
JSON-LD: Complete gids voor implementatie en SEO-voordelen
Leer wat JSON-LD is en hoe je het implementeert voor SEO. Ontdek de voordelen van gestructureerde data markup voor Google, ChatGPT, Perplexity en zichtbaarheid ...
14 min lezen
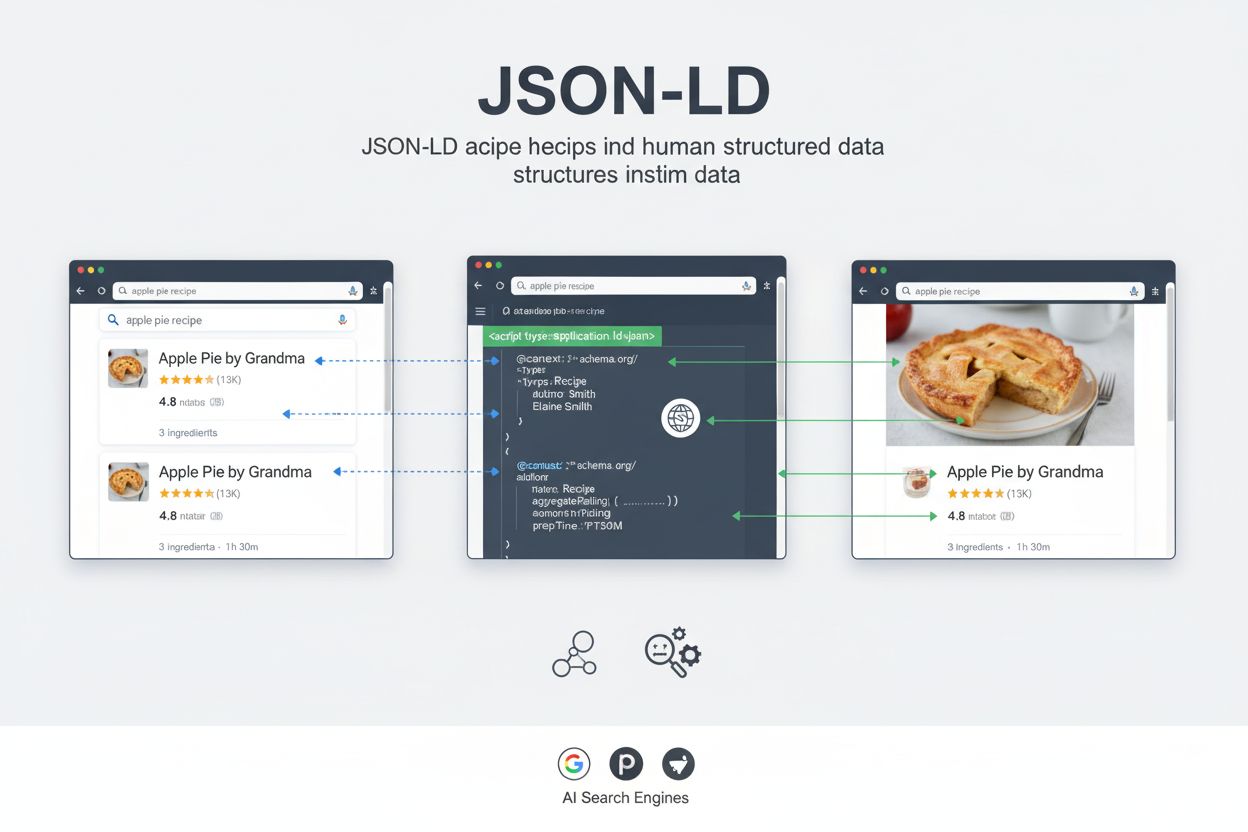
JSON-LD (JavaScript Object Notation for Linked Data) is een lichtgewicht, door W3C gestandaardiseerd formaat voor het uitdrukken van gestructureerde gegevens met behulp van JSON-syntaxis. Hiermee kunnen zoekmachines en AI-systemen webinhoud begrijpen via de schema.org-vocabulaire. Het wordt in webpagina’s geïntegreerd als machineleesbare markup die zoekmachines helpt rijke resultaten weer te geven en de vindbaarheid van inhoud op AI-platforms verbetert.
