
SearchGPT
Ontdek wat SearchGPT is, hoe het werkt en de impact op zoeken, SEO en digitale marketing. Bekijk functies, beperkingen en de toekomst van door AI aangedreven zo...
9 min lezen
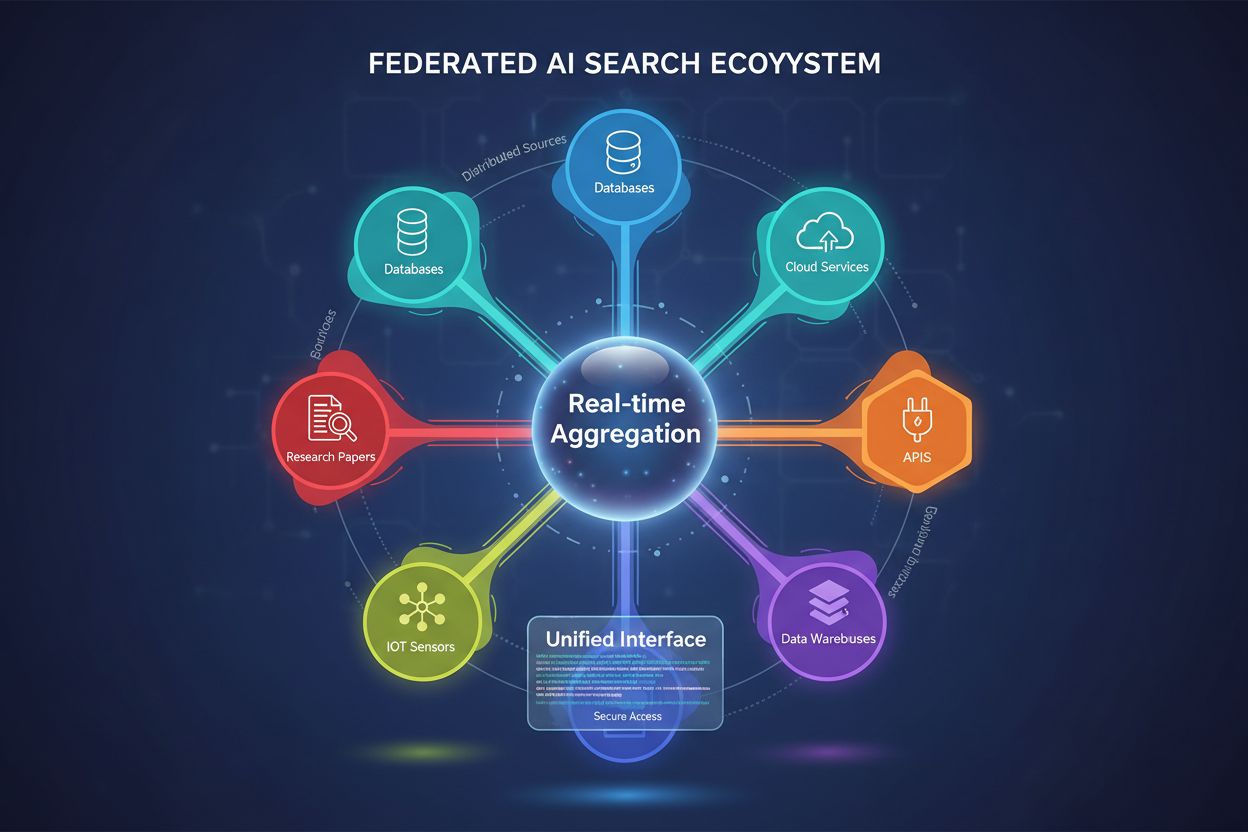
Federated AI Search is een systeem dat gelijktijdig meerdere onafhankelijke databronnen bevraagt met één enkele zoekopdracht en de resultaten in real-time samenvoegt zonder data te verplaatsen of te dupliceren. Het stelt organisaties in staat om verspreide informatie uit databases, API’s en cloudservices te benaderen, terwijl dataveiligheid en compliance worden behouden. In tegenstelling tot traditionele gecentraliseerde zoekmachines behouden federatieve systemen de autonomie van databronnen en bieden ze toch een eendrachtige informatieontdekking. Deze aanpak is vooral waardevol voor bedrijven die diverse databronnen beheren over verschillende afdelingen, locaties of organisaties.
Federated AI Search is een systeem dat gelijktijdig meerdere onafhankelijke databronnen bevraagt met één enkele zoekopdracht en de resultaten in real-time samenvoegt zonder data te verplaatsen of te dupliceren. Het stelt organisaties in staat om verspreide informatie uit databases, API's en cloudservices te benaderen, terwijl dataveiligheid en compliance worden behouden. In tegenstelling tot traditionele gecentraliseerde zoekmachines behouden federatieve systemen de autonomie van databronnen en bieden ze toch een eendrachtige informatieontdekking. Deze aanpak is vooral waardevol voor bedrijven die diverse databronnen beheren over verschillende afdelingen, locaties of organisaties.
