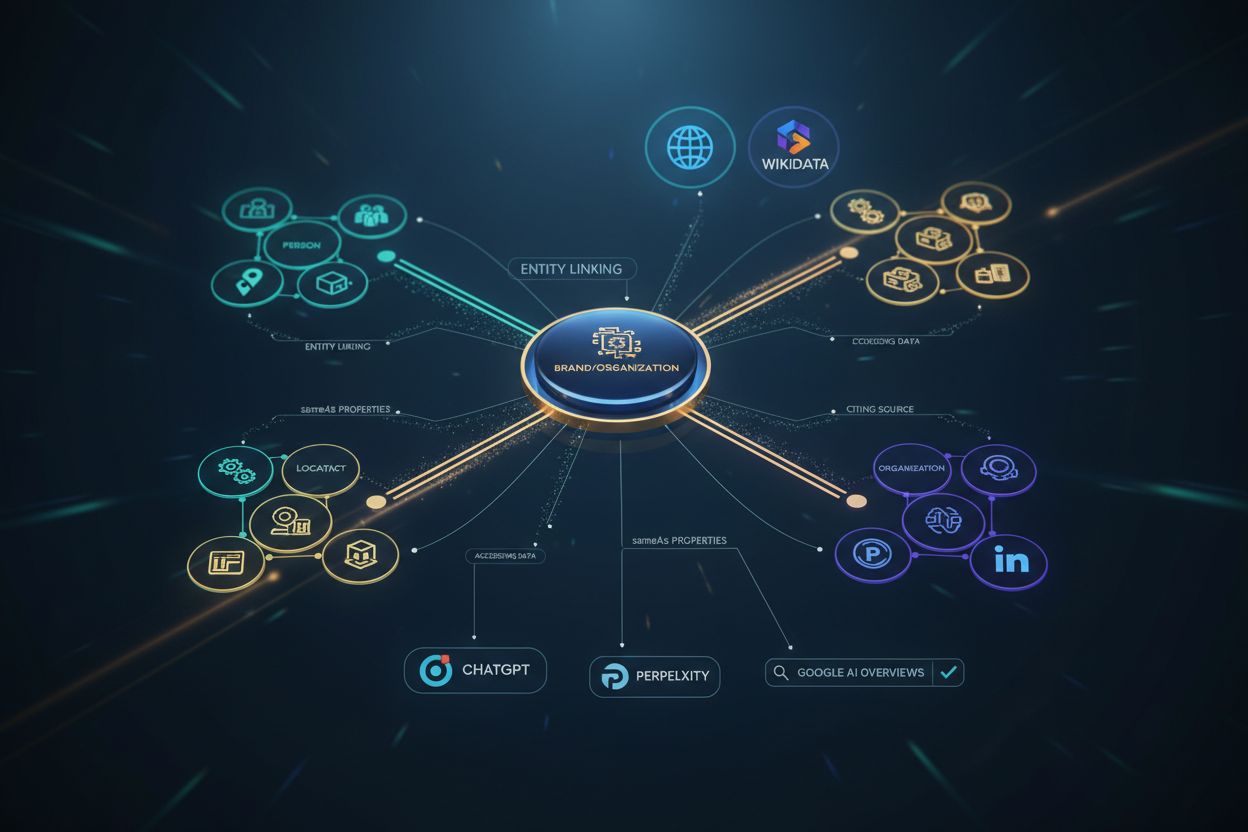
Schema.org-gestructureerde gegevens die entiteiten (personen, organisaties, producten, locaties) duidelijk definiëren in een machineleesbaar formaat, waardoor AI-systemen zoals ChatGPT, Perplexity en Google AI Overviews je content nauwkeurig kunnen herkennen, begrijpen en met meer vertrouwen en gezag kunnen citeren.
AI-entiteitsopmaak
Schema.org-gestructureerde gegevens die entiteiten (personen, organisaties, producten, locaties) duidelijk definiëren in een machineleesbaar formaat, waardoor AI-systemen zoals ChatGPT, Perplexity en Google AI Overviews je content nauwkeurig kunnen herkennen, begrijpen en met meer vertrouwen en gezag kunnen citeren.
Wat is AI-entiteitsopmaak?
