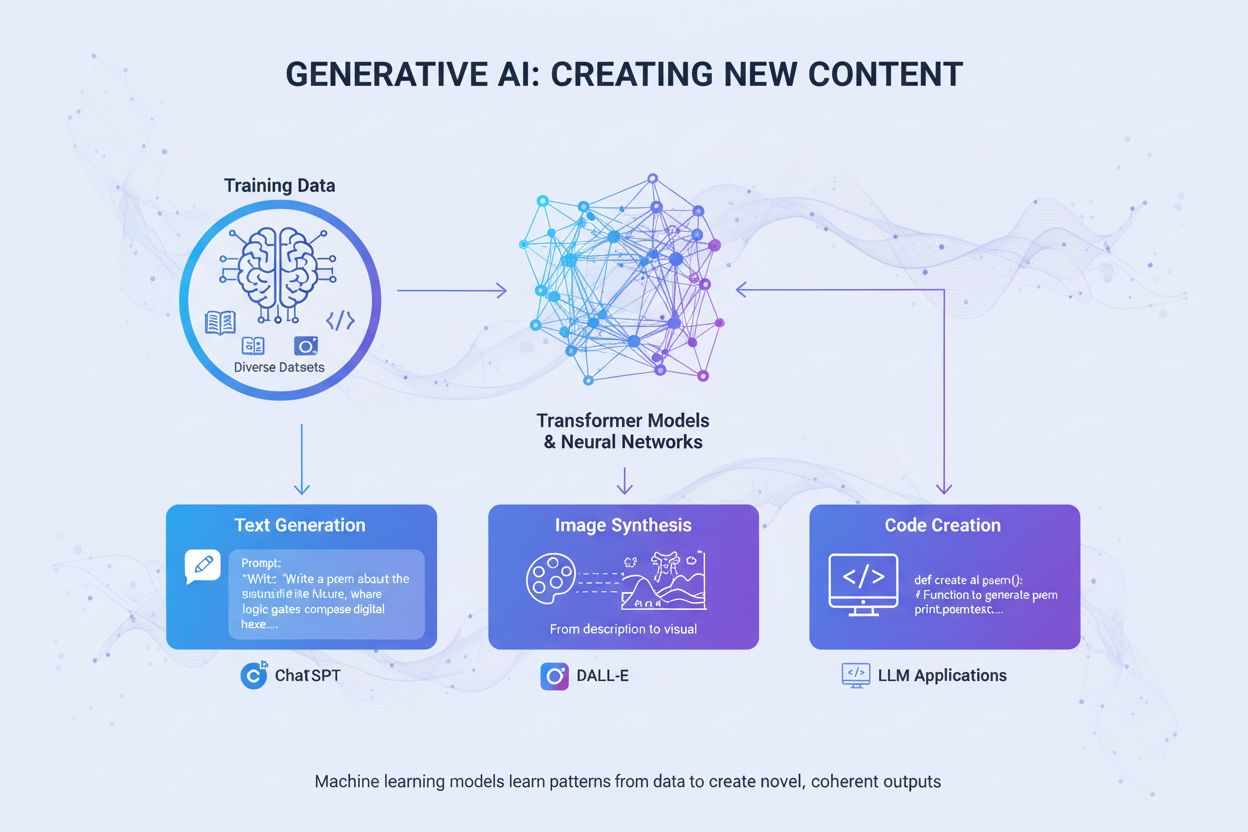
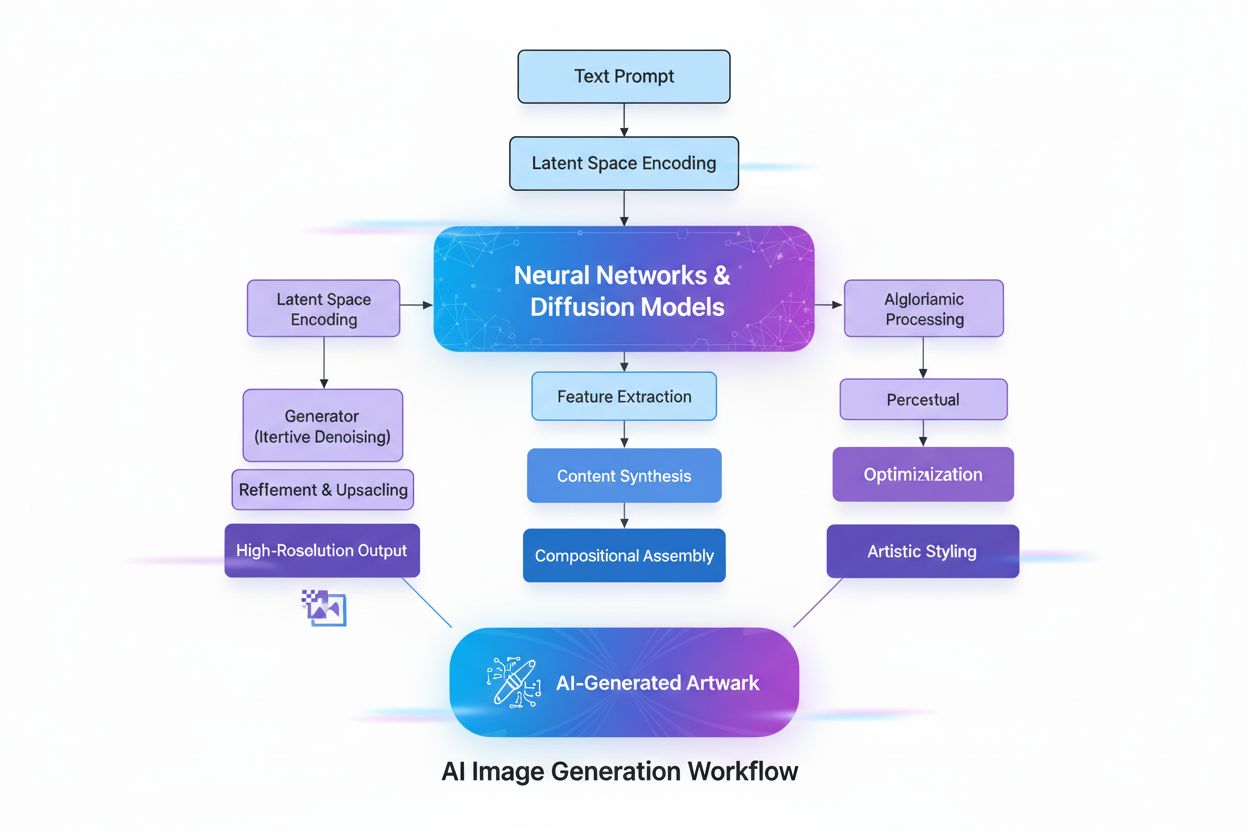
Definitie van Generatieve AI
Generatieve AI is een categorie van kunstmatige intelligentie die nieuwe, originele content creëert op basis van patronen geleerd uit trainingsdata. In tegenstelling tot traditionele AI-systemen die informatie classificeren of voorspellen, produceren generatieve AI-modellen autonoom nieuwe uitkomsten zoals tekst, afbeeldingen, video’s, audio, code en andere datatypes als reactie op gebruikersprompts of -verzoeken. Deze systemen maken gebruik van geavanceerde deep learning-modellen en neurale netwerken om complexe patronen en relaties binnen enorme datasets te identificeren, en gebruiken die kennis vervolgens om content te genereren die lijkt op, maar verschilt van de trainingsdata. De term “generatief” benadrukt het vermogen van het model om te genereren—om iets nieuws te creëren in plaats van alleen bestaande informatie te analyseren of te categoriseren. Sinds de publieke lancering van ChatGPT in november 2022 is generatieve AI uitgegroeid tot een van de meest transformerende technologieën in de informatica, wat fundamenteel verandert hoe organisaties contentcreatie, probleemoplossing en besluitvorming benaderen in vrijwel elke sector.
Historische Context en Evolutie van Generatieve AI