Federated AI Search is een gedistribueerd informatie-ophaalsysteem dat gelijktijdig meerdere heterogene databronnen bevraagt en de resultaten intelligent samenvoegt met behulp van kunstmatige intelligentie. In tegenstelling tot traditionele gecentraliseerde zoekmachines met één enkele geïndexeerde opslagplaats, werkt federated AI search over gedecentraliseerde netwerken van onafhankelijke databases, kennisbanken en informatiesystemen zonder data te consolideren of centraal te indexeren.
Het kernprincipe van federated AI search is bron-agnostisch zoeken, waarbij een enkele gebruikersquery intelligent wordt doorgestuurd naar relevante databronnen, onafhankelijk door elke bron wordt verwerkt en vervolgens wordt samengevoegd tot een eendrachtig resultaat. Deze aanpak behoudt de autonomie van data en maakt uitgebreide informatieontdekking over organisatorische en technische grenzen heen mogelijk.
Belangrijkste kenmerken van federated AI search-systemen zijn:
Gedistrubueerde Architectuur: Data blijft op de oorspronkelijke locatie in meerdere opslagplaatsen, waardoor datamigratie of centrale opslag niet nodig is. Elke bron onderhoudt zijn eigen indexering, toegangscontrole en update-mechanismen.
Intelligente Queryrouting: AI-algoritmen analyseren binnenkomende zoekopdrachten om te bepalen welke bronnen waarschijnlijk relevante informatie bevatten, wat de zoekeffectiviteit optimaliseert en onnodige zoekopdrachten naar irrelevante databases vermindert.
Resultaataggregatie en -rangschikking: Machine learning-modellen synthetiseren resultaten van meerdere bronnen, waarbij geavanceerde rangschikkingsalgoritmen worden toegepast die bronbetrouwbaarheid, relevantie, actualiteit en gebruikerscontext meenemen.
Ondersteuning voor Heterogene Bronnen: Federatieve systemen ondersteunen uiteenlopende dataformaten, schema’s, querytalen en toegangsprotocollen, waaronder relationele databases, documentopslagplaatsen, kennisgrafen, API’s en ongestructureerde tekstarchieven.
Real-time Integratie: In tegenstelling tot batch-gebaseerde datawarehousing biedt federated search vrijwel real-time toegang tot actuele informatie uit alle aangesloten bronnen, wat de actualiteit en nauwkeurigheid van resultaten waarborgt.
Semantisch Begrip: Moderne federatieve AI-zoekoplossingen maken gebruik van natuurlijke taalverwerking en semantische analyse om de query-intentie te begrijpen, voorbij alleen keyword-matching, waardoor accuratere bronselectie en interpretatie van resultaten mogelijk is.
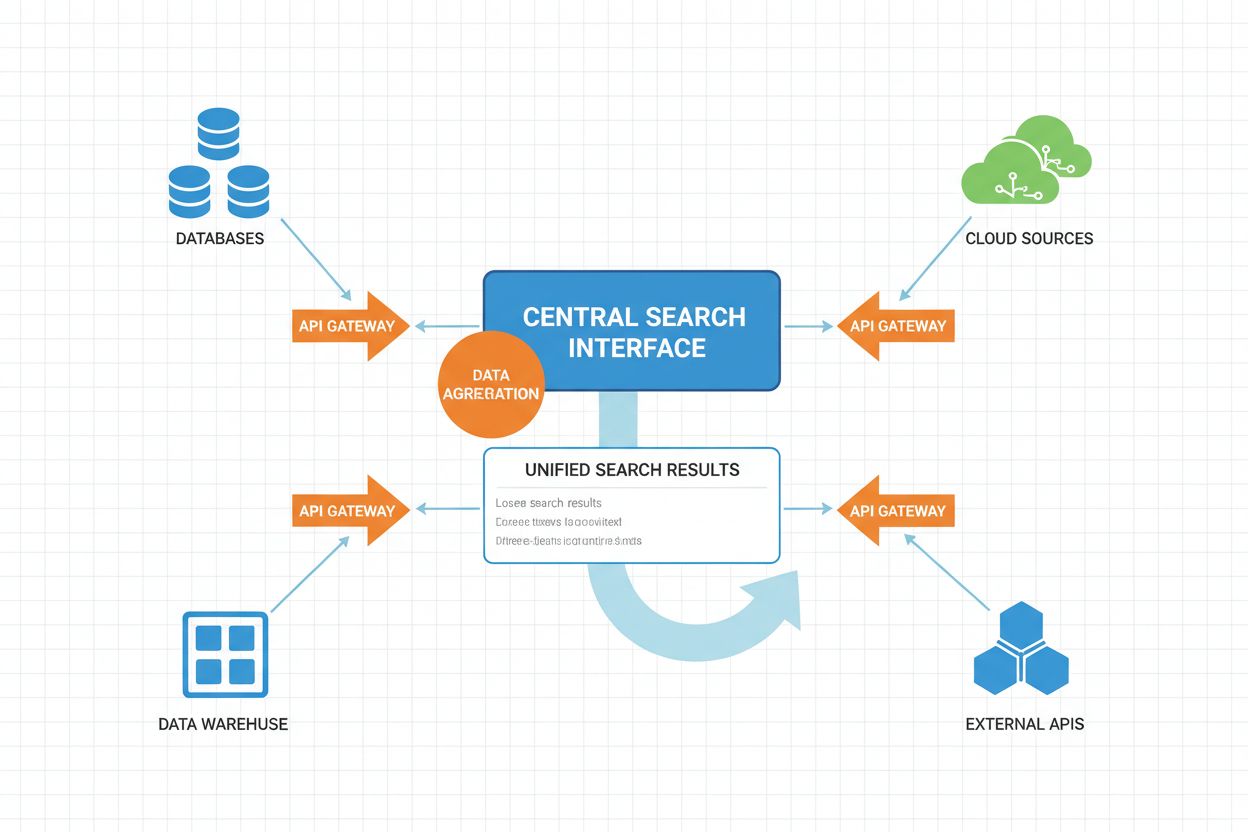
De operationele workflow van federated AI search bestaat uit meerdere gecoördineerde stappen, elk versterkt door kunstmatige intelligentie om prestaties en resultaatkwaliteit te optimaliseren.
