Crawl Rate
Crawl rate is de snelheid waarmee zoekmachines je website crawlen. Leer hoe dit de indexering, SEO-prestaties en zichtbaarheid in zoekresultaten beïnvloedt en h...
10 min lezen
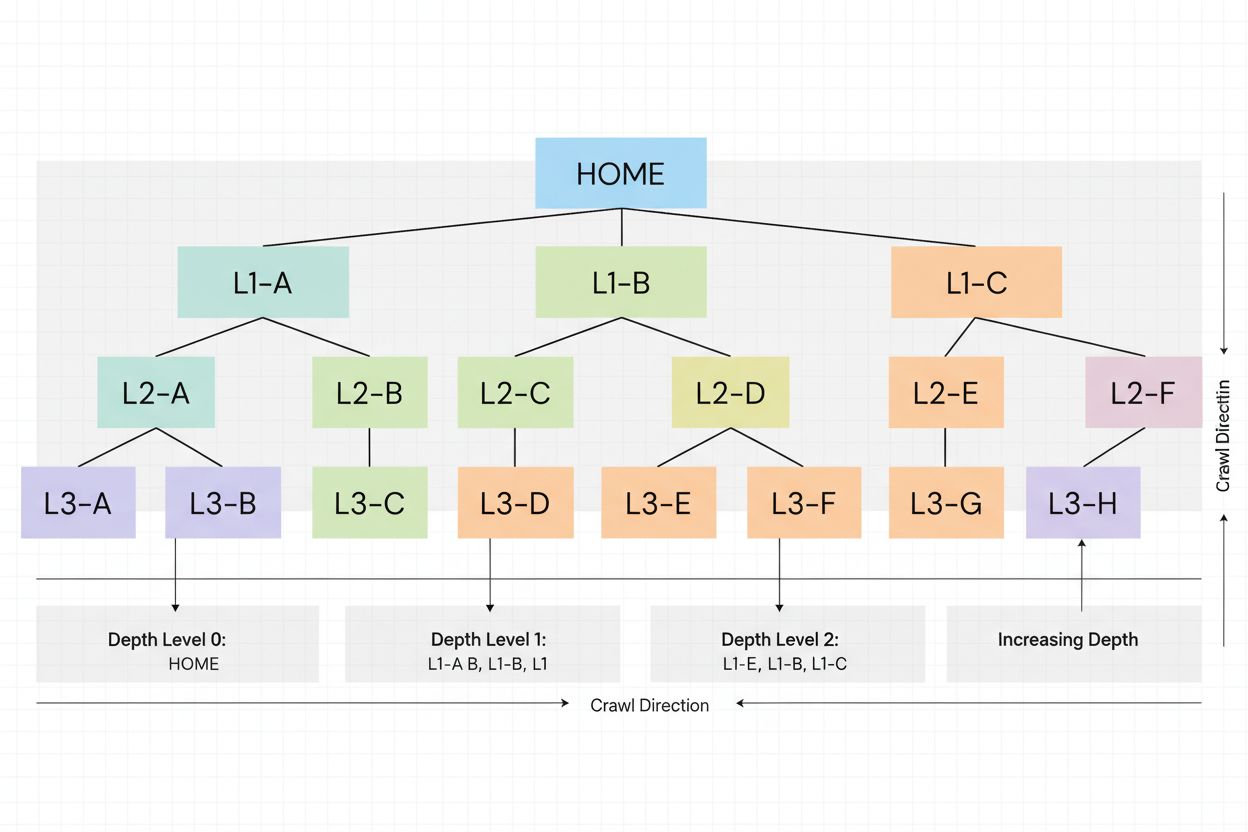
Crawl depth verwijst naar hoe diep zoekmachinecrawlers in de hiërarchische structuur van een website kunnen doordringen tijdens één crawlsessie. Het meet het aantal klikken of stappen vanaf de homepage dat nodig is om een specifieke pagina te bereiken, en beïnvloedt direct welke pagina’s worden geïndexeerd en hoe vaak ze binnen het toegewezen crawlbudget van een site worden gecrawld.