De fundamenten van generatieve AI gaan decennia terug, al heeft de technologie zich de laatste jaren dramatisch ontwikkeld. Vroege statistische modellen in de twintigste eeuw legden de basis voor het begrijpen van dataverdelingen, maar echte generatieve AI ontstond met vooruitgang in deep learning en neurale netwerken in de jaren 2010. De introductie van Variational Autoencoders (VAEs) in 2013 betekende een belangrijke doorbraak, waardoor modellen realistische variaties van data zoals afbeeldingen en spraak konden genereren. In 2014 kwamen Generative Adversarial Networks (GANs) en diffusiemodellen op, die de kwaliteit en realiteit van gegenereerde content verder verbeterden. Het keerpunt kwam in 2017 toen onderzoekers “Attention is All You Need” publiceerden, waarmee de transformer-architectuur werd geïntroduceerd—een doorbraak die fundamenteel veranderde hoe generatieve AI-modellen sequentiële data verwerken en genereren. Deze innovatie maakte de ontwikkeling van Large Language Models (LLMs) zoals de GPT-serie van OpenAI mogelijk, die ongekende capaciteiten toonden in het begrijpen en genereren van menselijke taal. Volgens onderzoek van McKinsey gebruikte in 2023 al een derde van de organisaties generatieve AI regelmatig in minstens één bedrijfsfunctie, en Gartner voorspelt dat tegen 2026 meer dan 80% van de ondernemingen generatieve AI-toepassingen of API’s zal hebben geïmplementeerd. De snelle overgang van onderzoekscuriositeit naar zakelijke noodzaak is een van de snelste technologie-adoptiecycli in de geschiedenis.
