Factoren die AI-systemen gebruiken om te bepalen welke bronnen ze citeren, waaronder autoriteit, actualiteit, relevantie en semantische volledigheid. Deze signalen verschillen aanzienlijk van traditionele SEO-rangschikkingsfactoren en geven prioriteit aan contentkwaliteit, E-E-A-T-signalen en realtime verificatie boven backlinks en domeinleeftijd.
Signalen voor Bronranking
Factoren die AI-systemen gebruiken om te bepalen welke bronnen ze citeren, waaronder autoriteit, actualiteit, relevantie en semantische volledigheid. Deze signalen verschillen aanzienlijk van traditionele SEO-rangschikkingsfactoren en geven prioriteit aan contentkwaliteit, E-E-A-T-signalen en realtime verificatie boven backlinks en domeinleeftijd.
Wat zijn signalen voor bronranking?
Signalen voor bronranking zijn de specifieke factoren die AI-systemen evalueren wanneer ze bepalen welke bronnen ze citeren in hun gegenereerde antwoorden. In tegenstelling tot traditionele zoekmachinerankings die zich richten op trefwoordrelevantie en backlink-autoriteit, gebruiken AI-systemen een fundamenteel andere set criteria om te bepalen welke content het waard is om als referentie te dienen. Deze signalen beoordelen of een bron gezaghebbend, actueel, relevant voor de vraag en betrouwbaar genoeg is om te citeren. Inzicht in deze signalen is cruciaal voor merken die zichtbaarheid willen op AI-gestuurde zoekplatforms zoals ChatGPT, Perplexity en Google AI Overviews. Onderzoek naar miljoenen AI-citaties heeft zeven kern ranking-signalen geïdentificeerd die consequent voorspellen of content wordt geciteerd, met correlatiesterktes variërend van r=0,92 (multi-modale content) tot r=0,31 (bedrijfsregels).
Ranking-signaal
Correlatiesterkte
Sleutelmeter
Impact
Multi-modale contentintegratie
r=0,92
+156% tot +317% boost
Hoogste impact
Semantische volledigheid
r=0,87
4,2x hoger als score >8,5/10
Zeer hoog
Realtime feitelijke verificatie
r=0,89
+89% selectiekans
Zeer hoog
Vector embedding alignment
r=0,84
7,3x hoger bij scores >0,88
Hoog
E-E-A-T autoriteitssignalen
r=0,81
96% van citaties heeft sterke E-E-A-T
Hoog
Entiteit knowledge graph dichtheid
r=0,76
4,8x hoger met 15+ entiteiten
Hoog
Gestructureerde data implementatie
+73% boost
Schema markup voordeel
Matig
De Zeven Kern Ranking-signalen Uitgelegd
AI-systemen vertrouwen niet op één magische formule om bronnen te selecteren. In plaats daarvan evalueren ze content via zeven verschillende ranking-signalen die samenwerken om de citatiewaardigheid te bepalen. Elk signaal vervult een specifieke rol in de evaluatiepipeline, en door te begrijpen hoe ze werken zie je waarom sommige bronnen consequent worden geciteerd terwijl andere onzichtbaar blijven.
1. Relevantie (basisranking): Dit fundamentele signaal bepaalt of content daadwerkelijk de gebruikersvraag beantwoordt. AI-systemen gebruiken semantisch begrip om intentie van de vraag te koppelen aan de betekenis van de content, en gaan verder dan eenvoudige trefwoordmatching. Een vraag over “duurzame verpakkingsoplossingen” matcht met content over milieuvriendelijke materialen, biologisch afbreekbare alternatieven en milieu-impact—niet alleen pagina’s met exact die woorden.
2. Onderwerpduidelijkheid: AI-systemen breken content op in semantische blokken (meestal 300-500 tokens) en zetten die om in vector-embeddings—wiskundige representaties van betekenis. Dit signaal meet hoe duidelijk elk blok zijn onderwerp communiceert. Content met expliciete onderwerpvermeldingen, logische structuur en gefocuste alinea’s scoort hoger dan ronddwalende content die afwijkt naar verwante concepten.
