
Hoe AI-crawlers identificeren in serverlogs: Complete detectiegids
Leer hoe je AI-crawlers zoals GPTBot, PerplexityBot en ClaudeBot kunt identificeren en monitoren in je serverlogs. Ontdek user-agent strings, IP-verificatiemeth...
8 min lezen

Leer hoe je AI-crawlers zoals GPTBot en ClaudeBot kunt blokkeren of toestaan met robots.txt, server-side blokkades en geavanceerde beschermingsmethoden. Volledige technische gids met voorbeelden.
Het digitale landschap is fundamenteel verschoven van traditionele zoekmachineoptimalisatie naar het beheren van een geheel nieuwe categorie geautomatiseerde bezoekers: AI-crawlers. In tegenstelling tot conventionele zoekbots die verkeer terugsturen naar je site via zoekresultaten, consumeren AI-trainingscrawlers je content om grote taalmodellen te bouwen zonder noodzakelijkerwijs verkeer terug te sturen. Dit onderscheid heeft grote gevolgen voor uitgevers, contentmakers en bedrijven die afhankelijk zijn van webverkeer als inkomstenbron. De belangen zijn groot—wie bepaalt welke AI-systemen toegang hebben tot je content, beïnvloedt direct je concurrentiepositie, gegevensprivacy en bedrijfsresultaat.
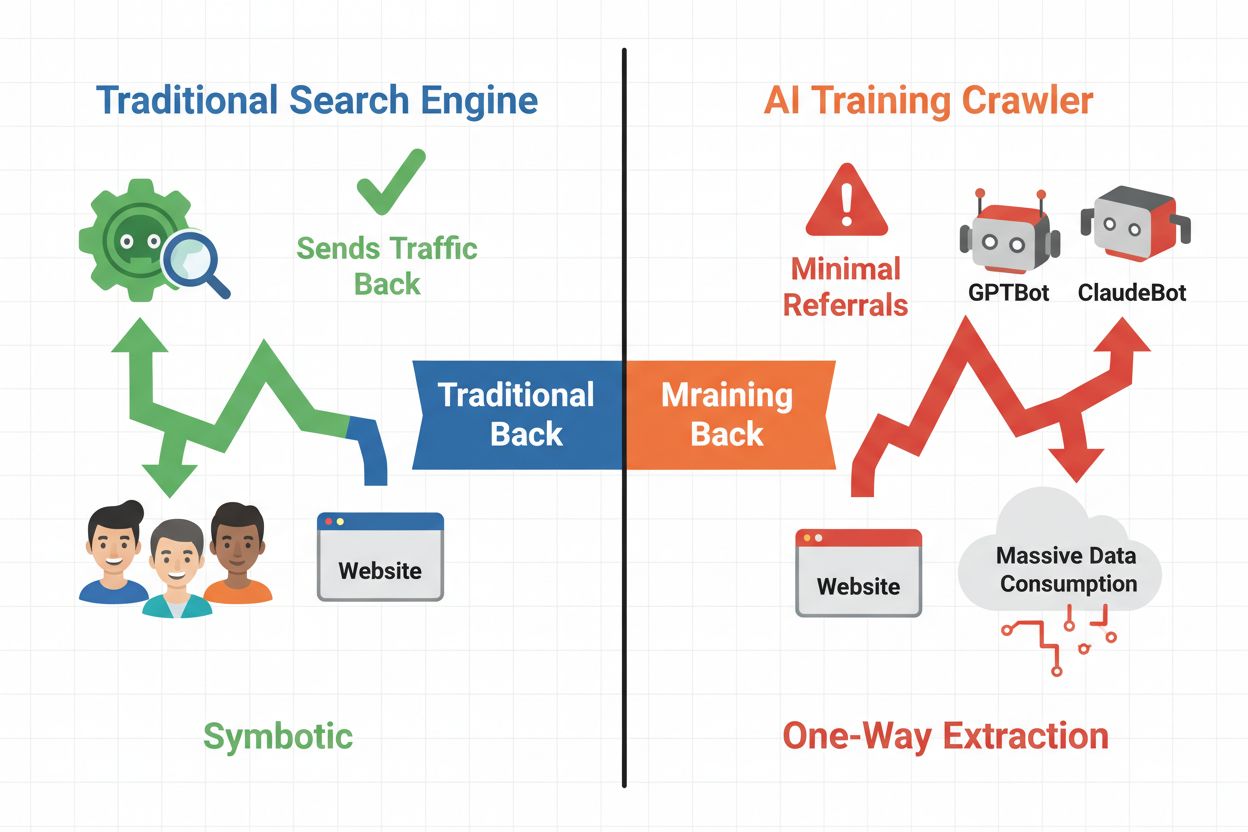
AI-crawlers vallen uiteen in drie duidelijke categorieën, elk met verschillende doeleinden en gevolgen voor verkeer. Trainingscrawlers worden door AI-bedrijven gebruikt om hun taalmodellen te bouwen en te verbeteren, werken op grote schaal en leveren doorgaans nauwelijks verkeer op. Zoek- en citatiecrawlers indexeren content voor AI-zoekmachines en citatiesystemen en zorgen soms voor doorverwijzingsverkeer naar uitgevers. Gebruikersgestuurde crawlers halen content op aanvraag op wanneer gebruikers interactie hebben met AI-toepassingen; dit is een klein maar groeiend segment. Door deze categorieën te begrijpen, kun je weloverwogen beslissingen nemen over welke crawlers je toestaat of blokkeert, afhankelijk van je bedrijfsmodel.