AI-entiteitsopmaak is Schema.org-gestructureerde data die entiteiten—zoals personen, organisaties, producten en locaties—duidelijk definieert in een machineleesbaar formaat dat AI-systemen eenvoudig kunnen herkennen en begrijpen. In tegenstelling tot traditionele SEO-markup die primair is ontworpen voor zoekmachines, is AI-entiteitsopmaak specifiek geoptimaliseerd voor hoe kunstmatige intelligentiesystemen zoals ChatGPT, Perplexity en Google AI Overviews webcontent parsen, interpreteren en citeren. Deze markup transformeert ambigue tekst in verifieerbare, gestructureerde feiten waardoor AI-systemen informatie met vertrouwen kunnen extraheren en toeschrijven aan gezaghebbende bronnen. Nu AI-gegenereerde antwoorden steeds vaker traditionele zoekresultaten vervangen, is het implementeren van juiste entiteitsopmaak geëvolueerd van een mooie optimalisatie naar essentiële infrastructuur voor merkzichtbaarheid en geloofwaardigheid in het door AI aangedreven zoeklandschap.
Hoe AI-systemen entiteitsopmaak gebruiken
AI-systemen functioneren in de kern als statistische patroonherkenningsmachines die enorme hoeveelheden data analyseren om antwoorden te genereren op basis van waarschijnlijkheid in plaats van redenering. Wanneer een AI ongestructureerde tekst tegenkomt zoals “John Smith is de CEO van Acme Corp”, moet het systeem relaties tussen tokens afleiden zonder gegarandeerde verificatie. Maar wanneer diezelfde informatie is verpakt in Organization-schema met een founder-eigenschap die verwijst naar een Person-schema, wordt het een verifieerbaar, machineleesbaar feit dat AI-systemen met vertrouwen kunnen gebruiken en citeren. Onderzoek toont aan dat LLM’s die zijn gebaseerd op knowledge graphs ongeveer 300% meer nauwkeurigheid behalen dan systemen die uitsluitend vertrouwen op ongestructureerde data—een dramatische verbetering die direct bepaalt of je content wordt geciteerd in AI-gegenereerde antwoorden.
Aspect
Ongestructureerde content
Entiteitsopmaak
AI-begrip
Probabilistisch gokken
Gecontroleerde feiten
Citatietrust
Laag (16% nauwkeurigheid)
Hoog (54% nauwkeurigheid)
Integratie met knowledge graph
Beperkt of afwezig
Volledige integratie
Kans op AI-citatie
Lagere waarschijnlijkheid
30%+ hogere zichtbaarheid
Verificatievermogen
Moeilijk voor AI
Expliciet en verifieerbaar
Duidelijkheid entiteitsrelaties
Ambigu
Precies gedefinieerd
Microsoft’s Principal Product Manager Fabrice Canel bevestigde op SMX München dat “Schema markup Microsoft’s LLMs helpt om content te begrijpen,” en Bing’s Copilot gebruikt specifiek gestructureerde data om webcontent te interpreteren. Dit is geen theorie—sites met uitgebreide gestructureerde data zien tot 30% meer zichtbaarheid in AI Overviews, wat het verschil betekent tussen geciteerd worden als gezaghebbende bron of volledig onzichtbaar zijn voor AI-systemen die steeds vaker bepalen hoe mensen informatie ontdekken.
Kern-entiteitstypen voor AI-zichtbaarheid
Niet alle schematypen zijn gelijk voor AI-citatie. Hoewel Schema.org meer dan 800 typen en meer dan duizend eigenschappen omvat, beïnvloeden er slechts een handvol direct hoe LLM’s je content interpreteren en citeren. Dit zijn de entiteitstypen die het meest uitmaken voor AI-zichtbaarheid:
Organization-schema: Definieert je bedrijf met uitgebreide sameAs-eigenschappen die linken naar Wikipedia, LinkedIn, Crunchbase en andere gezaghebbende platforms. Dit vestigt je merk als erkende entiteit in knowledge graphs en signaleert geloofwaardigheid aan AI-systemen die bronautoriteit beoordelen.
Person-schema: Stelt auteurs-expertise en geloofwaardigheid vast door verifieerbare auteursprofielen te creëren met links naar externe platforms. Wanneer het Person-schema van een auteur correct is geïmplementeerd met sameAs-eigenschappen, kunnen AI-systemen expertise over meerdere platforms verifiëren, wat E-E-A-T-signalen versterkt.
Article-schema: Bevat publicatiedata, auteursinformatie en uitgeversdetails—allemaal signalen die AI-systemen helpen contentgeloofwaardigheid en relevantie te beoordelen bij het bepalen wat te citeren. Article-schema met correcte autoraanduiding is je geloofwaardigheidspaspoort in het AI-zoektijdperk.
