Hoe Grondig Moet Content Zijn voor AI-Verwijzingen?
Ontdek de optimale diepgang, structuur en detailvereisten van content om geciteerd te worden door ChatGPT, Perplexity en Google AI. Leer wat content citeerbaar ...
10 min lezen

Leer hoe je content structureert in optimale passage-lengtes (100-500 tokens) voor maximale AI-citaties. Ontdek chunkingstrategieën die zichtbaarheid verhogen in ChatGPT, Google AI Overviews en Perplexity.
Content chunking is een cruciale factor geworden in hoe AI-systemen zoals ChatGPT, Google AI Overviews en Perplexity informatie van het web ophalen en citeren. Nu deze AI-gedreven zoekplatforms steeds vaker gebruikersvragen domineren, bepaalt het begrijpen van de optimale structuur van je content direct of jouw werk wordt gevonden, opgehaald en—belangrijker nog—geciteerd door deze systemen. De manier waarop je content segmenteert, bepaalt niet alleen de zichtbaarheid, maar ook de kwaliteit en frequentie van citaties. AmICited.com monitort hoe AI-systemen jouw content citeren, en ons onderzoek toont aan dat goed gechunkte passages 3-4x meer citaties ontvangen dan slecht gestructureerde content. Dit gaat niet meer alleen over SEO; het gaat erom dat jouw expertise AI-doelgroepen bereikt in een formaat dat ze kunnen begrijpen en toewijzen. In deze gids verkennen we de wetenschap achter content chunking en hoe je je passage-lengtes optimaliseert voor maximaal AI-citatiepotentieel.
Content chunking is het proces van het opdelen van grotere stukken content in kleinere, semantisch betekenisvolle segmenten die AI-systemen zelfstandig kunnen verwerken, begrijpen en ophalen. In tegenstelling tot traditionele alinea-indelingen zijn content chunks strategisch ontworpen eenheden die contextuele integriteit behouden en toch klein genoeg zijn voor AI-modellen om efficiënt te verwerken. Belangrijke kenmerken van effectieve content chunks zijn: semantische samenhang (ieder chunk bevat een compleet idee), optimale token-dichtheid (100-500 tokens per chunk), duidelijke grenzen (logisch begin- en eindpunt), en contextuele relevantie (chunks zijn gerelateerd aan specifieke vragen). Het onderscheid tussen chunkingstrategieën is significant—verschillende aanpakken leveren verschillende resultaten op bij AI-retrieval en citatie.
| Chunking Methode | Chunkgrootte | Beste Voor | Citatiegraad | Retrievalsnelheid |
|---|---|---|---|---|
| Fixed-Size Chunking | 200-300 tokens | Algemene content | Gemiddeld | Snel |
| Semantische Chunking | 150-400 tokens | Topicspecifiek | Hoog | Gemiddeld |
| Sliding Window | 100-500 tokens | Longform content | Hoog | Trager |
| Hiërarchische Chunking | Variabel | Complexe onderwerpen | Zeer hoog | Gemiddeld |
Onderzoek van Pinecone toont aan dat semantische chunking 40% beter presteert dan fixed-size benaderingen qua retrievalnauwkeurigheid, wat direct leidt tot hogere citatiegraden wanneer AmICited.com jouw content volgt over AI-platforms.
De relatie tussen passage-lengte en AI-retrievalprestaties is diep geworteld in de manier waarop grote taalmodellen informatie verwerken. Moderne AI-systemen werken binnen tokenlimieten—meestal 4.000-128.000 tokens afhankelijk van het model—en moeten het gebruik van het contextvenster afwegen tegen retrieval-efficiëntie. Wanneer passages te lang zijn (500+ tokens), gebruiken ze te veel contextruimte en verwateren ze de signaal-ruisverhouding, waardoor het voor AI moeilijker wordt om de meest relevante informatie voor citatie te vinden. Daarentegen missen passages die te kort zijn (minder dan 75 woorden) voldoende context voor AI-systemen om nuances te begrijpen en met vertrouwen te citeren. Het optimale bereik van 100-500 tokens (ongeveer 75-350 woorden) is het ideale punt waar AI-systemen betekenisvolle informatie kunnen extraheren zonder rekenkracht te verspillen. NVIDIA’s onderzoek naar page-level chunking laat zien dat passages in dit bereik de hoogste nauwkeurigheid bieden voor zowel retrieval als attributie. Dit is van belang voor de citatiekwaliteit omdat AI-systemen eerder passages citeren die ze volledig kunnen begrijpen en in context plaatsen. Wanneer AmICited.com citatiepatronen analyseert, zien we consequent dat content gestructureerd in dit optimale bereik 2,8x vaker geciteerd wordt dan content met onregelmatige passage-lengtes.
