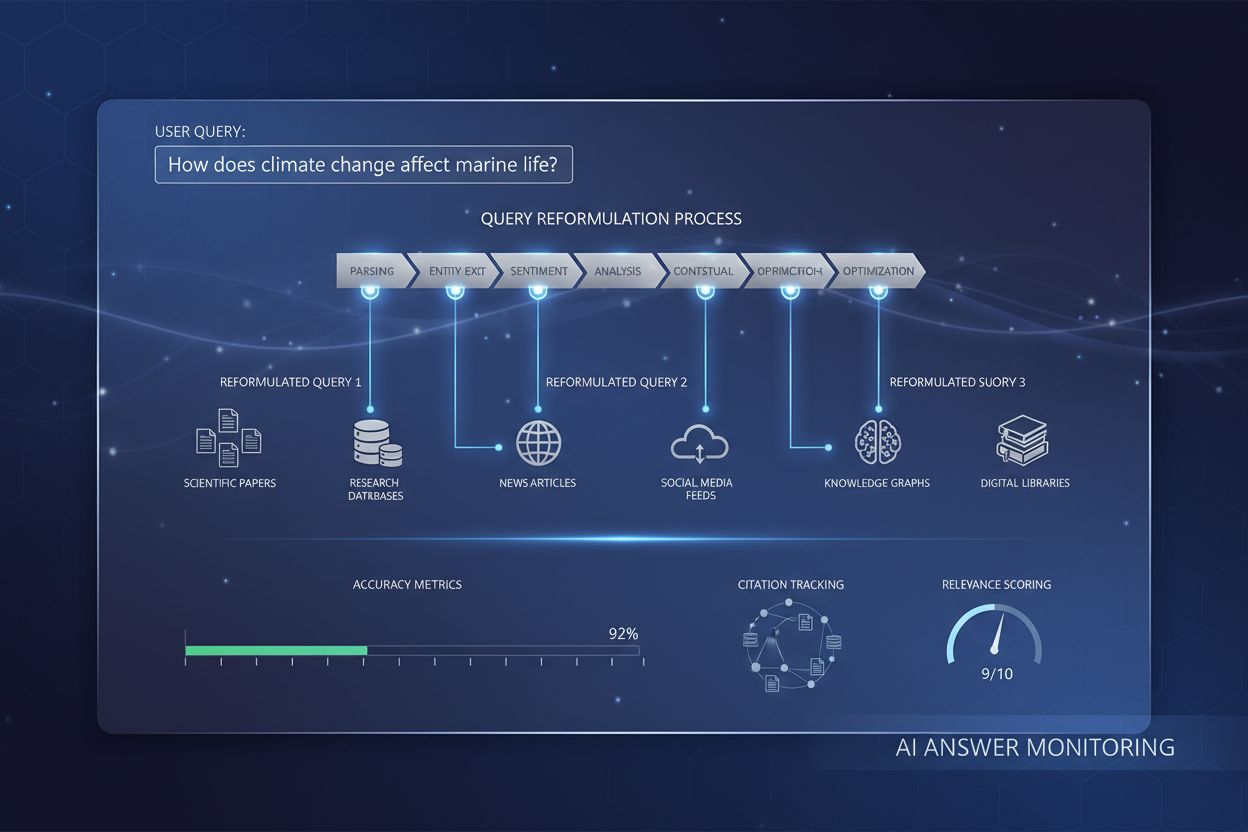
Query Reformulation
Ontdek hoe query-reformulering AI-systemen helpt gebruikersvragen te interpreteren en te verbeteren voor betere informatieopvraging. Begrijp de technieken, voor...
10 min lezen
Query expansion optimalisatie is het proces waarbij gebruikerszoekopdrachten worden uitgebreid met gerelateerde termen, synoniemen en contextuele variaties om de nauwkeurigheid van het ophalen en de relevantie van de inhoud in AI-systemen te verbeteren. Het overbrugt vocabulaireverschillen tussen gebruikersvragen en relevante documenten, zodat AI-systemen zoals GPT’s en Perplexity geschiktere inhoud kunnen vinden en refereren. Deze techniek is essentieel om zowel de volledigheid als de nauwkeurigheid van door AI gegenereerde antwoorden te verbeteren. Door queries intelligent uit te breiden, kunnen AI-platforms hun vermogen om relevante bronnen te ontdekken en te citeren drastisch verbeteren.
