
Gestructureerde gegevens
Gestructureerde gegevens zijn gestandaardiseerde opmaak die zoekmachines helpt om de inhoud van webpagina's te begrijpen. Ontdek hoe JSON-LD, schema.org en micr...
10 min lezen

Schema-markup die speciaal is ontworpen om AI-systemen te helpen inhoud nauwkeurig te begrijpen en te citeren. Gestructureerde gegevens gebruiken gestandaardiseerde formaten zoals JSON-LD om expliciete context te bieden over de pagina-inhoud, waardoor grote taalmodellen informatie betrouwbaarder kunnen parseren en bronnen met meer vertrouwen kunnen citeren.
Schema-markup die speciaal is ontworpen om AI-systemen te helpen inhoud nauwkeurig te begrijpen en te citeren. Gestructureerde gegevens gebruiken gestandaardiseerde formaten zoals JSON-LD om expliciete context te bieden over de pagina-inhoud, waardoor grote taalmodellen informatie betrouwbaarder kunnen parseren en bronnen met meer vertrouwen kunnen citeren.
Gestructureerde gegevens voor AI verwijzen naar georganiseerde, machineleesbare informatie die is geformatteerd volgens gestandaardiseerde schema’s waarmee kunstmatige intelligentiesystemen inhoud nauwkeurig kunnen begrijpen, interpreteren en gebruiken. In tegenstelling tot ongestructureerde tekst, waarvoor complexe natuurlijke taalverwerking nodig is om betekenis te ontcijferen, bieden gestructureerde gegevens expliciete context over wat informatie vertegenwoordigt. Deze duidelijkheid is essentieel omdat AI-systemen—vooral grote taalmodellen en zoekmachines—dagelijks miljarden datapunten verwerken. Wanneer inhoud wordt gestructureerd met standaarden als schema.org, JSON-LD of microdata, kan AI direct entiteiten, relaties en attributen herkennen zonder ambiguïteit. Deze gestructureerde benadering levert 300% hogere nauwkeurigheid in AI-begrip op in vergelijking met ongestructureerde alternatieven. Voor organisaties die zichtbaarheid willen in AI Overviews en andere AI-gegenereerde resultaten, zijn gestructureerde gegevens onmisbare infrastructuur geworden. Het transformeert ruwe inhoud in intelligentie die AI-systemen vol vertrouwen kunnen citeren, verwijzen en opnemen in hun antwoorden, wat fundamenteel verandert hoe digitale inhoud vindbaar wordt in een door AI aangedreven wereld.

AI-systemen verwerken gestructureerde gegevens via een geavanceerde pijplijn die gemarkeerde inhoud omzet in bruikbare intelligentie. Wanneer een AI correct geformatteerde gestructureerde gegevens tegenkomt, kan het direct essentiële informatie extraheren zonder de computationele belasting van natuurlijke taalinterpretatie. Het technische mechanisme volgt deze essentiële stappen:
Dit proces stelt AI in staat om meer dan 30% hogere zichtbaarheid in AI Overviews te leveren voor correct gestructureerde inhoud. De gestructureerde aanpak vermindert het risico op hallucinaties door AI-antwoorden te verankeren aan expliciete, verifieerbare data in plaats van probabilistische tekstgeneratie. Organisaties die een uitgebreide gestructureerde datastrategie implementeren, zien meetbare verbeteringen in hoe AI-systemen hun inhoud ontdekken, begrijpen en promoten op meerdere platforms en toepassingen.