3. Trefwoordmatch: Hoewel semantisch begrip domineert, dient trefwoordmatching nog steeds als ondersteunend signaal om semantische afwijking te voorkomen. Dit zorgt ervoor dat AI-systemen content citeren die de specifieke vraag daadwerkelijk beantwoordt, niet alleen iets dat er zijdelings mee te maken heeft. Voor een vraag over “machine learning-algoritmen” voorkomt trefwoordmatching dat content over “filosofie van kunstmatige intelligentie” wordt geciteerd ondanks semantische overeenkomsten.
4. Engagementsignalen: AI-systemen evalueren hoe waarschijnlijk het is dat gebruikers de content bevredigend vinden via PCTR (predictive click-through rate), wat gebruikersvoldoening benadert op basis van historische interactiepatronen. Content met duidelijke lay-outs, aantrekkelijke snippets, snelle laadtijden en mobiele optimalisatie scoort hoger omdat gebruikers historisch gezien met deze kenmerken interageren.
5. Actualiteit: AI-systemen herkennen wanneer timing belangrijk is voor bepaalde onderwerpen. Vragen met tijdelijke intentie (actualiteit, prijzen, trends) activeren evaluatie van actualiteit. AI controleert publicatiedata en update-tijdstempels om te waarborgen dat geciteerde content actuele informatie bevat. Content die binnen het afgelopen jaar is geüpdatet krijgt aanzienlijke voordelen qua actualiteit, met 65% van AI-bothits gericht op content van minder dan één jaar oud.
6. Vertrouwen en autoriteit (E-E-A-T): Dit signaal beoordeelt of bronnen Ervaring, Expertise, Autoriteit en Betrouwbaarheid tonen. AI-systemen verifiëren auteur-credentials, controleren op externe merkmeldingen, evalueren gebruikersreviews en beoordelen de diepgang van de content. Zesennegentig procent van AI-citaties komt van bronnen met sterke E-E-A-T-signalen, wat dit tot een van de belangrijkste factoren maakt.
7. Bedrijfsregels: De laatste laag bevat veiligheids-overrides en kwaliteitsfilters. AI-systemen geven officiële gezondheids-, financiële- en juridische bronnen een boost, terwijl spam, desinformatie en beleidsovertredende content worden onderdrukt. Deze laag zorgt ervoor dat AI Overviews kwaliteit en veiligheidsnormen handhaven, ongeacht andere ranking-signalen.
Ready to Monitor Your AI Visibility?
Track how AI chatbots mention your brand across ChatGPT, Perplexity, and other platforms.
Autoriteit- en Vertrouwenssignalen: Het E-E-A-T-raamwerk
E-E-A-T is geëvolueerd van een Google-richtlijn voor contentkwaliteit naar een actief filtermechanisme voor AI-citaties. Zesennegentig procent van de content die door grote AI-systemen wordt geciteerd, toont sterke E-E-A-T-signalen, waardoor dit raamwerk essentieel is voor AI-zichtbaarheid. AI-systemen verifiëren actief elk component voordat content voor citatie wordt overwogen.
Ervaring: Heeft de maker van de content directe ervaring met het onderwerp? AI let op specifieke uitkomsten, details achter de schermen en een persoonlijk perspectief. Content met “Uit onze analyse van 847 klantimplementaties zagen we…” weegt zwaarder dan “Uit studies blijkt…” zonder specificaties. Signalen van eerstehands ervaring zijn meetbare resultaten, gedocumenteerde processen en authentieke casestudy’s.
Expertise: Heeft de auteur relevante kennis, opleiding of professionele kwalificaties? AI-systemen verifiëren credentials via externe bronnen en controleren op gepubliceerde werken, certificeringen en erkenning in de sector. Auteur-schema markup met credentials, institutionele affiliaties en relevante prijzen verbetert de kans op citatie aanzienlijk. Een artikel van “Dr. Sarah Chen, AI Research Lead aan Stanford University” weegt zwaarder dan anonieme content.