Crawl depth verwijst naar hoe diep zoekmachinecrawlers in de hiërarchische structuur van een website kunnen doordringen tijdens één crawlsessie. Het meet het aantal klikken of stappen vanaf de homepage dat nodig is om een specifieke pagina te bereiken, en beïnvloedt direct welke pagina's worden geïndexeerd en hoe vaak ze binnen het toegewezen crawlbudget van een site worden gecrawld.
Crawl depth is een fundamenteel technisch SEO-concept dat verwijst naar hoe diep zoekmachinecrawlers in de hiërarchische structuur van een website kunnen navigeren tijdens één crawlsessie. Concreet meet het het aantal klikken of stappen dat nodig is vanaf de homepage om een specifieke pagina binnen de interne linkstructuur van je site te bereiken. Een website met hoge crawl depth betekent dat zoekmachinebots veel pagina’s door de hele site kunnen bereiken en indexeren, terwijl een website met lage crawl depth aangeeft dat crawlers mogelijk niet tot diepere pagina’s komen voordat hun toegewezen middelen op zijn. Dit concept is van cruciaal belang omdat het direct bepaalt welke pagina’s worden geïndexeerd, hoe vaak ze worden gecrawld en uiteindelijk hun zichtbaarheid in zoekmachineresultaten (SERP’s).
Het belang van crawl depth is de laatste jaren toegenomen door de exponentiële groei van webcontent. Aangezien Google’s index meer dan 400 miljard documenten bevat en er steeds meer AI-gegenereerde content bijkomt, krijgen zoekmachines te maken met ongekende beperkingen op crawlresources. Dit betekent dat websites met een slechte crawl depth-optimalisatie kunnen merken dat hun belangrijke pagina’s niet worden geïndexeerd of zelden worden gecrawld, met grote gevolgen voor hun organische zichtbaarheid. Begrip en optimalisatie van crawl depth is daarom essentieel voor elke website die haar zoekmachine-aanwezigheid wil maximaliseren.
Het concept van crawl depth is ontstaan uit de manier waarop zoekmachinecrawlers (ook wel webspiders of bots genoemd) werken. Wanneer Google’s Googlebot of andere zoekmachinebots een website bezoeken, volgen ze een systematisch proces: ze beginnen op de homepage en volgen interne links om meer pagina’s te ontdekken. De crawler kent aan elke website een beperkte hoeveelheid tijd en middelen toe, het zogenaamde crawlbudget. Dit budget wordt bepaald door twee factoren: crawl capacity limit (hoeveel de crawler aankan zonder de server te overbelasten) en crawl demand (hoe belangrijk en hoe vaak de site wordt bijgewerkt). Hoe dieper pagina’s in je sitestructuur liggen, hoe kleiner de kans dat crawlers ze bereiken voordat het crawlbudget op is.
Historisch gezien waren websitestructuren relatief eenvoudig, waarbij de meeste belangrijke content binnen 2-3 klikken van de homepage lag. Maar naarmate e-commercesites, nieuwsportalen en contentrijke websites exponentieel groeiden, zijn veel organisaties diep geneste structuren gaan creëren met pagina’s op 5, 6 of zelfs 10+ niveaus diep. Onderzoek van seoClarity en andere SEO-platformen toont aan dat pagina’s op diepte 3 of meer over het algemeen slechter presteren in organische zoekresultaten dan pagina’s dichter bij de homepage. Dit prestatieverschil bestaat omdat crawlers prioriteit geven aan pagina’s dichter bij de root en deze pagina’s ook meer link equity (ranking power) verzamelen via interne links. De relatie tussen crawl depth en indexatiegraad is vooral zichtbaar bij grote websites met duizenden of miljoenen pagina’s, waar crawlbudget een kritische beperkende factor wordt.