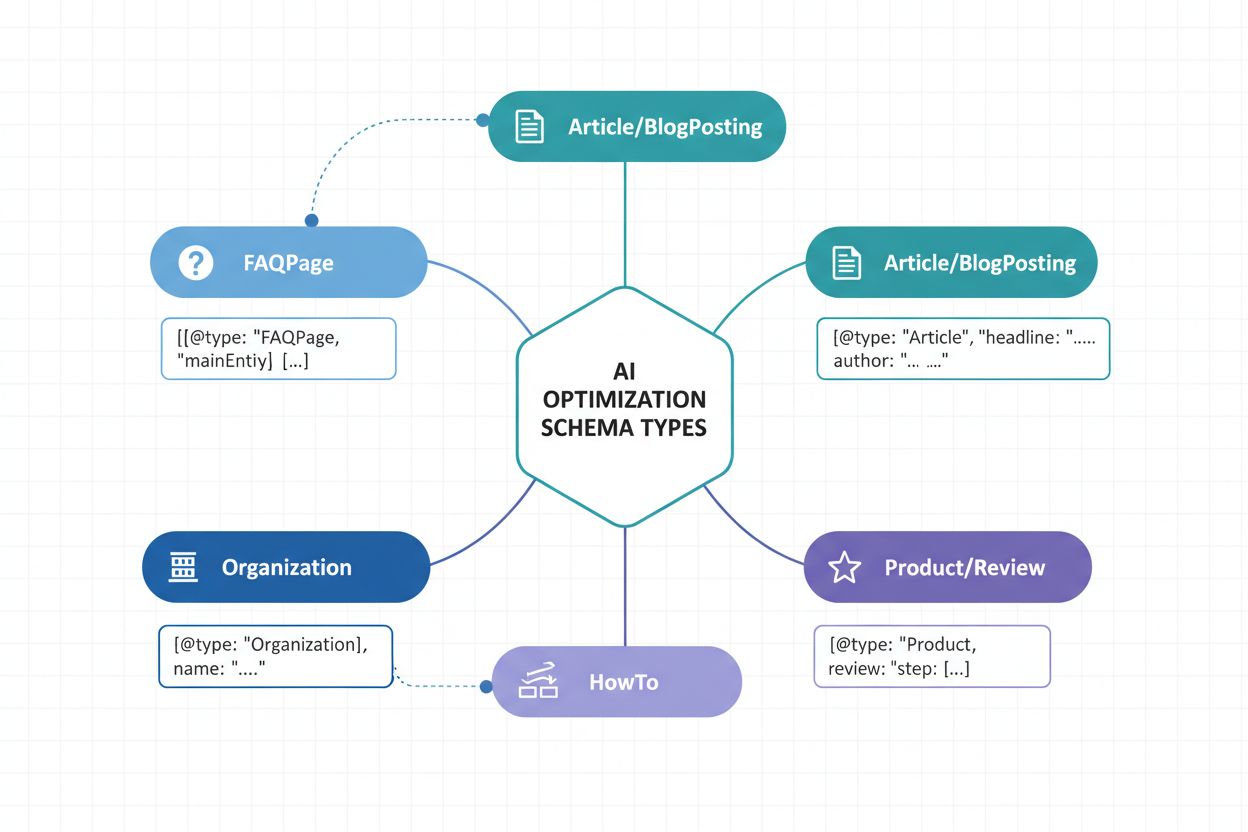
Het implementeren van de juiste schema-typen is fundamenteel voor een AI-zichtbaarheidsstrategie. Verschillende inhoudstypen vereisen specifieke gestructureerde data-markup om hun aard en waarde aan AI-systemen te communiceren. Hier zijn de essentiële schema-typen voor maximale AI-herkenning:
Article Schema - Markeert nieuwsartikelen, blogposts en longform-inhoud met kop, auteur, publicatiedatum en hoofdtekst. Cruciaal voor AI-systemen om gezaghebbende broninhoud te identificeren en publicatie-autoriteit vast te stellen.
Organization Schema - Definieert bedrijfsidentiteit, inclusief naam, logo, contactgegevens en sociale profielen. Stelt AI in staat om organisatie-inhoud correct te herkennen en toe te wijzen in diverse contexten.
Product Schema - Structureert productinformatie zoals naam, beschrijving, prijs, beschikbaarheid en beoordelingen. Essentieel voor zichtbaarheid in e-commerce AI-assistenten en productaanbevelingssystemen.
LocalBusiness Schema - Markeert bedrijfsadres, openingstijden, contactgegevens en diensten. Onmisbaar voor lokale AI-zoekopdrachten en locatiegebaseerde AI Overviews die zoekresultaten steeds meer domineren.
