Informatiedichtheid
Leer wat informatiedichtheid is en hoe het de kans op AI-citaties vergroot. Ontdek praktische technieken om inhoud te optimaliseren voor AI-systemen zoals ChatG...
16 min lezen

Leer hoe je informatiedichte content maakt waar AI-systemen de voorkeur aan geven. Beheers de Uniform Information Density-hypothese en optimaliseer je content voor AI Overviews, LLM’s en betere citaties.
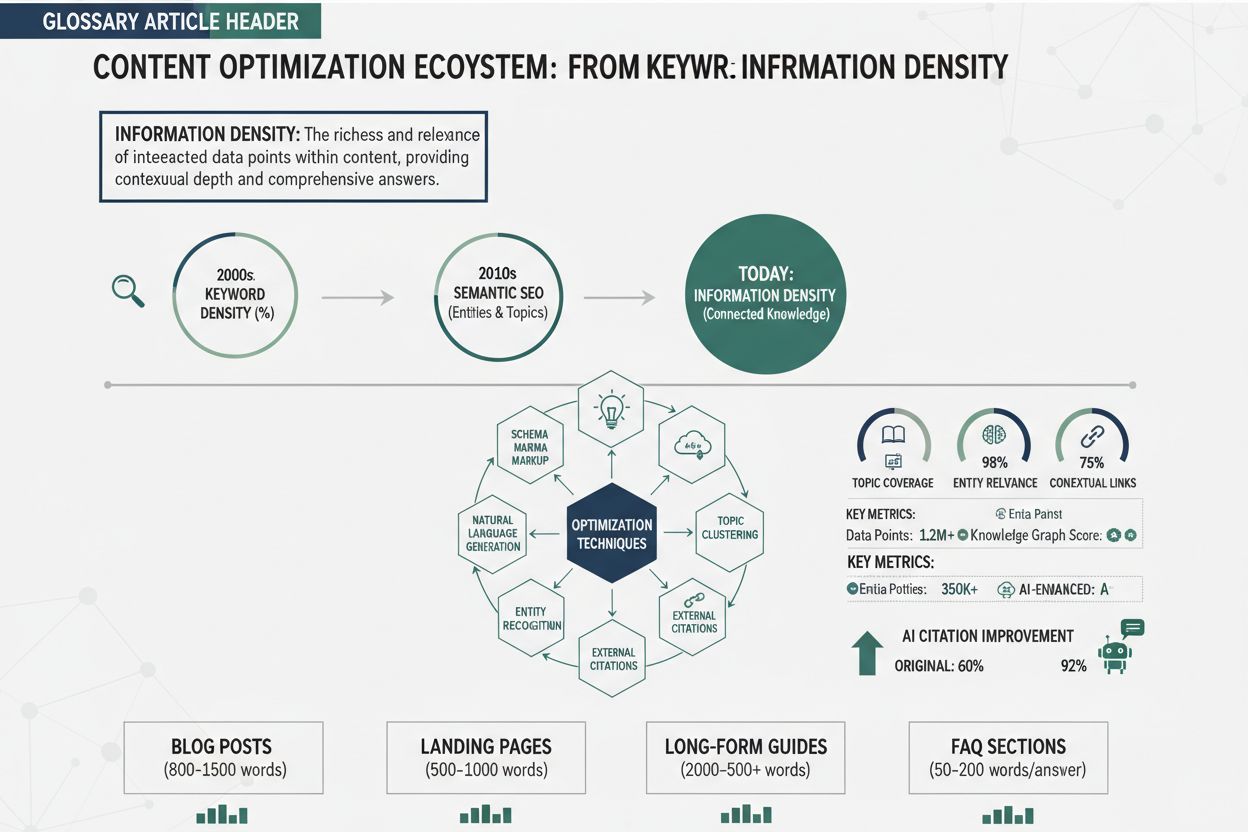
Informatiedichtheid verwijst naar de concentratie van betekenisvolle, direct toepasbare inzichten binnen een stuk content—hoeveel waarde er in elk woord, elke zin of alinea verpakt zit. Dit concept is steeds belangrijker geworden in het tijdperk van AI-gestuurd zoeken, vooral met de opkomst van Large Language Models (LLM’s) en AI Overviews. De Uniform Information Density (UID) hypothese, een taalkundig principe ondersteund door recent ArXiv-onderzoek, suggereert dat mensen en AI-systemen informatie effectiever verwerken wanneer de cognitieve belasting gelijkmatig over de content is verdeeld, in plaats van geconcentreerd in losse secties. Voor AI-systemen die content beoordelen, beïnvloedt informatiedichtheid direct hoe waarschijnlijk het is dat jouw content geselecteerd, geciteerd en gerankt wordt in AI-zoekresultaten. Wanneer je waardevolle content creëert, schrijf je niet alleen voor menselijke lezers—je optimaliseert voor hoe LLM’s informatie uit je werk halen, synthetiseren en refereren.