Ready to Monitor Your AI Visibility?
Track how AI chatbots mention your brand across ChatGPT, Perplexity, and other platforms.
Hoe Generatieve AI Werkt: Technische Architectuur
Generatieve AI werkt via een meerfasig proces dat begint met training op enorme datasets, gevolgd door tuning voor specifieke toepassingen, en continue cycli van genereren, evalueren en bijstellen. Tijdens de trainingsfase voeren experts deep learning-algoritmen terabytes aan rauwe, ongestructureerde data—zoals internetteksten, afbeeldingen of coderepositories—en het algoritme voert miljoenen “invuloefeningen” uit, waarbij het het volgende element in een reeks voorspelt en zichzelf bijstelt om de voorspellingsfout te minimaliseren. Dit proces creëert een neuraal netwerk van parameters waarin de patronen, entiteiten en relaties uit de trainingsdata zijn gecodeerd. Het resultaat is een foundation model—een groot, voorgetraind model dat meerdere taken in verschillende domeinen kan uitvoeren. Foundation-modellen zoals GPT-3, GPT-4 en Stable Diffusion vormen de basis voor talloze gespecialiseerde toepassingen. De tuningfase omvat fine-tuning van het foundation model met gelabelde data voor een specifieke taak, of het gebruik van Reinforcement Learning with Human Feedback (RLHF), waarbij menselijke beoordelaars verschillende uitkomsten scoren om het model te sturen richting grotere nauwkeurigheid en relevantie. Ontwikkelaars en gebruikers beoordelen voortdurend de uitkomsten en stellen modellen verder bij—soms wekelijks—om de prestaties te verbeteren. Een andere optimalisatietechniek is Retrieval Augmented Generation (RAG), waarbij het foundation model toegang krijgt tot relevante externe bronnen, zodat het model altijd over actuele informatie beschikt en transparant is over zijn bronnen.
Vergelijking van Architecturen van Generatieve AI-Modellen
| Modeltype | Trainingsmethode | Generatiesnelheid | Uitkomstkwaliteit | Diversiteit | Beste Toepassingen |
|---|
| Diffusiemodellen | Iteratief verwijderen van ruis uit willekeurige data | Traag (meerdere iteraties) | Zeer hoog (fotorealistisch) | Hoog | Beeldgeneratie, hoogwaardige synthese |
| Generative Adversarial Networks (GANs) | Generator vs. Discriminator competitie | Snel | Hoog | Lager | Domeinspecifieke generatie, stijltransfer |
| Variational Autoencoders (VAEs) | Encoder-decoder met latente ruimte | Gemiddeld | Gemiddeld | Gemiddeld | Datacompressie, anomaliedetectie |
| Transformer-modellen | Self-attention op sequentiële data | Gemiddeld tot snel | Zeer hoog (tekst/code) | Zeer hoog | Taalgeneratie, code-synthese, LLMs |
| Hybride benaderingen | Combinatie van meerdere architecturen | Variabel | Zeer hoog | Zeer hoog | Multimodale generatie, complexe taken |
Stay Updated on AI Visibility Trends
Get the latest insights on AI mentions, brand monitoring, and optimization strategies.
