
Grafiek
Leer wat grafieken zijn, hun typen en hoe ze ruwe data omzetten in bruikbare inzichten. Essentiële gids voor gegevensvisualisatieformaten voor analyse en rappor...
8 min lezen
Een tabel is een gestructureerde methode voor het organiseren van gegevens waarbij informatie wordt gerangschikt in een tweedimensionaal raster bestaande uit horizontale rijen en verticale kolommen, wat efficiënte opslag, opvraging en analyse van gegevens mogelijk maakt. Tabellen vormen het fundamentele bouwblok van relationele databases, spreadsheets en systemen voor gegevenspresentatie, waardoor gebruikers snel gerelateerde informatie over meerdere dimensies kunnen vinden en vergelijken.
Een tabel is een gestructureerde methode voor het organiseren van gegevens waarbij informatie wordt gerangschikt in een tweedimensionaal raster bestaande uit horizontale rijen en verticale kolommen, wat efficiënte opslag, opvraging en analyse van gegevens mogelijk maakt. Tabellen vormen het fundamentele bouwblok van relationele databases, spreadsheets en systemen voor gegevenspresentatie, waardoor gebruikers snel gerelateerde informatie over meerdere dimensies kunnen vinden en vergelijken.
Een tabel is een fundamentele datastructuur die informatie organiseert in een tweedimensionaal raster bestaande uit horizontale rijen en verticale kolommen. In zijn meest eenvoudige vorm vertegenwoordigt een tabel een verzameling gerelateerde gegevens die op een gestructureerde manier zijn gerangschikt, waarbij elk kruispunt van een rij en een kolom één gegevensitem of cel bevat. Tabellen vormen de hoeksteen van relationele databases, spreadsheets, datawarehouses en vrijwel elk systeem dat georganiseerde informatieopslag en -opvraging vereist. De kracht van tabellen ligt in hun vermogen om snelle visuele scanning, logische vergelijking van gegevens over meerdere dimensies en programmatische toegang tot specifieke informatie via gestandaardiseerde querytalen mogelijk te maken. Of ze nu worden gebruikt in bedrijfsanalyses, wetenschappelijk onderzoek of AI-monitoringplatforms—tabellen bieden een universeel begrepen formaat voor het presenteren van gestructureerde gegevens die eenvoudig geïnterpreteerd kunnen worden door zowel mensen als machines.
Het concept om informatie te organiseren in rijen en kolommen gaat eeuwen terug, nog vóór de moderne informatica. Oude beschavingen gebruikten tabellaire formaten om voorraden, financiële transacties en astronomische waarnemingen vast te leggen. De formele vastlegging van tabelstructuren in de informatica ontstond echter met de ontwikkeling van de relationele databasetheorie door Edgar F. Codd in 1970, wat een revolutie teweegbracht in de manier waarop gegevens opgeslagen en opgevraagd konden worden. Het relationele model stelde dat gegevens georganiseerd moesten worden in tabellen met duidelijk gedefinieerde relaties, wat de principes van databaseontwerp fundamenteel veranderde. Gedurende de jaren 80 en 90 democratiseerden spreadsheetapplicaties zoals Lotus 1-2-3 en Microsoft Excel het gebruik van tabellen, waardoor tabulaire gegevensorganisatie toegankelijk werd voor niet-technische gebruikers. Tegenwoordig gebruikt ongeveer 97% van de organisaties spreadsheetapplicaties voor gegevensbeheer en -analyse, wat het blijvende belang van op tabellen gebaseerde gegevensorganisatie aantoont. De evolutie zet zich voort met moderne ontwikkelingen in kolomnar databases, NoSQL-systemen en data lakes, die traditionele rij-georiënteerde benaderingen uitdagen, maar nog steeds fundamentele tabelachtige structuren behouden voor het organiseren van informatie.