BreadcrumbList Schema - Definieert de hiërarchie van site-navigatie, zodat AI de contentstructuur en relaties tussen pagina’s in uw informatiearchitectuur begrijpt.
FAQPage Schema - Structureert veelgestelde vragen met antwoorden, waardoor AI-systemen specifieke Q&A-inhoud direct kunnen extraheren en citeren in antwoorden.
NewsArticle en BlogPosting Schema’s - Gespecialiseerde artikeltypen die de inhoudscategorie aan AI-systemen signaleren, waardoor categorisatie en relevantiematching worden verbeterd.
Event Schema - Markeert evenementdetails zoals datum, locatie, beschrijving en registraties, essentieel voor AI-evenementontdekking en kalenderintegratie.
Momenteel gebruiken 45 miljoen domeinen schema.org-markup, wat 12,4% van alle domeinen wereldwijd vertegenwoordigt. Organisaties die meerdere schema-typen tegelijkertijd implementeren, zien samengestelde zichtbaarheidsvoordelen doordat AI-systemen rijkere contextuele inzichten krijgen in hun content-ecosysteem.
Succesvolle implementatie van gestructureerde gegevens vereist strategische planning en technische precisie. Organisaties dienen deze bewezen best practices te volgen om AI-zichtbaarheid te maximaliseren en datanauwkeurigheid te waarborgen:
Hier is een praktisch JSON-LD-voorbeeld voor een artikel:
{
"@context": "https://schema.org",
"@type": "Article",
"headline": "Gestructureerde gegevens voor AI: Strategische implementatiegids",
"author": {
"@type": "Person",
"name": "Contentauteur"
},
"datePublished": "2024-01-15",
"image": "https://example.com/image.jpg",
"articleBody": "Volledige artikeltekst hier...",
"publisher": {
"@type": "Organization",
"name": "Uw organisatie",
"logo": "https://example.com/logo.png"
}
}
Juiste implementatie levert 35% verbetering in CTR op via rich results in traditionele zoekresultaten, met extra voordelen naarmate AI Overviews het primaire kanaal voor ontdekking worden. Organisaties die hun prestaties van gestructureerde data monitoren via oplossingen zoals AmICited.com behalen concurrentievoordeel door te achterhalen welke contenttypen en schema-implementaties de hoogste AI-zichtbaarheid genereren.
Zowel gestructureerde gegevens als llms.txt dienen AI-vindbaarheid, maar werken via fundamenteel verschillende mechanismen. Gestructureerde gegevens maken gebruik van gestandaardiseerde schema’s (schema.org, JSON-LD) die in HTML zijn ingebed om specifieke content-elementen van expliciete semantische betekenis te voorzien. Deze aanpak integreert direct in webpagina’s, waardoor informatie direct beschikbaar is voor zowel zoekmachines als AI-systemen tijdens het crawlen. Gestructureerde data maakt gedetailleerde markup mogelijk van afzonderlijke artikelen, producten, evenementen en organisaties, zodat AI precieze relaties en attributen begrijpt.
llms.txt daarentegen is een tekstbestand in de hoofdmap van een website met instructies en richtlijnen voor grote taalmodellen. Het fungeert als manifestbestand dat voorkeuren communiceert over hoe AI-systemen met uw content moeten omgaan en deze moeten citeren. Hoewel llms.txt op hoog niveau richtlijnen biedt over gebruiksrechten en citatievoorkeuren, mist het de semantische precisie van gestructureerde data. Gestructureerde data beantwoordt de vraag “wat is deze inhoud?” met expliciete machineleesbare antwoorden, terwijl llms.txt antwoordt “hoe moet je deze inhoud gebruiken?” als leidraad.
De meest effectieve strategie combineert beide benaderingen: gestructureerde data zorgt ervoor dat AI-systemen uw inhoud nauwkeurig begrijpen en kunnen citeren, terwijl llms.txt duidelijke gebruiksrichtlijnen en citatie-eisen vastlegt. Organisaties die beide implementeren, zien 36% meer kans om te verschijnen in AI-gegenereerde samenvattingen vergeleken met organisaties die geen van beide gebruiken. Gestructureerde data vormt het fundament voor AI-begrip, terwijl llms.txt het governance-kader biedt voor correcte attributie en naleving.