Query expansion optimalisatie is het proces waarbij gebruikerszoekopdrachten worden uitgebreid met gerelateerde termen, synoniemen en contextuele variaties om de nauwkeurigheid van het ophalen en de relevantie van de inhoud in AI-systemen te verbeteren. Het overbrugt vocabulaireverschillen tussen gebruikersvragen en relevante documenten, zodat AI-systemen zoals GPT's en Perplexity geschiktere inhoud kunnen vinden en refereren. Deze techniek is essentieel om zowel de volledigheid als de nauwkeurigheid van door AI gegenereerde antwoorden te verbeteren. Door queries intelligent uit te breiden, kunnen AI-platforms hun vermogen om relevante bronnen te ontdekken en te citeren drastisch verbeteren.
Query Expansion Optimalisatie is het proces van het herformuleren en verrijken van zoekopdrachten door gerelateerde termen, synoniemen en semantische variaties toe te voegen om de prestaties van informatieophaling en de kwaliteit van antwoorden te verbeteren. In de kern pakt query expansion het vocabulaireverschillenprobleem aan—de fundamentele uitdaging dat gebruikers en AI-systemen vaak verschillende terminologie gebruiken om dezelfde concepten te beschrijven, waardoor relevante resultaten worden gemist. Deze techniek is cruciaal voor AI-systemen, omdat het de kloof overbrugt tussen hoe mensen hun informatiebehoefte uitdrukken en hoe content daadwerkelijk wordt geïndexeerd en opgeslagen. Door zoekopdrachten intelligent uit te breiden, kunnen AI-platforms zowel de relevantie als de volledigheid van hun antwoorden drastisch verbeteren.
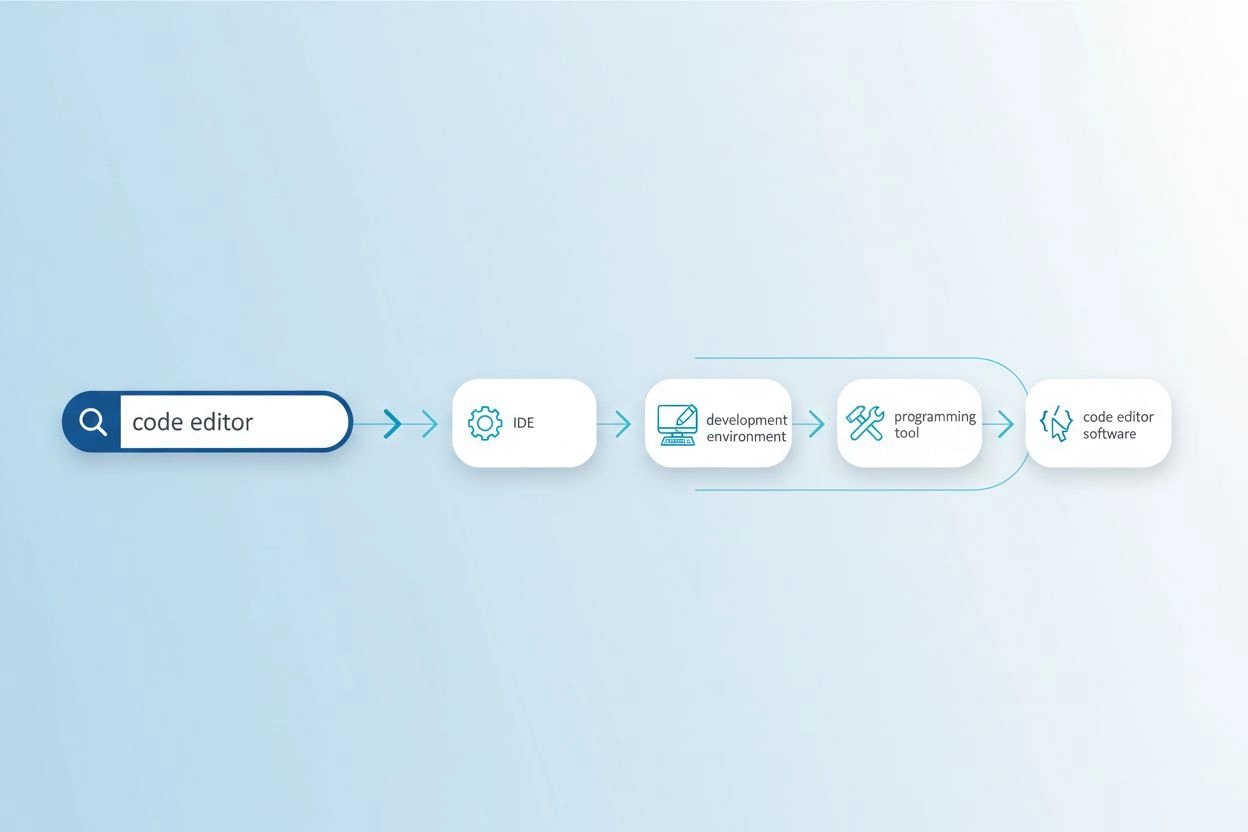
Het vocabulaireverschillenprobleem ontstaat wanneer de exacte woorden die in een zoekopdracht worden gebruikt, niet overeenkomen met de terminologie in relevante documenten, waardoor zoeksystemen waardevolle informatie missen. Zo kan een gebruiker die zoekt op “code editor” geen resultaten vinden over “IDEs” (Integrated Development Environments) of “teksteditors”, terwijl deze juist zeer relevant zijn. Evenzo kan iemand die zoekt op “voertuig” geen resultaten vinden met de tags “auto”, “automobiel” of “motorvoertuig”, ondanks de duidelijke semantische overlap. Dit probleem wordt steeds ernstiger in gespecialiseerde domeinen waar meerdere technische termen hetzelfde concept beschrijven, en het beïnvloedt direct de kwaliteit van door AI gegenereerde antwoorden door de beschikbare broninformatie te beperken. Query expansion lost dit op door automatisch gerelateerde zoekvariaties te genereren die verschillende manieren dekken waarop dezelfde informatie kan worden uitgedrukt.