| Fase | Proces | AI-component | Output |
|---|---|---|---|
| Queryanalyse | Gebruikersquery wordt geparseerd en geanalyseerd op intentie, entiteiten en context | NLP, Named Entity Recognition, Intentieclassificatie | Gestructureerde queryrepresentatie, geïdentificeerde entiteiten, intentiesignalen |
| Bronselectie | Systeem bepaalt welke databronnen het meest relevant zijn voor de query | Machine Learning Ranking Models, Bronrelevantieclassifiers | Geprioriteerde lijst van doelbronnen, betrouwbaarheidscores |
| Queryvertaling | Query wordt vertaald naar bron-specifieke formaten en querytalen | Schema Mapping, Query Translation Models, Semantische Matching | Bron-specifieke queries (SQL, SPARQL, API-calls, etc.) |
| Gedistrubueerde Uitvoering | Queries worden parallel uitgevoerd over geselecteerde bronnen | Load Balancing, Timeout Management, Parallel Processing | Ruwe resultaten van elke bron, uitvoeringsmetadata |
| Resultaatnormalisatie | Resultaten van verschillende bronnen worden omgezet naar een gemeenschappelijk formaat | Schema Alignment, Data Type Conversion, Format Standardization | Genormaliseerde resultaatset met consistente structuur |
| Semantische Verrijking | Resultaten worden verrijkt met extra context en metadata | Entity Linking, Semantische Tagging, Integratie van kennisgrafen | Verrijkte resultaten met semantische annotaties |
| Rangschikking en Deduplicatie | Resultaten worden gerangschikt op relevantie en dubbele resultaten worden verwijderd | Learning-to-Rank Models, Similariteitsdetectie, Relevantiebeoordeling | Gededupliceerde, gerangschikte resultatenlijst |
| Personalisatie | Resultaten worden aangepast op basis van gebruikersprofiel en voorkeuren | Collaborative Filtering, User Modeling, Context Awareness | Gepersonaliseerde resultaatsvolgorde |
| Presentatie | Resultaten worden geformatteerd voor gebruikerspresentatie | Natural Language Generation, Result Summarization | Resultaatweergave voor de gebruiker |
De workflow draait op parallelle uitvoering als kern, waarbij meerdere bronnen gelijktijdig worden bevraagd in plaats van sequentieel. Deze parallelisatie vermindert de algehele zoekvertraging aanzienlijk ondanks de overhead van coördinatie over meerdere bronnen. Geavanceerde federatieve systemen implementeren adaptieve queryplanning, waarbij het systeem leert van historische zoekpatronen om bronselectie en uitvoeringsstrategieën in de loop der tijd te optimaliseren.
Timeout- en fallbackmechanismen zijn cruciale componenten voor systeembetrouwbaarheid. Wanneer een bron traag reageert of faalt, kan het systeem wachten met adaptieve time-outs of doorgaan met resultaten van beschikbare bronnen, waardoor het systeem gracieus degradeert in volledigheid in plaats van volledig te falen.
Federated AI search-systemen kunnen worden gecategoriseerd op verschillende dimensies:
Op Architectuurmodel:
Op Type Databron:
Op Reikwijdte en Schaal:
Op Intelligentie-niveau:
Data-autonomie en Governance: Organisaties behouden controle over hun data en hoeven gevoelige informatie niet naar gecentraliseerde opslagplaatsen te verplaatsen. Dit waarborgt datagovernance, compliance en beveiliging op bron-niveau.
