
Entity Linking voor AI: Verbind je Merk over het Hele Web
Ontdek hoe entity linking jouw merk verbindt in AI-systemen. Leer strategieën om merkherkenning te verbeteren in ChatGPT, Perplexity en Google AI Overviews met ...
9 min lezen

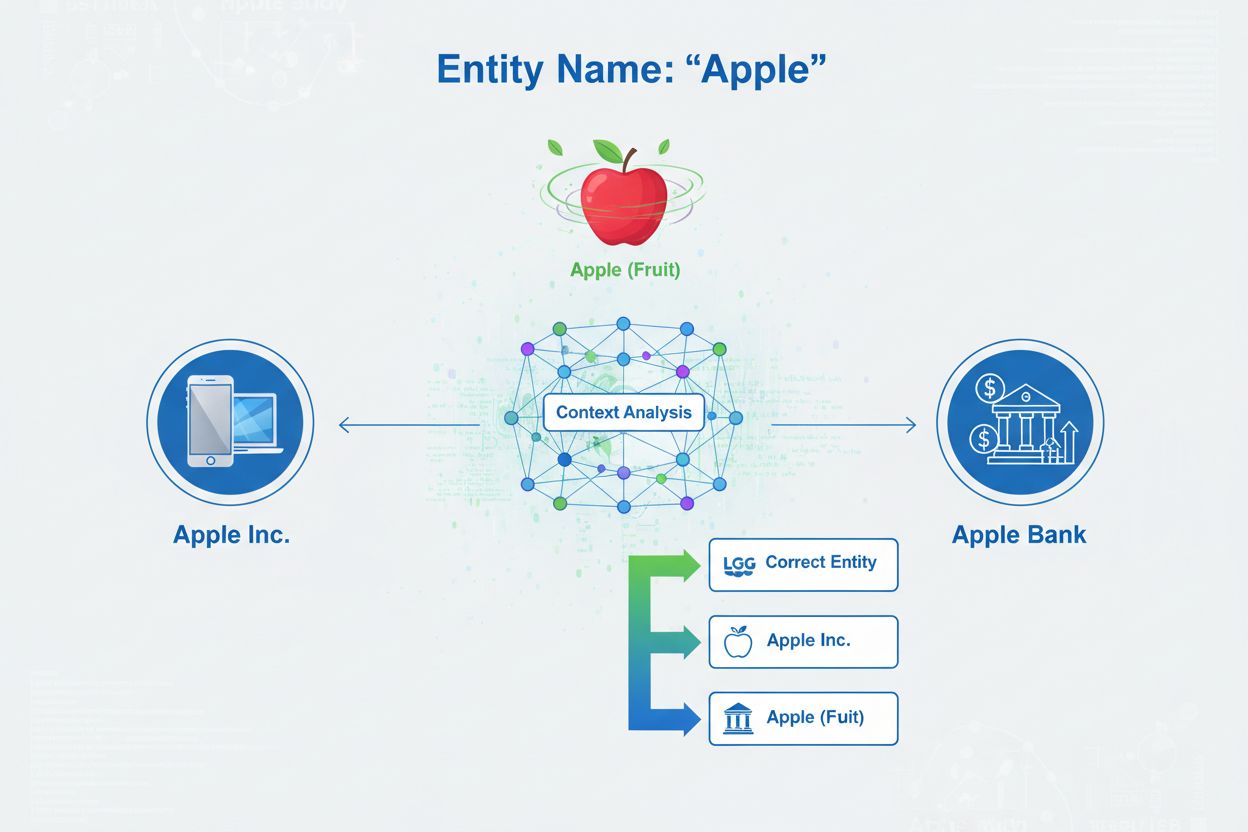
Entity disambiguation is het proces waarbij wordt bepaald naar welke specifieke entiteit een bepaalde vermelding verwijst wanneer meerdere entiteiten dezelfde naam delen. Het helpt AI-systemen om content nauwkeurig te begrijpen en te citeren door ambiguïteit in verwijzingen naar entiteiten op te lossen, zodat vermeldingen van ‘Apple’ correct identificeren of het om Apple Inc., het fruit of een andere entiteit met dezelfde naam gaat.