Product-schema: Markeert producten met prijs, beoordelingen, beschrijvingen en beschikbaarheidsinformatie. Voor e-commerce en SaaS-bedrijven stelt Product-schema AI-systemen in staat je aanbod te begrijpen en aan te bevelen wanneer gebruikers vragen naar oplossingen in jouw categorie.
FAQPage-schema: Formatteert content vooraf als vraag-antwoordparen, precies zoals AI-systemen informatie het liefst extraheren en presenteren. FAQPage is de AI-citatiewerkpaard omdat het kant-en-klare, citable antwoorden biedt die AI-systemen met vertrouwen kunnen gebruiken bij het beantwoorden van gerelateerde vragen.
Entiteitskoppeling en knowledge graphs
Entiteitskoppeling is het proces waarbij belangrijke concepten of “entiteiten” binnen je content worden geïdentificeerd en verbonden met erkende bronnen zoals Wikidata, Wikipedia, Google’s Knowledge Graph of de eigen knowledge graph van je organisatie. Deze verbinding is cruciaal omdat het AI-systemen helpt precies te begrijpen naar welke entiteit je verwijst en hoe deze zich verhoudt tot andere concepten in het bredere informatielandschap. Door bijvoorbeeld “Bronco” te koppelen aan de Ford Bronco SUV in plaats van het paard Bronco, wordt de betekenis verduidelijkt en wordt ervoor gezorgd dat je content correct wordt geïnterpreteerd door AI-systemen.
Wanneer je entiteitskoppeling implementeert via Schema.org-markup, bouw je in feite bruggen tussen je content en gezaghebbende kennisbronnen. Deze bruggen stellen AI-systemen in staat relaties te volgen en context veel nauwkeuriger te begrijpen. Een auto-onderdelenwinkel die schrijft over “hoe je je filter in je Bronco vervangt” wordt semantisch verbonden met entiteiten zoals “Ford Bronco” en “autofilter”, wat aan AI-systemen signaleert dat dit gezaghebbende, contextueel relevante content is die het citeren waard is. De sameAs-eigenschap is je belangrijkste hulpmiddel voor entiteitskoppeling—door URL’s naar Wikipedia, Wikidata en andere gezaghebbende bronnen toe te voegen, vertel je AI-systemen “deze entiteit is hetzelfde als deze erkende entiteit in de knowledge graph.” Deze cross-platform consistentie bouwt entiteitsautoriteit die AI-systemen gebruiken om expertise te verifiëren en citatiewaardigheid te bepalen.
Implementatie best practices
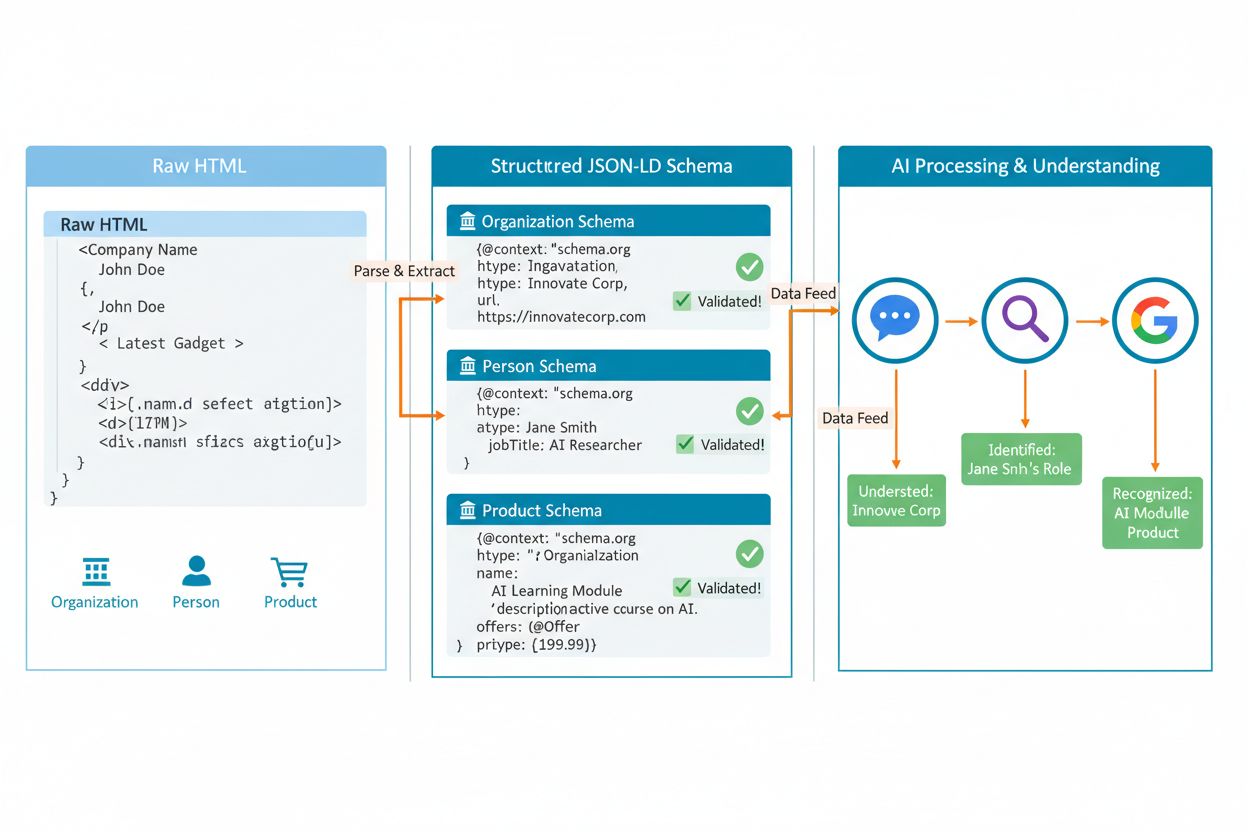
De meest effectieve manier om AI-entiteitsopmaak te implementeren is via JSON-LD-formaat, wat Google expliciet aanbeveelt omdat het schema van HTML-content scheidt en het eenvoudiger maakt om op schaal te implementeren en te onderhouden. Plaats je JSON-LD in de <head>-sectie van je pagina:
De echte kracht van schema komt uit het verbinden van gerelateerde entiteiten met @id-eigenschappen, wat een web van relaties creëert dat AI-systemen kunnen volgen om context te begrijpen. Door dezelfde @id op meerdere pagina’s te gebruiken, bouw je een content knowledge graph die AI-systemen kunnen gebruiken voor geavanceerdere redenatie. Kritieke regel: markeer alleen content die daadwerkelijk zichtbaar is op de pagina. Als gebruikers de informatie niet kunnen zien, voeg het dan niet toe aan schema. AI-systemen vergelijken schema met de pagina-inhoud en discrepanties schaden je geloofwaardigheid. Dit betekent dat FAQ-antwoorden in schema ergens op de pagina moeten verschijnen, prijzen moeten overeenkomen met getoonde prijzen en auteursinformatie verifieerbaar moet zijn op je site.
AI-entiteitsopmaak versus traditionele SEO
Waar traditionele schema-opmaak primair is ontworpen om zoekmachines te helpen rich snippets weer te geven en de doorklikratio te verbeteren, gaat AI-entiteitsopmaak fundamenteel om het mogelijk maken voor AI-systemen om je content met vertrouwen te begrijpen, te verifiëren en te citeren. Traditionele SEO-markup kan je een sterbeoordeling in zoekresultaten opleveren; AI-entiteitsopmaak helpt je geciteerd te worden als gezaghebbende bron in AI-gegenereerde antwoorden. Dit onderscheid is enorm belangrijk in een zero-click zoekwereld waar gebruikers samengevatte antwoorden zien van meerdere bronnen gecombineerd in één AI-gegenereerd resultaat.
De impact op merkauthoriteit is diepgaand. Wanneer je merk verschijnt in een AI-gegenereerd antwoord, signaleert dat geloofwaardigheid en expertise, zelfs als gebruikers niet doorklikken naar je site. In een AI Overview verschijnen bouwt bewustzijn en autoriteit op schaal, en bereikt gebruikers eerder in hun kooptraject tijdens onderzoeks- en verkenningsfasen. Traditionele SEO richt zich op zoekwoorden en rankings; AI-entiteitsopmaak focust op entiteitsrelaties en kennisgraph-integratie. Een merk dat correcte entiteitsopmaak over de hele website implementeert, creëert een semantische datalaag die AI-systemen in staat stelt niet alleen te begrijpen wat je zegt, maar ook wie je bent, waar je voor staat en hoe je verbonden bent met belangrijke onderwerpen. Deze duidelijkheid versterkt E-E-A-T-signalen—Ervaring, Expertise, Autoriteit en Betrouwbaarheid—die bepalen hoe AI-systemen je merk herkennen en citeren.
