
AI Crawler Referentiekaart: Alle Bots in Één Oogopslag
Compleet naslagwerk over AI crawlers en bots. Identificeer GPTBot, ClaudeBot, Google-Extended en meer dan 20 andere AI-crawlers met user agents, crawl rates en ...
16 min lezen

Uitgebreide gids voor AI-crawlers in 2025. Identificeer GPTBot, ClaudeBot, PerplexityBot en 20+ andere AI-bots. Leer hoe u crawlers kunt blokkeren, toestaan of monitoren met robots.txt en geavanceerde technieken.
AI-crawlers zijn geautomatiseerde bots die ontworpen zijn om systematisch door websites te browsen en data te verzamelen, maar hun doel is de afgelopen jaren fundamenteel veranderd. Waar traditionele zoekmachinecrawlers zoals Googlebot zich richten op het indexeren van content voor zoekresultaten, richten moderne AI-crawlers zich vooral op het verzamelen van trainingsdata voor grote taalmodellen en generatieve AI-systemen. Volgens recente gegevens van Playwire zijn AI-crawlers nu verantwoordelijk voor ongeveer 80% van al het AI-botverkeer, wat een dramatische toename betekent in het volume en de diversiteit aan geautomatiseerde bezoekers op websites. Deze verschuiving weerspiegelt de bredere transformatie in de ontwikkeling en training van kunstmatige-intelligentiesystemen, waarbij wordt afgeweken van publiek beschikbare datasets naar realtime webcontentverzameling. Het begrijpen van deze crawlers is essentieel geworden voor website-eigenaren, uitgevers en contentmakers die weloverwogen beslissingen moeten nemen over hun digitale aanwezigheid.
AI-crawlers kunnen worden ingedeeld in drie verschillende categorieën op basis van hun functie, gedrag en impact op uw website. Trainingscrawlers vormen het grootste segment en zijn goed voor ongeveer 80% van het AI-botverkeer; ze zijn ontworpen om content te verzamelen voor het trainen van machine learning-modellen en opereren doorgaans met een hoog volume en minimale verwijzingen, waardoor ze veel bandbreedte verbruiken maar weinig bezoekers naar uw site terugsturen. Zoek- en citatiecrawlers werken op een matig volume en zijn specifiek ontworpen om content te vinden en te vermelden in door AI aangedreven