De opkomst van AI-zoekmachines zoals Perplexity, ChatGPT en Google AI Overviews heeft een nieuwe dimensie toegevoegd aan crawl depth-optimalisatie. Deze AI-systemen gebruiken hun eigen gespecialiseerde crawlers (zoals PerplexityBot en GPTBot) die mogelijk andere crawlpatronen en prioriteiten hebben dan traditionele zoekmachines. Toch blijft het fundamentele principe hetzelfde: pagina’s die gemakkelijk toegankelijk zijn en goed zijn geïntegreerd in de sitestructuur, worden sneller ontdekt, gecrawld en als bron geciteerd in AI-gegenereerde antwoorden. Dit maakt crawl depth-optimalisatie relevant voor zowel traditionele SEO als voor AI-zoekzichtbaarheid en generative engine optimization (GEO).
| Concept | Definitie | Perspectief | Meting | Impact op SEO |
|---|---|---|---|---|
| Crawl Depth | Hoe diep crawlers in de sitestructuur navigeren op basis van interne links en URL-structuur | Perspectief van zoekmachinecrawler | Aantal klikken/stappen vanaf homepage | Beïnvloedt indexatiefrequentie en dekking |
| Click Depth | Aantal gebruikersklikken vanaf de homepage naar een pagina via het kortste pad | Perspectief van de gebruiker | Letterlijk aantal benodigde klikken | Beïnvloedt gebruikerservaring en navigatie |
| Page Depth | Positie van een pagina in de hiërarchische structuur van de site | Structureel perspectief | Niveau van URL-nesting | Beïnvloedt distributie van link equity |
| Crawl Budget | Totale middelen (tijd/bandbreedte) toegewezen om een website te crawlen | Resource-allocatie | Aantal pagina’s per dag gecrawld | Bepaalt hoeveel pagina’s worden geïndexeerd |
| Crawl Efficiency | Hoe effectief crawlers de content van een site navigeren en indexeren | Optimalisatieperspectief | Pagina’s geïndexeerd vs. gebruikt crawlbudget | Maximaliseert indexatie binnen budgetlimieten |
Begrijpen hoe crawl depth werkt vereist inzicht in de manier waarop zoekmachinecrawlers websites navigeren. Wanneer Googlebot of een andere crawler je site bezoekt, begint deze op de homepage (diepte 0) en volgt interne links om meer pagina’s te ontdekken. Elke pagina die vanaf de homepage wordt gelinkt, bevindt zich op diepte 1; pagina’s die vanaf die pagina’s worden gelinkt, op diepte 2, enzovoorts. De crawler volgt niet noodzakelijkerwijs een lineair pad; hij ontdekt meerdere pagina’s per niveau voordat hij dieper navigeert. De reis van de crawler wordt echter beperkt door het crawlbudget, dat bepaalt hoeveel pagina’s binnen een bepaalde tijd kunnen worden bezocht.
De technische relatie tussen crawl depth en indexatie wordt door verschillende factoren bepaald. Ten eerste speelt crawlprioritering een belangrijke rol—zoekmachines crawlen niet alle pagina’s even vaak. Ze geven prioriteit aan pagina’s op basis van belangrijkheid, actualiteit en relevantie. Pagina’s met meer interne links, hogere autoriteit en recente updates worden vaker gecrawld. Ten tweede beïnvloedt de URL-structuur zelf de crawl depth. Een pagina op /categorie/subcategorie/product/ heeft een grotere crawl depth dan een pagina op /product/, zelfs als beide vanaf de homepage zijn gelinkt. Ten derde vormen redirect chains en gebroken links obstakels die crawlbudget verspillen. Een redirect chain dwingt de crawler om meerdere omleidingen te volgen voordat hij de uiteindelijke pagina bereikt, wat middelen kost die anders aan andere content besteed hadden kunnen worden.