| Crawler Type | Doel | Impact op verkeer | Voorbeelden |
|---|---|---|---|
| Training | Opbouwen/verbeteren van LLM’s | Minimaal tot geen | GPTBot, ClaudeBot, Bytespider |
| Zoek/Citatie | Indexeren voor AI-zoek & citaties | Gemiddeld doorverwijzingsverkeer | Googlebot-Extended, Perplexity |
| Gebruikersgestuurd | Op aanvraag ophalen voor gebruikers | Laag maar consistent | ChatGPT-plugins, Claude browsing |
Het AI-crawler-ecosysteem omvat crawlers van ’s werelds grootste technologiebedrijven, elk met een eigen user agent en doel. OpenAI’s GPTBot (user agent: GPTBot/1.0) crawlt om ChatGPT en andere modellen te trainen, terwijl Anthropic’s ClaudeBot (user agent: Claude-Web/1.0) soortgelijke doelen dient voor Claude. Google’s Googlebot-Extended (user agent: Mozilla/5.0 ... Googlebot-Extended) indexeert content voor AI Overviews en Bard, terwijl Meta’s Meta-ExternalFetcher crawlt voor hun AI-initiatieven. Andere grote spelers zijn:
Elke crawler werkt op een andere schaal en houdt zich in uiteenlopende mate aan blokkeerrichtlijnen.
Het robots.txt-bestand is je eerste verdedigingslinie voor het beheren van AI-crawler-toegang, maar het is belangrijk om te begrijpen dat het adviserend is en niet wettelijk afdwingbaar. Dit bestand staat in de root van je domein (bijv. jouwsite.com/robots.txt) en gebruikt eenvoudige syntax om crawlers te instrueren welke delen ze moeten vermijden. Om alle AI-crawlers volledig te blokkeren, voeg je de volgende regels toe:
User-agent: GPTBot
Disallow: /
User-agent: Claude-Web
Disallow: /
User-agent: Googlebot-Extended
Disallow: /
User-agent: Meta-ExternalFetcher
Disallow: /
User-agent: Amazonbot
Disallow: /
User-agent: Bytespider
Disallow: /
User-agent: Applebot-Extended
Disallow: /
User-agent: CCBot
Disallow: /
Als je selectief wilt blokkeren—zoekcrawlers toestaan maar trainingscrawlers blokkeren—gebruik dan deze aanpak:
User-agent: GPTBot
Disallow: /
User-agent: Claude-Web
Disallow: /
User-agent: Bytespider
Disallow: /
User-agent: Googlebot-Extended
Disallow: /news/
Allow: /
Een veelgemaakte fout is het gebruik van te brede regels zoals Disallow: *, wat parsers kan verwarren, of het vergeten van het specificeren van individuele crawlers als je alleen bepaalde wilt blokkeren. Grote bedrijven als OpenAI, Anthropic en Google respecteren doorgaans robots.txt, maar sommige crawlers zoals Perplexity staan erom bekend deze regels volledig te negeren.