zoekresultaten en applicaties; in tegenstelling tot trainingscrawlers kunnen deze bots daadwerkelijk verkeer naar uw website sturen wanneer gebruikers doorklikken vanuit AI-antwoorden. Door gebruikers getriggerde fetchers vormen de kleinste categorie en werken on-demand wanneer gebruikers expliciet content opvragen via AI-applicaties zoals de browsefunctie van ChatGPT; deze crawlers hebben een laag volume maar zijn zeer relevant voor individuele gebruikersvragen.
| Categorie | Doel | Voorbeelden |
|---|---|---|
| Trainingscrawlers | Data verzamelen voor AI-modeltraining | GPTBot, ClaudeBot, Meta-ExternalAgent, Bytespider |
| Zoek-/citatiecrawlers | Content vinden en vermelden in AI-antwoorden | OAI-SearchBot, Claude-SearchBot, PerplexityBot, You.com |
| Door gebruikers getriggerde fetchers | Op aanvraag content ophalen voor gebruikers | ChatGPT-User, Claude-Web, Gemini-Deep-Research |
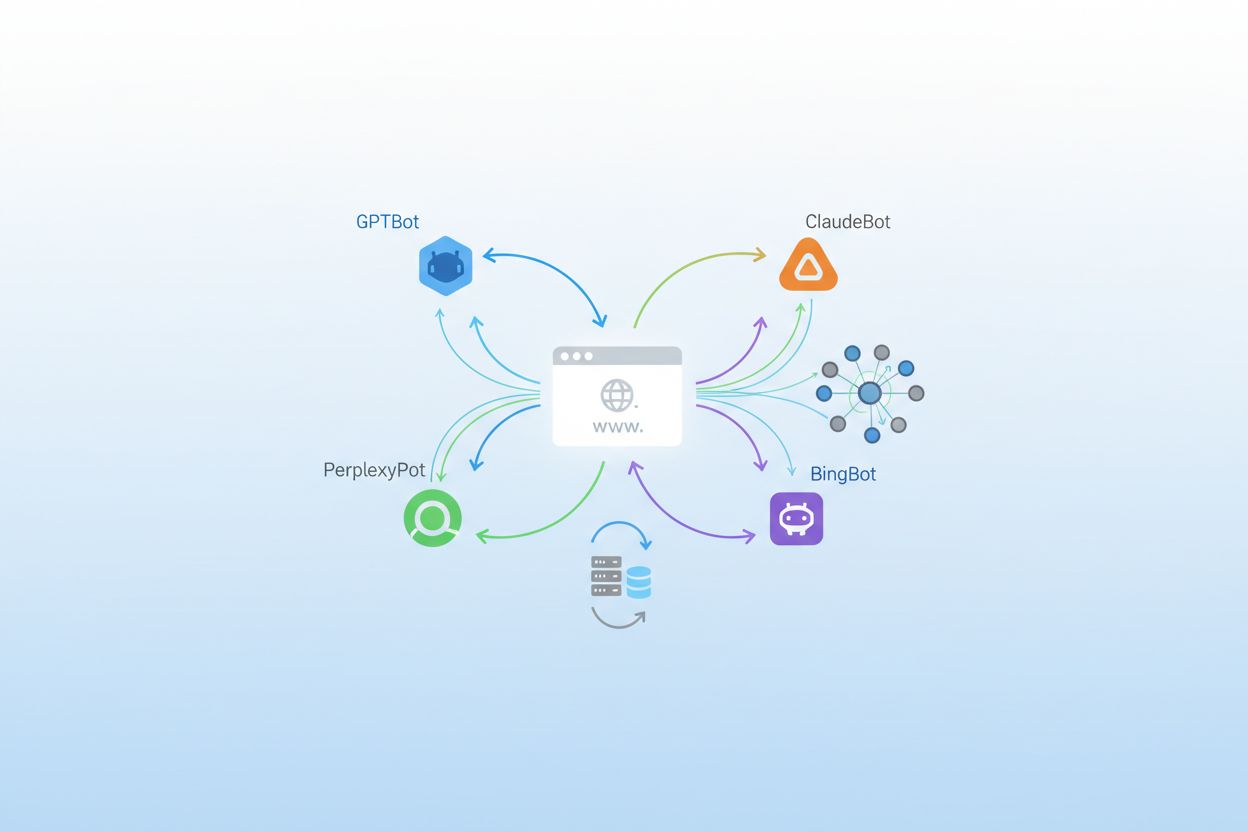
OpenAI heeft het meest diverse en agressieve crawler-ecosysteem in het AI-landschap, met meerdere bots die verschillende doelen dienen binnen hun productaanbod. GPTBot is hun primaire trainingscrawler, verantwoordelijk voor het verzamelen van content om GPT-4 en toekomstige modellen te verbeteren, en heeft volgens Cloudflare-gegevens een verbluffende 305% groei in crawlerverkeer doorgemaakt; deze bot werkt met een 400:1 crawl-to-referral ratio, wat betekent dat hij 400 keer content downloadt voor elke bezoeker die hij naar uw site terugstuurt. OAI-SearchBot heeft een volledig andere functie en richt zich op het vinden en citeren van content voor de zoekfunctie van ChatGPT zonder de content te gebruiken voor modeltraining. ChatGPT-User vertegenwoordigt de explosiefste groeicategorie, met een opmerkelijke 2.825% stijging in verkeer, en wordt geactiveerd wanneer gebruikers de functie “Browse with Bing” inschakelen om realtime content op te halen. U kunt deze crawlers herkennen aan hun user-agent strings: GPTBot/1.0, OAI-SearchBot/1.0 en ChatGPT-User/1.0. OpenAI biedt IP-verificatiemethoden om legitiem crawlerverkeer vanuit hun infrastructuur te bevestigen.