De technische implementatie van crawl depth-optimalisatie omvat verschillende belangrijke strategieën. Interne linkarchitectuur is essentieel—door belangrijke pagina’s strategisch te linken vanaf de homepage en autoritatieve pagina’s, verlaag je hun effectieve crawl depth en vergroot je de kans dat ze vaak worden gecrawld. XML-sitemaps geven crawlers een direct overzicht van de sitestructuur, zodat ze pagina’s efficiënter kunnen ontdekken zonder alleen op links te hoeven vertrouwen. Sitesnelheid is ook een belangrijke factor; snellere pagina’s laden sneller, waardoor crawlers meer pagina’s binnen hun budget kunnen bezoeken. Tot slot bieden robots.txt en noindex-tags de mogelijkheid om te bepalen welke pagina’s crawlers moeten prioriteren, zodat ze geen budget verspillen aan pagina’s met lage waarde, zoals duplicaten of adminpagina’s.
De praktische gevolgen van crawl depth reiken verder dan technische SEO-metrics—ze hebben directe impact op bedrijfsresultaten. Voor e-commercesites betekent gebrekkige crawl depth-optimalisatie dat productpagina’s diep in categorieën mogelijk niet of zelden worden geïndexeerd. Dit leidt tot minder organische zichtbaarheid, minder productvertoningen in zoekresultaten en uiteindelijk tot omzetverlies. Uit onderzoek van seoClarity blijkt dat pagina’s met een hogere crawl depth aanzienlijk lagere indexatiepercentages hadden, waarbij pagina’s op diepte 4+ tot 50% minder vaak werden gecrawld dan pagina’s op diepte 1-2. Voor grote retailers met duizenden SKU’s kan dit miljoenen euro’s aan misgelopen organische omzet betekenen.
Voor contentrijke websites zoals nieuwssites, blogs en kennisbanken beïnvloedt crawl depth-optimalisatie direct de vindbaarheid van content. Artikelen die diep in categorieën zijn geplaatst, komen mogelijk nooit in de index van Google terecht, waardoor ze geen organisch verkeer genereren, ongeacht hun kwaliteit of relevantie. Dit is vooral problematisch voor nieuwssites waarbij actualiteit cruciaal is—als nieuwe artikelen niet snel worden gecrawld en geïndexeerd, missen ze de kans om te ranken op trending topics. Uitgevers die crawl depth optimaliseren door hun structuur te ‘flatten’ en interne links te verbeteren, zien een dramatische toename van geïndexeerde pagina’s en organisch verkeer.
De relatie tussen crawl depth en link equity distributie heeft grote zakelijke gevolgen. Link equity (ook wel PageRank of ranking power genoemd) stroomt via interne links vanaf de homepage naar buiten. Pagina’s dichter bij de homepage ontvangen meer link equity, waardoor ze makkelijker ranken op concurrerende zoekwoorden. Door crawl depth te optimaliseren en belangrijke pagina’s binnen 2-3 klikken van de homepage te houden, kun je link equity concentreren op je meest waardevolle pagina’s—meestal productpagina’s, diensten of cornerstone content. Deze strategische distributie van link equity kan de rankings voor waardevolle zoekwoorden aanzienlijk verbeteren.
Daarnaast beïnvloedt crawl depth-optimalisatie de crawlbudgetefficiëntie, wat steeds belangrijker wordt naarmate websites groeien. Grote sites met miljoenen pagina’s hebben vaak een streng crawlbudget. Door crawl depth te optimaliseren, dubbele content te verwijderen, gebroken links te herstellen en redirect chains te elimineren, zorg je dat crawlers hun budget besteden aan waardevolle, unieke content in plaats van aan pagina’s met weinig waarde. Dit is vooral van belang voor enterprise-websites en grote e-commerceplatforms waar crawlbudgetbeheer het verschil kan betekenen tussen 80% of slechts 40% van de pagina’s in de index.