| Oorspronkelijke zoekopdracht | Uitgebreide zoekopdracht | Impact |
|---|---|---|
| code editor | IDE, teksteditor, ontwikkelomgeving, broncode-editor | Vindt 3-5x meer relevante resultaten |
| machine learning | AI, kunstmatige intelligentie, deep learning, neurale netwerken | Vangt domeinspecifieke terminologievariaties |
| voertuig | auto, automobiel, motorvoertuig, transport | Bevat veelgebruikte synoniemen en gerelateerde termen |
| hoofdpijn | migraine, spanningshoofdpijn, pijnbestrijding, hoofdpijnbehandeling | Pakt medische terminologievariaties aan |
Moderne query expansion maakt gebruik van verschillende complementaire technieken, elk met eigen voordelen afhankelijk van het gebruiksdoel en domein:
Elke techniek biedt een andere balans tussen rekenkosten, uitbreidingskwaliteit en domeinspecificiteit, waarbij LLM-gebaseerde benaderingen de hoogste kwaliteit leveren maar meer middelen vereisen.
Query expansion verbetert AI-antwoorden door taalmodellen en zoeksystemen een rijkere, meer volledige set bronmateriaal te bieden voor het genereren van antwoorden. Wanneer een zoekopdracht wordt uitgebreid met synoniemen, gerelateerde concepten en alternatieve formuleringen, kan het zoeksysteem documenten vinden die een andere terminologie gebruiken maar even relevante informatie bevatten, wat de recall van het zoekproces sterk verhoogt. Deze bredere context stelt AI-systemen in staat meer volledige en genuanceerde antwoorden te geven, omdat ze niet langer beperkt worden door de specifieke woordkeuze in de oorspronkelijke zoekopdracht. Echter, query expansion introduceert een trade-off tussen precisie en recall: uitgebreide zoekopdrachten halen meer relevante documenten op, maar kunnen ook ruis en minder relevante resultaten opleveren als de uitbreiding te agressief is. De sleutel tot optimalisatie is het afstemmen van de uitbreidingsintensiteit om de relevantie te maximaliseren en irrelevante ruis te minimaliseren, zodat AI-antwoorden vollediger worden zonder aan nauwkeurigheid in te boeten.