Anthropic, het bedrijf achter Claude, heeft een van de meest selectieve maar intensieve crawleroperaties in de industrie. ClaudeBot is hun primaire trainingscrawler en heeft een buitengewone 38.000:1 crawl-to-referral ratio, wat betekent dat hij content veel agressiever downloadt dan de bots van OpenAI in verhouding tot het teruggestuurde verkeer; deze extreme ratio weerspiegelt Anthropic’s focus op uitgebreide dataverzameling voor modeltraining. Claude-Web en Claude-SearchBot hebben andere doelen, waarbij de eerste zich bezighoudt met door gebruikers getriggerde contentopvraging en de tweede zich richt op zoek- en citatiefuncties. Google heeft zijn crawlerstrategie aangepast voor het AI-tijdperk door Google-Extended te introduceren, een speciale token waarmee websites kunnen kiezen voor AI-training terwijl traditionele Googlebot-indexering wordt geblokkeerd, en Gemini-Deep-Research, dat diepgaande onderzoeksqueries uitvoert voor gebruikers van Google’s AI-producten. Veel website-eigenaren twijfelen of ze Google-Extended moeten blokkeren, aangezien het afkomstig is van hetzelfde bedrijf dat het zoekverkeer beheert, wat de beslissing complexer maakt dan bij derde partijen.
Meta is een belangrijke speler geworden in de AI-crawlerwereld met Meta-ExternalAgent, die goed is voor ongeveer 19% van het AI-crawlerverkeer en wordt gebruikt om hun AI-modellen te trainen en functies aan te sturen binnen Facebook, Instagram en WhatsApp. Meta-WebIndexer heeft een aanvullende functie en richt zich op webindexering voor hun AI-functies en aanbevelingen. Apple introduceerde Applebot-Extended ter ondersteuning van Apple Intelligence, hun on-device AI-functies, en deze crawler groeit gestaag naarmate het bedrijf zijn AI-mogelijkheden uitbreidt op iPhone, iPad en Mac. Amazon gebruikt Amazonbot voor Alexa en Rufus, hun AI-shoppingassistent, waardoor deze relevant is voor e-commercesites en productgerichte content. PerplexityBot vertegenwoordigt een van de meest spectaculaire groeiverhalen in het crawlerlandschap, met een verbluffende 157.490% stijging in verkeer, wat de explosieve groei van Perplexity AI als zoekalternatief weerspiegelt; ondanks deze enorme groei vertegenwoordigt Perplexity nog steeds een lager absoluut volume dan OpenAI en Google, maar de groeilijn wijst op snel toenemend belang.
Naast de grote spelers zijn er talloze nieuwe en gespecialiseerde AI-crawlers actief die data verzamelen van websites wereldwijd. Bytespider, beheerd door ByteDance (het moederbedrijf van TikTok), kende een dramatische 85% daling in crawlerverkeer, mogelijk vanwege een strategieaanpassing of minder behoefte aan trainingsdata. Cohere, Diffbot en CCBot van Common Crawl zijn gespecialiseerde crawlers met uiteenlopende doelen, van taalmodeltraining tot gestructureerde data-extractie. You.com, Mistral en DuckDuckGo hebben elk hun eigen crawlers voor hun AI-zoek- en assistentfuncties, wat het crawlerlandschap steeds complexer maakt. Nieuwe crawlers verschijnen regelmatig, waarbij zowel startups als gevestigde bedrijven AI-producten lanceren die webdata nodig hebben. Op de hoogte blijven van deze nieuwe crawlers is cruciaal, omdat blokkeren of toestaan aanzienlijke invloed kan hebben op uw zichtbaarheid in nieuwe AI-gedreven ontdekplatforms en applicaties.