Kerntechnologieën Achter Generatieve AI
De transformer-architectuur is de meest invloedrijke technologie achter moderne generatieve AI. Transformers gebruiken self-attention-mechanismen om te bepalen welke delen van de input het belangrijkst zijn bij de verwerking, waardoor het model langeafstandsafhankelijkheden en context kan vastleggen. Positionele codering geeft de volgorde van inputelementen weer, zodat transformers de sequentiestructuur begrijpen zonder sequentiële verwerking. Deze parallelle verwerkingscapaciteit versnelt de training sterk ten opzichte van eerdere recurrente neurale netwerken (RNNs). De encoder-decoder-structuur van de transformer, gecombineerd met meerdere lagen attention-heads, stelt het model in staat om gelijktijdig verschillende aspecten van data te overwegen en contextuele embeddings te verfijnen in elke laag. Deze embeddings bevatten alles van grammatica en syntaxis tot complexe semantische betekenissen. Large Language Models (LLMs) zoals ChatGPT, Claude en Gemini zijn gebouwd op transformer-architecturen en bevatten miljarden parameters—gecodeerde representaties van geleerde patronen. De schaal van deze modellen, gecombineerd met training op internet-schaal data, stelt ze in staat om uiteenlopende taken uit te voeren van vertalen en samenvatten tot creatief schrijven en codegeneratie. Diffusiemodellen, een andere belangrijke architectuur, werken door eerst ruis toe te voegen aan trainingsdata tot deze willekeurig is, waarna het algoritme wordt getraind om die ruis iteratief te verwijderen om gewenste uitkomsten te onthullen. Hoewel diffusiemodellen meer trainingstijd vergen dan VAEs of GANs, bieden ze superieure controle over de uitkomstkwaliteit, vooral voor hoogwaardige beeldgeneratietools zoals DALL-E en Stable Diffusion.
Zakelijke Impact en Adoptie van Generatieve AI
De businesscase voor generatieve AI is overtuigend gebleken, met meetbare productiviteitswinst en kostenbesparingen voor bedrijven. Volgens het enterprise AI-rapport van OpenAI uit 2025 besparen gebruikers 40–60 minuten per dag dankzij generatieve AI-toepassingen, wat leidt tot aanzienlijke productiviteitsverbeteringen in organisaties. De markt voor generatieve AI werd in 2024 gewaardeerd op 16,87 miljard USD en zal naar verwachting 109,37 miljard USD bereiken in 2030, met een CAGR van 37,6%—een van de snelste groeipercentages in de geschiedenis van enterprise software. De uitgaven van ondernemingen aan generatieve AI stegen naar $37 miljard in 2025, tegenover $11,5 miljard in 2024, wat een 3,2-voudige jaarlijkse stijging betekent. Deze versnelling weerspiegelt groeiend vertrouwen in rendement op investering, waarbij AI-kopers converteren op 47% vergeleken met 25% bij traditionele SaaS, wat aangeeft dat generatieve AI voldoende directe waarde biedt voor snelle adoptie. Organisaties implementeren generatieve AI in diverse functies: klantenserviceteams gebruiken AI-chatbots voor gepersonaliseerde antwoorden en first-contact-oplossing; marketingafdelingen zetten contentgeneratie in voor blogs, e-mails en sociale media; softwareontwikkelingsteams gebruiken codegeneratie-tools om ontwikkelcycli te versnellen; en onderzoeksteams gebruiken generatieve modellen voor het analyseren van complexe datasets en het voorstellen van nieuwe oplossingen. Financiële dienstverleners gebruiken generatieve AI voor fraudedetectie en gepersonaliseerd financieel advies, terwijl zorginstellingen het toepassen op medicijnontwikkeling en medische beeldanalyse. De veelzijdigheid van de technologie in sectoren toont het transformerende potentieel voor bedrijfsvoering aan.
Toepassingen van Generatieve AI in Sectoren en Domeinen
De toepassingen van generatieve AI beslaan vrijwel elke sector en functie. Bij tekstgeneratie produceren modellen samenhangende, contextueel relevante content zoals documentatie, marketingteksten, blogartikelen, onderzoeksrapporten en creatieve teksten. Ze blinken uit in het automatiseren van saaie schrijftaken zoals samenvattingen en metadata-generatie, waardoor menselijke schrijvers zich kunnen richten op creatiever werk. Beeldgeneratie-tools zoals DALL-E, Midjourney en Stable Diffusion creëren fotorealistische afbeeldingen, originele kunstwerken, en voeren stijltransfer en beeldbewerking uit. Videogeneratie stelt gebruikers in staat animaties te maken vanuit tekstprompts en special effects toe te passen sneller dan traditionele methoden. Audio- en muziekgeneratie synthetiseert natuurlijk klinkende spraak voor chatbots en digitale assistenten, maakt audioboek-narratie en genereert originele muziek in professionele stijl. Codegeneratie stelt ontwikkelaars in staat originele code te schrijven, snippets aan te vullen, te vertalen tussen programmeertalen en applicaties te debuggen. In de zorg versnelt generatieve AI medicijnontwikkeling door nieuwe eiwitsequenties en moleculaire structuren met gewenste eigenschappen te genereren. Synthetische datageneratie levert gelabelde trainingsdata voor machine learning-modellen, vooral waardevol wanneer echte data beperkt, onbeschikbaar of onvoldoende is voor randgevallen. In de automotive creëert generatieve AI 3D-simulaties voor voertuigontwikkeling en synthetische data voor training van autonome voertuigen. Media- en entertainmentbedrijven zetten generatieve AI in voor het maken van animaties, scripts, game-omgevingen en gepersonaliseerde contentaanbevelingen. Energiebedrijven passen generatieve modellen toe voor gridmanagement, optimalisatie van operationele veiligheid en energieproductieprognoses. De breedte van toepassingen toont de rol van generatieve AI als fundamentele technologie die bepaalt hoe organisaties creëren, analyseren en innoveren.