Autoriteit: Wordt de contentmaker erkend als dé bron in het vakgebied? AI beoordeelt of andere gezaghebbende bronnen de auteur citeren, of ze spreken op branche-evenementen en of ze consistent als expert gepositioneerd zijn over verschillende platforms. Merken die op 4+ platforms verschijnen, worden 2,8 keer vaker door AI-systemen geciteerd.
Betrouwbaarheid: Kunnen gebruikers erop vertrouwen dat de content accuraat, transparant en veilig is? AI kijkt naar HTTPS-implementatie, duidelijke contactinformatie, privacybeleid, bekendmaking van affiliaties en correctiebeleid. Content met positieve online recensies, responsieve klantenservice en gedocumenteerde nauwkeurigheidspraktijken scoort hoger. Vertrouwensproblemen zoals beveiligingswaarschuwingen of desinformatiegeschiedenis kunnen het citatiepotentieel permanent beschadigen.
Actualiteit en Contentrecency
Actualiteit van content is een cruciaal ranking-signaal geworden nu AI-systemen steeds meer prioriteit geven aan actuele informatie. Vijfenzestig procent van de AI-bothits zijn gericht op content die binnen het afgelopen jaar is gepubliceerd, en negenenzeventig procent komt van content die binnen twee jaar is geüpdatet. Dit betekent een drastische verschuiving ten opzichte van traditionele SEO, waar evergreen content oneindig lang kon ranken zonder updates.
AI-systemen herkennen tijdelijke intentie—vragen waarbij timing sterk meespeelt. Vragen over “huidige AI-trends”, “marketingstrategieën voor 2025” of “nieuwste AI-tools” activeren beoordeling van actualiteit. AI controleert publicatiedata, update-tijdstempels en schema markup om te waarborgen dat geciteerde content actuele informatie bevat. Content ouder dan zes jaar krijgt slechts zelden een citaat, tenzij het gaat om fundamentele of historische informatie.
Het actualiteitssignaal werkt verschillend per platform. ChatGPT vertrouwt op trainingsdata met een kennis-cutoff, waardoor oudere content minder snel wordt opgehaald uit parametische kennis. Perplexity en Google AI Overviews gebruiken realtime retrieval en verkiezen actief recent geüpdatete content. Evergreen content aanvullen met actuele statistieken, recente voorbeelden en nieuwe inzichten kan de citatiekansen aanzienlijk verhogen, zelfs voor bestaande pagina’s.
Stay Updated on AI Visibility Trends
Get the latest insights on AI mentions, brand monitoring, and optimization strategies.
Semantische Volledigheid en Relevantie
Semantische volledigheid meet of content een volledig, zelfstandig antwoord biedt dat geen extra context of extra klikken vereist om te begrijpen. Dit is de sterkste voorspeller van AI-citatie (r=0,87 correlatie), waarbij content met een score boven 8,5/10 4,2 keer zo vaak wordt geciteerd als content onder 6,0/10.
AI-systemen beoordelen of elke passage zelfstandig kan dienen als citeerbare eenheid. Een semantisch volledig antwoord bevat een direct antwoord op de kernvraag, benodigde context en definities, specifieke voorbeelden of datapunten en een korte conclusie. Incomplete antwoorden verwijzen naar “zoals eerder vermeld”, vereisen het lezen van eerdere secties of gebruiken onverklaarde jargon. Wanneer AI een passage extraheert voor citatie, moet deze waarde leveren aan gebruikers zonder dat ze omliggende content hoeven te lezen.
Vector-embeddings—wiskundige representaties van betekenis—bepalen semantische afstemming. Content met cosine similarity scores boven 0,88 toont 7,3 keer hogere selectieratio’s dan content onder 0,75. Dit betekent dat het dekken van het semantische spectrum van je onderwerp (gerelateerde concepten, synoniemen, contextuele relaties) belangrijker is dan trefwoorddichtheid. Voor een onderwerp als “AI Overviews” vereist semantische volledigheid het bespreken van rankingfactoren, optimalisatietactieken, platformverschillen en implementatiestrategieën—niet alleen de term definiëren.