Entity disambiguation is het proces waarbij wordt bepaald naar welke specifieke entiteit een bepaalde vermelding verwijst wanneer meerdere entiteiten dezelfde naam delen. Het helpt AI-systemen om content nauwkeurig te begrijpen en te citeren door ambiguïteit in verwijzingen naar entiteiten op te lossen, zodat vermeldingen van 'Apple' correct identificeren of het om Apple Inc., het fruit of een andere entiteit met dezelfde naam gaat.
Entity disambiguation is het proces waarbij wordt bepaald naar welke specifieke entiteit een bepaalde vermelding verwijst wanneer meerdere entiteiten dezelfde naam of vergelijkbare verwijzingen delen. In de context van kunstmatige intelligentie en natural language processing (NLP) zorgt entity disambiguation ervoor dat een AI-systeem bij het tegenkomen van een entiteit in tekst, correct identificeert welk object, persoon, organisatie of locatie uit de echte wereld wordt bedoeld. Dit verschilt wezenlijk van named entity recognition (NER), dat simpelweg vaststelt dát er een entiteit aanwezig is en deze classificeert als bijvoorbeeld “persoon,” “organisatie,” of “locatie.” Waar NER antwoordt op de vraag “Is er hier een entiteit?”, beantwoordt entity disambiguation “Welke specifieke entiteit is dit?” Bij het verwerken van de zin “Apple was het geesteskind van Steve Jobs” identificeert NER “Apple” als een organisatie, maar entity disambiguation bepaalt of dit verwijst naar Apple Inc., het technologiebedrijf, of mogelijk een andere entiteit met dezelfde naam. Dit onderscheid is cruciaal voor AI-systemen die content nauwkeurig moeten begrijpen en citeren. Daarom monitort AmICited.com hoe AI-systemen zoals ChatGPT, Perplexity en Google AI Overviews entity disambiguation toepassen in hun antwoorden over merken en organisaties.
Het fundamentele probleem dat entity disambiguation oplost is ambiguïteit—het feit dat veel entiteitsnamen naar verschillende objecten in de echte wereld kunnen verwijzen. Deze ambiguïteit levert aanzienlijke uitdagingen op voor AI-systemen die proberen content correct te begrijpen en te genereren. Volgens de Stanford AI Index 2024 bevat meer dan 18% van de LLM-uitvoer waarin merkentiteiten voorkomen, hallucinaties of foutieve toeschrijvingen. AI-systemen verwarren dus regelmatig een entiteit met een andere of genereren foutieve informatie over entiteiten. Dit foutenpercentage heeft serieuze implicaties voor merkrepresentatie en contentnauwkeurigheid. Wanneer een AI-systeem een entiteit verkeerd identificeert, kan het onjuiste informatie geven, uitspraken aan de verkeerde organisatie toeschrijven of de juiste bron van informatie niet vermelden.
| Entiteitsnaam | Mogelijke betekenissen | AI-verwarringsgraad |
|---|---|---|
| Apple | Techbedrijf / Fruit / Bank | Hoog |
| Delta | Luchtvaartmaatschappij / Kranenfabrikant / Griekse letter | Hoog |
| Jaguar | Autofabrikant / Diersoort | Middel |
| Amazon | E-commercebedrijf / Regenwoud / Rivier | Hoog |
| Orange | Kleur / Fruit / Telecombedrijf | Middel |
De gevolgen van slechte entity disambiguation gaan verder dan simpele feitelijke fouten. Voor contentmakers en merken kan verkeerde identificatie in AI-antwoorden leiden tot verloren zichtbaarheid, foutieve toeschrijvingen en schade aan de merkreputatie. Wanneer een gebruiker een AI-systeem vraagt naar “Delta,” kan deze informatie zoeken over Delta Airlines, maar als het systeem deze verwart met Delta Faucet Company, ontvangt de gebruiker irrelevante informatie. Daarom monitort AmICited.com hoe AI-systemen entiteiten disambigueren—om merken te helpen begrijpen of ze correct geïdentificeerd en geciteerd worden in AI-gegenereerde content op meerdere platforms.