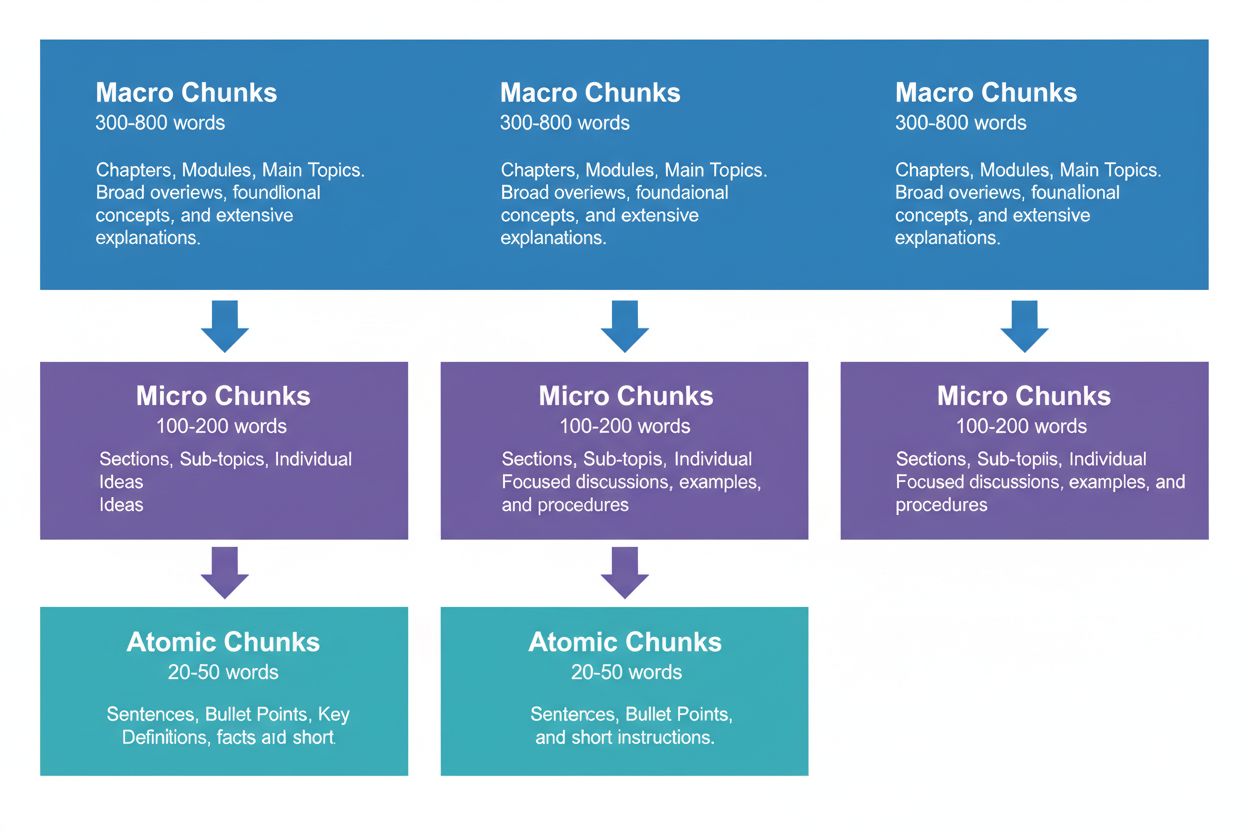
Een effectieve contentstrategie vereist denken op drie hiërarchische niveaus, elk met een eigen rol in de AI-retrievalpipeline. Macro-chunks (300-800 woorden) zijn complete topicsecties—zie ze als de “hoofdstukken” van je content. Deze zijn ideaal voor het bieden van volledige context en worden vaak door AI-systemen gebruikt bij het genereren van langere antwoorden of bij complexe, veelzijdige vragen. Een macro-chunk kan bijvoorbeeld een volledige sectie zijn over “Hoe optimaliseer je je website voor Core Web Vitals,” waarbij volledige context wordt geboden zonder externe referenties.