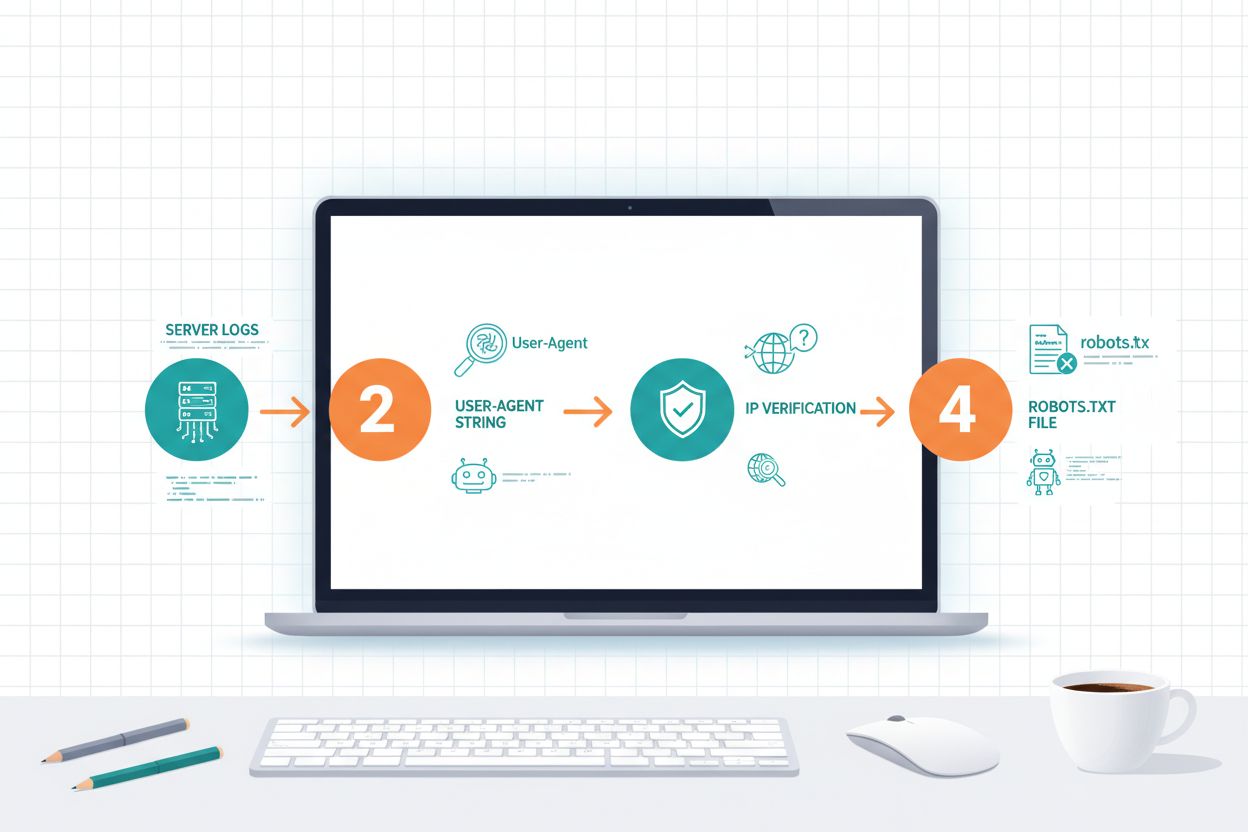
AI-crawlers herkennen vereist inzicht in hoe ze zich identificeren en het analyseren van uw serververkeer. User-agent strings zijn de belangrijkste identificatiemethode, aangezien elke crawler zich kenbaar maakt met een specifieke identificatie in HTTP-verzoeken; bijvoorbeeld, GPTBot gebruikt GPTBot/1.0, ClaudeBot gebruikt Claude-Web/1.0 en PerplexityBot gebruikt PerplexityBot/1.0. Door uw serverlogs te analyseren (meestal te vinden op /var/log/apache2/access.log op Linux-servers of IIS-logs op Windows) ziet u welke crawlers uw site bezoeken en hoe vaak. IP-verificatie is een andere belangrijke techniek, waarbij u controleert of een crawler die zich voordoet als OpenAI of Anthropic daadwerkelijk afkomstig is van hun legitieme IP-ranges, die deze bedrijven publiceren voor beveiligingsdoeleinden. Door uw robots.txt-bestand te bekijken ziet u welke crawlers u expliciet toestaat of blokkeert, en door dit te vergelijken met uw werkelijke verkeer ontdekt u of crawlers uw richtlijnen naleven. Tools zoals Cloudflare Radar bieden realtime inzicht in crawlerverkeer en helpen u bij het identificeren van de meest actieve bots op uw site. Praktische identificatiestappen zijn: uw analyseplatform controleren op botverkeer, ruwe serverlogs doorzoeken op user-agentpatronen, IP-adressen vergelijken met gepubliceerde crawler-IP-ranges en online verificatietools gebruiken om verdachte verkeersbronnen te bevestigen.