LLM’s beoordelen contentdichtheid via meerdere geavanceerde mechanismen die veel verder gaan dan simpele woordentellingen of keyword-frequentie. Deze systemen analyseren content-metrieken met entropie-gebaseerde berekeningen die meten hoeveel informatie wordt overgebracht ten opzichte van de totale tekstlengte, waarbij wordt gekeken naar wat onderzoekers “step-level uniformity” noemen—de consistentie van informatiedistributie over opeenvolgende secties van je content. Wanneer een LLM je artikel verwerkt, berekent het de informatiewinst bij elk token en beoordeelt het of je consistente waarde levert of dat bepaalde secties overbodig, zijdelings of van lage waarde zijn. Verschillende beoordelingskaders geven prioriteit aan verschillende aspecten van contentkwaliteit, zoals blijkt uit onderstaande vergelijking:
| Metriek | Wat het Meet | AI-relevantie | Beste Voor |
|---|---|---|---|
| BLEU Score | Precisie van woordovereenkomsten | Lagere relevantie voor dichtheid | Machinevertaling evaluatie |
| ROUGE Score | Overlap van contentherkenning | Gemiddelde relevantie | Samenvattingskwaliteit |
| Perplexity | Voorspelbaarheid van tekstreeksen | Hoge relevantie | LLM-zekerheidsbeoordeling |
| Informatiedichtheid | Betekenisvolle content per eenheid lengte | Hoogste relevantie | AI-citatie en selectie |
Inzicht in deze LLM-beoordelingskaders helpt je te begrijpen dat AI-systemen niet alleen zoeken naar uitgebreide content—ze zoeken naar content die consistente informatiewaarde behoudt, en vermijden zo de veelvoorkomende valkuil van opvulling of vulling die je boodschap verwatert.
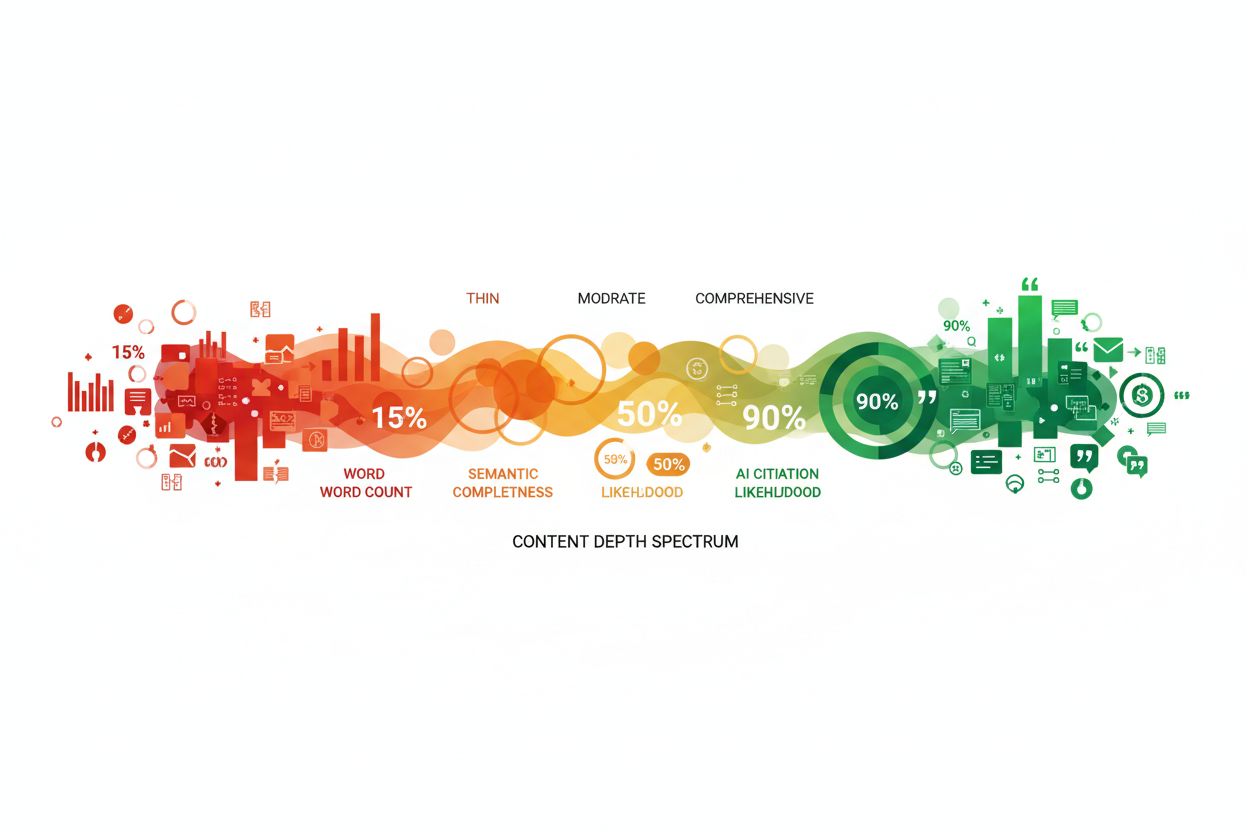
Het onderscheid tussen dichte content en dunne content bepaalt fundamenteel hoe AI-systemen met jouw materiaal omgaan. Dichte content levert veel informatie met weinig opvulling, terwijl dunne content veel herhaling, vulling of weinig waardevolle uitwijdingen bevat. Overweeg deze belangrijke verschillen:
Een praktisch voorbeeld: een dun artikel over AI-contentoptimalisatie zou drie alinea’s besteden aan uitleg wat AI is, dan nog drie aan waarom content belangrijk is, en pas daarna ingaan op optimalisatietechnieken. Een dichte content-versie zou uitgaan van basiskennis, context natuurlijk integreren en proportioneel ruimte geven aan direct toepasbare strategieën. AI-systemen herkennen en belonen deze efficiëntie omdat het aantoont dat de auteur het onderwerp voldoende beheerst om het kernachtig over te brengen.
Informatiedichtheid is uitgegroeid tot een kritisch rankingsignaal in AI-gestuurde zoekomgevingen, dat direct beïnvloedt of jouw content in AI Overviews verschijnt en hoe vaak het geciteerd wordt door AI-systemen. Onderzoek van BrightEdge naar AI-algoritmes toont aan dat content die geselecteerd wordt voor AI Overviews ongeveer 40% hogere informatiedichtheidsscores behaalt dan niet-geselecteerde content, wat suggereert dat AI-systemen actief de voorkeur geven aan dichte, waardevolle content bij het synthetiseren van antwoorden. De relatie tussen informatiedichtheid en citatiefrequentie is vooral belangrijk vanuit het perspectief van AmICited.com: wanneer AI-systemen zoals Perplexity of Google’s AI Overviews bronnen moeten vermelden, citeren ze bij voorkeur content die geconcentreerde waarde biedt, omdat dit de noodzaak voor meerdere bronverwijzingen om een enkele vraag volledig te beantwoorden, vermindert. Content met hoge informatiedichtheid scoort meestal ook beter omdat het gebruikersintentie vollediger vervult—AI-systemen herkennen dat dichte content meer volledige antwoorden biedt, waardoor de kans dat gebruikers andere bronnen moeten raadplegen kleiner wordt. Bovendien beoordelen AI Overviews-algoritmes specifiek of content effectief samengevat en gesynthetiseerd kan worden, en dichte content is van nature beter samen te vatten omdat het minder overbodige elementen bevat die tijdens het syntheseproces weggefilterd moeten worden.