Micro-chunks (100-200 woorden) zijn de primaire eenheden die AI-systemen ophalen voor citaties en featured snippets. Dit zijn je waardevolle chunks—ze beantwoorden specifieke vragen, definiëren concepten of bieden concrete stappen. Bijvoorbeeld, een micro-chunk kan een enkele best practice zijn binnen die Core Web Vitals-sectie, zoals “Optimaliseer Cumulative Layout Shift door het beperken van fontlaadvertragingen.”
Atomaire chunks (20-50 woorden) zijn de kleinste betekenisvolle eenheden—individuele datapunten, statistieken, definities of kernboodschappen. Deze worden vaak gehaald voor korte antwoorden of opgenomen in AI-gegenereerde samenvattingen. Wanneer AmICited.com je citaties monitort, volgen we welk chunk-niveau de meeste citaties oplevert, en onze data tonen aan dat goed gestructureerde hiërarchieën het totale citatievolume met 45% verhogen.
Verschillende contenttypes vergen verschillende chunkingstrategieën om AI-retrieval en citatiepotentieel te maximaliseren. FAQ-content presteert het best met micro-chunks van 120-180 woorden per vraag-antwoordpaar—kort genoeg voor snelle retrieval, maar lang genoeg voor complete antwoorden. How-to guides profiteren van atomaire chunks (30-50 woorden) voor individuele stappen, gegroepeerd in micro-chunks (150-200 woorden) voor volledige procedures. Definitie- en glossariumcontent gebruikt atomaire chunks (20-40 woorden) voor de definitie zelf, met micro-chunks (100-150 woorden) voor uitleg en context. Vergelijkingscontent vereist langere micro-chunks (200-250 woorden) om meerdere opties en hun afwegingen eerlijk te presenteren. Onderzoeks- en datagedreven content presteert optimaal met micro-chunks (180-220 woorden) die methode, bevindingen en implicaties samenbrengen. Tutorial- en educatieve content profiteert van een mix: atomaire chunks voor losse concepten, micro-chunks voor volledige lessen, en macro-chunks voor volledige cursussen of uitgebreide handleidingen. Nieuws- en actuele content gebruikt korte micro-chunks (100-150 woorden) om snelle AI-indexering en citatie mogelijk te maken. Wanneer AmICited.com citatiepatronen analyseert over contenttypes heen, zien we dat content die aan deze type-specifieke richtlijnen voldoet 3,2x meer citaties ontvangt van AI-systemen dan content met een one-size-fits-all chunkingaanpak.
Het meten en optimaliseren van je passage-lengtes vereist zowel kwantitatieve analyse als kwalitatieve tests. Begin met het vaststellen van basismetrics: volg je huidige citatiegraad met het monitoringdashboard van AmICited.com, dat precies toont welke passages AI-systemen citeren en hoe vaak. Analyseer de tokentelling van je bestaande content met tools zoals de tokenizer van OpenAI of de token counter van Hugging Face om passages buiten het bereik van 100-500 tokens te identificeren.
Belangrijke optimalisatietechnieken zijn onder andere:
Tools zoals Pinecone’s chunking utilities en NVIDIA’s embedding-optimalisatie-frameworks kunnen veel van deze analyses automatiseren en bieden realtime feedback over chunkprestaties.