Belangrijkste Mogelijkheden en Voordelen van Generatieve AI
- Contentcreatie op Schaal: Genereer diverse, hoogwaardige content in tekst, beeld, video en audio, wat productietijd en kosten verlaagt en personalisatie mogelijk maakt
- Versneld Onderzoek en Innovatie: Analyseer complexe datasets, ontdek verborgen patronen en stel nieuwe oplossingen voor, wat ontdekking versnelt in onder meer farmacie en materiaalkunde
- Verbeterde Productiviteit: Automatiseer repetitieve taken, genereer codevoorstellen, maak documentatie en ondersteun workflows, zodat teams zich op strategisch werk kunnen richten
- Verbeterde Besluitvorming: Haal betekenisvolle inzichten uit grote datasets, genereer hypotheses en aanbevelingen, en ondersteun datagedreven besluitvorming op directie- en analyse-niveau
- Dynamische Personalisatie: Analyseer gebruikersvoorkeuren en -geschiedenis om gepersonaliseerde content, aanbevelingen en ervaringen in realtime te genereren, wat betrokkenheid en klanttevredenheid verhoogt
- 24/7 Beschikbaarheid: Blijf continu operationeel zonder vermoeidheid, met permanente beschikbaarheid voor klantenservice, chatbots en geautomatiseerde antwoorden
- Kostenreductie: Verminder arbeidskosten voor contentcreatie, klantenservice en routineprocessen, terwijl efficiëntie en kwaliteit verbeteren
- Concurrentievoordeel: Stel organisaties in staat sneller te innoveren, producten sneller op de markt te brengen en unieke klantervaringen te creëren die concurrenten moeilijk kunnen repliceren
Uitdagingen, Beperkingen en Risicobeheersing bij Generatieve AI
Ondanks de indrukwekkende mogelijkheden brengt generatieve AI aanzienlijke uitdagingen met zich mee die organisaties moeten aanpakken. AI-hallucinaties—plausibel klinkende maar feitelijk onjuiste uitkomsten—ontstaan omdat generatieve modellen het volgende element voorspellen op basis van patronen in plaats van feitelijke controle. Een advocaat gebruikte bijvoorbeeld ChatGPT voor juridisch onderzoek en kreeg volledig fictieve jurisprudentie, compleet met citaten en toeschrijvingen. Bias- en eerlijkheidskwesties ontstaan wanneer trainingsdata maatschappelijke vooroordelen bevat, waardoor modellen bevooroordeelde, oneerlijke of aanstootgevende content genereren. Inconsistente uitkomsten zijn het gevolg van de probabilistische aard van generatieve modellen, waardoor identieke input verschillende uitkomsten kan opleveren—problematisch voor toepassingen die consistentie vereisen zoals klantenservice-chatbots. Gebrek aan uitlegbaarheid maakt het moeilijk te begrijpen hoe modellen tot bepaalde uitkomsten komen; zelfs ingenieurs kunnen het besluitvormingsproces van deze “black box”-modellen nauwelijks verklaren. Beveiligings- en privacydreigingen ontstaan wanneer propriëtaire data wordt gebruikt voor modeltraining of wanneer modellen content genereren die intellectueel eigendom blootlegt of schendt. Deepfakes—AI-gegenereerde of gemanipuleerde afbeeldingen, video’s of audio bedoeld om te misleiden—zijn een van de meest zorgwekkende toepassingen, waarbij cybercriminelen deepfakes inzetten voor voice phishing en financiële fraude. Rekenkosten blijven aanzienlijk, met het trainen van grote foundation-modellen dat duizenden GPU’s en weken aan verwerking vereist, wat miljoenen dollars kost. Organisaties beperken deze risico’s via waarborgen die modellen beperken tot betrouwbare bronnen, continue evaluatie en tuning om hallucinaties te verminderen, diverse trainingsdata om bias te minimaliseren, prompt engineering voor consistente uitkomsten en beveiligingsprotocollen ter bescherming van propriëtaire informatie. Transparantie over AI-gebruik en menselijk toezicht op kritische beslissingen blijven essentiële best practices.