JSON-LD (JavaScript Object Notation for Linked Data) is een lichtgewicht, door W3C gestandaardiseerd formaat voor het uitdrukken van gestructureerde gegevens met behulp van JSON-syntaxis. Hiermee kunnen zoekmachines en AI-systemen webinhoud begrijpen via de schema.org-vocabulaire. Het wordt in webpagina's geïntegreerd als machineleesbare markup die zoekmachines helpt rijke resultaten weer te geven en de vindbaarheid van inhoud op AI-platforms verbetert.
JSON-LD staat voor JavaScript Object Notation for Linked Data en is een lichtgewicht, gestandaardiseerd formaat voor het uitdrukken van gestructureerde gegevens op webpagina’s. Sinds januari 2014 is JSON-LD een W3C Recommendation en combineert het de eenvoud van JSON-syntaxis met de semantische kracht van linked data-vocabularia, in het bijzonder schema.org. In tegenstelling tot andere formaten voor gestructureerde gegevens, die markup vermengen met HTML-inhoud, wordt JSON-LD als een apart <script>-element in de paginakop of -body geplaatst, waardoor gegevens gescheiden blijven van de presentatielaag. Deze scheiding maakt JSON-LD buitengewoon eenvoudig te implementeren, onderhouden en op te schalen op grote websites en contentmanagementsystemen.
Het primaire doel van JSON-LD is om machineleesbare context te bieden waarmee zoekmachines, AI-systemen en andere webapplicaties de betekenis en relaties binnen webpagina-inhoud kunnen begrijpen. Bij correcte implementatie stelt JSON-LD zoekmachines in staat om rijke resultaten weer te geven—uitgebreide zoekfragmenten met onder meer beoordelingen, prijzen, afbeeldingen, evenementdetails en andere gestructureerde informatie. Voor AI-gedreven zoekplatforms zoals ChatGPT, Perplexity, Google AI Overviews en Claude fungeert JSON-LD als een essentiële brug tussen menselijk leesbare inhoud en machine-interpreteerbare gegevens, waardoor de nauwkeurigheid en relevantie van AI-gegenereerde antwoorden en citaties verbeteren.
JSON-LD is het aanbevolen formaat voor gestructureerde gegevens door Google en andere grote zoekmachines, omdat het implementatiefouten minimaliseert en naadloos werkt met moderne webtechnieken, waaronder JavaScript-frameworks en dynamische contentgeneratie. De flexibiliteit van het formaat maakt het mogelijk om complexe, geneste datastructuren uit te drukken, waardoor het geschikt is voor uiteenlopende inhoudstypen, van eenvoudige productinformatie tot complexe organisatiehiërarchieën en evenementdetails.
JSON-LD is ontstaan uit de behoefte om traditionele JSON-dataformaten te verbinden met semantische webstandaarden. Voorafgaand aan JSON-LD gebruikten ontwikkelaars die met linked data werkten doorgaans RDF/XML of Turtle-formaten, die krachtig maar complex waren en niet aansloten bij webontwikkelpraktijken. De ontwikkeling van JSON-LD begon begin jaren 2010 als onderdeel van de W3C JSON-LD Community Group, omdat JSON inmiddels de standaard was voor web-API’s en gegevensuitwisseling. Het formaat werd officieel gestandaardiseerd door de W3C in 2014 en verdere verfijningen leidden tot JSON-LD 1.1, dat in 2020 een volledige W3C Recommendation werd.