Succes en ROI meten
In tegenstelling tot traditionele SEO, waar je rankings en klikken kunt volgen, is het meten van AI-citaties nog in ontwikkeling, maar verschillende methoden bieden betrouwbare inzichten. De meest directe methode is handmatige sampling: stel maandelijks vragen aan ChatGPT, Claude en Perplexity die je doelgroep ook zou stellen, en documenteer of je wordt geciteerd, in welke context en met welk sentiment. Google Search Console bevat nu AI Overview-data onder het zoektype “Web”, waarmee je indrukpatronen kunt monitoren en zichtbaarheidstrends kunt detecteren. Tools zoals AmICited.com monitoren specifiek hoe AI-systemen je merk noemen in GPT’s, Perplexity en Google AI Overviews, en bieden gerichte tracking van AI-citatieprestaties.
Verwachte resultaten verschijnen doorgaans binnen 90 dagen na systematische optimalisatie. Basiswerk—Organization-schema met sameAs-eigenschappen en Article-schema op belangrijke content—kan binnen 4-8 weken meetbare verbeteringen in citaties opleveren. Autoriteitsopbouw via cross-platform aanwezigheid en entiteitskoppeling duurt 3-6 maanden om volledig effect te hebben. Sites met uitgebreide gestructureerde data zien tot 30% meer zichtbaarheid in AI Overviews, terwijl goede entiteitskoppeling sterkere engagementstatistieken oplevert, waaronder verbeterde doorklikratio’s. De ROI gaat verder dan citaties: gestructureerde data verbetert ook traditionele zoekzichtbaarheid via rich snippets, verhoogt CTR tot 35% en versterkt de algemene contentvindbaarheid op meerdere AI-platforms.
Toekomst van entiteitsopmaak en semantische data
De opkomende llms.txt-standaard, geïntroduceerd door Answer.AI in 2024, stelt een eenvoudig tekstbestandsformaat voor om AI-systemen gecureerde toegang tot je belangrijkste content te geven. Hoewel de adoptie nog beperkt is—per midden 2025 hadden slechts zo’n 951 domeinen llms.txt-bestanden gepubliceerd—is de specificatie elegant en kan deze terrein winnen naarmate AI-systemen zich ontwikkelen. Toch blijft traditionele schema-opmaak de bewezen, breed ondersteunde aanpak voor AI-zichtbaarheid. De bredere trend is duidelijk: AI-systemen zijn steeds meer gebouwd op knowledge graphs, en entiteiten en hun relaties vormen de knooppunten en verbindingen die deze systemen ondersteunen. Merken die nu investeren in uitgebreide, semantisch rijke gestructureerde data, hebben aanzienlijke concurrentievoordelen—niet alleen in de AI Overviews en chatbots van vandaag, maar op elk AI-gestuurd ontdekplatform dat nog zal komen.
De semantische datalaag die je opbouwt via correcte entiteitsopmaak wordt fundamentele infrastructuur voor hoe AI je merk de komende jaren begrijpt en weergeeft. In 2025 hebben meer dan 45 miljoen webdomeinen Schema.org-gestructureerde data geïmplementeerd—slechts ongeveer 12,4% van alle geregistreerde domeinen. Die kloof betekent een enorme kans voor vooruitstrevende merken die het technische werk willen doen. De vraag is niet of AI-systemen in de toekomst zwaarder zullen leunen op gestructureerde data; dat doen ze nu al. De vraag is of jouw content deel uitmaakt van dat gestructureerde, citable ecosysteem of onzichtbaar is voor de AI-systemen die steeds vaker bepalen hoe mensen informatie ontdekken.
Veelgestelde vragen
Wat is het verschil tussen AI-entiteitsopmaak en traditionele schema-opmaak?
Traditionele schema-opmaak is voornamelijk ontworpen voor zoekmachines om rich snippets weer te geven en de doorklikratio te verbeteren. AI-entiteitsopmaak is specifiek geoptimaliseerd voor hoe AI-systemen content parsen, interpreteren en citeren. Terwijl traditionele markup helpt bij zoekzichtbaarheid, helpt AI-entiteitsopmaak je om als gezaghebbende bron geciteerd te worden in AI-gegenereerde antwoorden en samenvattingen.