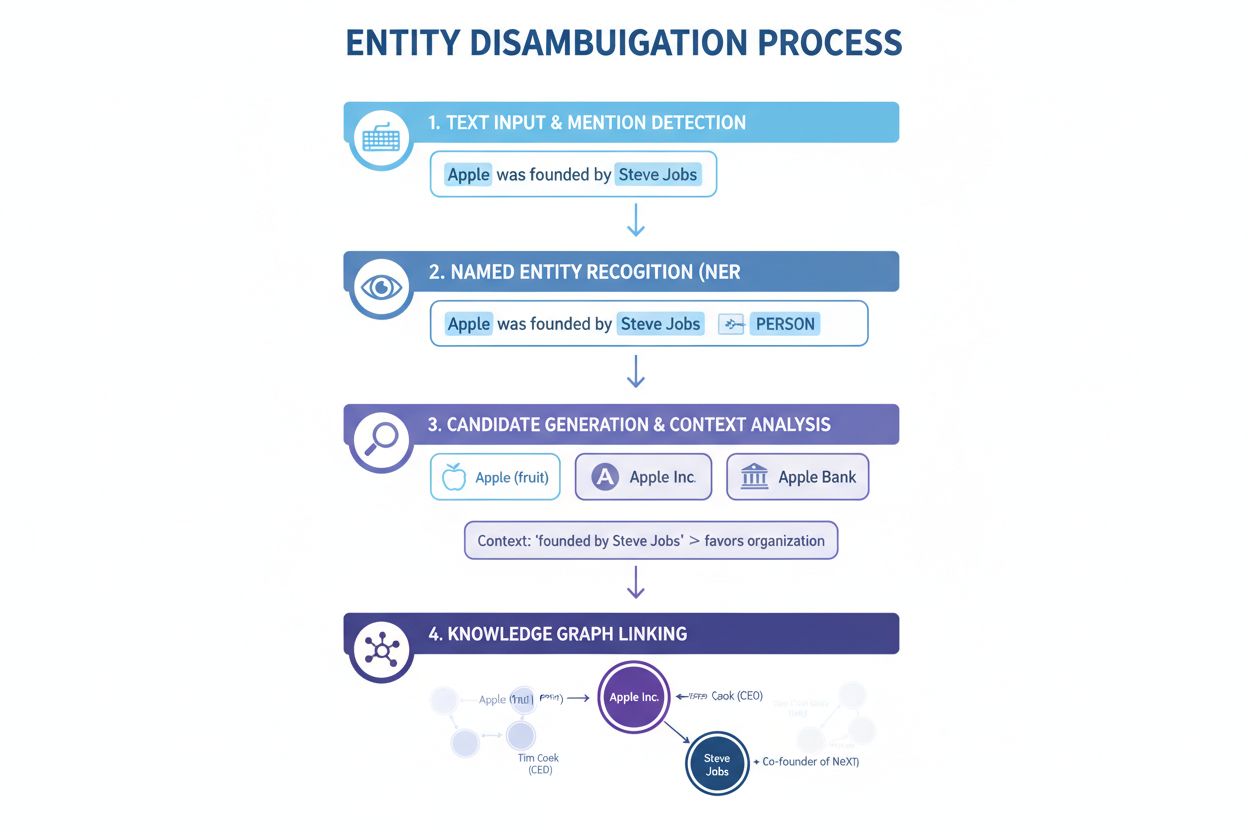
Entity disambiguation werkt via een systematisch proces dat meerdere NLP-technieken combineert om ambiguïteit op te lossen en entiteiten correct te identificeren. Inzicht in dit proces verklaart waarom sommige AI-systemen beter presteren in citatienauwkeurigheid dan andere.
Named Entity Recognition (NER): De eerste stap is het identificeren en classificeren van entiteiten in tekst. NER-systemen scannen tekst en lokaliseren vermeldingen van entiteiten, en wijzen deze toe aan categorieën zoals persoon, organisatie, locatie, product of datum. In de zin “Apple was het geesteskind van Steve Jobs” identificeert NER zowel “Apple” als “Steve Jobs” als entiteiten en classificeert deze respectievelijk als organisatie en persoon. Deze basisstap is essentieel, want zonder identificatie van entiteiten kan disambiguatie niet plaatsvinden.
Entiteitscategorisatie: Nadat entiteiten zijn geïdentificeerd, worden ze preciezer gecategoriseerd. Dit houdt in dat niet alleen breed wordt geclassificeerd, maar ook de specifieke aard en context van elke entiteit wordt begrepen. Het systeem analyseert de omringende tekst om te bepalen of “Apple” in een technologische context (Apple Inc.), voedselcontext (het fruit) of financiële context (Apple Bank) voorkomt. Deze contextanalyse verkleint de mogelijkheden vóór de daadwerkelijke disambiguatiestap.