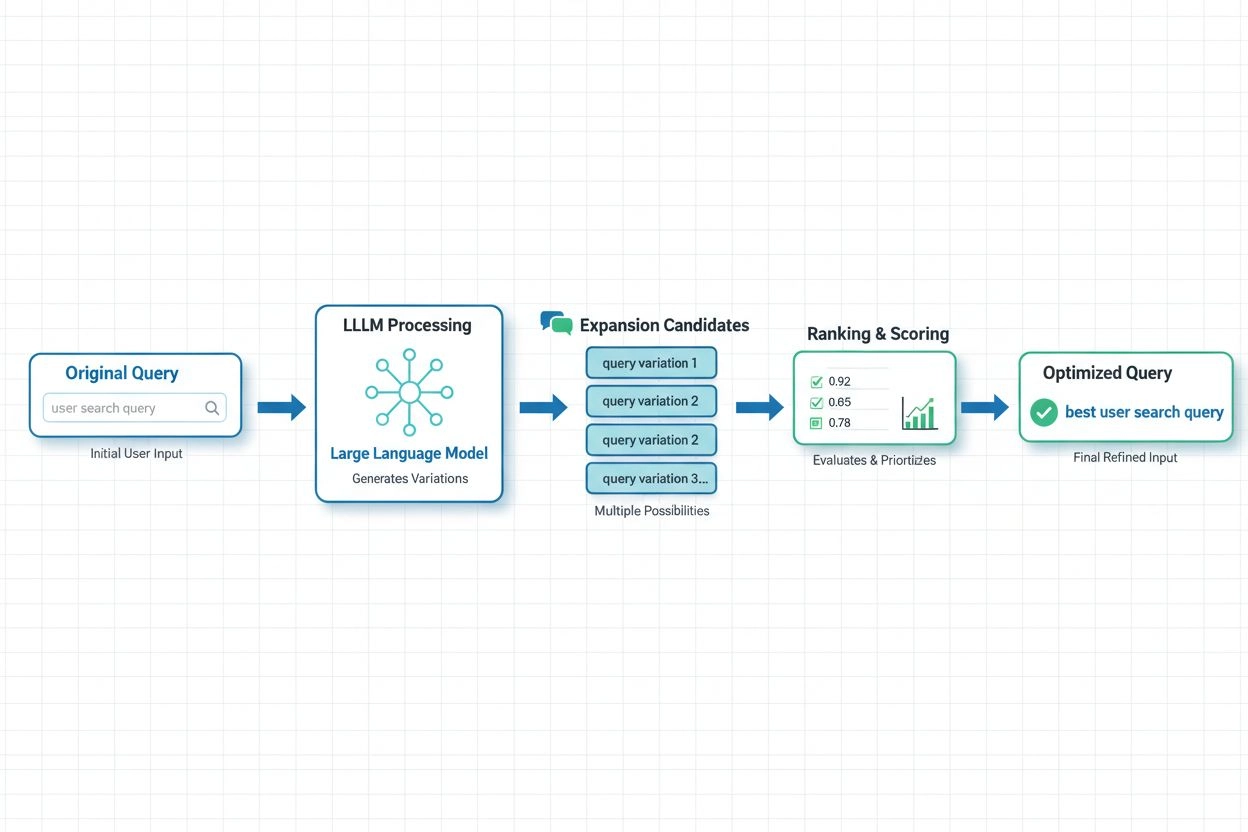
In moderne AI-systemen is LLM-gebaseerde query expansion de meest geavanceerde benadering, waarbij de semantische begripscapaciteiten van grote taalmodellen worden ingezet om contextueel geschikte zoekvariaties te genereren. Recent onderzoek van Spotify toont de kracht van deze aanpak: hun implementatie, die preferentieafstemmingstechnieken combineert (RSFT en DPO-methoden), realiseerde ongeveer 70% reductie in verwerkingstijd en tegelijkertijd een verbetering van de top-1 retrievalnauwkeurigheid. Deze systemen werken door taalmodellen te trainen die gebruikersvoorkeuren en intenties begrijpen en uitbreidingen genereren die aansluiten bij wat gebruikers daadwerkelijk waardevol vinden in plaats van zomaar synoniemen toe te voegen. Real-time optimalisatieaanpakken passen uitbreidingsstrategieën continu aan op basis van gebruikersfeedback en retrievalresultaten, waardoor systemen leren welke uitbreidingen het beste werken voor specifieke zoektypes en domeinen. Deze dynamische aanpak is vooral waardevol voor AI-monitoringplatformen, omdat systemen zo kunnen volgen hoe query expansion de citatienauwkeurigheid en contentontdekking beïnvloedt over verschillende onderwerpen en sectoren.