Multi-modale Content en Gestructureerde Data
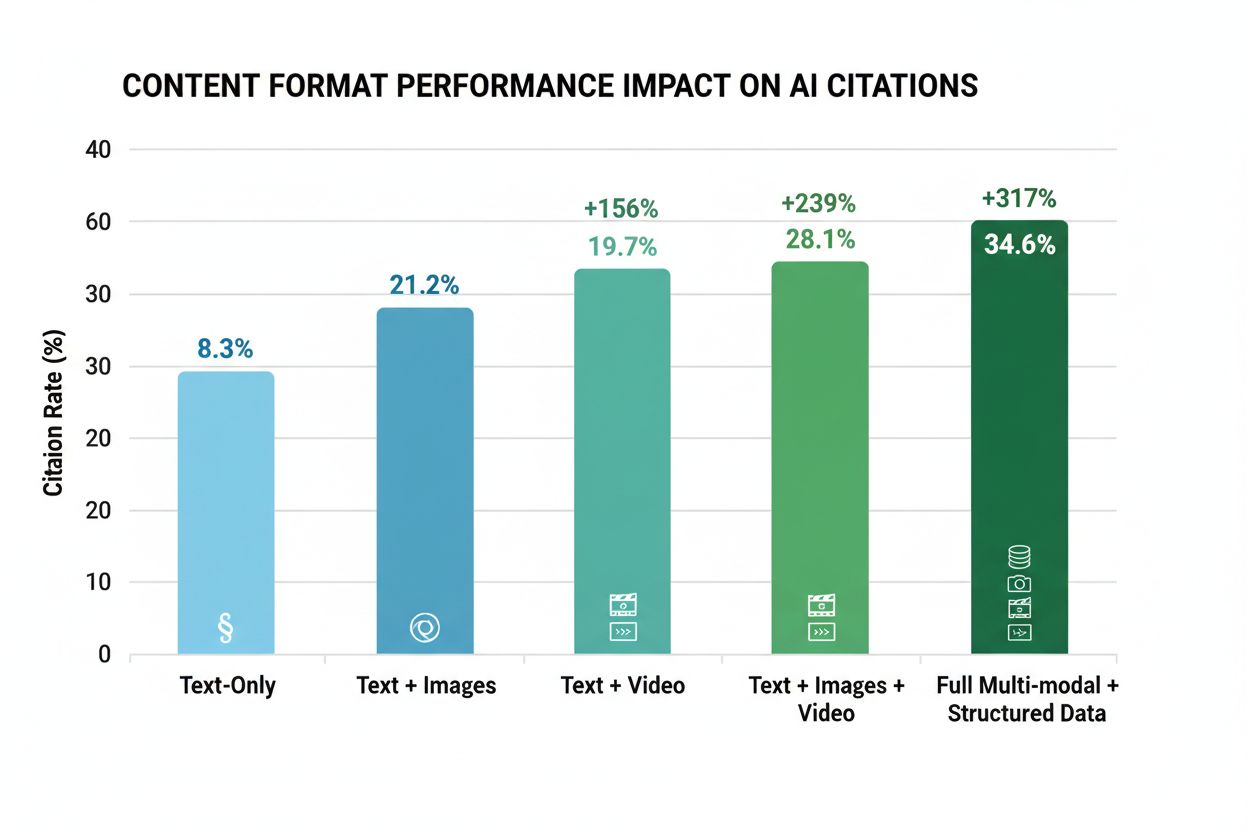
Integratie van multi-modale content is de grootste rankingverschuiving in 2025, met r=0,92 correlatie met AI-citatie—de hoogste van alle ranking-signalen. Content die tekst, afbeeldingen, video’s en gestructureerde data combineert laat 156% tot 317% hogere selectieratio’s zien dan alleen tekst. Het gaat niet om decoratieve afbeeldingen; het draait om strategische integratie waarbij elk element de andere ondersteunt en versterkt.