Schaalbaarheid Zonder Consolidatie: Federatieve systemen schalen door nieuwe bronnen toe te voegen zonder datamigratie of herstructurering van datawarehouses. Hierdoor kunnen organisaties geleidelijk nieuwe databronnen integreren naarmate de bedrijfsbehoeften veranderen.
Real-time Informatietoegang: Door bronnen direct te bevragen, biedt federated search toegang tot actuele informatie zonder de vertraging van batch-gebaseerde datawarehousing. Dit is vooral waardevol voor tijdkritische toepassingen.
Kostenefficiëntie: Elimineert de aanzienlijke infrastructuur- en operationele kosten van centrale datawarehouses. Organisaties vermijden dataduplicatie, dubbele opslag en complexe ETL-processen.
Minder Dataredundantie: Waar datawarehousing data dupliceert over systemen heen, behoudt federated search één enkele bron van waarheid, met minder opslag en betere consistentie.
Flexibiliteit en Aanpasbaarheid: Nieuwe bronnen kunnen worden geïntegreerd zonder bestaande infrastructuur te wijzigen of centrale repositories te herindexeren. Dit maakt snelle aanpassing aan veranderende eisen mogelijk.
Verbeterde Data-kwaliteit: Door autoritatieve bronnen direct te bevragen, vermindert federated search veroudering van data en inconsistenties die ontstaan door periodieke synchronisatie.
Verbeterde Beveiliging: Gevoelige data blijft op de originele locatie, waardoor risico op onbevoegde toegang of lekken wordt verminderd. Toegangscontrole blijft bij de bron in plaats van centraal geregeld.
Ondersteuning van Heterogene Bronnen: Federatieve systemen ondersteunen uiteenlopende technologieën, formaten en protocollen zonder standaardisatie of migratie naar een gemeenschappelijk platform.
Intelligente Resultaatsynthese: AI-gestuurde rangschikking en aggregatie leveren kwalitatief betere resultaten op dan simpele samenvoeging, met oog voor bronbetrouwbaarheid, relevantie en gebruikerscontext.
Moderne federated AI search-systemen bestaan uit diverse onderling verbonden technische componenten die gezamenlijk geïntegreerde zoekfunctionaliteit leveren.
Query Processing Engine: De centrale component die gebruikersqueries ontvangt en de federatieve zoekworkflow orkestreert. Dit omvat queryparsing, semantische analyse en intentieherkenning. Geavanceerde systemen gebruiken transformer-gebaseerde taalmodellen voor complex querybegrip en impliciete gebruikersintentie.
Bronnenregister en Metadatabeheer: Beheert uitgebreide metadata over beschikbare databronnen, zoals schema-informatie, inhoudskenmerken, updatefrequentie, beschikbaarheid en prestatiestatistieken. Dit register maakt intelligente bronselectie en queryoptimalisatie mogelijk. Machine learning-modellen analyseren historische zoekpatronen om bronrelevantie voor nieuwe queries te voorspellen.
Intelligent Source Selection Module: Gebruikt machine learning-classifiers om te bepalen welke bronnen waarschijnlijk relevante informatie voor een query bevatten. Hierbij worden contentdekking, historische succespercentages, bronbeschikbaarheid en verwachte responstijden meegenomen. Geavanceerde systemen gebruiken reinforcement learning om bronselectiestrategieën continu te optimaliseren.
Query Translation and Adaptation Layer: Zet gebruikersqueries om naar bron-specifieke formaten en querytalen. Dit omvat SQL-generatie voor relationele databases, SPARQL voor kennisgrafen, REST API-calls voor webservices en natuurlijke taalqueries voor ongestructureerde systemen. Semantische mapping waarborgt query-intentie over verschillende talen en datamodellen.
Distributed Execution Coordinator: Beheert parallelle query-uitvoering over meerdere bronnen, inclusief timeoutbeheer, load balancing en foutafhandeling. Deze component implementeert adaptieve time-outs die zich aanpassen aan bronrespons en systeembelasting.
Result Normalization Engine: Zet resultaten van verschillende bronnen om naar een gemeenschappelijk formaat voor aggregatie en rangschikking. Dit omvat schema-afstemming, datatypeconversie en standaardisatie. De engine verwerkt ontbrekende velden, conflicterende datatypes en structuurverschillen.
Semantische Verrijkingsmodule: Verrijkt resultaten met extra context en semantische informatie. Dit omvat entity linking naar kennisbanken, semantische tagging op basis van ontologieën en relatie-extractie uit ongestructureerde tekst. Deze verrijkingen verbeteren de rangschikking en begrijpelijkheid.
Learning-to-Rank Model: Een machine learning-model getraind op historische query-resultaatparen om relevantie te voorspellen. Dit model gebruikt honderden features zoals bronbetrouwbaarheid, actualiteit, gebruikersprofiel en semantische overeenkomst tussen query en resultaat. Moderne implementaties gebruiken gradient boosting of neurale netwerken voor rangschikking.