De adoptie van JSON-LD versnelde aanzienlijk nadat Google en andere grote zoekmachines het in 2013 aanraadden als voorkeursformaat voor schema.org-markup. Deze aanbeveling was een keerpunt, omdat het de webontwikkelgemeenschap liet zien dat JSON-LD niet slechts een academisch experiment was, maar een praktische, productieklare oplossing voor SEO- en content discovery-uitdagingen. In het afgelopen decennium is het gebruik van JSON-LD exponentieel gegroeid: 41% van alle websites gebruikt nu JSON-LD voor gestructureerde gegevens, tegen 34% in 2022. Onder websites die een vorm van gestructureerde data toepassen, gebruikt circa 70% JSON-LD, waarmee het het toonaangevende formaat is binnen het structured data-landschap.
De evolutie van JSON-LD is ook beïnvloed door de opkomst van AI-gedreven zoekmachines en grote taalmodellen. Nu platforms zoals ChatGPT, Perplexity en Google AI Overviews gemeengoed zijn geworden, is het belang van JSON-LD toegenomen, omdat deze systemen sterk afhankelijk zijn van gestructureerde gegevens om accurate, contextuele informatie uit webpagina’s te halen. Het vermogen van het formaat om entiteitstypen, relaties en eigenschappen helder te definiëren, maakt het onmisbaar voor het trainen en inzetten van AI-systemen die webinhoud op schaal moeten begrijpen.
JSON-LD-documenten volgen de standaard JSON-syntaxis, maar bevatten speciale gereserveerde sleutelwoorden met het @-symbool die semantische betekenis geven. De belangrijkste hiervan zijn @context, @type en @id. De @context-eigenschap geeft de vocabulaire-namespace aan—meestal https://schema.org—die de betekenis bepaalt van alle eigenschappen en typen in de markup. Deze context fungeert als een namespace-verklaring, vergelijkbaar met XML-namespaces, zodat eigenschapsnamen consistent worden geïnterpreteerd over verschillende systemen en platforms.
De @type-eigenschap bepaalt het schema-type van de beschreven entiteit, zoals Product, Article, Event, Organization of LocalBusiness. Elk type in schema.org heeft een set bijbehorende eigenschappen waarmee instanties van dat type kunnen worden beschreven. Voor een Product-type zijn dat bijvoorbeeld eigenschappen als name, description, price, image, aggregateRating en offers. De @id-eigenschap biedt een unieke identificatie van de entiteit, meestal een URL die naar meer informatie leidt.
Naast deze kernsleutelwoorden bevatten JSON-LD-documenten aangepaste eigenschappen die direct overeenkomen met de schema.org-vocabulaire. Deze eigenschappen kunnen eenvoudige waarden bevatten (strings, getallen, datums) of complexe geneste objecten die gerelateerde entiteiten weergeven. Zo kan een Product-entiteit een offers-eigenschap hebben die een ingebed Offer-object bevat met een eigen @type en eigenschappen als price en priceCurrency. Dankzij deze nestingsmogelijkheid kan JSON-LD complexe gegevensrelaties en hiërarchieën uitdrukken die in platte formaten zoals Microdata lastig te representeren zijn.