Wanneer robots.txt alleen niet voldoende is, bieden verschillende sterkere beschermingsmethoden extra controle over AI-crawler-toegang. IP-gebaseerd blokkeren houdt in dat je IP-reeksen van AI-crawlers identificeert en deze op firewall- of serverniveau blokkeert—dit is zeer effectief, maar vereist doorlopend onderhoud omdat IP-reeksen veranderen. Server-side blokkades via .htaccess-bestanden (Apache) of Nginx-configuratiebestanden bieden meer gedetailleerde controle en zijn moeilijker te omzeilen dan robots.txt. Voor Apache-servers implementeer je deze blokkeerregel:
<IfModule mod_rewrite.c>
RewriteEngine On
RewriteCond %{HTTP_USER_AGENT} (GPTBot|Claude-Web|Bytespider|Amazonbot) [NC]
RewriteRule ^.*$ - [F,L]
</IfModule>
Meta tag-blokkering via <meta name="robots" content="noindex, noimageindex, nofollowbydefault"> voorkomt indexering maar stopt trainingscrawlers niet. Verificatie van request headers controleert of crawlers daadwerkelijk afkomstig zijn van de opgegeven bron door reverse DNS en SSL-certificaten te verifiëren. Gebruik server-side blokkering als je absolute zekerheid wilt dat crawlers geen toegang krijgen tot je content, en combineer meerdere methoden voor maximale bescherming.
Of je AI-crawlers blokkeert, hangt af van verschillende belangen. Trainingscrawlers blokkeren (GPTBot, ClaudeBot, Bytespider) voorkomt dat je content wordt gebruikt voor het trainen van AI-modellen, wat je intellectueel eigendom en concurrentievoordeel beschermt. Zoekcrawlers toestaan (Googlebot-Extended, Perplexity) kan echter doorverwijzingsverkeer opleveren en je zichtbaarheid vergroten in AI-zoekresultaten—een groeiend kanaal voor ontdekking. De afweging wordt complexer als je bedenkt dat sommige AI-bedrijven een slechte crawl-naar-verwijzingsratio hebben: de crawlers van Anthropic genereren ongeveer 38.000 crawlverzoeken voor elke enkele verwijzing, terwijl die van OpenAI ongeveer 400:1 is. Serverbelasting en bandbreedte zijn een andere overweging—AI-crawlers verbruiken veel resources en blokkeren kan infrastructuurkosten verlagen. Je beslissing moet aansluiten bij je bedrijfsmodel: nieuwsorganisaties en uitgevers kunnen baat hebben bij doorverwijzingsverkeer, terwijl SaaS-bedrijven en makers van eigen content doorgaans liever blokkeren.
Het implementeren van crawlerblokkades is slechts de helft van het werk—je moet verifiëren of crawlers je richtlijnen daadwerkelijk respecteren. Serverloganalyse is je primaire verificatiemiddel; bekijk je access logs op user agent strings en IP-adressen van crawlers die je site proberen te benaderen na blokkade. Gebruik grep om je logs te doorzoeken:
grep -i "gptbot\|claude-web\|bytespider" /var/log/apache2/access.log | wc -l
Dit commando telt hoe vaak deze crawlers je site bezocht hebben. Testtools zoals curl kunnen crawlerverzoeken simuleren om te controleren of je blokkeerregels correct werken:
curl -A "GPTBot/1.0" https://jouwsite.com/robots.txt
Controleer je logs wekelijks in de eerste maand na het implementeren van blokkades, daarna elk kwartaal. Als je crawlers detecteert die je robots.txt negeren, schakel dan over op server-side blokkering of neem contact op met het abuse-team van de crawleroperator.
Het AI-crawlerlandschap verandert snel nu nieuwe bedrijven AI-producten lanceren en bestaande crawlers hun user agents en IP-reeksen wijzigen. Kwartaalreviews van je blokkeerlijst zorgen ervoor dat je geen nieuwe crawlers mist of per ongeluk legitiem verkeer blokkeert. Het ecosysteem van crawlers is gefragmenteerd en gedecentraliseerd, waardoor een volledig permanente blokkeerlijst onmogelijk is. Houd deze bronnen in de gaten voor updates:
Stel agenda-herinneringen in om je robots.txt en server-side regels elke 90 dagen te controleren en abonneer je op security mailinglijsten die nieuwe crawlerdeployments volgen.