Deduplicatie-engine: Herkent en verwijdert dubbele of bijna-dubbele resultaten uit verschillende bronnen. Dit gebeurt via exact matching, fuzzy string matching en semantische overeenkomst op basis van embeddings.
Personalisatie-engine: Past resultaatsvolgorde aan op basis van gebruikersprofielen, voorkeuren en contextuele informatie. Deze component gebruikt collaborative filtering en content-based aanbevelingen voor hogere relevantie.
Caching en Optimalisatielaag: Implementeert intelligente cachingstrategieën om dubbel zoeken te verminderen. Dit omvat caching van zoekresultaten, bronmetadata en geleerde zoekpatronen.
Monitoring en Analyticsmodule: Volgt systeemprestaties, bronbetrouwbaarheid, zoekpatronen en kwaliteitsstatistieken van resultaten. Deze data wordt gebruikt voor doorlopende optimalisatie.
Zorg en Medisch Onderzoek: Federated search integreert patiëntendossiers over ziekenhuis- en zorgsystemen, onderzoeksdatabanken, klinische trialregisters en medische literatuur. Artsen kunnen uitgebreide patiëntgeschiedenissen bevragen zonder gevoelige data te centraliseren. Onderzoekers krijgen toegang tot verspreide klinische data voor epidemiologische studies, met behoud van AVG- en HIPAA-compliance.
Financiële Diensten: Banken en investeringsmaatschappijen gebruiken federated search om handelsdata, marktinformatie, regelgevende databases en interne transacties gelijktijdig te bevragen. Dit maakt real-time risicoanalyse, compliance-monitoring en marktanalyse mogelijk zonder gevoelige financiële data te centraliseren.
Juridisch en Compliance: Advocatenkantoren en juridische afdelingen zoeken over jurisprudentie, regelgevingsdatabanken, interne documentbeheersystemen en contractdatabases. Federated search maakt volledige juridische research mogelijk, terwijl vertrouwelijkheid en geheimhouding gewaarborgd blijven.
E-commerce en Retail: Online retailers integreren productcatalogi van meerdere magazijnen, leverancierssystemen en marktplaatsen. Federated search zorgt voor eendrachtige productontdekking, terwijl leveranciers hun eigen voorraadsystemen en prijsstrategieën behouden.
Overheid en Publieke Administratie: Overheidsinstanties zoeken over verspreide databases zoals bevolkingsregisters, belastinggegevens, vergunningen en openbare archieven zonder gevoelige burgerinformatie te centraliseren. Dit maakt uitgebreide publieke dienstverlening mogelijk met behoud van privacy.
Productie en Supply Chain: Fabrikanten integreren leveranciersdatabases, voorraadsystemen, productieregistraties en logistieke platforms. Federated search biedt supply chain-inzicht, terwijl partners hun eigen systemen en vertrouwelijke data behouden.
Onderwijs en Onderzoek: Universiteiten zoeken over institutionele repositories, bibliotheeksystemen, onderzoeksdatabanken en open-access publicaties. Federated search maakt volledige academische ontdekking mogelijk met respect voor autonomie en intellectueel eigendom.
Telecom: Telecomproviders zoeken over klantdatabases, netwerkbeheer, facturatiesystemen en dienstencatalogi. Federated search biedt eendrachtige klantenservice, terwijl aparte systemen voor verschillende diensten of regio’s blijven bestaan.
Energie en Nutsbedrijven: Energiebedrijven zoeken over productie-installaties, distributienetwerken, klantdatabases en compliance-systemen. Federated search biedt operationeel inzicht, terwijl regionale operators eigen systemen behouden.
Media en Uitgeverij: Mediaorganisaties zoeken over contentrepositories, archieven, rechtenbeheer en distributieplatforms. Federated search maakt volledige contentontdekking mogelijk, met behoud van eigendom en licentievoorwaarden.
Bronheterogeniteit en Integratiecomplexiteit: Het integreren van diverse databronnen met verschillende schema’s, querytalen en protocollen vereist veel engineering. Schema-mapping en semantische afstemming blijven een uitdaging, vooral bij verschillende representaties van dezelfde concepten.
Querylatentie en Prestaties: Federated search brengt altijd enige vertraging met zich mee door het bevragen van meerdere bronnen. Trage of niet-reagerende bronnen kunnen de algehele prestaties beïnvloeden. Timeoutbeheer vereist een goede balans tussen volledigheid en snelheid.
Bronbetrouwbaarheid en Beschikbaarheid: Federatieve systemen zijn afhankelijk van externe bronnen die beschikbaar en responsief moeten blijven. Netwerkstoringen of bron-uitval hebben direct invloed op de zoekkwaliteit. Gracieuze degradatie is nodig bij bronuitval.
Resultaatkwaliteit en Rangschikkingsnauwkeurigheid: Resultaten combineren van bronnen met verschillende kwaliteitsniveaus, dekking en relevantie is moeilijk. Rangschikkingmodellen moeten bronbetrouwbaarheid wegen en bias voorkomen.