| Aspect | JSON-LD | Microdata | RDFa |
|---|---|---|---|
| Implementatielocatie | Apart <script>-element in <head> of <body> | Ingebed in HTML-attributen | Ingebed in HTML-attributen |
| Implementatiegemak | Zeer eenvoudig; minimale HTML-aanpassingen nodig | Gemiddeld; vereist toevoeging van HTML-attributen | Gemiddeld tot complex; vereist namespace-verklaringen |
| Onderhoudscomplexiteit | Laag; data gescheiden van presentatie | Gemiddeld; markup vermengd met inhoud | Gemiddeld tot hoog; meerdere vocabularia mogelijk |
| Ondersteuning voor dynamische content | Uitstekend; werkt met JavaScript-injectie | Beperkt; vereist server-side rendering | Beperkt; vereist server-side rendering |
| Aanbeveling Google | Aanbevolen | Ondersteund | Ondersteund |
| Adoptiegraad (2024) | 41% van alle websites; 70% van structured data-sites | ~20% van structured data-sites | ~15% van structured data-sites |
| Vocabulaire-flexibiliteit | Eén vocabulaire per document (meestal schema.org) | Eén vocabulaire per document | Meerdere vocabularia ondersteund |
| Nesting-complexiteit | Uitstekend; natuurlijke JSON-hiërarchie | Goed; vereist meerdere itemscope-verklaringen | Goed; ondersteunt complexe relaties |
| Compatibiliteit met AI-zoekmachines | Uitstekend; voorkeur bij ChatGPT, Perplexity, Claude | Goed; ondersteund maar minder voorkeur | Goed; ondersteund maar minder voorkeur |
Wanneer een zoekmachinecrawler of AI-systeem een webpagina met JSON-LD-markup tegenkomt, wordt het <script type="application/ld+json">-element geparset en worden de gestructureerde gegevens eruit gehaald. De crawler gebruikt de @context om te begrijpen welke vocabulaire wordt gebruikt en interpreteert elke eigenschap volgens de definities van schema.org. Hierdoor kan de zoekmachine specifieke, machineleesbare informatie over de pagina-inhoud extraheren zonder afhankelijk te zijn van natuurlijke taalverwerking of heuristieken.
Voor Google Zoeken maakt JSON-LD-markup de weergave van rijke resultaten mogelijk—uitgebreide zoekfragmenten met visuele elementen zoals beoordelingen, prijzen, afbeeldingen en evenementdetails. Wanneer Google een productpagina crawlt met correct geïmplementeerde JSON-LD-markup, kan het de productnaam, prijs, beschikbaarheid, recensies en afbeeldingen direct uit de gestructureerde data halen. Deze informatie wordt vervolgens gebruikt om een rijk resultaat te genereren dat in de zoekresultaten verschijnt, doorgaans met een hoger doorklikpercentage dan standaard blauwe links. Onderzoek van grote websites toont het effect aan: Rotten Tomatoes zag een 25% hoger doorklikpercentage op pagina’s met gestructureerde data, terwijl Nestlé een 82% hoger doorklikpercentage mat op pagina’s die als rijke resultaten verschenen.
Voor AI-zoekmachines zoals Perplexity, ChatGPT en Google AI Overviews heeft JSON-LD een andere, maar even belangrijke functie. Deze systemen gebruiken gestructureerde gegevens om de semantische betekenis van inhoud te begrijpen, belangrijke entiteiten en relaties te identificeren en nauwkeurige informatie te extraheren voor opname in AI-gegenereerde antwoorden. Wanneer een AI-systeem JSON-LD-markup aantreft, kan het met vertrouwen bepalen welk type entiteit wordt beschreven, welke eigenschappen die entiteit heeft en hoe deze zich tot andere entiteiten verhoudt. Dit gestructureerde begrip helpt AI-systemen om accuratere, contextueel relevante antwoorden te geven en informatie correct toe te schrijven aan bronwebsites.
Effectieve implementatie van JSON-LD vereist inzicht in enkele kernprincipes en best practices. Ten eerste dient JSON-LD bij voorkeur in de <head>-sectie van het HTML-document geplaatst te worden, hoewel plaatsing in de <body> ook mogelijk is. De plaatsing in <head> heeft de voorkeur omdat zo de structured data wordt geparsed vóór de pagina-inhoud, al kunnen moderne zoekmachines en AI-systemen JSON-LD overal op de pagina herkennen.
Ten tweede moet de @context altijd expliciet worden gedefinieerd, doorgaans als "@context": "https://schema.org". Hierdoor worden alle eigenschapsnamen en typen volgens schema.org geïnterpreteerd. Hoewel het technisch mogelijk is om meerdere contexten of aangepaste vocabularia te gebruiken, maakt het overgrote deel van de webimplementaties exclusief gebruik van schema.org.