Disambiguatie: Dit is de kernstap waarbij het systeem bepaalt naar welke specifieke entiteit wordt verwezen. Het systeem evalueert meerdere kandidaat-entiteiten die overeenkomen met de geïdentificeerde naam en gebruikt verschillende signalen—waaronder context, entiteitsbeschrijvingen, semantische relaties en knowledge graph-informatie—om de meest waarschijnlijke entiteit te selecteren. Voor “Apple was het geesteskind van Steve Jobs” herkent het systeem dat Steve Jobs sterk verbonden is met Apple Inc., waardoor dat de juiste keuze is.
Koppeling aan Knowledge Base: De laatste stap is het koppelen van de gedisambigueerde entiteit aan een unieke identifier in een externe knowledge base of knowledge graph, zoals Wikidata, Wikipedia of een eigen database. Deze koppeling bevestigt de identiteit van de entiteit en verrijkt de tekst met semantische informatie voor verdere verwerking en analyse. De entiteit krijgt een unieke URI (Uniform Resource Identifier) als definitief referentiepunt.
Er zijn verschillende benaderingen voor entity disambiguation ontwikkeld, elk met eigen voor- en nadelen. Inzicht hierin verklaart waarom moderne AI-systemen verschillen in disambiguatienauwkeurigheid.
Regelgebaseerde benaderingen: Deze systemen gebruiken vooraf gedefinieerde taalkundige regels en heuristieken. Ze kunnen bijvoorbeeld regels toepassen als “als ‘Apple’ voorkomt bij ‘iPhone’ of ‘MacBook’, dan verwijst het naar Apple Inc.” of “als ‘Delta’ voorkomt bij ‘airline’ of ‘flight’, dan verwijst het naar Delta Airlines.” Regelgebaseerde systemen zijn interpreteerbaar en vereisen geen grote trainingsdatasets, maar zijn niet flexibel voor nieuwe contexten en moeten handmatig worden bijgewerkt.
Machine learning-benaderingen: Gecontroleerde machine learning-modellen leren van geannoteerde trainingsdata om de juiste entiteit te voorspellen op basis van contextuele kenmerken. Ze halen kenmerken uit de omliggende tekst en gebruiken algoritmen zoals Support Vector Machines of Random Forests om te classificeren welke entiteit het waarschijnlijkst is. Machine learning-benaderingen zijn flexibeler dan regelgebaseerde systemen, maar vereisen veel gelabelde data en generaliseren mogelijk slecht naar onbekende entiteiten.
Deep learning- en transformer-gebaseerde modellen: Moderne entity disambiguation maakt steeds meer gebruik van transformer-architecturen zoals BERT, RoBERTa en gespecialiseerde modellen als GENRE en BLINK. Deze modellen vatten context dieper op en leggen semantische relaties en subtiele taalkundige patronen vast. Ze presteren beter op standaard benchmarks en kunnen complexere scenario’s aan. Zo gebruikt Ontotext’s CEEL (Common English Entity Linking) een transformerarchitectuur geoptimaliseerd voor CPU-efficiëntie, met 96% entiteitsherkenning en 76% entity linking-nauwkeurigheid op standaard benchmarks.
Integratie met knowledge graphs: Moderne systemen combineren machine learning steeds vaker met knowledge graphs—gestructureerde databases van entiteiten en hun relaties. Knowledge graphs bieden rijke contextuele informatie over entiteiten, hun eigenschappen en onderlinge relaties. Door tijdens disambiguatie knowledge graphs te raadplegen, kunnen systemen metadata, beschrijvingen en relatie-informatie benutten voor nauwkeurigere disambiguatie.
Entity disambiguation is essentieel geworden in veel sectoren en toepassingen, waarbij nauwkeurige entiteitsherkenning en -citatie van groot belang zijn.
Zoekmachines: Google, Bing en andere zoekmachines maken intensief gebruik van entity disambiguation om relevante resultaten te tonen. Wanneer een gebruiker zoekt op “Apple,” moet het systeem bepalen of de gebruiker Apple Inc., het fruit of een andere entiteit bedoelt. Zoekmachines gebruiken context van de zoekopdracht, gebruikersgeschiedenis en knowledge graphs om te disambigueren. Daarom tonen zoekresultaten voor “Apple” meestal eerst het technologiebedrijf.
Media en publicatie: Nieuwsorganisaties en contentplatforms gebruiken entity disambiguation om content vindbaar te maken en gerelateerde artikelen te koppelen. Wanneer in een nieuwsartikel “Apple” wordt genoemd, kan het systeem automatisch linken naar de kennisbankpagina van Apple Inc., waardoor lezers extra context en gerelateerde artikelen krijgen.