Data-actualiteit en Consistentie: Federatieve systemen vragen actuele brondata op, maar bronnen kunnen verschillende updatefrequenties en consistentiegaranties hebben. Conflicterende informatie vereist geavanceerde resolutiestrategieën.
Schaalbaarheidsbeperkingen: Naarmate het aantal bronnen stijgt, groeit de coördinatieoverhead. Het selecteren van relevante bronnen uit duizenden opties wordt computationeel zwaar. Parallelle uitvoering vraagt om robuuste infrastructuur.
Beveiliging en Toegangscontrole: Federatieve systemen moeten bron-niveau toegangsbeheer afdwingen terwijl ze een eendrachtige zoekinterface bieden. Toegangscontrole over meerdere bronnen in multi-tenant omgevingen is complex.
Privacy en Databescherming: Federated search moet voldoen aan privacywetgeving zoals AVG, CCPA en branchespecifieke regels. Zorgen dat gevoelige data niet lekt via aggregatie of metadata vereist zorgvuldige systeemopzet.
Bronontdekking en -beheer: Het identificeren, catalogiseren en beheren van bronnen en hun metadata vraagt voortdurende operationele inspanning.
Semantische Interoperabiliteit: Echte semantische interoperabiliteit bereiken over bronnen heen met verschillende ontologieën en modellen blijft uitdagend. Automatische schema-mapping en entity-resolutie zijn beperkt.
Coördinatiekosten: Federated search elimineert consolidatiekosten, maar introduceert coördinatieoverhead. Gedistribueerde uitvoering, foutafhandeling en queryoptimalisatie vereisen geavanceerde infrastructuur.
Beperkte Standaardisatie: Gebrek aan universele standaarden voor federatieve zoekprotocollen en interfaces bemoeilijkt integratie en vergroot kans op vendor lock-in.
Federated AI Search vs. Datawarehousing: Datawarehousing consolideert data uit verschillende bronnen in één centrale opslag, wat snelle zoekopdrachten mogelijk maakt maar met aanzienlijke ETL-inspanning en datavertraging. Federated search bevraagt bronnen direct en biedt real-time toegang, maar met hogere querylatentie. Warehousing is geschikt voor historische analyse; federated search blinkt uit in actuele informatieontdekking.
Federated AI Search vs. Datalakes: Datalakes slaan ruwe data uit verschillende bronnen centraal op met minimale transformatie. Ze zijn flexibel maar vragen veel opslag en governance. Federated search vermijdt elke vorm van dataopslag, behoudt bronautonomie, maar vereist geavanceerdere zoekverwerking.
Federated AI Search vs. API’s en Microservices: API’s bieden programmatische toegang tot individuele diensten, maar vragen kennis van de interface. Federated search abstraheert bron-specifieke details, waardoor eendrachtig zoeken mogelijk is. API’s zijn geschikt voor applicatie-integratie; federated search voor informatieontdekking over diensten heen.
Federated AI Search vs. Kennisgrafen: Kennisgrafen representeren informatie als entiteiten en relaties, wat semantische redenatie mogelijk maakt. Federated search kan verspreide kennisgrafen bevragen zonder centrale graphbouw. Kennisgrafen bieden diep semantisch begrip; federated search benadrukt bronautonomie.
Federated AI Search vs. Zoekmachines: Traditionele zoekmachines onderhouden gecentraliseerde indexen van gecrawlde content. Federated search bevraagt bronnen direct zonder pre-indexering. Zoekmachines bieden brede dekking van publieke content; federated search integreert private of specialistische bronnen.
Federated AI Search vs. Master Data Management (MDM): MDM-systemen creëren gezaghebbende masterrecords uit meerdere bronnen. Federated search bevraagt bronnen onafhankelijk en creëert geen masterrecords. MDM is gericht op governance en consistentie; federated search op bronautonomie en real-time toegang.
Federated AI Search vs. Enterprise Search: Enterprise search indexeert interne documenten en databases in een centraal index. Federated search bevraagt bronnen direct zonder centrale indexering. Enterprise search biedt snelle full-text search; federated search ondersteunt verschillende bronsoorten en real-time updates.
Federated AI Search vs. Blockchain en Distributed Ledgers: Blockchain-systemen zorgen voor gedistribueerde consensus en data-integriteit. Federated search coördineert zoekopdrachten over onafhankelijke bronnen zonder consensus. Blockchain is voor vertrouwen en verificatie; federated search voor informatieontdekking.
Uitgebreide Bronbeoordeling: Voer vooraf een grondige beoordeling uit van bronkenmerken zoals datakwaliteit, updatefrequentie, beschikbaarheid, schema-complexiteit en toegangsprotocollen. Dit informeert bronselectie-algoritmen en realistische verwachtingen.
Incrementele Integratie: Start met een klein aantal bekende bronnen en breid geleidelijk uit. Zo bouwt het team expertise op, worden integratieproblemen vroegtijdig gesignaleerd en processen verfijnd voor opschaling.