De beslissing om AI-crawlers toe te laten of te blokkeren vereist het afwegen van verschillende zakelijke overwegingen waarvoor geen standaardoplossing bestaat. De belangrijkste afwegingen zijn:
Aangezien 80% van het AI-botverkeer afkomstig is van trainingscrawlers met weinig verwijzingspotentieel, kiezen veel uitgevers ervoor om trainingscrawlers te blokkeren en zoek- en citatiecrawlers toe te staan. De uiteindelijke keuze hangt af van uw bedrijfsmodel, contenttype en strategische prioriteiten rond AI-zichtbaarheid versus resourcegebruik.
Het robots.txt-bestand is uw belangrijkste middel om crawlerrichtlijnen aan AI-bots te communiceren, hoewel het belangrijk is te beseffen dat naleving vrijwillig is en niet technisch afdwingbaar. Robots.txt gebruikt user-agent matching om specifieke crawlers te targeten, zodat u verschillende regels kunt maken voor verschillende bots; zo kunt u bijvoorbeeld GPTBot blokkeren terwijl u OAI-SearchBot toestaat, of alle trainingscrawlers blokkeren en zoekcrawlers toestaan. Volgens recent onderzoek heeft slechts 14% van de top 10.000 domeinen AI-specifieke robots.txt-regels geïmplementeerd, wat aangeeft dat de meeste websites hun crawlerbeleid nog niet hebben geoptimaliseerd voor het AI-tijdperk. Het bestand gebruikt eenvoudige syntaxis waarbij u een user-agentnaam opgeeft gevolgd door disallow- of allow-instructies, en u kunt wildcards gebruiken om meerdere crawlers met vergelijkbare naamgevingspatronen te matchen.
Hier zijn drie praktische robots.txt-configuratiescenario’s:
# Scenario 1: Blokkeer alle AI-trainingscrawlers, sta zoekcrawlers toe
User-agent: GPTBot
Disallow: /
User-agent: ClaudeBot
Disallow: /
User-agent: Meta-ExternalAgent
Disallow: /
User-agent: Amazonbot
Disallow: /
User-agent: Bytespider
Disallow: /
User-agent: OAI-SearchBot
Allow: /
User-agent: PerplexityBot
Allow: /
# Scenario 2: Blokkeer alle AI-crawlers volledig
User-agent: GPTBot
Disallow: /
User-agent: ClaudeBot
Disallow: /
User-agent: Meta-ExternalAgent
Disallow: /
User-agent: Amazonbot
Disallow: /
User-agent: Bytespider
Disallow: /
User-agent: OAI-SearchBot
Disallow: /
User-agent: PerplexityBot
Disallow: /
User-agent: Applebot-Extended
Disallow: /
# Scenario 3: Selectief blokkeren per directory
User-agent: GPTBot
Disallow: /private/
Disallow: /admin/
Allow: /public/
User-agent: ClaudeBot
Disallow: /
User-agent: OAI-SearchBot
Allow: /
Onthoud dat robots.txt slechts adviserend is en dat kwaadaardige of niet-conforme crawlers uw instructies volledig kunnen negeren. User-agent matching is niet hoofdlettergevoelig, dus gptbot, GPTBot en GPTBOT verwijzen allemaal naar dezelfde crawler, en u kunt User-agent: * gebruiken voor regels die op alle crawlers van toepassing zijn.