Het meten van de effectiviteit van gestructureerde gegevens vereist het volgen van specifieke metrics die laten zien hoe AI-systemen uw inhoud ontdekken, begrijpen en citeren. Organisaties moeten deze belangrijke prestatie-indicatoren monitoren:
AmICited.com biedt gespecialiseerde monitoring voor AI-citatieprestaties, waardoor organisaties kunnen volgen hoe hun investeringen in gestructureerde data zich vertalen naar daadwerkelijke AI-zichtbaarheid en attributie. Het platform laat zien welke content AI-citaties ontvangt, welke queries uw content triggeren en hoe uw citatiefrequentie zich verhoudt tot die van concurrenten. Deze data-gedreven aanpak maakt van gestructureerde data-implementatie een meetbaar zakelijk voordeel.
Organisaties die een uitgebreide gestructureerde datastrategie hanteren, rapporteren dat 93% van de zoekopdrachten door AI wordt beantwoord zonder klikken, waardoor zichtbaarheid in citaties steeds belangrijker wordt om verkeer te genereren. Het meten van citatieprestaties garandeert dat uw investeringen in gestructureerde data kwantificeerbare rendementen opleveren dankzij verbeterde AI-vindbaarheid en merktoeschrijving.
Succesvolle implementatie van gestructureerde gegevens volgt een gefaseerde aanpak die de capaciteit stapsgewijs opbouwt en bij elke fase meetbare waarde oplevert. Organisaties dienen hun implementatietijdlijn als volgt te structureren:
Fase 1: Fundament (maanden 1-2)
Fase 2: Uitbreiding (maanden 3-4)
Fase 3: Optimalisatie (maanden 5-6)
Fase 4: Strategische integratie (maand 7+)
Deze tijdlijn stelt organisaties in staat binnen 2-3 maanden aanzienlijke AI-zichtbaarheid te bereiken, terwijl ze toewerken naar een uitgebreide, grootschalige infrastructuur voor gestructureerde data. Early adopters die deze roadmap volgen, behalen concurrentievoordeel naarmate AI Overviews de belangrijkste kanalen voor ontdekking worden.
Gestructureerde gegevens zijn geëvolueerd van optionele SEO-verrijking tot essentiële strategische infrastructuur in een door AI gedreven digitaal landschap. Nu AI-systemen steeds vaker bepalen hoe gebruikers informatie vinden, lopen organisaties zonder uitgebreide gestructureerde data-markup structurele zichtbaarheid mis. Deze verschuiving weerspiegelt fundamentele veranderingen in informatiestromen: traditionele zoekopdrachten vereisten dat gebruikers doorklikten naar websites, maar AI Overviews beantwoorden vragen direct, waardoor zichtbaarheid in citaties het nieuwe concurrentieslagveld is.
Organisaties die gestructureerde data strategisch implementeren, positioneren zich voor langdurig succes op meerdere AI-platforms en opkomende kanalen voor ontdekking. De investering in infrastructuur levert meer op dan alleen directe AI-zichtbaarheid—gestructureerde data verbetert intern contentbeheer, maakt betere personalisatie mogelijk, ondersteunt voice search-optimalisatie en creëert data-assets die waardevol zijn voor toekomstige AI-toepassingen. Early adopters die een solide basis voor gestructureerde data leggen, behalen een steeds groter wordend voordeel naarmate AI-systemen steeds sterker de voorkeur geven aan goed gemarkeerde content.
Het concurrentievoordeel van vroege adoptie kan niet worden overschat. Naarmate meer organisaties het belang van gestructureerde gegevens erkennen, wordt implementatie een basisvoorwaarde voor zichtbaarheid. Organisaties die nu een robuuste infrastructuur voor gestructureerde data opzetten, zullen AI-gegenereerde resultaten domineren naarmate deze kanalen volwassen worden. Daarentegen zullen organisaties die implementatie uitstellen het steeds moeilijker krijgen om zichtbaar te zijn omdat AI-systemen leren de voorkeur te geven aan uitgebreid gemarkeerde inhoud. Gestructureerde data is niet slechts een technische implementatie, maar een fundamentele strategische inzet om vindbaar en citeerbaar te blijven in een door AI gemedieerd informatie-ecosysteem.