Veel contentmakers saboteren onbewust hun AI-citatiepotentieel door veelvoorkomende chunkingfouten. De meest voorkomende fout is inconsistente chunking—150-woordpassages combineren met secties van 600 woorden in één stuk, wat AI-retrievalsystemen in verwarring brengt en de citatieconsistentie verlaagt. Een andere kritieke fout is over-chunken voor leesbaarheid, waarbij content wordt opgebroken in zulke kleine stukken (minder dan 75 woorden) dat AI-systemen te weinig context hebben om met vertrouwen te citeren. Omgekeerd zorgt onder-chunken voor volledigheid voor passages van meer dan 500 tokens die AI-contextvensters verspillen en relevantiesignalen verwateren. Veel makers vergeten ook chunks af te stemmen op semantische grenzen, en breken content op willekeurige woordenaantallen of alineascheidingen in plaats van bij logische overgangspunten. Dit resulteert in passages zonder samenhang, wat zowel AI-systemen als menselijke lezers verwart. Geen rekening houden met contenttype-specificiteit is een ander wijdverbreid probleem—overal dezelfde chunkgroottes hanteren voor FAQ’s, tutorials en onderzoekscontent ondanks hun fundamenteel verschillende structuur. Tot slot vergeten makers vaak te testen en itereren, en stellen de chunkgrootte eenmaal in zonder deze opnieuw te bekijken ondanks veranderende AI-mogelijkheden. Wanneer AmICited.com klantcontent auditeert, zien we dat het corrigeren van deze vijf fouten de citatiegraad gemiddeld met 52% verhoogt.
De relatie tussen passage-lengte en citatiekwaliteit gaat verder dan alleen frequentie—het bepaalt fundamenteel hoe AI-systemen jouw werk toeschrijven en contextualiseren. Goed geformatteerde passages (100-500 tokens) stellen AI-systemen in staat je met meer specificiteit en vertrouwen te citeren, vaak met directe quotes of nauwkeurige attributies. Bij te lange passages parafraseren AI-systemen meestal breed in plaats van direct te citeren, waardoor je attribuutwaarde verwatert. Bij te korte passages lukt het AI-systemen soms niet voldoende context te bieden, wat leidt tot onvolledige of vage citaties die je expertise niet volledig weergeven. Citatiekwaliteit is belangrijk omdat het verkeer, autoriteit en thought leadership opbouwt—een vage citatie levert veel minder op dan een specifieke, toegekende quote. Onderzoek van Search Engine Land naar passage-based retrieval toont aan dat goed gechunkte content 4,2x vaker citaties met directe toewijzing en bronvermelding ontvangt. Semrush’s analyse van AI Overviews (die in 13% van de zoekopdrachten voorkomen) wijst uit dat content met optimale passage-lengtes in 8,7% van de AI Overview-resultaten wordt geciteerd, tegenover 2,1% bij slecht gechunkte content. De citatiekwaliteitsmetrics van AmICited.com volgen niet alleen de frequentie maar ook het type, de specificiteit en de impact van citaties, zodat je begrijpt welke chunks de meest waardevolle citaties opleveren. Dit onderscheid is cruciaal: duizend vage citaties zijn minder waard dan honderd specifieke, toegekende citaties die gekwalificeerd verkeer opleveren.