Hoewel het blokkeren van AI-crawlers voorkomt dat ze toegang krijgen tot je content, pakt AmICited de aanvullende uitdaging aan: monitoren of AI-systemen jouw merk en content citeren en vermelden in hun output. AmICited volgt vermeldingen van je organisatie in AI-gegenereerde antwoorden en geeft inzicht in hoe je content AI-modeluitvoer beïnvloedt en waar je merk opduikt in AI-zoekresultaten. Zo ontstaat een allesomvattende AI-strategie: je beheert welke crawlers toegang hebben via robots.txt en server-side blokkades, terwijl AmICited je inzicht geeft in de downstream-impact van je content op AI-systemen. Samen bieden deze tools volledig inzicht en controle over je aanwezigheid in het AI-ecosysteem—van het voorkomen van ongewenst gebruik als trainingsdata tot het meten van de daadwerkelijke citaties en vermeldingen die je content oplevert op AI-platforms.
Nee. Het blokkeren van AI-trainingscrawlers zoals GPTBot, ClaudeBot en Bytespider heeft geen invloed op je Google- of Bing-zoekresultaten. Traditionele zoekmachines gebruiken andere crawlers (Googlebot, Bingbot) die onafhankelijk werken. Blokkeer deze alleen als je volledig uit de zoekresultaten wilt verdwijnen.
Belangrijke crawlers van OpenAI (GPTBot), Anthropic (ClaudeBot), Google (Google-Extended) en Perplexity (PerplexityBot) geven officieel aan dat ze robots.txt-richtlijnen respecteren. Kleinere of minder transparante bots kunnen je configuratie negeren, daarom bestaan er gelaagde beschermingsstrategieën.
Dat hangt af van je strategie. Door alleen trainingscrawlers (GPTBot, ClaudeBot, Bytespider) te blokkeren, bescherm je je content tegen modeltraining terwijl je zoekgerichte crawlers toestaat om je te laten verschijnen in AI-zoekresultaten. Volledig blokkeren verwijdert je volledig uit AI-ecosystemen.
Controleer je configuratie minimaal elk kwartaal. AI-bedrijven introduceren regelmatig nieuwe crawlers. Anthropic heeft hun 'anthropic-ai' en 'Claude-Web' bots samengevoegd tot 'ClaudeBot', waardoor de nieuwe bot tijdelijk onbeperkte toegang kreeg tot sites die hun regels niet hadden bijgewerkt.
Blokkeren voorkomt dat crawlers je content volledig kunnen benaderen, waardoor het wordt beschermd tegen dataverzameling voor trainingen of indexering. Door crawlers toe te staan geef je ze toegang, maar kan je content worden gebruikt voor modeltraining of verschijnen in AI-zoekresultaten met minimale doorverwijzingsverkeer.
Ja, robots.txt is adviserend en niet wettelijk afdwingbaar. Goedgedragende crawlers van grote bedrijven respecteren doorgaans robots.txt, maar sommige crawlers negeren deze. Voor sterkere bescherming kun je blokkeren op serverniveau via .htaccess of firewallregels.
Controleer je serverlogs op user agent strings van geblokkeerde crawlers. Als je verzoeken ziet van crawlers die je hebt geblokkeerd, respecteren ze mogelijk je robots.txt niet. Gebruik testtools zoals de robots.txt-tester van Google Search Console of curl-commando's om je configuratie te verifiëren.
Het blokkeren van trainingscrawlers heeft doorgaans minimale impact op direct verkeer omdat ze sowieso nauwelijks voor doorverwijzingsverkeer zorgen. Het blokkeren van zoekcrawlers kan de zichtbaarheid in AI-gestuurde ontdekkingplatforms verminderen. Monitor je analytics gedurende 30 dagen na het blokkeren om het daadwerkelijke effect te meten.
Terwijl je crawler-toegang beheert met robots.txt, helpt AmICited je bij het volgen van hoe AI-systemen jouw content citeren en vermelden in hun output. Krijg volledig inzicht in je AI-aanwezigheid.
Leer hoe je AI-crawlers zoals GPTBot, PerplexityBot en ClaudeBot kunt identificeren en monitoren in je serverlogs. Ontdek user-agent strings, IP-verificatiemeth...

Leer hoe je een audit uitvoert op AI-crawler toegang tot je website. Ontdek welke bots jouw content kunnen zien en los blokkades op die AI-zichtbaarheid in Chat...

Leer hoe je AI-crawlers zoals GPTBot, ClaudeBot en PerplexityBot in je serverlogs kunt herkennen en monitoren. Volledige gids met user-agent strings, IP-verific...