Ten derde moet de JSON-LD-markup de zichtbare inhoud op de pagina nauwkeurig weerspiegelen. Zoekmachines en AI-systemen verwachten dat de gestructureerde gegevens overeenkomen met wat gebruikers daadwerkelijk op de pagina zien. Het toevoegen van JSON-LD-markup voor informatie die niet zichtbaar is voor gebruikers—of die tegenstrijdig is met zichtbare inhoud—kan resulteren in sancties of genegeerde markup. Dit principe is cruciaal om vertrouwen te behouden bij zoekmachines en te zorgen dat AI-systemen je inhoud correct citeren.
Ten vierde moeten alle verplichte eigenschappen voor het gekozen schema-type worden opgenomen. Hoewel schema.org veel optionele eigenschappen biedt, zorgt het opnemen van de vereiste eigenschappen ervoor dat zoekmachines de markup correct kunnen valideren en weergeven. Voor een Product-schema zijn bijvoorbeeld minimaal de eigenschappen name, description en offers nodig om in aanmerking te komen voor rijke resultaten.
Ten vijfde moet JSON-LD worden gevalideerd met tools zoals de Google Rich Results Test of de Schema.org Validator vóór livegang. Deze tools controleren op syntaxisfouten, ontbrekende verplichte eigenschappen en andere problemen die kunnen voorkomen dat de markup wordt herkend. Testen tijdens ontwikkeling voorkomt problemen in productie en zorgt ervoor dat de markup functioneert zoals bedoeld.
Het toepassen van JSON-LD-structured data levert meetbare voordelen op diverse vlakken. Vanuit een SEO-perspectief stelt JSON-LD je in staat om rijke resultaten te verkrijgen die het doorklikpercentage aanzienlijk verhogen. Food Network converteerde 80% van hun pagina’s naar gestructureerde data en zag een 35% toename in bezoeken. Rakuten ontdekte dat gebruikers 1,5x meer tijd doorbrengen op pagina’s met gestructureerde gegevens ten opzichte van niet-gestructureerde pagina’s, en een 3,6x hogere interactiegraad op AMP-pagina’s met zoekfuncties.
Vanuit het perspectief van AI-zoekzichtbaarheid wordt JSON-LD steeds crucialer nu AI-zoekmachines gemeengoed worden. Websites die JSON-LD-markup implementeren, hebben meer kans dat hun inhoud nauwkeurig wordt begrepen, geciteerd en opgenomen in AI-gegenereerde antwoorden. Dit is met name van belang voor AmICited-gebruikers die willen volgen hoe hun merk, domein en URL’s verschijnen in AI-zoekresultaten op platforms als ChatGPT, Perplexity, Google AI Overviews en Claude. Correcte JSON-LD-implementatie zorgt ervoor dat AI-systemen de gestructureerde context hebben die nodig is om je inhoud correct toe te schrijven en te citeren.
Vanuit technisch oogpunt vermindert JSON-LD de implementatiecomplexiteit en het onderhoud. Omdat de markup losstaat van de HTML-inhoud, kunnen ontwikkelaars gestructureerde gegevens onafhankelijk van wijzigingen in de paginalay-out beheren. Dit is vooral waardevol voor grote organisaties met complexe contentmanagementsystemen, waar verschillende teams verantwoordelijk zijn voor inhoud en techniek.
Vanuit het oogpunt van gebruikerservaring verbetert JSON-LD indirect de betrokkenheid door rijkere, informatieve zoekresultaten mogelijk te maken. Gebruikers klikken sneller op zoekresultaten met beoordelingen, prijzen, afbeeldingen en andere gestructureerde informatie, wat leidt tot meer verkeer en betere conversiepercentages voor websites die JSON-LD effectief inzetten.
JSON-LD integreert naadloos met moderne webontwikkelingspraktijken en technologieën. In tegenstelling tot Microdata en RDFa, waarvoor server-side rendering nodig is om juist te worden geparsed door zoekmachines, kan JSON-LD dynamisch worden toegevoegd via JavaScript. Dit is essentieel voor single-page applications (SPA’s), progressive web apps (PWA’s) en andere JavaScript-rijke websites die inhoud dynamisch genereren.
