeren die je site bezoeken
grep -i "bot\|crawler" /var/log/nginx/access.log | \
awk '{print $12}' | sort | uniq -c | sort -rn | head -20
# Bandbreedte berekenen per specifieke crawler
grep "GPTBot" /var/log/nginx/access.log | \
awk '{sum+=$10} END {print "GPTBot bandbreedte: " sum/1024/1024 " MB"}'
# 403-responses monitoren voor geblokkeerde crawlers
grep " 403 " /var/log/nginx/access.log | grep -i "bot" | wc -l
Regelmatige analyse van deze data — idealiter wekelijks of maandelijks — laat zien of je blokkeringsstrategie werkt, of er nieuwe crawlers zijn verschenen en of eerder geblokkeerde crawlers hun gedrag hebben aangepast. Deze informatie voedt je classificatiekader, zodat je beleid blijft aansluiten bij bedrijfsdoelen en technische realiteit.
Uitgevers die selectieve crawlerblokkering implementeren, maken regelmatig fouten die hun strategie ondermijnen of ongewenste gevolgen hebben. Deze valkuilen kennen helpt je een effectiever beleid te voeren:
Alle crawlers zonder onderscheid blokkeren: De meest voorkomende fout is te brede blokkeringsregels die zoekmachines én trainingscrawlers treffen, waardoor zoekzichtbaarheid verloren gaat in een poging content te beschermen.
Alleen vertrouwen op robots.txt: Denken dat robots.txt alleen ongeoorloofde toegang voorkomt, negeert de 13% crawlers die het volledig negeren, waardoor je content kwetsbaar blijft voor data-extractie.
Niet monitoren en aanpassen: Een statisch blokkeringsbeleid invoeren en nooit herzien betekent dat je nieuwe crawlers mist, niet inspeelt op veranderende businessmodellen en mogelijk nuttige crawlers blokkeert die hun praktijk hebben verbeterd.
Alleen op user agent blokkeren: Geavanceerde crawlers spoofen of wisselen regelmatig van user agent, waardoor blokkeren op alleen user agent ineffectief is zonder aanvullende IP-regels en crawl-limieten.
Geen crawl-limieten instellen: Zelfs toegestane crawlers kunnen te veel bandbreedte verbruiken als ze niet worden gelimiteerd, wat prestaties voor menselijke gebruikers schaadt en onnodig infrastructuur gebruikt.
De toekomst van de relatie tussen uitgevers en AI-crawlers zal waarschijnlijk meer onderhandeling en compensatiemodellen omvatten in plaats van simpel blokkeren. Totdat er branchebrede standaarden zijn, blijft selectieve crawler-controle de meest praktische aanpak om content te beschermen en zoekzichtbaarheid te behouden. Uitgevers zouden hun blokkeringsstrategie moeten zien als een dynamisch beleid dat meegroeit met het crawler-ecosysteem, met regelmatige herbeoordeling van welke crawlers toegang verdienen op basis van hun zakelijke impact en betrouwbaarheid.
De meest succesvolle uitgevers zijn degenen die gelaagde verdediging toepassen — door robots.txt, serverhandhaving, CDN-controles en doorlopende monitoring te combineren tot een allesomvattende strategie. Deze aanpak beschermt tegen zowel goed- als kwaadwillende crawlers en behoudt het zoekverkeer dat inkomsten en gebruikersinteractie drijft. Naarmate AI-bedrijven de waarde van uitgeverscontent erkennen en compensatie of licenties gaan aanbieden, is het kader dat je nu opbouwt eenvoudig aanpasbaar voor nieuwe verdienmodellen, terwijl je controle over je digitale bezit behoudt.
Trainingscrawlers zoals GPTBot en ClaudeBot verzamelen data om AI-modellen te bouwen zonder verkeer terug te sturen naar je site. Zoekcrawlers zoals OAI-SearchBot en PerplexityBot indexeren content voor AI-zoekmachines en kunnen aanzienlijk doorverwijsverkeer naar je site sturen. Dit onderscheid begrijpen is cruciaal voor een effectieve selectieve blokkeringsstrategie.
Ja, dit is de kern van selectieve crawler-controle. Je kunt robots.txt gebruiken om trainingsbots te verbieden en zoekbots toe te staan, en vervolgens afdwingen met server-level controles voor bots die robots.txt negeren. Deze aanpak beschermt je content tegen ongeoorloofde training en behoudt je zichtbaarheid in AI-zoekresultaten.
De meeste grote AI-bedrijven zeggen robots.txt te respecteren, maar naleving is vrijwillig. Onderzoek toont aan dat ongeveer 13% van de AI-bots robots.txt-richtlijnen volledig negeert. Daarom is handhaving op serverniveau essentieel voor uitgevers die hun content serieus willen beschermen tegen niet-nalevende crawlers.
Significant en groeiend. ChatGPT stuurde 243,8 miljoen bezoeken naar 250 nieuws- en mediasites in april 2025, een stijging van 98% ten opzichte van januari. Door deze crawlers te blokkeren, mis je deze opkomende verkeersbron. Voor veel uitgevers vertegenwoordigt AI-zoekverkeer nu 5-15% van het totale doorverwijsverkeer.
Analyseer je serverlogs regelmatig met grep-commando's om bot user agents te identificeren, de crawlfrequentie bij te houden en te controleren op naleving van je robots.txt-regels. Bekijk de logs minstens maandelijks om nieuwe bots, ongebruikelijke patronen en bots die geblokkeerd zouden moeten zijn te ontdekken. Deze data ondersteunen strategische beslissingen over je crawlerbeleid.
Je beschermt je content tegen ongeoorloofde training, maar je verliest zichtbaarheid in AI-zoekresultaten, mist opkomende verkeersbronnen en mogelijk minder merkvermeldingen in AI-gegenereerde antwoorden. Uitgevers die alles blokkeren, zien vaak 40-60% minder zoekzichtbaarheid en missen kansen op merkontdekking via AI-platformen.
Ten minste maandelijks, want er verschijnen voortdurend nieuwe bots en bestaande bots veranderen hun gedrag. Het AI-crawlerlandschap verandert snel, met nieuwe operators die crawlers starten en bestaande partijen die hun bots samenvoegen of hernoemen. Regelmatige evaluaties zorgen ervoor dat je beleid blijft aansluiten bij je bedrijfsdoelen en de technische realiteit.
Dit is het aantal gecrawlde pagina's versus het aantal bezoekers dat naar je site wordt teruggestuurd. Anthropic crawlt 38.000 pagina's per bezoeker die wordt terugverwezen, terwijl OpenAI een verhouding van 1.091:1 aanhoudt en Perplexity op 194:1 zit. Lagere ratios geven meer waarde voor het toestaan van de crawler. Deze metriek helpt je te bepalen welke crawlers toegang verdienen op basis van hun werkelijke zakelijke impact.
AmICited volgt welke AI-platformen jouw merk en content vermelden. Krijg inzicht in je AI-zichtbaarheid en zorg voor correcte bronvermelding in ChatGPT, Perplexity, Google AI Overviews en meer.
Ontdek hoe Web Application Firewalls geavanceerde controle bieden over AI-crawlers, verder dan robots.txt. Implementeer WAF-regels om je content te beschermen t...

Leer hoe je AI-crawlers zoals GPTBot en ClaudeBot kunt blokkeren of toestaan met robots.txt, server-side blokkades en geavanceerde beschermingsmethoden. Volledi...

Ontdek hoe je strategische beslissingen neemt over het blokkeren van AI-crawlers. Evalueer inhoudstype, verkeersbronnen, verdienmodellen en concurrentiepositie ...