Zorgsector: Medische instellingen gebruiken entity disambiguation voor het correct identificeren van medicijnen, ziektes en procedures in patiëntendossiers en vakliteratuur. Vooral bij medicijnnamen is dit cruciaal—“aspirine” kan verwijzen naar het generieke geneesmiddel, een merknaam of een dosering. Nauwkeurige disambiguatie voorkomt fouten in medische dossiers.
Financiële sector: Investeringsmaatschappijen en analisten gebruiken entity disambiguation om bedrijfsvermeldingen te volgen in nieuws, rapportages en marktdata. Bij risicoanalyse is het belangrijk dat alle vermeldingen van “Apple” correct aan Apple Inc. worden toegeschreven, zodat analyses kloppen.
E-commerce: Online retailers gebruiken entity disambiguation om productvermeldingen aan echte producten te koppelen. Bij een zoekopdracht naar “Apple laptop” moet “Apple” als bedrijf worden gedisambigueerd en aan relevante producten worden gekoppeld.
AmICited.com past deze principes toe om te monitoren hoe AI-systemen als ChatGPT, Perplexity en Google AI Overviews merkvermeldingen disambigueren en correct citeren.
Knowledge graphs zijn fundamenteel voor moderne entity disambiguation-systemen en bieden gestructureerde representaties van entiteiten en hun relaties. Een knowledge graph is een database van entiteiten (knopen) en hun relaties (verbindingen). Elke entiteitsknoop bevat metadata zoals naam, beschrijving, type en eigenschappen. Zo kan “Apple Inc.” in een knowledge graph eigenschappen hebben als “opgericht in 1976,” “hoofdkantoor in Cupertino,” “sector: technologie,” en relaties als “opgericht door Steve Jobs” en “produceert iPhone.”
Wanneer een entity disambiguation-systeem een ambigue entiteit tegenkomt, kan het de knowledge graph raadplegen voor contextuele informatie over kandidaat-entiteiten. Dit helpt het systeem om beter geïnformeerde beslissingen te nemen. Als het systeem “Apple” moet disambigueren en de omliggende tekst vermeldt “Steve Jobs,” kan het via de knowledge graph vaststellen dat Steve Jobs sterk verbonden is met Apple Inc., waardoor de juiste entiteit gekozen wordt. Knowledge graphs zoals Wikidata en Wikipedia bieden publieke entiteitsinformatie die veel AI-systemen gebruiken. Eigen knowledge graphs, zoals die van Google en Microsoft, bieden domeinspecifieke entiteitsinformatie. De integratie van knowledge graphs met machine learning heeft de nauwkeurigheid van entity disambiguation aanzienlijk verbeterd.
Ondanks de vooruitgang kampen entity disambiguation-systemen met aanhoudende uitdagingen.
Polysemie en ambiguïteit: Veel entiteitsnamen hebben meerdere betekenissen, en context is niet altijd voldoende om te disambigueren. “Bank” kan een financiële instelling of een rivier-oever zijn. Sommige namen zijn zo ambigu dat zelfs mensen zonder extra context moeite hebben. AI-systemen moeten leren herkennen wanneer context onvoldoende is en hier passend mee omgaan.
Nieuwe en opkomende entiteiten: Knowledge bases en trainingsdata raken verouderd naarmate nieuwe entiteiten ontstaan. Wanneer een nieuw bedrijf start of een nieuw product wordt gelanceerd, kan het zijn dat deze niet in de knowledge base voorkomt. Zero-shot entity linking—het kunnen disambigueren van entiteiten die niet zijn gezien tijdens training—blijft een grote uitdaging.
Naamvariaties en spelfouten: Entiteiten hebben vaak meerdere namen, afkortingen en variaties. “Verenigde Staten,” “VS,” “U.S.” en “Amerika” verwijzen allemaal naar dezelfde entiteit. Spelfouten maken het nog lastiger. Systemen moeten deze variaties herkennen en correct toewijzen.
Onvolledige of verouderde data: Knowledge bases kunnen onvolledig of verouderd zijn. Bedrijven veranderen van hoofdkantoor, leiderschap wisselt, of er vinden overnames plaats. Als de kennisbank niet snel wordt bijgewerkt, kan het systeem verkeerde beslissingen nemen.