Contentformaat
Citatieratio
Verbetering
Alleen tekst
8,3%
Basislijn
Tekst + afbeeldingen
21,2%
+156%
Tekst + video
19,7%
+137%
Tekst + afbeeldingen + video
28,1%
+239%
Volledig multi-modaal + schema
34,6%
+317%
Gestructureerde data markup (schema.org) communiceert expliciet aan AI-systemen wat je content bevat. FAQ-schema voedt direct AI-vraag-antwoord-extractie, HowTo-schema maakt stapsgewijze extractie mogelijk en Article-schema geeft contenttype en actualiteit aan. Juist geïmplementeerde schema markup alleen al zorgt voor een +73% selectieboost. In combinatie met multi-modale content vermenigvuldigt het effect zich.
Afbeeldingen moeten concepten uitleggen, niet alleen de pagina sieren. Infographics die dataverhoudingen tonen, geannoteerde screenshots van processen en vergelijkende tabellen als grafieken verhogen allemaal de kans op citatie. Video’s werken het best als 60-90 seconden explainers die complexe onderwerpen simpel maken. YouTube-video’s worden steeds vaker geïntegreerd in AI Overviews, waardoor video-optimalisatie essentieel is voor maximale zichtbaarheid.
Platformspecificieke Rankingverschillen
Verschillende AI-platforms wegen ranking-signalen anders, wat platformgerichte optimalisatiestrategieën vereist. ChatGPT vertrouwt sterk op parametische kennis uit trainingsdata, waarbij Wikipedia domineert met 47,9% van de citaties. Perplexity legt de nadruk op realtime retrieval, waarbij Reddit leidt met 46,7% van de citaties. Google AI Overviews behouden een sterkere correlatie met traditionele SEO, terwijl ze bronnen over meerdere platforms spreiden.
Signaal
ChatGPT
Perplexity
Google AIO
Wikipedia
47,9%
8,2%
12,1%
Reddit
12,3%
46,7%
21,0%
YouTube
18,2%
13,9%
15,4%
Domeinautoriteit
Matig
Laag
Matig
Contentactualiteit
Training cutoff
Realtime cruciaal
Belangrijk
E-E-A-T-signalen
Zeer hoog
Hoog
Zeer hoog
Door ChatGPT’s parametische kennis hangt merkzichtbaarheid af van de frequentie in trainingsdata. Aanwezigheid op Wikipedia, mediavermeldingen en thought leadership op gezaghebbende platforms vergroten de representatie in trainingsdata. Perplexity’s realtime retrieval betekent dat actualiteit van content, engagement op Reddit en actuele informatie de boventoon voeren. Google AI Overviews combineren traditionele SEO-principes met AI-specifieke signalen, waardoor zowel traditionele rankings als E-E-A-T van belang zijn.
Cross-platform optimalisatie is essentieel, want slechts 11% van de domeinen wordt geciteerd door zowel ChatGPT als Perplexity. Een complete strategie vereist aanwezigheid op meerdere platforms: officiële website met sterke E-E-A-T, Wikipedia (indien relevant), Reddit-community-engagement, YouTube-content, vakpublicaties en G2/Capterra-reviews. Merken op 4+ platforms hebben 2,8 keer meer kans om in AI-antwoorden te verschijnen.
Hoe optimaliseer je voor signalen van bronranking
Optimaliseren voor signalen van bronranking vereist een fundamenteel andere aanpak dan traditionele SEO. In plaats van rankings te najagen, focus je op het bieden van het meest gezaghebbende, volledige en verifieerbare antwoord op de vragen van je doelgroep.
Bouw eerst E-E-A-T-signalen op: Voeg gedetailleerde auteursbiografieën met credentials toe, implementeer Person- en Organization-schema, link naar LinkedIn-profielen van auteurs en toon relevante certificaten. Dit is de snelste manier om de kans op citatie te vergroten.