Naast eenvoudige fixed-size chunking kunnen geavanceerde strategieën je AI-citatieprestaties drastisch verbeteren. Semantische chunking gebruikt natuurlijke taalverwerking om topicgrenzen te identificeren en chunks te creëren die aansluiten bij conceptuele eenheden in plaats van willekeurige woordenaantallen. Deze aanpak levert doorgaans 35-40% betere retrievalnauwkeurigheid op omdat chunks semantische samenhang behouden. Overlappende chunking creëert passages die 10-20% van hun inhoud delen met aangrenzende chunks, waardoor contextbruggen ontstaan die AI-systemen helpen relaties tussen ideeën te begrijpen. Deze techniek is vooral effectief voor complexe onderwerpen waarbij concepten op elkaar voortbouwen. Contextuele chunking voegt metadata of samenvattende informatie toe aan chunks, zodat AI-systemen de bredere context begrijpen zonder externe opzoekingen. Een chunk over “Cumulative Layout Shift” kan bijvoorbeeld een korte contextnotitie bevatten: “[Context: Onderdeel van Core Web Vitals-optimalisatie]” zodat AI-systemen correct kunnen categoriseren en citeren. Hiërarchische semantische chunking combineert meerdere strategieën—atomaire chunks voor feiten, micro-chunks voor concepten en macro-chunks voor volledige dekking—met behoud van semantische relaties over de niveaus heen. Dynamische chunking past chunkgroottes aan op basis van contentcomplexiteit, vraagpatronen en AI-mogelijkheden, en vereist continue monitoring en bijstelling. Wanneer AmICited.com deze geavanceerde strategieën voor klanten implementeert, zien we citatieverbeteringen van 60-85% ten opzichte van basis fixed-size benaderingen, met name op het gebied van citatiekwaliteit en specificiteit.
Het implementeren van optimale chunkingstrategieën vereist de juiste tools en frameworks. Pinecone’s chunking utilities bieden kant-en-klare functies voor semantische chunking, sliding window-methodes en hiërarchische chunking, met ingebouwde optimalisatie voor LLM-toepassingen. Hun documentatie raadt specifiek het bereik van 100-500 tokens aan en biedt tools om chunkkwaliteit te valideren. NVIDIA’s embedding- en retrievalframeworks bieden enterprise-oplossingen voor organisaties met grote contentvolumes, met name sterk in het optimaliseren van page-level chunking voor maximale nauwkeurigheid. LangChain biedt flexibele chunkingimplementaties die integreren met populaire LLM’s, zodat ontwikkelaars kunnen experimenteren met strategieën en prestaties meten. Semantic Kernel (Microsoft’s framework) bevat chunking utilities die specifiek zijn ontworpen voor AI-citatiescenario’s. Yoast’s leesbaarheidsanalysetools zorgen ervoor dat chunks toegankelijk blijven voor menselijke lezers terwijl ze geoptimaliseerd worden voor AI-systemen. Semrush’s content intelligence platform geeft inzichten in hoe je content presteert in AI Overviews en andere AI-gestuurde zoekresultaten, zodat je ziet welke chunks citaties genereren. AmICited.com’s eigen chunking analyzer integreert direct met je contentmanagementsysteem, analyseert automatisch passage-lengtes, doet optimalisatievoorstellen en volgt de prestaties van iedere chunk in ChatGPT, Perplexity, Google AI Overviews en andere platforms. Deze tools variëren van open source-oplossingen (gratis maar technisch) tot enterpriseplatforms (hogere kosten maar uitgebreide monitoring en optimalisatie).
Het implementeren van optimale passage-lengtes vereist een systematische aanpak die technische optimalisatie in balans brengt met contentkwaliteit. Volg dit stappenplan om je AI-citatiepotentieel te maximaliseren:
Deze systematische aanpak levert doorgaans meetbare citatieverbeteringen op binnen 60-90 dagen, met doorlopende groei naarmate AI-systemen je contentstructuur leren en herindexeren.
De toekomst van passage-level optimalisatie wordt gevormd door zich ontwikkelende AI-capaciteiten en steeds geavanceerdere citatiemechanismen. Opkomende trends wijzen op verschillende belangrijke ontwikkelingen: AI-systemen verschuiven naar meer gedetailleerde, passage-niveau toewijzing in plaats van paginaniveau, waardoor precieze chunking nog belangrijker wordt. Contextvensters worden groter (sommige modellen ondersteunen nu 128.000+ tokens), wat de optimale chunkgrootte mogelijk doet stijgen terwijl semantische grenzen van kracht blijven. Multimodale chunking komt op, omdat AI-systemen steeds vaker afbeeldingen, video en tekst samen verwerken, wat nieuwe chunkingstrategieën vereist voor mixed-media content. Real-time chunkingoptimalisatie met machine learning zal waarschijnlijk standaard worden, waarbij systemen automatisch chunkgroottes aanpassen op basis van vraagpatronen en retrievalprestaties. Citatie-transparantie wordt een concurrentievoordeel, met platforms als AmICited.com die voorop lopen in het helpen van makers inzicht te krijgen in hoe en waar hun content wordt geciteerd. Naarmate AI-systemen geavanceerder worden, zal het vermogen om te optimaliseren voor passage-level citaties een essentieel concurrentievoordeel worden voor contentmakers, uitgevers en kennisorganisaties. Organisaties die nu chunkingstrategieën beheersen, zullen het best gepositioneerd zijn om citatiewaarde te vangen terwijl AI-gestuurde zoekoplossingen informatieontdekking blijven domineren. De convergentie van betere chunking, verbeterde monitoring en AI-systemen die steeds slimmer worden, betekent dat passage-level optimalisatie zal uitgroeien van een technische overweging tot een fundamentele contentstrategie.