Naast robots.txt bieden verschillende geavanceerde methoden sterkere bescherming tegen ongewenste AI-crawlers, elk met hun eigen effectiviteit en implementatiecomplexiteit. IP-verificatie en firewallregels stellen u in staat verkeer van specifieke IP-ranges die aan AI-crawlers zijn gekoppeld te blokkeren; u kunt deze ranges vinden in de documentatie van de crawler-operators en uw firewall of Web Application Firewall (WAF) zo configureren dat verzoeken van die IP’s worden geweigerd, hoewel dit onderhoud vereist omdat IP-ranges kunnen wijzigen. .htaccess server-side blokkering biedt Apache-serverbescherming door user-agent strings en IP-adressen te controleren voordat content wordt geleverd, wat betrouwbaardere handhaving biedt dan robots.txt, omdat dit op serverniveau gebeurt en niet afhankelijk is van crawlercompliance.
Hier is een praktisch .htaccess-voorbeeld voor geavanceerde crawlerblokkering:
# Blokkeer AI-trainingscrawlers op serverniveau
<IfModule mod_rewrite.c>
RewriteEngine On
# Blokkeren op user-agent string
RewriteCond %{HTTP_USER_AGENT} (GPTBot|ClaudeBot|Meta-ExternalAgent|Amazonbot|Bytespider) [NC]
RewriteRule ^.*$ - [F,L]
# Blokkeren op IP-adres (voorbeeld-IP's - vervang door actuele crawler-IP's)
RewriteCond %{REMOTE_ADDR} ^192\.0\.2\.0$ [OR]
RewriteCond %{REMOTE_ADDR} ^198\.51\.100\.0$
RewriteRule ^.*$ - [F,L]
# Specifieke crawlers toestaan terwijl anderen worden geblokkeerd
RewriteCond %{HTTP_USER_AGENT} !OAI-SearchBot [NC]
RewriteCond %{HTTP_USER_AGENT} (GPTBot|ClaudeBot) [NC]
RewriteRule ^.*$ - [F,L]
</IfModule>
# HTML meta tag aanpak (toevoegen aan paginakoppen)
# <meta name="robots" content="noarchive, noimageindex">
# <meta name="googlebot" content="noindex, nofollow">
HTML meta tags zoals <meta name="robots" content="noarchive"> en <meta name="googlebot" content="noindex"> bieden controle op paginaniveau, maar zijn minder betrouwbaar dan server-side blokkering omdat crawlers de HTML moeten lezen om ze te zien. Houd er rekening mee dat IP-spoofing technisch mogelijk is, wat betekent dat geavanceerde actoren zich kunnen voordoen als legitieme crawler-IP’s, dus een combinatie van meerdere methoden biedt betere bescherming dan vertrouwen op slechts één aanpak. Elke methode heeft zijn voordelen: robots.txt is eenvoudig te implementeren maar niet afdwingbaar, IP-blokkering is betrouwbaar maar vereist onderhoud, .htaccess biedt handhaving op serverniveau en meta tags geven fijnmazige controle op paginaniveau.
Het implementeren van crawlerbeleid is slechts de helft van het werk; u moet actief monitoren of crawlers uw instructies opvolgen en uw strategie aanpassen op basis van feitelijke verkeerspatronen. Serverlogs zijn uw primaire databron, doorgaans te vinden op /var/log/apache2/access.log op Linux-servers of in de IIS-logs-map op Windows-servers, waar u kunt zoeken op specifieke user-agent strings om te zien welke crawlers uw site bezoeken en hoe vaak. Analyseplatforms zoals Google Analytics, Matomo of Plausible kunnen zo worden ingesteld dat botverkeer apart wordt bijgehouden van menselijk bezoek, zodat u het volume en het gedrag van verschillende crawlers in de tijd kunt zien. Cloudflare Radar biedt realtime inzicht in crawlerverkeer wereldwijd en laat zien hoe het crawlerverkeer op uw site zich verhoudt tot branchegemiddelden. Om te controleren of crawlers uw blokkades respecteren, kunt u online tools gebruiken om uw robots.txt-bestand te controleren, uw serverlogs doorzoeken op geblokkeerde user-agents en IP-adressen vergelijken met gepubliceerde crawler-IP-ranges om te bevestigen dat het verkeer daadwerkelijk van legitieme bronnen komt. Praktische monitoringstappen zijn: wekelijkse loganalyse instellen om het crawlersvolume te volgen, waarschuwingen configureren voor ongebruikelijke crawleractiviteit, uw analyse-dashboard maandelijks controleren op botverkeertrends en kwartaalreviews uitvoeren van uw crawlerbeleid om te zorgen dat deze nog steeds aansluiten bij uw bedrijfsdoelen. Door regelmatig te monitoren ontdekt u nieuwe crawlers, signaleert u beleidschendingen en kunt u datagedreven beslissingen nemen over welke crawlers u wilt toelaten of blokkeren.