Ondanks de voordelen brengt query expansion aanzienlijke uitdagingen met zich mee die zorgvuldige optimalisatiestrategieën vereisen. Het over-expansieprobleem doet zich voor wanneer te veel zoekvariaties worden toegevoegd, waardoor ruis en irrelevante documenten worden opgehaald die de antwoordkwaliteit verwateren en de rekenkosten verhogen. Domeinspecifieke afstemming is essentieel, omdat uitbreidingsmethoden die goed werken voor algemene webzoekopdrachten kunnen falen in gespecialiseerde vakgebieden zoals medisch onderzoek of juridische documentatie, waar terminologische precisie cruciaal is. Organisaties moeten een balans vinden tussen dekking en nauwkeurigheid—genoeg uitbreiden om relevante variaties te dekken zonder zó ver te gaan dat irrelevante resultaten het signaal overheersen. Effectieve validatiebenaderingen zijn onder andere het uitvoeren van A/B-tests met verschillende uitbreidingsstrategieën tegen door mensen beoordeelde relevantie, monitoren van statistieken zoals precision@k en recall@k en continu analyseren welke uitbreidingen daadwerkelijk de prestaties bij downstream taken verbeteren. De meest succesvolle implementaties gebruiken adaptieve uitbreiding die de intensiteit aanpast op basis van zoekkenmerken, domeincontext en geobserveerde retrievalkwaliteit, in plaats van uniforme uitbreidingsregels op alle zoekopdrachten toe te passen.
Voor AmICited.com en AI-monitoringplatformen is query expansion optimalisatie fundamenteel voor het accuraat volgen van hoe AI-systemen bronnen citeren en refereren over verschillende onderwerpen en zoekcontexten. Wanneer AI-systemen intern uitgebreide zoekopdrachten gebruiken, krijgen ze toegang tot een breder scala aan potentiële bronnen, wat direct van invloed is op welke citaties in hun antwoorden verschijnen en hoe volledig ze de beschikbare informatie dekken. Dit betekent dat het monitoren van de kwaliteit van AI-antwoorden niet alleen vereist te begrijpen wat gebruikers vragen, maar ook welke uitgebreide zoekvariaties het AI-systeem mogelijk achter de schermen gebruikt om ondersteunende informatie op te halen. Merken en contentmakers moeten hun contentstrategie optimaliseren door te overwegen hoe hun materiaal ontdekt kan worden via query expansion—door diverse terminologievariaties, synoniemen en gerelateerde concepten in hun content te verwerken om zichtbaar te zijn bij verschillende zoekformuleringen. AmICited helpt organisaties hierbij door te monitoren hoe hun content verschijnt in door AI gegenereerde antwoorden over diverse zoektypes en uitbreidingen, door gaten bloot te leggen waar content mogelijk wordt gemist vanwege vocabulaireverschillen en door inzicht te geven in hoe query expansion strategieën citatiepatronen en contentontdekking in AI-systemen beïnvloeden.
Query expansion voegt gerelateerde termen en synoniemen toe aan de oorspronkelijke zoekopdracht terwijl de kernintentie behouden blijft, terwijl query rewriting de volledige zoekopdracht herformuleert om beter aan te sluiten bij de mogelijkheden van het zoeksysteem. Query expansion is toevoegend—het verbreedt de zoekscope—terwijl rewriting transformerend is en de manier verandert waarop de zoekopdracht wordt uitgedrukt. Beide technieken verbeteren het ophalen, maar uitbreiding is doorgaans minder risicovol omdat het de oorspronkelijke intentie behoudt.
Query expansion heeft direct invloed op welke bronnen AI-systemen ontdekken en citeren omdat het de beschikbare documenten voor retrieval verandert. Wanneer AI-systemen intern uitgebreide zoekopdrachten gebruiken, krijgen ze toegang tot een breder scala aan potentiële bronnen, wat van invloed is op welke citaties in hun antwoorden verschijnen. Dit betekent dat het monitoren van de kwaliteit van AI-antwoorden niet alleen vereist te begrijpen wat gebruikers vragen, maar ook welke uitgebreide zoekvariaties het AI-systeem mogelijk op de achtergrond gebruikt.