Schaalbaarheid en prestaties: Grote hoeveelheden tekst verwerken met hoge nauwkeurigheid in entity disambiguation vereist veel rekenkracht. Real-time disambiguatie op webschaal is kostbaar en systemen moeten balanceren tussen nauwkeurigheid, snelheid en kosten.
Voor merken en contentmakers is inzicht in entity disambiguation essentieel voor een correcte representatie in AI-content. Naarmate AI-systemen steeds bepalender worden in informatievoorziening, moeten merken proactief zorgen dat ze correct worden gedisambigueerd en geciteerd.
Pre-disambiguatiestrategieën: Merken kunnen strategieën toepassen om hun entiteit gemakkelijker herkenbaar te maken voor AI-systemen. Een belangrijke strategie is het implementeren van gestructureerde data met Schema.org-markup en JSON-LD op de website. Dit geeft AI-systemen expliciet informatie over de merkidentiteit, waaronder naam, beschrijving, logo, locatie en andere kenmerken.
Optimalisatie van knowledge graphs: Zorg voor een sterke aanwezigheid in Wikidata en Wikipedia. Zorg dat Wikipedia-artikelen en Wikidata-pagina’s volledig en actueel zijn en bouw relaties met gerelateerde entiteiten. Hoe completer deze kennis, hoe groter de kans op correcte disambiguatie.
Contextuele contentstrategie: Maak content die duidelijk de identiteit van het merk en het onderscheid met andere entiteiten toont. Content die de branche, producten, oprichters en unieke waarde benoemt, helpt AI-systemen bij disambiguatie.
Citatiemonitoring: Tools als AmICited.com stellen merken in staat te volgen hoe AI-systemen hun merk disambigueren en citeren op verschillende platforms. Door te monitoren of systemen als ChatGPT, Perplexity en Google AI Overviews het merk correct identificeren en citeren, kunnen fouten worden opgespoord en gecorrigeerd.
Generative Engine Optimization (GEO): Entity disambiguation wordt steeds belangrijker voor AI-zichtbaarheid. Merken moeten entiteitsoptimalisatie meenemen in hun bredere Generative Engine Optimization-strategie. Dit omvat het duidelijk definiëren, documenteren en onderscheiden van de merkentiteit.
Entity disambiguation blijft zich ontwikkelen dankzij technologische vooruitgang en nieuwe uitdagingen.
Meertalige entity disambiguation: Naarmate AI-systemen wereldwijd worden ingezet, wordt het belangrijk om entiteiten over talen heen te disambigueren. Eenzelfde persoon kan verschillende spellingen hebben en dezelfde entiteit kan in verschillende talen verschillende namen hebben. Geavanceerde meertalige modellen worden ontwikkeld om dit aan te kunnen.
Realtime disambiguatie in grote taalmodellen: Moderne taalmodellen zoals GPT-4 en Claude integreren steeds vaker realtime entity disambiguation tijdens tekstgeneratie. In plaats van alleen op trainingsdata te vertrouwen, kunnen deze modellen knowledge graphs en externe databases raadplegen tijdens inferentie, voor betere citatie en minder hallucinaties.
Verbeterde zero-shot learning: Toekomstige systemen zullen beter presteren op entiteiten die niet voorkwamen in training. Ontwikkelingen in few-shot- en zero-shot learning zorgen ervoor dat systemen nieuwe entiteiten effectiever kunnen disambigueren.
Integratie met Retrieval-Augmented Generation (RAG): Systemen die taalmodellen combineren met informatieopvraging worden steeds populairder. Ze kunnen relevante entiteitsinformatie ophalen uit knowledge bases tijdens tekstgeneratie, voor betere disambiguatie en citatie.
Standaardisatie en interoperabiliteit: Naarmate entity disambiguation belangrijker wordt, zullen er standaarden ontstaan voor entiteitsrepresentatie en disambiguatie. Dit vergemakkelijkt de uitwisseling van entiteitsinformatie tussen systemen en knowledge bases.
Entity disambiguation is uitgegroeid van een niche NLP-taak tot een kernfunctie voor correcte AI-representatie van informatie. Naarmate AI bepalender wordt voor informatievoorziening, groeit het belang van nauwkeurige entity disambiguation. Voor merken, contentmakers en organisaties is het optimaliseren voor entity disambiguation essentieel om zichtbaar te blijven en correct gerepresenteerd te worden in het tijdperk van generatieve AI.