Contentmanagementsystemen (CMS) zoals WordPress, Shopify, Wix en Drupal bieden steeds vaker standaard ondersteuning voor JSON-LD, hetzij native, hetzij via plug-ins. Dankzij deze democratisering van JSON-LD-implementatie kunnen zelfs niet-technische gebruikers gestructureerde gegevens aan hun pagina’s toevoegen zonder code te schrijven. Veel CMS-platforms genereren JSON-LD-markup automatisch op basis van paginametadata en inhoud, waardoor de last voor ontwikkelaars en contentmakers wordt verlaagd.
JSON-LD werkt ook uitstekend met headless CMS-architecturen, waarbij content losstaat van presentatie. In deze systemen kan JSON-LD server-side worden gegenereerd en meegeleverd als onderdeel van de paginarespons, of client-side worden vervaardigd met JavaScript-frameworks als React, Vue of Angular. Deze flexibiliteit maakt JSON-LD geschikt voor vrijwel elke moderne webarchitectuur.
https://schema.org voor consistente vocabulaire-interpretatieHet toekomstige belang van JSON-LD zal waarschijnlijk alleen maar toenemen. Naarmate AI-gedreven zoekmachines en grote taalmodellen geavanceerder worden, groeit de behoefte aan hoogwaardige, machineleesbare gestructureerde data. Zoekmachines en AI-systemen gebruiken gestructureerde gegevens steeds vaker niet alleen voor weergave, maar als kernonderdeel van hun begrip- en rangschikkingsalgoritmes.
Nieuwe ontwikkelingen in JSON-LD zijn onder meer JSON-LD-star, waarmee complexere kennisgraafrelaties worden ondersteund, en CBOR-LD, dat een compactere binaire representatie van JSON-LD-gegevens biedt. Deze uitbreidingen wijzen erop dat het JSON-LD-ecosysteem zal blijven evolueren om te voldoen aan de behoeften van steeds geavanceerdere webapplicaties en AI-systemen.
De opkomst van AI-zoekmachines betekent een paradigmaverschuiving in het gebruik van gestructureerde data. Traditionele zoekmachines gebruiken gestructureerde gegevens vooral voor weergave—om rijke resultaten te genereren. AI-zoekmachines gebruiken gestructureerde data daarentegen als fundamentele input voor hun begrip en redenering. Dit betekent dat websites die JSON-LD effectief implementeren een aanzienlijk voordeel hebben qua AI-zoekzichtbaarheid en citatiefrequentie.
Daarnaast kan JSON-LD een steeds belangrijkere rol gaan spelen bij het uitdrukken van gegevensherkomst, licenties en gebruiksrechten, naarmate privacy en datagovernance belangrijker worden. Dankzij de flexibiliteit en uitbreidbaarheid is het formaat goed inzetbaar voor het uitdrukken van complexe metadata over gegevensbronnen en gebruiksrestricties, wat steeds belangrijker zal worden nu organisaties controle willen houden over hoe hun data door AI-systemen wordt gebruikt.
Voor organisaties die platforms zoals AmICited gebruiken om hun verschijning in AI-zoekresultaten te monitoren, is het implementeren van uitgebreide JSON-LD-markup een strategische investering. Door AI-systemen duidelijke, gestructureerde context over je inhoud te bieden, vergroot je de kans dat je merk, domein en URL’s accuraat worden begrepen, geciteerd en opgenomen in AI-gegenereerde antwoorden. Nu AI-zoek steeds belangrijker wordt, wordt JSON-LD een essentieel onderdeel van elke toekomstbestendige SEO- en zichtbaarheidstrategie.