Ja, overmatige uitbreiding kan ruis veroorzaken en irrelevante documenten ophalen die de kwaliteit van het antwoord verwateren. Dit gebeurt wanneer te veel zoekvariaties worden toegevoegd zonder adequate filtering. De sleutel is het balanceren van de intensiteit van de uitbreiding om de relevantie te maximaliseren en irrelevante ruis te minimaliseren. Effectieve implementaties gebruiken adaptieve uitbreiding die de intensiteit aanpast op basis van de kenmerken van de zoekopdracht en geobserveerde retrievalkwaliteit.
Large Language Models hebben query expansion getransformeerd door semantisch begrip van gebruikersintentie mogelijk te maken en contextueel geschikte zoekvariaties te genereren. LLM-gebaseerde uitbreiding gebruikt preferentieafstemmingstechnieken om modellen te trainen die uitbreidingen genereren die daadwerkelijk de retrievalresultaten verbeteren, in plaats van alleen willekeurige synoniemen toe te voegen. Recent onderzoek toont aan dat LLM-gebaseerde benaderingen de verwerkingstijd met ~70% kunnen verminderen terwijl de retrievalnauwkeurigheid wordt verbeterd.
Merken moeten meerdere terminologievariaties, synoniemen en gerelateerde concepten in hun content verwerken om zichtbaar te zijn bij verschillende zoekformuleringen. Dit betekent nadenken over hoe uw materiaal ontdekt kan worden via query expansion—door zowel technische als alledaagse termen te gebruiken, alternatieve formuleringen op te nemen en gerelateerde concepten te adresseren. Deze strategie zorgt ervoor dat uw content vindbaar blijft ongeacht welke zoekvariaties AI-systemen gebruiken.
Belangrijke statistieken zijn onder andere precision@k (relevantie van de top-k resultaten), recall@k (dekking van relevante inhoud in de top-k resultaten), Mean Reciprocal Rank (positie van het eerste relevante resultaat) en prestaties bij downstream taken. Organisaties monitoren ook verwerkingstijd, computationele kosten en gebruikersfeedback. A/B-testen met verschillende uitbreidingsstrategieën tegen door mensen beoordeelde relevantie leveren de meest betrouwbare validatie op.
Nee, het zijn complementaire maar verschillende technieken. Query expansion wijzigt de invoerzoekopdracht om het ophalen te verbeteren, terwijl semantisch zoeken gebruikmaakt van embeddings en vectorrepresentaties om conceptueel vergelijkbare inhoud te vinden. Query expansion kan onderdeel zijn van een semantische zoekpipeline, maar semantisch zoeken kan ook werken zonder expliciete query expansion. Beide technieken pakken vocabulaireverschillen aan, maar via verschillende mechanismen.
AmICited volgt hoe AI-systemen bronnen citeren en refereren over verschillende onderwerpen en zoekcontexten, en laat zien welke uitgebreide zoekopdrachten ertoe leiden dat uw merk wordt genoemd. Door citatiepatronen te monitoren over diverse zoektypes en uitbreidingen, biedt AmICited inzicht in hoe query expansion strategieën contentontdekking en citatienauwkeurigheid in AI-systemen zoals GPT's en Perplexity beïnvloeden.
Query expansion optimalisatie beïnvloedt hoe AI-systemen zoals GPT's en Perplexity uw content ontdekken en citeren. Gebruik AmICited om te volgen welke uitgebreide zoekopdrachten leiden tot het noemen van uw merk in AI-antwoorden.
Ontdek hoe query-reformulering AI-systemen helpt gebruikersvragen te interpreteren en te verbeteren voor betere informatieopvraging. Begrijp de technieken, voor...

Query refinement is het iteratieve proces van het optimaliseren van zoekopdrachten voor betere resultaten in AI-zoekmachines. Leer hoe het werkt bij ChatGPT, Pe...

Leer strategieën voor AI-zoekoptimalisatie om de zichtbaarheid van je merk te vergroten in ChatGPT, Google AI Overviews en Perplexity. Optimaliseer content voor...