Robuust Metadatabeheer: Investeer in uitgebreide bronmetadata, zoals schema-informatie, contentdekking, kwaliteits- en prestatiestatistieken. Behoud metadata-actualiteit met monitoring en periodieke validatie.
Intelligente Bronselectie: Implementeer machine learning-gebaseerde bronselectie die leert van zoekresultaten. Houd bij welke bronnen relevant zijn en optimaliseer strategieën continu.
Adaptief Timeoutbeheer: Gebruik adaptieve time-outs die zich aanpassen aan bronrespons en systeembelasting. Vermijd vaste time-outs die ofwel te lang wachten of te snel afbreken.
Resultaatkwaliteitsborging: Stel kwaliteitsstatistieken op zoals relevantie, actualiteit en volledigheid. Implementeer feedbackmechanismen waarmee gebruikers resultaten beoordelen en gebruik deze data bij het trainen van rangschikkingsmodellen.
Uitgebreide Monitoring: Houd bronbeschikbaarheid, responstijden, resultaatkwaliteit en gebruikerssatisfactie bij. Gebruik deze inzichten om bronnen te optimaliseren en zoekprestaties te verbeteren.
Beveiliging en Toegangscontrole: Implementeer bron-niveau toegangsbeheer, zodat autorisatie over het hele federatieve systeem wordt afgedwongen. Zorg dat gebruikers alleen toegang hebben tot informatie waarvoor ze gemachtigd zijn.
Cachingstrategieën: Implementeer intelligente caching op meerdere niveaus, zoals zoekresultaten, bronmetadata en geleerde querypatronen. Balanceer cache-actualiteit en prestaties.
Gebruikerservaring Optimaliseren: Ontwerp interfaces die duidelijk communiceren uit welke bronnen resultaten komen, met betrouwbaarheids- en actualiteitsindicatoren. Geef transparantie over geraadpleegde bronnen en rangschikkingsredenen.
Prestatieoptimalisatie: Profiel zoekuitvoering om knelpunten te vinden. Optimaliseer bronselectie, queryvertaling en resultaataggregatie. Overweeg het pre-computeren van veelvoorkomende zoekpatronen.
Continu Leren: Implementeer feedbackloops die gebruikersinteracties vastleggen. Gebruik deze data om bronselectie, rangschikking en presentatie continu te verbeteren.
Documentatie en Governance: Houd volledige documentatie bij van bronkenmerken, integratieaanpak en systeemarchitectuur. Stel governancebeleid op voor bronbeheer.
Testen en Validatie: Implementeer uitgebreide tests: unit-tests voor componenten, integratietests voor broninteracties en end-to-end-tests voor complete workflows. Valideer resultaten tegen bekende waarheid.
Geavanceerd Natuurlijke Taalbegrip: Toekomstige federatieve systemen gebruiken grote taalmodellen en geavanceerde NLP-technieken om complexe queries met impliciete context en genuanceerde intentie te begrijpen. Dit verbetert bronselectie en interpretatie.
Autonome Bronontdekking: Machine learning-systemen ontdekken en catalogiseren automatisch databronnen, beoordelen relevantie en kwaliteit, en integreren ze met minimale menselijke tussenkomst.
Integratie van het Semantisch Web: Met de volwassenwording van semantische webtechnologieën gebruiken federatieve systemen ontologieën en linked data-standaarden voor diepere interoperabiliteit en betere omgang met heterogene datamodellen.
Explainable AI en Transparantie: Toekomstige systemen bieden gedetailleerde uitleg over rangschikkingsbeslissingen, bronselectie en resultaataggregatie. Deze transparantie versterkt vertrouwen en begrip van het systeem.
Federated Learning-integratie: Federated learning stelt systemen in staat om machine learning-modellen te trainen over verspreide bronnen zonder data te centraliseren. Zo wordt data-autonomie gecombineerd met voorspellende kracht.
Real-time Streaming-integratie: Federatieve systemen integreren steeds vaker real-time datastromen naast traditionele databases, waardoor zoeken in continu veranderende informatie mogelijk wordt.
Multimodale Search: Toekomstige federatieve systemen zoeken over tekst, beelden, video en audio. Multimodale AI-modellen maken crossmodaal zoeken en resultaatsynthese mogelijk.
Personalisatie en Contextbewustzijn: Geavanceerde gebruikersmodellering en contextbegrip zorgen voor sterke personalisatie. Systemen begrijpen gebruikersniveau, informatiewensen en voorkeuren voor aangepaste presentatie.
Quantum Computing-toepassingen: Quantum computing kan in de toekomst worden ingezet voor optimalisatieproblemen als bronselectie en resultaatsrangschikking, wat mogelijk snellere zoekopdrachten oplevert.
Blockchain-integratie: Federatieve systemen kunnen blockchain gebruiken voor bronverificatie, herkomsttracking van resultaten en decentrale coördinatie, vooral in toepassingen waar vertrouwen cruciaal is.