JSON-LD en Microdata zijn beide formaten voor gestructureerde gegevens, maar verschillen in implementatie. JSON-LD wordt opgenomen in een apart <script>-tag en is niet vermengd met HTML-inhoud, waardoor het makkelijker te onderhouden en op grote schaal toe te passen is. Microdata gebruikt HTML-attributen direct binnen de pagina-inhoud. Google raadt JSON-LD aan voor de meeste implementaties omdat het minder gevoelig is voor gebruikersfouten en naadloos werkt met dynamisch toegevoegde inhoud vanuit JavaScript-frameworks en contentmanagementsystemen.
JSON-LD stelt zoekmachines in staat pagina-inhoud beter te begrijpen, wat kan resulteren in rijke resultaten—uitgebreide zoekweergaven met beoordelingen, prijzen, afbeeldingen en andere gestructureerde informatie. Onderzoeken tonen aan dat pagina's met gestructureerde gegevens aanzienlijk hogere doorklikpercentages hebben. Zo mat Nestlé een 82% hoger doorklikpercentage op pagina's die als rijke resultaten werden weergegeven ten opzichte van pagina's zonder rijke resultaten, wat het directe effect van JSON-LD op zoekprestaties en gebruikersbetrokkenheid aantoont.
De @context in JSON-LD specificeert de vocabulaire-namespace (meestal schema.org) die de betekenis bepaalt van de eigenschappen en typen die in de markup worden gebruikt. Het werkt als een XML-namespace en geeft zoekmachines en AI-systemen aan hoe de gegevens moeten worden geïnterpreteerd. Bijvoorbeeld, @context: 'https://schema.org' geeft aan de parser aan dat @type-waarden zoals 'Product' of 'Article' verwijzen naar schema.org-definities, zodat consistente interpretatie over verschillende platforms en systemen wordt gegarandeerd.
Ja, gestructureerde gegevens met JSON-LD worden steeds belangrijker voor AI-zoekmachines. Platforms zoals ChatGPT, Perplexity en Google AI Overviews gebruiken gestructureerde gegevens om webpagina's beter te begrijpen en informatie eruit te halen. JSON-LD biedt machineleesbare context die deze AI-systemen helpt belangrijke entiteiten, relaties en inhoudstypen te identificeren, waardoor de kans toeneemt dat jouw inhoud wordt geciteerd en opgenomen in AI-gegenereerde antwoorden.
Belangrijke JSON-LD-eigenschappen zijn onder meer @context (definieert de vocabulaire), @type (specificeert het schema-type zoals Product of Article), @id (unieke identificatie van de entiteit) en aangepaste eigenschappen op basis van het schema-type. Voor een Product-schema kun je bijvoorbeeld name, description, price, image en aggregateRating opnemen. Elke eigenschap komt overeen met een schema.org-definitie, zodat zoekmachines specifieke informatie over je inhoud kunnen uitlezen en begrijpen.
Het gebruik van JSON-LD is sterk toegenomen en bereikte in 2024 41% van alle websites, tegenover 34% in 2022. Onder websites die gestructureerde gegevens gebruiken, is JSON-LD het meest gebruikte formaat, toegepast door circa 70% van de sites met gestructureerde gegevens. Deze groei weerspiegelt de aanbeveling van Google om JSON-LD te gebruiken en de eenvoud van implementatie ten opzichte van alternatieven zoals Microdata en RDFa.
JSON-LD biedt diverse voordelen ten opzichte van RDFa: het is eenvoudiger te implementeren en te onderhouden, hoeft niet met HTML-inhoud te worden vermengd, werkt naadloos met door JavaScript gegenereerde inhoud en is minder foutgevoelig. Hoewel RDFa het combineren van meerdere vocabularia mogelijk maakt voor complexe vereisten, maken de eenvoud van JSON-LD en de expliciete aanbeveling door Google het de voorkeurskeuze voor de meeste websites die gestructureerde gegevens voor zoekzichtbaarheid en AI-vindbaarheid willen implementeren.
Begin met het volgen van hoe AI-chatbots uw merk vermelden op ChatGPT, Perplexity en andere platforms. Krijg bruikbare inzichten om uw AI-aanwezigheid te verbeteren.