Het AI-crawlerlandschap blijft zich snel ontwikkelen, met nieuwe spelers die de markt betreden en bestaande crawlers die hun mogelijkheden onverwacht uitbreiden. Nieuwe crawlers van bedrijven zoals xAI (Grok), Mistral en DeepSeek beginnen op grote schaal webdata te verzamelen, en elke nieuwe AI-startup zal waarschijnlijk een eigen crawler lanceren ter ondersteuning van modeltraining en productfuncties. Agentic browsers vormen een nieuw hoofdstuk in crawlertechnologie, met systemen zoals ChatGPT Operator en Comet die websites kunnen bedienen als menselijke gebruikers, door knoppen te klikken, formulieren in te vullen en complexe interfaces te navigeren; deze browsergebaseerde agents zijn lastig te identificeren en blokkeren met traditionele methoden. Het probleem met browsergebaseerde agents is dat ze zich mogelijk niet duidelijk identificeren in user-agent strings en IP-gebaseerde blokkades kunnen omzeilen door gebruik te maken van residentiële proxies of gedistribueerde infrastructuur. Nieuwe crawlers verschijnen regelmatig, soms zonder waarschuwing, waardoor het essentieel is om op de hoogte te blijven van ontwikkelingen in de AI-wereld en uw beleid dienovereenkomstig aan te passen. De trend wijst erop dat crawlerverkeer zal blijven toenemen, met Cloudflare die een 18% algemene stijging in crawlerverkeer rapporteert van mei 2024 tot mei 2025, en deze groei zal waarschijnlijk versnellen naarmate meer AI-applicaties mainstream worden. Website-eigenaren en uitgevers moeten waakzaam en flexibel blijven, hun crawlerbeleid regelmatig herzien en nieuwe ontwikkelingen monitoren om te zorgen dat hun strategieën effectief blijven in dit snel veranderende landschap.
Het beheren van crawlertoegang tot uw website is belangrijk, maar net zo essentieel is het begrijpen hoe uw content wordt gebruikt en geciteerd in AI-gegenereerde antwoorden. AmICited.com is een gespecialiseerd platform dat dit probleem oplost door te volgen hoe AI-crawlers uw content verzamelen en te monitoren of uw merk en content correct worden vermeld in AI-applicaties. Het platform helpt u te begrijpen welke AI-systemen uw content gebruiken, hoe vaak uw informatie voorkomt in AI-antwoorden en of er correcte bronvermelding plaatsvindt. Voor uitgevers en contentmakers biedt AmICited.com waardevolle inzichten in uw zichtbaarheid binnen het AI-ecosysteem, zodat u de impact kunt meten van uw keuze om crawlers toe te staan of te blokkeren en de daadwerkelijke waarde kunt achterhalen die u ontvangt van AI-gedreven ontdekking. Door uw citaties op meerdere AI-platforms te monitoren kunt u beter geïnformeerde beslissingen nemen over uw crawlerbeleid, kansen identificeren om de zichtbaarheid van uw content in AI-antwoorden te verbeteren en zorgen dat uw intellectueel eigendom correct wordt toegeschreven. Als u serieus wilt weten hoe uw merk aanwezig is op het AI-web, biedt AmICited.com de transparantie en monitoring die u nodig heeft om geïnformeerd te blijven en de waarde van uw content te beschermen in dit nieuwe tijdperk van AI-gestuurde ontdekking.