Welke entiteitstypen moet ik als eerste prioriteren?
Begin met Organization-schema op je homepage met uitgebreide sameAs-eigenschappen, vervolgens Article-schema op belangrijke contentpagina's. FAQPage-schema moet daarna—dit is het meest direct bruikbaar voor AI-extractie. Daarna voeg je HowTo-schema toe aan handleidingen en SoftwareApplication-schema aan productpagina's.
Hoe lang duurt het om resultaat te zien van het implementeren van entiteitsopmaak?
Basiswerk kan binnen 4-8 weken meetbare verbeteringen in citaties opleveren. Autoriteitsopbouw via cross-platform aanwezigheid en entiteitskoppeling duurt 3-6 maanden om volledig te renderen. De meeste merken zien binnen 90 dagen na systematische optimalisatie meetbare verbeteringen in citaties.
Kan entiteitsopmaak mijn site schaden als het verkeerd geïmplementeerd is?
Alleen verkeerd geïmplementeerde markup schaadt de prestaties. De richtlijnen van Google zijn duidelijk: gebruik relevante schematypen die overeenkomen met de zichtbare inhoud, houd prijzen en data accuraat en markeer geen content die gebruikers niet kunnen zien. Valideer altijd met Google's Rich Results Test voordat je publiceert.
Gebruiken alle AI-systemen entiteitsopmaak op dezelfde manier?
Hoewel alle grote AI-systemen profiteren van gestructureerde data, gebruiken ze deze mogelijk op verschillende manieren. ChatGPT, Perplexity en Google AI Overviews geven allemaal de voorkeur aan content met duidelijke semantische structuur, maar de implementatiedetails verschillen. Goede entiteitsopmaak verbetert de zichtbaarheid op alle AI-platforms.
Hoe verbetert entiteitsopmaak AI-citatieratio's?
Entiteitsopmaak transformeert ambigue tekst in verifieerbare, machineleesbare feiten die AI-systemen met vertrouwen kunnen extraheren en citeren. LLM's die zijn verbonden met knowledge graphs behalen 300% meer nauwkeurigheid dan systemen die vertrouwen op ongestructureerde data. Sites met uitgebreide gestructureerde data zien tot 30% meer zichtbaarheid in AI Overviews.
Wat is de relatie tussen entiteitsopmaak en knowledge graphs?
Entiteitsopmaak creëert verbindingen tussen je content en knowledge graphs zoals Google's Knowledge Graph en Wikidata. Deze verbindingen stellen AI-systemen in staat om entiteitsrelaties en context te begrijpen. Door juiste entiteitskoppeling via sameAs-eigenschappen implementeer je je merk in het bredere knowledge graph-ecosysteem.
Moet ik naast entiteitsopmaak ook llms.txt implementeren?
Voor de meeste sites moet schema-opmaak de prioriteit zijn—het is bewezen en breed ondersteund. llms.txt is nog een opkomende standaard met beperkte adoptie door AI-crawlers. Als je een ontwikkelaarsgerichte organisatie bent met veel documentatie, kan het zinvol zijn om llms.txt te maken als toekomstgerichte stap, maar laat dit je niet afleiden van uitgebreide schema-implementatie.
Monitor hoe AI je merk noemt
Volg je merkvermeldingen op ChatGPT, Perplexity, Google AI Overviews en andere AI-systemen. Begrijp hoe AI-systemen je content citeren en optimaliseer je zichtbaarheid.
Wat is entiteitsoptimalisatie en waarom zegt iedereen dat het de toekomst is van AI-zoekzichtbaarheid?
Communitydiscussie over entiteitsoptimalisatie voor AI-zoekopdrachten. Praktische strategieën om jouw merk te vestigen als een erkende entiteit die AI-systemen ...
Wat is entiteitsoptimalisatie voor AI? Volledige gids voor 2025
Ontdek wat entiteitsoptimalisatie voor AI is, hoe het werkt en waarom het cruciaal is voor zichtbaarheid in ChatGPT, Perplexity en andere AI-zoekmachines. Compl...
Entiteitsherkenning is een AI NLP-capaciteit voor het identificeren en categoriseren van benoemde entiteiten in tekst. Leer hoe het werkt, de toepassingen in AI...
9 min lezen
Cookie Toestemming We gebruiken cookies om uw browse-ervaring te verbeteren en ons verkeer te analyseren. See our privacy policy.