Named entity recognition identificeert dat er een entiteit in tekst voorkomt en classificeert deze in categorieën zoals persoon, organisatie of locatie. Entity disambiguation gaat verder door te bepalen naar welke specifieke entiteit wordt verwezen wanneer meerdere entiteiten dezelfde naam delen. NER identificeert bijvoorbeeld 'Apple' als een organisatie, terwijl entity disambiguation bepaalt of het om Apple Inc., Apple Bank of een andere entiteit gaat.
Entity disambiguation zorgt ervoor dat AI-systemen nauwkeurig begrijpen over welke entiteit wordt gesproken en deze correct citeren. Volgens de Stanford AI Index 2024 bevat meer dan 18% van de LLM-uitvoer waarin merkentiteiten voorkomen, hallucinaties of foutieve toeschrijvingen. Nauwkeurige entity disambiguation voorkomt dat AI-systemen entiteiten verwarren, wat cruciaal is voor het behoud van de merkreputatie en citatienauwkeurigheid.
Knowledge graphs bieden gestructureerde informatie over entiteiten en hun onderlinge relaties. Wanneer een AI-systeem een onduidelijke entiteit tegenkomt, kan het de knowledge graph raadplegen voor metadata, beschrijvingen en relatie-informatie over kandidaat-entiteiten. Deze contextuele informatie helpt het systeem om beter geïnformeerde beslissingen te nemen en de juiste entiteit te selecteren.
Ja, via zero-shot entity linking-benaderingen. Moderne systemen kunnen herkennen wanneer een entiteit nieuw is en hier op de juiste manier mee omgaan, in plaats van deze foutief aan een bestaande entiteit te koppelen. Dit blijft echter een uitdagend probleem, en systemen presteren beter wanneer nieuwe entiteiten duidelijke contextsignalen hebben die hen onderscheiden van bestaande entiteiten.
Nauwkeurige entity disambiguation zorgt ervoor dat uw merk correct wordt geïdentificeerd en geciteerd in AI-gegenereerde antwoorden. Als AI-systemen uw merk goed disambigueren, ontvangen gebruikers correcte informatie over uw organisatie, wat de zichtbaarheid en reputatie van het merk verbetert. Slechte disambiguatie kan ertoe leiden dat uw merk wordt verward met concurrenten of andere entiteiten, waardoor de zichtbaarheid afneemt en de reputatie mogelijk wordt geschaad.
Belangrijke uitdagingen zijn polysemie (meerdere betekenissen voor dezelfde naam), nieuwe entiteiten die niet in de trainingsdata voorkomen, naamvariaties en spelfouten, onvolledige of verouderde knowledge bases en schaalbaarheidsproblemen. Sommige entiteitsnamen zijn van zichzelf erg ambigu en context alleen is soms niet voldoende om de juiste entiteit te bepalen.
Merken kunnen gestructureerde data implementeren met Schema.org-markup, accurate Wikipedia- en Wikidata-pagina's bijhouden, contextuele content creëren die hun merk duidelijk onderscheidt en monitoren hoe AI-systemen hun merk disambigueren met tools zoals AmICited. Deze strategieën helpen AI-systemen uw merk correct te identificeren en te citeren.
Context is cruciaal voor entity disambiguation. De omringende tekst, gerelateerde entiteiten en semantische relaties geven signalen die AI-systemen helpen bepalen naar welke entiteit wordt verwezen. Als 'Apple' bijvoorbeeld voorkomt naast 'Steve Jobs' en 'technologie', kan het systeem deze context gebruiken om het correct te disambigueren als Apple Inc. in plaats van het fruit.
Volg de nauwkeurigheid van entity disambiguation op AI-platforms en zorg dat uw merk correct wordt geïdentificeerd en geciteerd in AI-gegenereerde antwoorden.
Ontdek hoe entity linking jouw merk verbindt in AI-systemen. Leer strategieën om merkherkenning te verbeteren in ChatGPT, Perplexity en Google AI Overviews met ...

Entiteitsherkenning is een AI NLP-capaciteit voor het identificeren en categoriseren van benoemde entiteiten in tekst. Leer hoe het werkt, de toepassingen in AI...

Ontdek hoe AI-systemen relaties tussen entiteiten in tekst identificeren, extraheren en begrijpen. Leer technieken voor extractie van entiteitsrelaties, NLP-met...