Implementeer uitgebreide schema markup: Voeg FAQ-, Article-, HowTo- en ImageObject-schema toe aan alle relevante content. Valideer met Google’s Rich Results Test. Juist gestructureerde content toont +73% hogere selectieratio’s.
Zorg voor contentactualiteit: Update evergreen content met actuele statistieken, recente voorbeelden en nieuwe inzichten. Onderhoud “laatst bijgewerkt”-data en gebruik schema markup om actualiteit te signaleren. Streef naar updates binnen het afgelopen jaar.
Creëer semantisch volledige content: Structureer content zodat individuele alinea’s zelfstandig als citeerbare eenheden kunnen dienen. Begin met directe antwoorden, gebruik alinea’s van 40-60 woorden voor optimale chunking en vermijd verwijzingen naar “eerder genoemde secties”.
Ontwikkel multi-modale content: Combineer tekst met contextuele afbeeldingen, verklarende video’s en datavisualisaties. Zorg dat elk element waarde toevoegt in plaats van decoratie. Gebruik correcte alt-tekst en bijschriften.
Bouw entiteit-autoriteit op: Noem 15-20 relevante entiteiten per 1.000 woorden. Link entiteiten naar gezaghebbende bronnen. Maak of optimaliseer Wikidata-entries. Bouw aanwezigheid op meerdere platforms waar AI-systemen gezaghebbende stemmen vinden.
Voeg verifieerbare citaties toe: Neem specifieke, gezaghebbende citaties op voor belangrijke claims. Link naar originele bronnen, niet naar aggregators. Gebruik Tier 1-bronnen (peer-reviewed onderzoek, overheidsdata) voor maximale geloofwaardigheid.
Optimaliseer voor toegankelijkheid: Snelle paginasnelheden, mobielvriendelijkheid, duidelijke navigatie en semantische HTML verbeteren zowel AI-crawler-toegang als gebruikersvoldoeningssignalen.
Veelvoorkomende Misvattingen over Bronranking
Traditionele SEO-wijsheden zijn vaak strijdig met wat daadwerkelijk werkt voor AI-citaties. Het begrijpen van deze misvattingen voorkomt verspilling van tijd aan tactieken die geen zichtbaarheid meer opleveren.
Misvatting: Backlinks zijn cruciaal voor AI-citaties. Realiteit: Backlinks tonen een zwakke of neutrale correlatie met AI-citaties (r=0,18 voor domeinautoriteit). Merkzoekvolume (0,334 correlatie) is een veel sterkere voorspeller. AI-systemen beoordelen contentautoriteit onafhankelijk van linkprofielen.
Misvatting: Keyword stuffing verbetert AI-zichtbaarheid. Realiteit: Keyword stuffing presteert slechter in generatieve engines dan in traditionele zoekmachines. AI-systemen herkennen en bestraffen onnatuurlijke keywordherhaling. Natuurlijke taalvariaties en semantische volledigheid zijn veel belangrijker.
Misvatting: Afbeeldingen en video’s toevoegen verbetert automatisch citaties. Realiteit: Multi-modale content helpt alleen bij strategische integratie. Willekeurige afbeeldingen of video’s zonder contextuele relevantie hebben geen meetbaar effect. Content moet eerst semantisch volledig zijn; multi-modale elementen versterken, maar vervangen geen kwaliteit.
Misvatting: Op #1 ranken garandeert AI-citaties. Realiteit: Slechts 4,5% van AI Overview-URL’s kwam overeen met een organisch resultaat op pagina 1. Zevenenveertig procent van AI-citaties komt van pagina’s die lager dan positie 5 ranken. Contentautoriteit is belangrijker dan rankingpositie.