Trainingscrawlers zoals GPTBot en ClaudeBot verzamelen content om datasets op te bouwen voor de ontwikkeling van grote taalmodellen, waardoor ze deel uitmaken van de kennisbasis van de AI. Zoekcrawlers zoals OAI-SearchBot en PerplexityBot indexeren content voor door AI aangedreven zoekervaringen en kunnen via citaties verwijzingsverkeer terugsturen naar uitgevers.
Dit hangt af van uw zakelijke prioriteiten. Door trainingscrawlers te blokkeren beschermt u uw content tegen opname in AI-modellen. Het blokkeren van zoekcrawlers kan uw zichtbaarheid op door AI aangedreven ontdekplatforms zoals ChatGPT search of Perplexity verminderen. Veel uitgevers kiezen voor selectieve blokkering die trainingscrawlers aanpakt en zoek- en citatiecrawlers toestaat.
De meest betrouwbare verificatiemethode is het controleren van het verzoek-IP-adres aan de hand van officieel gepubliceerde IP-ranges van crawler-operators. Grote bedrijven zoals OpenAI, Anthropic en Amazon publiceren hun crawler-IP-adressen. U kunt ook firewallregels gebruiken om geverifieerde IP’s op een allowlist te plaatsen en verzoeken van niet-geverifieerde bronnen die zich als AI-crawlers voordoen te blokkeren.
Google geeft officieel aan dat het blokkeren van Google-Extended geen invloed heeft op zoekrangschikkingen of opname in AI Overviews. Sommige webmasters hebben echter hun zorgen geuit, dus houd uw zoekprestaties in de gaten na het doorvoeren van blokkades. AI Overviews in Google Search volgen de standaard Googlebot-regels, niet Google-Extended.
Nieuwe AI-crawlers verschijnen regelmatig, dus bekijk en update uw blocklist minimaal elk kwartaal. Volg bronnen zoals het ai.robots.txt project op GitHub voor door de community onderhouden lijsten. Controleer maandelijks uw serverlogs om nieuwe crawlers te identificeren die uw site bezoeken maar nog niet in uw configuratie staan.
Ja, robots.txt is adviserend en niet afdwingbaar. Goedgedragende crawlers van grote bedrijven respecteren doorgaans robots.txt-directieven, maar sommige crawlers negeren ze. Voor sterkere bescherming kunt u server-side blokkering toepassen via .htaccess of firewallregels, en legitieme crawlers verifiëren aan de hand van gepubliceerde IP-adresranges.
AI-crawlers kunnen aanzienlijke serverbelasting en bandbreedteverbruik veroorzaken. Sommige infrastructuurprojecten meldden dat het blokkeren van AI-crawlers het bandbreedteverbruik verminderde van 800GB naar 200GB per dag, wat een besparing van ongeveer $1.500 per maand opleverde. Uitgevers met veel verkeer kunnen aanzienlijke kostenreducties zien door selectieve blokkering.
Controleer uw serverlogs (meestal op /var/log/apache2/access.log op Linux) op user-agent strings die overeenkomen met bekende crawlers. Gebruik analysetools zoals Google Analytics of Cloudflare Radar om botverkeer apart te volgen. Stel waarschuwingen in bij ongebruikelijke crawleractiviteit en voer kwartaalreviews uit van uw crawlerbeleid.
Volg hoe AI-platforms zoals ChatGPT, Perplexity en Google AI Overviews uw content vermelden. Ontvang realtime meldingen wanneer uw merk wordt genoemd in AI-gegenereerde antwoorden.
Compleet naslagwerk over AI crawlers en bots. Identificeer GPTBot, ClaudeBot, Google-Extended en meer dan 20 andere AI-crawlers met user agents, crawl rates en ...

Ontdek hoe je strategische beslissingen neemt over het blokkeren van AI-crawlers. Evalueer inhoudstype, verkeersbronnen, verdienmodellen en concurrentiepositie ...

Leer hoe je noai- en noimageai-meta tags implementeert om AI-crawler-toegang tot je website-inhoud te beheren. Complete gids voor AI-toegangscontroleheaders en ...