Gestructureerde gegevens beïnvloeden de Google-rankings niet direct, maar verbeteren de weergave in zoekresultaten aanzienlijk via rich snippets, wat de doorklikratio tot wel 35% verhoogt. Voor AI-systemen hebben gestructureerde gegevens een directer effect op de kans dat uw inhoud wordt geciteerd in AI-gegenereerde antwoorden.
Ja, AI-systemen verwerken gestructureerde gegevens zowel tijdens training als bij realtime zoekopdrachten. Hoewel OpenAI geen publieke uitspraken heeft gedaan, zijn er aanwijzingen dat GPTBot en andere AI-crawlers JSON-LD-markup parseren. Microsoft heeft officieel bevestigd dat de AI-systemen van Bing schema-markup gebruiken om inhoud beter te begrijpen.
JSON-LD is het aanbevolen formaat omdat het het schema scheidt van de HTML-inhoud, wat het eenvoudiger maakt om op grote schaal te implementeren en te onderhouden. Google beveelt JSON-LD expliciet aan en het is minder gevoelig voor implementatiefouten dan Microdata of RDFa.
Rich snippets kunnen binnen 1-4 weken na implementatie verschijnen. Verbeteringen in CTR zijn vaak binnen 2 weken meetbaar. Voor AI-citatieverbeteringen moet u rekenen op 4-8 weken voordat het fundament effect heeft, met voordelen voor autoriteitsopbouw die zich opstapelen over 3-6 maanden.
Geef eerst prioriteit aan schema-markup—dit is bewezen en breed ondersteund. llms.txt is nog een opkomende standaard met beperkte adoptie door AI-crawlers. Bent u een ontwikkelaarsgericht bedrijf met veel documentatie, dan kan de minimale inspanning om llms.txt te maken de moeite waard zijn om toekomstbestendig te zijn.
Begin met Organization-schema op uw homepage (met sameAs-eigenschappen), gevolgd door Article-schema op belangrijke inhoudspagina's. FAQPage-schema moet daarna—dit is het meest direct bruikbaar voor AI-extractie. Daarna voegt u HowTo-schema toe aan handleidingen en SoftwareApplication-schema aan productpagina's.
Alleen onjuist geïmplementeerde markup schaadt de prestaties. De richtlijnen van Google zijn duidelijk: gebruik relevante schema-typen die overeenkomen met zichtbare inhoud, houd prijzen en datums accuraat en markeer geen inhoud die gebruikers niet kunnen zien. Valideer altijd met de Rich Results Test van Google voordat u publiceert.
Gestructureerde gegevens bieden expliciete context die AI-systemen helpt te begrijpen wat informatie vertegenwoordigt—entiteiten, relaties, attributen. Deze duidelijkheid stelt AI in staat uw inhoud met vertrouwen te extraheren en te citeren. LLM's die gebaseerd zijn op kennisgrafen behalen 300% hogere nauwkeurigheid vergeleken met modellen die alleen op ongestructureerde data vertrouwen.
Volg hoe AI-systemen uw inhoud citeren op ChatGPT, Perplexity, Google AI Overviews en andere platforms. Krijg realtime inzicht in uw AI-aanwezigheid.
Gestructureerde gegevens zijn gestandaardiseerde opmaak die zoekmachines helpt om de inhoud van webpagina's te begrijpen. Ontdek hoe JSON-LD, schema.org en micr...

Ontdek hoe vergelijkende contentstructuren informatie optimaliseren voor AI-systemen. Leer waarom AI-platforms de voorkeur geven aan vergelijkingstabellen, matr...
Ontdek hoe AI-crawlers gestructureerde data verwerken. Leer waarom de implementatiemethode van JSON-LD belangrijk is voor zichtbaarheid in ChatGPT, Perplexity, ...