Factor
Impact traditionele SEO
Impact AI-citatie
Aantal backlinks
HOOG
Zwak/Neutraal
Keyword stuffing
Negatief
Nog negatiever
Afbeeldingen/video’s
Engagementboost
Geen impact zonder integratie
#1 ranking
Primair doel
Slechts 4,5% correlatie
Domeinleeftijd
Positief signaal
Irrelevant
E-E-A-T-signalen
Belangrijk
Kritiek (96% van citaties)
Contentactualiteit
Behulpzaam
Essentieel (65% <1 jaar oud)
Meten en Volgen van Bronrankingprestaties
Het volgen van AI-citatieprestaties vereist andere metrics dan traditionele SEO. Share of Voice meet welk percentage van AI-antwoorden je merk noemt versus concurrenten. Citation Frequency volgt hoe vaak jouw URL’s verschijnen over verschillende platforms. Merk sentiment beoordeelt of vermeldingen positief, negatief of neutraal zijn. Citation Drift—de maandelijkse volatiliteit in citaties—ligt doorgaans tussen 40-60%, waardoor voortdurende optimalisatie essentieel is.
Enterprise-tools zoals Profound volgen 240+ miljoen ChatGPT-citaties met concurrentiebenchmarks en GA4-integratie. Semrush’s AI Toolkit integreert met bestaande SEO-suites. Mid-market opties zoals LLMrefs, Peec AI en First Answer bieden keyword-to-prompt mapping en share of voice tracking vanaf $50-400 per maand. Budgetvriendelijke tools zoals Otterly.AI, Scrunch AI en Knowatoa bieden domeincitatietracking en GEO-audits vanaf $30-50 per maand.
Effectieve meting combineert kwantitatieve tracking met kwalitatieve analyse. Monitor je top 20 zoekwoorden maandelijks door ChatGPT, Perplexity en Google AI Overviews direct te bevragen. Documenteer welke bronnen verschijnen, hoe ze worden geciteerd en welke contentkenmerken ze delen. Gebruik deze inzichten voor het bepalen van optimalisatieprioriteiten. Volg niet alleen of je wordt geciteerd, maar ook hoe prominent en in welke context. Een citaat in de openingszin weegt zwaarder dan een vermelding als ondersteunend bewijs.
De merken die AI-citaties domineren, optimaliseren niet voor één signaal—ze implementeren alle zeven signalen systematisch in een geïntegreerde strategie. Ze bouwen E-E-A-T-signalen op, creëren semantisch volledige content, implementeren gestructureerde data, ontwikkelen multi-modale assets, behouden actualiteit en bouwen cross-platform autoriteit. Deze allesomvattende aanpak maakt het verschil tussen merken die worden geciteerd en merken die onzichtbaar blijven in het AI-gestuurde zoeklandschap.
Veelgestelde vragen
Wat is het verschil tussen signalen voor bronranking en traditionele SEO-rangschikkingsfactoren?
Signalen voor bronranking evalueren contentkwaliteit, autoriteit en relevantie specifiek voor AI-citatiedoeleinden, terwijl traditionele SEO-factoren zich richten op zoekmachineresultaten. AI-systemen geven prioriteit aan semantische volledigheid, E-E-A-T-signalen en realtime verificatie boven backlinks en domeinleeftijd. Domeinautoriteit vertoont slechts een correlatie van r=0,18 met AI-citaties, vergeleken met 0,43 in traditionele SEO, waardoor pagina-niveau signalen veel belangrijker zijn dan site-brede metrics.
Hoe belangrijk is domeinautoriteit voor AI-bronranking?
Domeinautoriteit is een zwakke voorspeller geworden voor AI-citaties, met een correlatie die is gedaald tot r=0,18 (was 0,43 voor 2024). AI-systemen evalueren contentautoriteit onafhankelijk van domeinautoriteit, wat betekent dat nieuwere of kleinere websites vaker geciteerd kunnen worden dan gevestigde high-DA domeinen als hun content sterkere E-E-A-T-signalen, semantische volledigheid en realtime verificatie toont.
Kunnen nieuwe websites door AI-systemen geciteerd worden?