De opkomst van AI-zoekmachines en generatieve AI-systemen heeft nieuwe dimensies toegevoegd aan crawl depth-optimalisatie. ChatGPT, aangedreven door OpenAI, gebruikt de GPTBot-crawler om webcontent te ontdekken en te indexeren. Perplexity, een toonaangevende AI-zoekmachine, gebruikt PerplexityBot om bronnen te verzamelen. Google AI Overviews (voorheen SGE) gebruikt Google’s eigen crawlers om informatie te verzamelen voor AI-samenvattingen. Claude, de AI-assistent van Anthropic, crawlt ook webcontent voor training en retrieval. Elk van deze systemen heeft andere crawlpatronen, prioriteiten en resourcebeperkingen dan traditionele zoekmachines.
De belangrijkste conclusie is dat crawl depth-principes óók gelden voor AI-zoekmachines. Pagina’s die gemakkelijk toegankelijk, goed gelinkt en structureel prominent zijn, worden sneller ontdekt door AI-crawlers en als bron geciteerd in AI-gegenereerde antwoorden. Onderzoek van AmICited en andere AI-monitoringplatformen toont aan dat sites met geoptimaliseerde crawl depth vaker worden geciteerd in AI-zoekresultaten. Dit komt omdat AI-systemen prioriteit geven aan bronnen die autoritatief, toegankelijk en actueel zijn—allemaal kenmerken die samenhangen met een lage crawl depth en een goede interne linkstructuur.
Toch zijn er verschillen in het gedrag van AI-crawlers ten opzichte van Googlebot. AI-crawlers kunnen agressiever zijn in hun crawlpatronen en dus meer bandbreedte verbruiken. Ook kunnen ze andere voorkeuren hebben wat betreft contenttype en actualiteit. Sommige AI-systemen geven meer prioriteit aan recent bijgewerkte content dan traditionele zoekmachines, waardoor crawl depth-optimalisatie nog belangrijker wordt om zichtbaar te blijven in AI-zoekresultaten. Ook houden AI-crawlers zich mogelijk niet altijd aan bepaalde richtlijnen zoals robots.txt of noindex-tags, al wordt hieraan gewerkt naarmate AI-bedrijven zich meer aan SEO-best practices willen houden.
Voor bedrijven die zich richten op AI-zoekzichtbaarheid en generative engine optimization (GEO), dient crawl depth-optimalisatie een dubbel doel: het verbetert de traditionele SEO én vergroot de kans dat AI-systemen je content ontdekken, crawlen en citeren. Dit maakt crawl depth-optimalisatie tot een basisstrategie voor elke organisatie die zichtbaar wil zijn in zowel traditionele als AI-aangedreven zoekplatforms.
Crawl depth-optimalisatie vereist een systematische benadering die zowel de structurele als technische aspecten van je site aanpakt. De volgende best practices zijn effectief gebleken bij duizenden websites:
Voor grote enterprise-websites met duizenden of miljoenen pagina’s wordt crawl depth-optimalisatie steeds complexer en belangrijker. Enterprise-sites hebben vaak te maken met strikte crawlbudgetten, waardoor het essentieel is om geavanceerde strategieën te implementeren. Eén aanpak is crawlbudgetallocatie, waarbij je strategisch bepaalt welke pagina’s crawlresources verdienen op basis van hun zakelijke waarde. Waardevolle pagina’s (productpagina’s, diensten, cornerstone content) moeten oppervlakkig blijven en vaak gelinkt worden, terwijl pagina’s met lage waarde (archief, duplicaten, dunne content) moeten worden voorzien van noindex of gedeprioriteerd.
Een andere geavanceerde strategie is dynamische interne linking, waarbij je datagedreven inzichten gebruikt om te bepalen welke pagina’s extra interne links nodig hebben om hun crawl depth te verbeteren. Tools zoals seoClarity’s Internal Link Analysis kunnen pagina’s op te grote diepte met weinig interne links identificeren en zo kansen blootleggen voor verbeterde crawlefficiëntie. Daarnaast biedt logfile-analyse inzicht in hoe crawlers je site werkelijk navigeren, zodat je knelpunten en inefficiënties in je crawl depth-structuur kunt ontdekken. Door het gedrag van crawlers te analyseren, kun je pagina’s vinden die inefficiënt worden gecrawld en hun toegankelijkheid optimaliseren.