Het creëren van waardevolle content vereist bewuste structurele en redactionele keuzes die informatiedoorvoer boven woordenaantal stellen. Begin met een kritische audit van je bestaande content: identificeer elke zin die niet bijdraagt aan je kernboodschap of direct toepasbare waarde biedt, en verwijder deze of integreer hem in omliggende zinnen die meerdere doelen dienen. Gebruik gestructureerde content-formats—genummerde lijsten, vergelijkende tabellen, hiërarchische koppen en definitie-secties—waardoor lezers en AI-systemen snel kerninformatie kunnen halen zonder verhalende proza te hoeven ontleden. Implementeer het principe “één idee per alinea”, zodat elke sectie een duidelijk doel heeft en haar boodschap niet verwatert met zijdelingse informatie; dit ondersteunt direct de UID-hypothese door cognitieve belasting gelijkmatig te verdelen. Leg je complexe concepten uit, gebruik dan progressieve onthulling: introduceer eerst de essentie, voeg vervolgens ondersteunende details, voorbeelden en nuance toe—dit werkt voor zowel menselijke lezers als LLM’s die content op verschillende informatieniveaus kunnen extraheren. Neem specifieke datapunten, statistieken en concrete voorbeelden op in plaats van abstracte generalisaties; “ongeveer 40% hogere informatiedichtheid” is waardevoller voor AI-systemen dan “aanzienlijk hogere dichtheid”. Optimaliseer tot slot je contentoptimalisatie-proces door informatiedichtheid als primaire maatstaf te behandelen, naast traditionele SEO-factoren—beoordeel concepten specifiek op de vraag of elke sectie kan worden ingekort, gecombineerd of verwijderd zonder essentiële waarde te verliezen.
Het meten van informatiedichtheid vraagt om inzicht in zowel theoretische kaders als praktische tools voor contentmakers. De meest directe aanpak is het berekenen van een informatiedichtheidsscore met entropie-gebaseerde metrieken: deel de totale informatie-inhoud (gemeten in bits of via semantische analyse) door het totale aantal woorden om te bepalen hoeveel betekenisvolle informatie je per tekstdeel levert. Diverse tools helpen bij deze beoordeling: natural language processing-platforms kunnen semantische diversiteit en conceptverdeling analyseren, leesbaarheidstools kunnen patronen van redundantie opsporen, en eigen scripts met Python-bibliotheken als NLTK kunnen entropiemetingen uitvoeren op je content. Een praktisch voorbeeld: als een artikel van 2.000 woorden ongeveer 150 unieke semantische concepten bevat die gelijkmatig verdeeld zijn, is de informatiedichtheid hoger dan een artikel van 2.000 woorden met slechts 80 unieke concepten die zich in de eerste helft concentreren. Je kunt ook proxy-metrieken gebruiken zoals de verhouding unieke termen tot totaal aantal woorden, de gemiddelde informatiewinst per alinea, of het aantal direct toepasbare inzichten per 500 woorden—dit zijn geen perfecte metingen, maar bieden nuttige richting. BrightEdge’s onderzoek raadt aan te monitoren hoe vaak je content door AI-systemen wordt geciteerd als real-world validatie van informatiedichtheid; als je content consistent verschijnt in AI Overviews en geciteerd wordt, zit je waarschijnlijk op het juiste dichtheidsniveau.