Monitoring van Generatieve AI-Zichtbaarheid en Merkaanwezigheid
Nu generatieve AI-systemen primaire informatiebronnen worden voor miljoenen gebruikers, moeten organisaties inzicht krijgen in hoe hun merken, producten en content verschijnen in AI-gegenereerde antwoorden. AI-zichtbaarheid monitoring houdt in dat systematisch wordt bijgehouden hoe grote generatieve AI-platforms—waaronder ChatGPT, Perplexity, Google AI Overviews en Claude—merken, producten en concurrenten beschrijven. Deze monitoring is belangrijk omdat AI-systemen vaak bronnen citeren en informatie aanhalen zonder traditionele zoekmachine-zichtbaarheidsstatistieken. Merken die niet voorkomen in AI-antwoorden missen kansen op zichtbaarheid en invloed in het AI-gedreven zoeklandschap. Tools zoals AmICited stellen organisaties in staat om merkvermeldingen te volgen, de nauwkeurigheid van citaties te monitoren, te identificeren welke domeinen en URL’s worden aangehaald in AI-antwoorden en te begrijpen hoe AI-systemen hun concurrentiepositie representeren. Deze data helpt organisaties hun content te optimaliseren voor AI-citatie, desinformatie of onjuiste representaties te signaleren en concurrentie-zichtbaarheid te behouden nu AI het primaire interface wordt tussen gebruikers en informatie. De praktijk van GEO (Generative Engine Optimization) richt zich op het optimaliseren van content specifiek voor AI-citatie en zichtbaarheid, als aanvulling op traditionele SEO-strategieën. Organisaties die proactief hun AI-zichtbaarheid monitoren en optimaliseren, behalen concurrentievoordelen in het opkomende AI-gedreven informatielandschap.
Toekomsttrends en Strategische Vooruitzichten voor Generatieve AI
Het generatieve AI-landschap evolueert snel, met verschillende trends die de toekomst bepalen. Multimodale AI-systemen die tekst, afbeeldingen, video en audio naadloos integreren worden steeds geavanceerder, waardoor complexere en genuanceerdere contentgeneratie mogelijk wordt. Agentic AI—autonome AI-systemen die taken uitvoeren en doelen bereiken zonder menselijke tussenkomst—vormen de volgende stap na generatieve AI, waarbij AI-agenten gegenereerde content gebruiken om met tools te interageren en beslissingen te nemen. Kleinere, efficiëntere modellen verschijnen als alternatieven voor massieve foundation-modellen, waardoor organisaties generatieve AI kunnen inzetten met lagere rekenkosten en snellere reacties. Retrieval Augmented Generation (RAG) blijft zich ontwikkelen, zodat modellen toegang krijgen tot actuele informatie en externe kennisbronnen, waarmee hallucinatie- en nauwkeurigheidsproblemen worden aangepakt. Regelgevingskaders ontwikkelen zich wereldwijd, met overheden die richtlijnen opstellen voor verantwoorde AI-ontwikkeling en -implementatie. Enterprise maatwerk via fine-tuning en domeinspecifieke modellen versnelt, omdat organisaties generatieve AI willen aanpassen aan hun unieke bedrijfscontext. Ethische AI-praktijken worden een concurrentievoordeel, met organisaties die prioriteit geven aan transparantie, eerlijkheid en verantwoorde inzet. De convergentie van deze trends suggereert dat generatieve AI steeds meer zal worden geïntegreerd in bedrijfsvoering, efficiënter en toegankelijker wordt voor organisaties van elke omvang, en onderworpen zal zijn aan sterkere governance en ethische standaarden. Organisaties die investeren in het begrijpen van generatieve AI, hun AI-zichtbaarheid monitoren en verantwoord implementeren, zijn het best gepositioneerd om waarde te halen uit deze transformerende technologie en de bijbehorende risico’s te beheersen.