Voor meertalige websites en internationale sites is crawl depth-optimalisatie nog belangrijker. Hreflang-tags en een goede URL-structuur voor verschillende taalversies kunnen de crawlefficiëntie beïnvloeden. Door ervoor te zorgen dat elke taalversie een geoptimaliseerde crawl depth-structuur heeft, maximaliseer je de indexatie in alle markten. Evenzo betekent mobile-first indexing dat crawl depth-optimalisatie rekening moet houden met zowel desktop- als mobiele versies, zodat belangrijke content op beide platforms toegankelijk is.
Het belang van crawl depth verandert mee met de ontwikkeling van zoektechnologie. Met de opkomst van AI-zoekmachines en generatieve AI-systemen wordt crawl depth-optimalisatie relevant voor een breder publiek dan alleen traditionele SEO-specialisten. Naarmate AI-systemen geavanceerder worden, kunnen ze andere crawlpatronen en prioriteiten ontwikkelen, wat crawl depth-optimalisatie mogelijk nóg belangrijker maakt. Ook de toenemende hoeveelheid AI-gegenereerde content legt extra druk op de index van Google, waardoor crawlbudgetbeheer belangrijker wordt dan ooit.
Vooruitkijkend zijn er verschillende trends die crawl depth-optimalisatie zullen beïnvloeden. Ten eerste worden AI-gedreven crawl-optimalisatietools geavanceerder, met machine learning om optimale crawl depth-structuren voor verschillende type sites te identificeren. Ten tweede wordt real-time crawlmonitoring standaard, waarmee site-eigenaren precies kunnen zien hoe crawlers hun site navigeren en direct aanpassingen kunnen doen. Ten derde worden crawl depth-metrics geïntegreerd in SEO-platformen en analysetools, zodat ook niet-technische marketeers dit kritieke aspect kunnen optimaliseren.
De relatie tussen crawl depth en AI-zoekzichtbaarheid wordt waarschijnlijk een belangrijk aandachtspunt voor SEO-professionals. Nu steeds meer gebruikers AI-zoekmachines raadplegen, moeten bedrijven niet alleen voor traditionele zoekopdrachten optimaliseren, maar ook voor AI-vindbaarheid. Dit betekent dat crawl depth-optimalisatie deel zal uitmaken van een bredere generative engine optimization (GEO)-strategie die zowel traditionele SEO als AI-zoekzichtbaarheid omvat. Organisaties die crawl depth-optimalisatie vroegtijdig beheersen, hebben een concurrentievoordeel in het AI-gedreven zoeklandschap.
Tot slot kan het concept crawl depth zich verder ontwikkelen naarmate zoektechnologieën geavanceerder worden. Toekomstige zoekmachines kunnen andere methoden gebruiken om content te ontdekken en te indexeren, waardoor het belang van traditionele crawl depth mogelijk afneemt. Maar het onderliggende principe—dat makkelijk toegankelijke, goed gestructureerde content sneller wordt gevonden en gerankt—zal waarschijnlijk relevant blijven. Investeren in crawl depth-optimalisatie is daarom een solide langetermijnstrategie om zoekzichtbaarheid te behouden op zowel huidige als toekomstige zoekplatformen.
Crawl depth meet hoe ver zoekmachinebots navigeren door de hiërarchie van je site op basis van interne links en URL-structuur, terwijl click depth meet hoeveel gebruikersklikken nodig zijn om vanaf de homepage een pagina te bereiken. Een pagina kan een click depth van 1 hebben (gelinkt in de footer) maar een crawl depth van 3 (genest in de URL-structuur). Crawl depth is vanuit het perspectief van de zoekmachine, click depth is vanuit de gebruiker.