De meest voorkomende fout bij het nastreven van informatiedichtheid is over-optimalisatie, waarbij makers zo agressief mogelijk dichtheid proberen te maximaliseren dat content moeilijk leesbaar wordt of noodzakelijke context en uitleg verliest. Dit uit zich vaak in keyword stuffing vermomd als dichtheidsoptimalisatie—meerdere doeltermen in zinnen proppen waar ze niet natuurlijk thuishoren, wat juist de informatie-waarde verlaagt en AI-straffen kan opleveren. Een andere kritieke fout is informatie-overload door te veel onderwerpen in één stuk te behandelen; dit schendt de UID-hypothese door overmatige cognitieve belasting in bepaalde secties te concentreren terwijl andere dun bevolkt blijven. Slechte structuur is een andere valkuil: zelfs informatiedichte content verliest effectiviteit als deze niet hiërarchisch is opgebouwd met duidelijke conceptrelaties, waardoor lezers en AI-systemen harder moeten werken om waarde te halen. Sommige makers verwarren dichtheid met beknoptheid en produceren content die weliswaar kort is, maar niet diepgaand genoeg om gebruikersintentie te vervullen of AI-systemen de context te bieden voor correcte synthese en citatie. Tot slot leidt het niet behouden van een consistente informatiedistributie tot ongelijke cognitieve belasting—bijvoorbeeld door alle statistieken en data in de introductie te proppen en daarna alleen nog verhalende uitleg te geven, wat de UID-principes schendt en de effectiviteit bij AI vermindert.
De principes van informatiedichtheid zijn van toepassing op alle contentvormen, maar het optimale dichtheidsniveau en de implementatiestrategie verschillen sterk per type. Blogposts profiteren meestal van een matige tot hoge informatiedichtheid met strategisch gebruik van voorbeelden en uitleg om dichte concepten toegankelijk te maken; een technische blogpost kan 70-80% dichtheid behouden, terwijl een voor beginners gerichte post op 50-60% kan zitten voor het begrip. Technische documentatie vraagt om de hoogste informatiedichtheid, aangezien lezers geconcentreerde waarde en minimale opvulling verwachten—documentatie die meer dan 85% informatiedichtheid haalt, presteert doorgaans beter bij AI-systemen omdat deze makkelijker samen te vatten en te citeren is. Productpagina’s vereisen een andere aanpak, met een balans tussen informatiedichtheid, overtuiging en gebruikerservaring; je wilt waarde in productomschrijvingen en voordelen stoppen, maar overmatige dichtheid kan klanten overweldigen en conversies verlagen. Nieuwsartikelen en journalistieke content werken onder andere randvoorwaarden, waarbij narratieve flow en context soms een lagere informatiedichtheid vereisen, hoewel AI-systemen nog steeds nieuws prefereren dat feiten efficiënt levert zonder overmatige redactionele toelichting. Onderzoeksrapporten en whitepapers kunnen zeer hoge informatiedichtheid aan, omdat het publiek technische diepgang verwacht, maar ook academische content profiteert van duidelijke structuur en strategische samenvattingen om UID-principes te waarborgen. Inzicht in deze variaties stelt je in staat de informatiedichtheid optimaal toe te passen voor jouw specifieke contenttype, met behoud van effectiviteit voor zowel menselijke lezers als AI-systemen.
Naarmate AI-systemen geavanceerder worden, zal informatiedichtheid waarschijnlijk een nog belangrijker ranking- en citatiesignaal worden, zeker naarmate de concurrentie voor opname in AI Overviews toeneemt. Opkomend onderzoek suggereert dat toekomstige LLM’s steeds genuanceerdere methoden zullen ontwikkelen om informatiekwaliteit en dichtheid te beoordelen, mogelijk verdergaand dan simpele entropieberekeningen naar meer geavanceerde semantische analyses die niet alleen geconcentreerde informatie belonen, maar ook informatie die optimaal gestructureerd is voor synthese en citatie. De evolutie van AI-zoektoepassingen zal waarschijnlijk makers bevoordelen die begrijpen dat AI-evolutie niet draait om het manipuleren van algoritmen, maar om daadwerkelijk beter te voldoen aan gebruikersdoelen—dichte, goed gestructureerde content dient dit doel van nature door AI-systemen rijkere input te bieden. Contentmakers moeten zich voorbereiden op een toekomst waarin contentstrategie steeds meer nadruk legt op kwaliteit boven kwantiteit, waarin een artikel van 1.500 woorden met uitzonderlijke informatiedichtheid beter presteert dan een artikel van 5.000 woorden met matige dichtheid, en waarin het vermogen om complexe ideeën kernachtig te communiceren een concurrentievoordeel oplevert. Organisaties die hun aanwezigheid in AI Overviews monitoren en citatiefrequenties volgen via platforms als AmICited.com hebben een aanzienlijk voordeel, omdat ze direct kunnen zien hoe veranderingen in informatiedichtheid hun zichtbaarheid in AI-zoekresultaten beïnvloeden. De makers en organisaties die nu investeren in het begrijpen en optimaliseren van informatiedichtheid, zijn het best gepositioneerd om te floreren wanneer AI-zoektoepassingen het dominante mechanisme worden voor online contentontdekking.