Leer wat JSON-LD is en hoe je het implementeert voor SEO. Ontdek de voordelen van gestructureerde data markup voor Google, ChatGPT, Perplexity en zichtbaarheid ...
Communitydiscussie over JSON-LD-implementatie voor AI-zoekzichtbaarheid. Ontwikkelaars en SEO's delen hoe gestructureerde data AI-citaties beïnvloeden en best p...
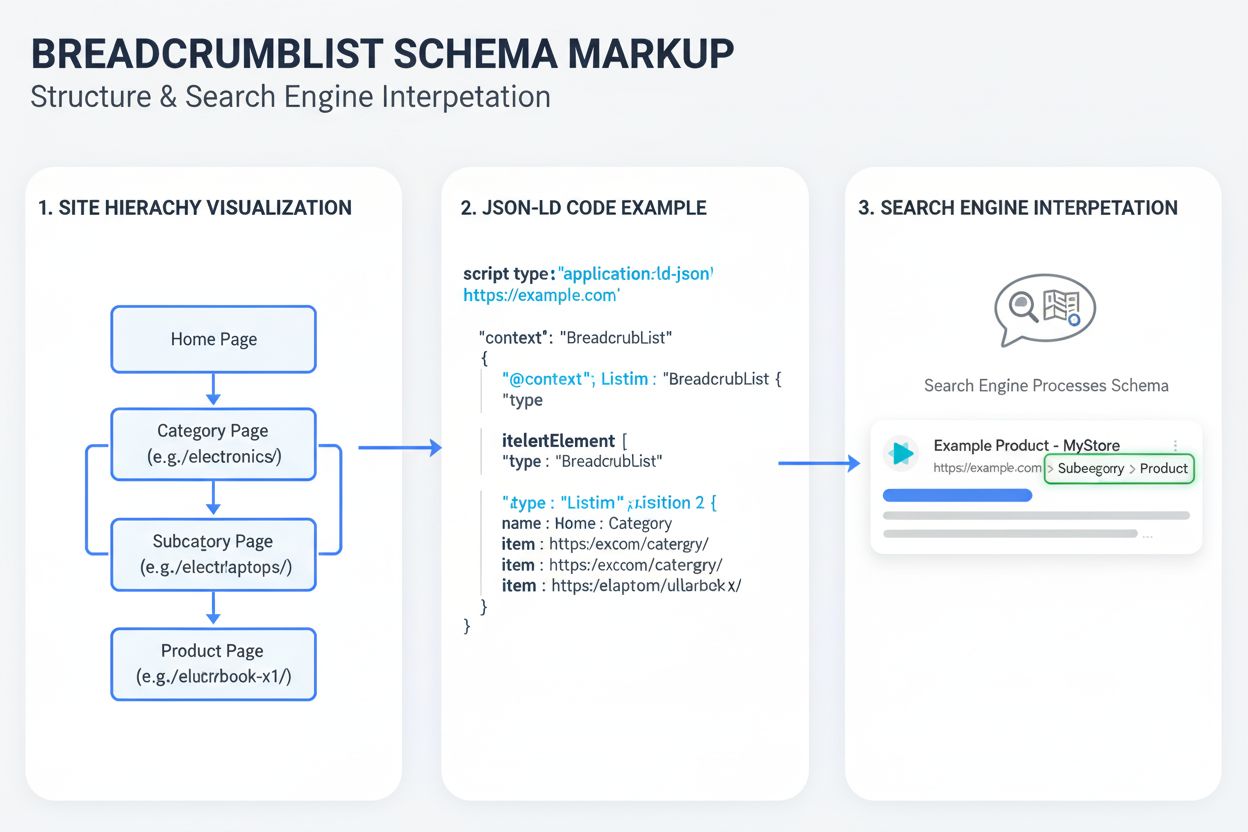
BreadcrumbList Schema is gestructureerde data-opmaak die zoekmachines helpt de hiërarchie van een site te begrijpen en breadcrumb-navigatie in zoekresultaten te...