Edge Computing en Gedistribueerde Verwerking: Federated search gaat meer gebruikmaken van edge computing om zoekopdrachten dichter bij databronnen te verwerken, met lagere latentie en meer privacy.
Autonome Optimalisatie: Zelfoptimaliserende federatieve systemen leren continu van zoekpatronen, bronkenmerken en gebruikersfeedback om volledig autonoom te verbeteren.
Cross-domein Kennisintegratie: Toekomstige systemen integreren kennis over traditionele domeingrenzen heen, waardoor onverwachte inzichten en verbanden mogelijk worden tussen uiteenlopende databronnen.
Traditionele gecentraliseerde zoekopdrachten consolideren alle data in één enkele geïndexeerde opslagplaats, waarbij datamigratie nodig is en vertraging optreedt. Federated AI search bevraagt verschillende onafhankelijke bronnen direct in real-time, zonder data te verplaatsen of te dupliceren, waardoor de autonomie van de bron behouden blijft en toch een eendrachtige toegang wordt geboden. Dit maakt federated search ideaal voor organisaties met verspreide databronnen en strikte datagovernance-eisen.
Federated AI search laat data op de oorspronkelijke locatie en respecteert de toegangscontroles en beveiligingsbeleid van elke bron. Gebruikers krijgen alleen toegang tot informatie waarvoor ze bevoegd zijn en gevoelige data verlaat nooit het bronsysteem. Deze aanpak vereenvoudigt compliance met regelgeving zoals de AVG en HIPAA door de risico's van centralisatie van gevoelige informatie te elimineren.
Belangrijke uitdagingen zijn het beheren van heterogene databronnen met verschillende schema's en formaten, omgaan met vertragingen in zoekopdrachten van meerdere bronnen, zorgen voor consistente resultaatsrangschikking over de bronnen heen en het handhaven van systeembetrouwbaarheid als bronnen niet beschikbaar zijn. Organisaties moeten ook investeren in robuust metadatabeheer en intelligente algoritmen voor bronselectie om de prestaties te optimaliseren.
Ja, federated AI search schaalt door nieuwe bronnen toe te voegen zonder datamigratie of herstructurering van datawarehouses. Naarmate het aantal bronnen toeneemt, groeit echter ook de coördinatieoverhead van zoekopdrachten. Moderne systemen gebruiken machine learning voor intelligente bronselectie en implementeren cachingstrategieën om prestaties op schaal te behouden.
Datawarehousing consolideert data in een gecentraliseerde opslagplaats, waardoor snelle zoekopdrachten mogelijk zijn maar met aanzienlijke ETL-inspanning en data-latentie. Federated search bevraagt bronnen direct, biedt real-time toegang maar met hogere zoekopdrachtlatentie. Warehousing is geschikt voor historische analyses en rapportages, terwijl federated search uitblinkt in actuele informatieontdekking over verspreide bronnen.
Zorg, financiën, e-commerce, overheid en onderzoeksorganisaties profiteren aanzienlijk van federated search. In de zorg wordt het gebruikt om patiëntendossiers over aanbieders heen te integreren, in de financiën voor compliance en risicobeoordeling, in e-commerce voor eendrachtige productontdekking en in onderzoek om verspreide academische databases te doorzoeken.
AI versterkt federated search door natuurlijke taalverwerking voor querybegrip, machine learning voor intelligente bronselectie, semantische analyse voor betere rangschikking van resultaten en automatische deduplicatie. AI-modellen leren van zoekpatronen om bronselectie en resultaataggregatie continu te optimaliseren, waardoor de systeemprestaties in de loop van de tijd verbeteren.
Semantisch begrip stelt federatieve systemen in staat om de intentie van zoekopdrachten te begrijpen buiten alleen het matchen van trefwoorden, relevantere bronnen te identificeren en resultaten te rangschikken op basis van betekenis in plaats van alleen keyword-overlap. Dit omvat entiteitsherkenning, relatie-extractie en integratie van kennisgrafen, wat resulteert in relevantere en contextueel passende zoekresultaten.
AmICited volgt hoe AI-systemen zoals ChatGPT, Perplexity en Google AI Overviews jouw merk noemen en refereren. Begrijp je AI-zichtbaarheid en optimaliseer je aanwezigheid in AI-gegenereerde antwoorden.
Ontdek wat SearchGPT is, hoe het werkt en de impact op zoeken, SEO en digitale marketing. Bekijk functies, beperkingen en de toekomst van door AI aangedreven zo...

Ontdek hoe AI-zoekindexering data omzet in doorzoekbare vectoren, waardoor AI-systemen zoals ChatGPT en Perplexity relevante informatie uit jouw content kunnen ...
Begrijp hoe AI-zoekfunnels anders werken dan traditionele marketingfunnels. Leer hoe AI-systemen zoals ChatGPT en Google AI het aankooptraject van de koper same...