Crawl depth heeft geen directe invloed op rankings, maar bepaalt wel sterk of pagina's überhaupt worden geïndexeerd. Pagina's die diep in je sitestructuur zitten, worden minder snel gecrawld binnen het toegewezen crawlbudget, waardoor ze mogelijk niet of minder vaak worden geïndexeerd. Deze verminderde indexatie en actualiteit kunnen indirect de rankings schaden. Pagina's dichter bij de homepage ontvangen doorgaans meer crawl-attentie en link equity, wat hun rankingpotentieel vergroot.
De meeste SEO-experts adviseren om belangrijke pagina's binnen 3 klikken van de homepage te houden. Zo zijn ze eenvoudig vindbaar voor zowel zoekmachines als gebruikers. Voor grotere websites met duizenden pagina's is enige diepte onvermijdelijk, maar het doel moet zijn om kritieke pagina's zo oppervlakkig mogelijk te houden. Pagina's op diepte 3 en dieper presteren doorgaans slechter in zoekresultaten door verminderde crawlfrequentie en link equity-distributie.
Crawl depth beïnvloedt direct hoe efficiënt je je crawlbudget benut. Google wijst elk domein een specifiek crawlbudget toe op basis van crawl capacity limit en crawl demand. Als je site teveel diepte heeft en veel pagina's diep begraven zijn, kan de crawler zijn budget besteden voordat alle belangrijke pagina's bereikt zijn. Door crawl depth te optimaliseren en onnodige lagen te verminderen, zorg je dat je waardevolste content binnen het budget wordt gecrawld en geïndexeerd.
Ja, je kunt de crawlefficiëntie verbeteren zonder je volledige site te herstructureren. Strategische interne linking is de meest effectieve aanpak—link belangrijke diepe pagina's vanaf je homepage, categoriepagina's of autoritatieve content. Ook het regelmatig updaten van je XML-sitemap, het herstellen van gebroken links en het verminderen van redirect chains helpen crawlers efficiënter pagina's te bereiken. Deze tactieken verbeteren crawl depth zonder architecturale aanpassingen.
AI-zoekmachines zoals Perplexity, ChatGPT en Google AI Overviews gebruiken hun eigen gespecialiseerde crawlers (PerplexityBot, GPTBot, enz.) die mogelijk andere crawlpatronen hebben dan Googlebot. Toch houden deze AI-crawlers rekening met crawl depth—pagina's die makkelijk toegankelijk en goed gelinkt zijn, worden sneller ontdekt en als bron gebruikt. Crawl depth optimaliseren is dus nuttig voor zowel traditionele zoekmachines als AI-systemen en vergroot je zichtbaarheid op alle zoekplatformen.
Tools zoals Google Search Console, Screaming Frog SEO Spider, seoClarity en Hike SEO bieden crawl depth-analyse en visualisatie. Google Search Console toont crawlstatistieken en frequentie, terwijl gespecialiseerde SEO-crawlers de hiërarchische structuur van je site visualiseren en pagina's met overmatige diepte identificeren. Met deze tools kun je optimalisatiemogelijkheden ontdekken en verbeteringen in crawlefficiëntie volgen.
Begin met het volgen van hoe AI-chatbots uw merk vermelden op ChatGPT, Perplexity en andere platforms. Krijg bruikbare inzichten om uw AI-aanwezigheid te verbeteren.
Crawl rate is de snelheid waarmee zoekmachines je website crawlen. Leer hoe dit de indexering, SEO-prestaties en zichtbaarheid in zoekresultaten beïnvloedt en h...

Crawl budget is het aantal pagina's dat zoekmachines op je website crawlen binnen een bepaalde periode. Leer hoe je het crawl budget optimaliseert voor betere i...
Crawlfrequentie is hoe vaak zoekmachines en AI-crawlers je site bezoeken. Leer wat de crawl rates beïnvloedt, waarom het belangrijk is voor SEO en AI-zichtbaarh...