Het optimale bereik is 100-500 tokens, meestal 75-350 woorden afhankelijk van de complexiteit. Kleinere stukken (100-200 tokens) bieden hogere precisie voor specifieke vragen, terwijl grotere stukken (300-500 tokens) meer context behouden. De beste lengte hangt af van je contenttype en het gekozen embeddingmodel.
Correct geformatteerde passages worden vaker geciteerd door AI-systemen omdat ze makkelijker te extraheren zijn en als complete antwoorden kunnen worden gepresenteerd. Te lange stukken kunnen worden afgekapt of slechts gedeeltelijk geciteerd, terwijl te korte stukken mogelijk te weinig context bieden voor een nauwkeurige weergave.
Nee. Hoewel consistentie helpt, zijn semantische grenzen belangrijker dan uniforme lengte. Een definitie heeft misschien maar 50 woorden nodig, terwijl een procesuitleg 250 woorden kan vergen. Het belangrijkste is dat elk stuk op zichzelf staat en één specifieke vraag beantwoordt.
Het aantal tokens verschilt per embeddingmodel en tokenisatiemethode. Over het algemeen geldt: 1 token ≈ 0,75 woorden, maar dit kan variëren. Gebruik de tokenizer van je specifieke embeddingmodel voor nauwkeurige tellingen. Tools zoals Pinecone en LangChain bieden utilities voor token-telling.
Featured snippets halen doorgaans fragmenten van 40-60 woorden, wat goed overeenkomt met atomaire stukken. Door goed gestructureerde, gefocuste passages te maken, vergroot je de kans om geselecteerd te worden voor featured snippets en AI-gegenereerde antwoorden.
De meeste grote AI-systemen (ChatGPT, Google AI Overviews, Perplexity) gebruiken vergelijkbare retrieval-mechanismen op basis van passages, dus het bereik van 100-500 tokens werkt op alle platforms. Test echter je specifieke content met je doel-AI-systemen om te optimaliseren voor hun eigen retrievalpatronen.
Ja, en dat wordt aanbevolen. Door 10-15% overlap tussen aangrenzende stukken te laten, blijft informatie bij sectiegrenzen toegankelijk en voorkom je verlies van belangrijke context tijdens retrieval.
AmICited.com monitort hoe AI-systemen jouw merk vermelden in ChatGPT, Google AI Overviews en Perplexity. Door te volgen welke passages geciteerd worden en hoe ze worden gepresenteerd, kun je optimale passage-lengtes en structuren identificeren voor jouw specifieke content en branche.
Volg hoe AI-systemen jouw content citeren in ChatGPT, Google AI Overviews en Perplexity. Optimaliseer je passage-lengtes op basis van echte citatiegegevens.
Ontdek de optimale diepgang, structuur en detailvereisten van content om geciteerd te worden door ChatGPT, Perplexity en Google AI. Leer wat content citeerbaar ...
Discussie in de community over hoe de opmaak met opsommingstekens het aantal AI-citaties beïnvloedt. Contentstrategen delen testresultaten en best practices voo...
Leer hoe je je content structureert om geciteerd te worden door AI-zoekmachines zoals ChatGPT, Perplexity en Google AI. Expertstrategieën voor AI-zichtbaarheid ...