Ja, nieuwe websites kunnen absoluut door AI-systemen geciteerd worden als ze sterke E-E-A-T-signalen tonen, hoogwaardige en volledige content publiceren en actualiteit behouden. Onderzoek toont aan dat 65% van de AI-bothits gericht is op content die binnen het afgelopen jaar is gepubliceerd, en 79% op content die binnen 2 jaar is geüpdatet. Het opbouwen van auteur-credentials, het implementeren van gestructureerde data en het creëren van semantisch volledige content is veel belangrijker dan domeinleeftijd.
Waarom verschijnt Wikipedia in zoveel AI-citaties?
Wikipedia domineert AI-citaties (verschijnt in ~18,4% van alle citaties en 47,9% van de ChatGPT-antwoorden) omdat het ~22% van de belangrijkste LLM-trainingsdata vertegenwoordigt en perfecte semantische volledigheid, E-E-A-T-signalen en een neutraal perspectief toont. Wikipedia-content is gestructureerd voor eenvoudige extractie, beantwoordt vragen volledig zonder externe referenties en is afkomstig van geverifieerde bijdragers, waardoor het een ideale bron is voor AI-citaties.
Hoe vaak updaten AI-systemen hun bronranking?
Citaatpatronen tonen aanzienlijke maandelijkse volatiliteit, met Google AI Overviews die 59,3% maandelijkse citaatverschuiving hebben en ChatGPT 54,1%. Dit betekent dat bronrankings regelmatig veranderen doordat AI-systemen hun trainingsdata updaten, retrieval-algoritmes aanpassen en reageren op contentactualiteit. Continue optimalisatie en monitoring zijn essentieel voor het behouden van AI-zichtbaarheid.
Wat is de snelste manier om signalen voor bronranking te verbeteren?
De snelste verbeteringen komen van: (1) Het implementeren van E-E-A-T-signalen via auteur-credentials en expertcitaten (+78-89% zichtbaarheid), (2) Toevoegen van gestructureerde data zoals FAQ- en Articleschema (+73% selectieboost), (3) Zorgen voor actualiteit met recente updates, en (4) Creëren van semantisch volledige content die vragen volledig beantwoordt zonder externe referenties. Deze aanpassingen kunnen binnen 2-4 weken resultaat tonen.
Verbetert multi-modale content (afbeeldingen en video's) echt AI-citaties?
Ja, multi-modale content verbetert AI-citaties aanzienlijk. Content met tekst plus afbeeldingen toont +156% hogere selectieratio's, tekst plus video +137% verbetering en volledig multi-modaal met gestructureerde data +317% verbetering vergeleken met alleen tekst. Maar simpelweg afbeeldingen en video's toevoegen zonder strategische integratie helpt niet—ze moeten contextueel relevant zijn en correct gestructureerd met schema markup.
Monitor je AI-citatieautoriteit
Volg hoe AI-systemen jouw merk citeren in ChatGPT, Perplexity en Google AI Overviews. Begrijp je signalen voor bronranking en optimaliseer voor maximale AI-zichtbaarheid.
Hoe verhoog je AI-trustsignalen voor betere zichtbaarheid in AI-zoekopdrachten
Ontdek hoe je AI-trustsignalen verhoogt in ChatGPT, Perplexity en Google AI Overviews. Bouw entiteit-identiteit, bewijs en technische trust op om AI-citaties te...
Relevantiesignalen zijn indicatoren die AI-systemen gebruiken om de toepasbaarheid van content te beoordelen. Leer hoe zoekwoordovereenkomst, semantische releva...
Hoe bouw je domeinautoriteit op voor AI-zoekmachines
Leer hoe je domeinautoriteit opbouwt die door AI-zoekmachines wordt herkend. Ontdek strategieën voor entiteitsoptimalisatie, citaties, thematische autoriteit en...
8 min lezen
Cookie Toestemming We gebruiken cookies om uw browse-ervaring te verbeteren en ons verkeer te analyseren. See our privacy policy.