Informatiedichtheid verwijst naar de concentratie van betekenisvolle, direct toepasbare inzichten binnen content—hoeveel waarde er in elk woord of elke zin verpakt zit. AI-systemen beoordelen deze maatstaf om te bepalen welke content ze citeren en uitlichten in AI Overviews. Hogere informatiedichtheid leidt doorgaans tot betere zichtbaarheid in AI-zoekresultaten.
De UID-hypothese suggereert dat effectieve communicatie een stabiele informatiestroom door content heen behoudt. AI-systemen verwerken content effectiever wanneer de cognitieve belasting gelijkmatig verspreid is, in plaats van geconcentreerd in losse secties. Dit principe beïnvloedt direct hoe LLM's je content selecteren en citeren.
Dichte content levert veel informatie met weinig opvulling, gebruikt precieze taal en elimineert herhaling. Dunne content bevat veel herhaling en weinig waardevolle uitwijdingen. AI-systemen geven de voorkeur aan dichte content omdat deze efficiënter samen te vatten en te citeren is, waardoor minder bronverwijzingen nodig zijn.
Je kunt informatiedichtheid meten door de verhouding van betekenisvolle informatie tot het totale aantal woorden te berekenen met entropie-gebaseerde metrieken. Praktische methoden zijn het bijhouden van unieke semantische concepten per woord, het monitoren van direct toepasbare inzichten per 500 woorden, of kijken hoe vaak AI-systemen je content citeren in AI Overviews.
Ja, aanzienlijk. Onderzoek toont aan dat content die geselecteerd wordt voor AI Overviews ongeveer 40% hogere informatiedichtheidsscores heeft dan niet-geselecteerde content. AI-systemen citeren bij voorkeur dichte, waardevolle content omdat dit meeromvattende antwoorden biedt met minder bronnen nodig.
Veelgemaakte fouten zijn over-optimalisatie die de leesbaarheid vermindert, keyword stuffing vermomd als dichtheid, informatie-overload door te veel onderwerpen te behandelen, slechte structuur, dichtheid verwarren met beknoptheid, en het niet behouden van een consistente informatiedistributie door de content heen.
De eisen aan informatiedichtheid verschillen per format: technische documentatie profiteert van meer dan 85% dichtheid, blogposts werken goed bij 70-80%, productpagina's balanceren dichtheid en overtuigingskracht bij 50-70%, en nieuwsartikelen opereren vaak met lagere dichtheid vanwege narratieve eisen. Optimaliseer de dichtheid passend bij jouw contenttype.
Naarmate AI-systemen geavanceerder worden, zal informatiedichtheid waarschijnlijk een nog belangrijker rankingsignaal worden. Toekomstige LLM's zullen waarschijnlijk meer genuanceerde methoden ontwikkelen om informatiekwaliteit te beoordelen, waarbij makers die begrijpen dat dichte, goed gestructureerde content het gebruikersdoel beter dient, de voorkeur krijgen.
Volg hoe AI-systemen zoals ChatGPT, Perplexity en Google AI Overviews jouw merk citeren en vermelden. Krijg realtime inzichten in je AI-zichtbaarheid en contentprestaties.
Leer wat informatiedichtheid is en hoe het de kans op AI-citaties vergroot. Ontdek praktische technieken om inhoud te optimaliseren voor AI-systemen zoals ChatG...
Leer hoe je inhoud maakt die diep genoeg is om door AI-systemen geciteerd te worden. Ontdek waarom semantische volledigheid belangrijker is dan het aantal woord...

Leer hoe je contentformaten test op AI-citaties met behulp van A/B-testmethodologie. Ontdek welke formaten de hoogste AI-zichtbaarheid en citatiepercentages opl...