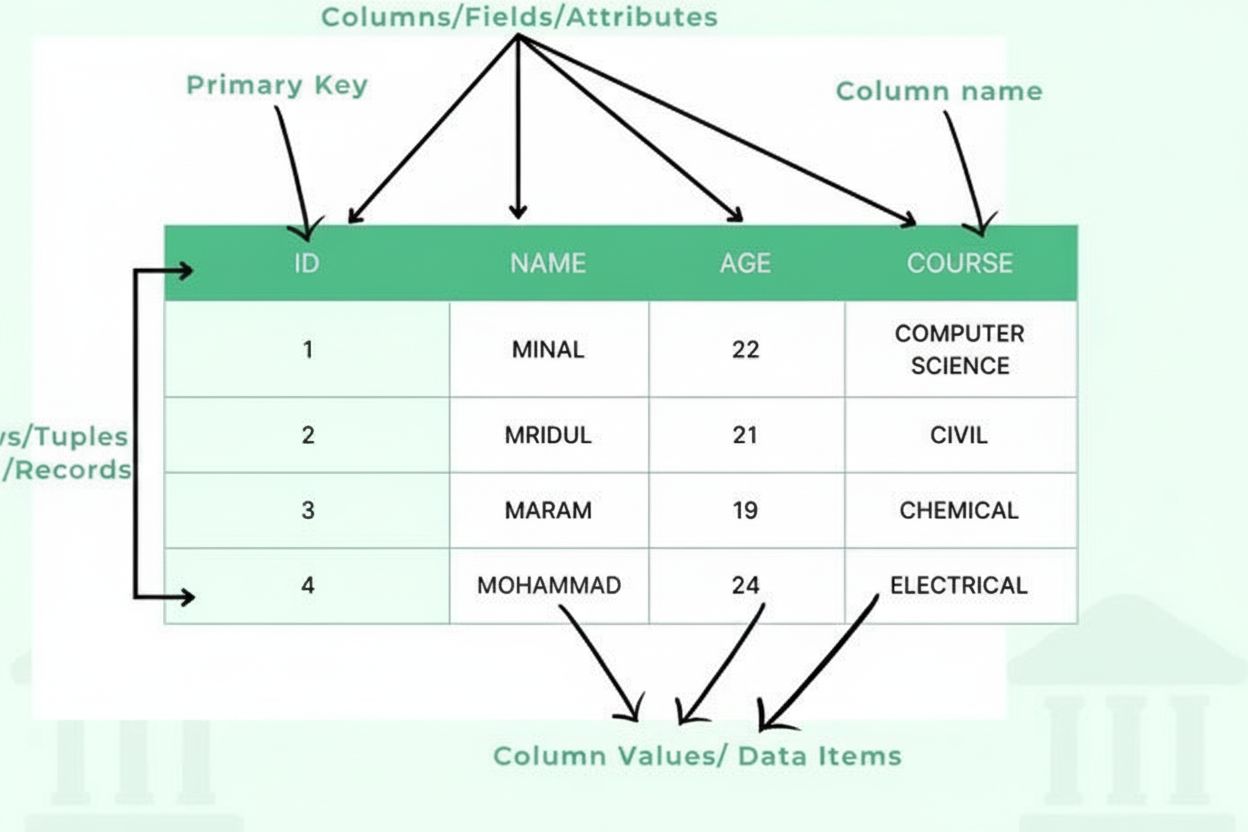
Een tabel bestaat uit verschillende essentiële structurele componenten die samenwerken om een georganiseerd gegevenskader te creëren. Kolommen (ook wel velden of attributen genoemd) lopen verticaal en vertegenwoordigen categorieën van informatie, zoals “Klantnaam”, “E-mailadres” of “Aankoopdatum”. Elke kolom heeft een gedefinieerd gegevenstype dat aangeeft welk soort informatie deze kan bevatten: gehele getallen, tekststrings, datums, decimalen of meer complexe structuren. Rijen (ook wel records of tuples genoemd) lopen horizontaal en vertegenwoordigen individuele gegevensvermeldingen of entiteiten, waarbij elke rij één volledig record bevat. Het kruispunt van een rij en een kolom creëert een cel of gegevensitem dat één enkel gegevenselement bevat. Kolomkoppen identificeren elke kolom en staan bovenaan de tabel, wat context biedt voor de onderliggende gegevens. Primaire sleutels zijn speciale kolommen die elke rij uniek identificeren, zodat er geen dubbele records bestaan. Buitenlandse sleutels leggen relaties tussen tabellen vast door primaire sleutels in andere tabellen te refereren. Deze hiërarchische organisatie stelt databases in staat om gegevensintegriteit te behouden, redundantie te voorkomen en complexe queries te ondersteunen die informatie opvragen op basis van meerdere criteria.
| Aspect | Rij-georiënteerde tabellen | Kolom-georiënteerde tabellen | Hybride benaderingen |
|---|---|---|---|
| Opslagmethode | Gegevens worden per compleet record opgeslagen en benaderd | Gegevens worden per individuele kolom opgeslagen en benaderd | Combineert voordelen van beide benaderingen |
| Queryprestaties | Geoptimaliseerd voor transactionele queries die volledige records ophalen | Geoptimaliseerd voor analytische queries op specifieke kolommen | Gebalanceerde prestaties voor gemengde werklasten |
| Toepassingsgebieden | OLTP (Online Transaction Processing), bedrijfsvoering | OLAP (Online Analytical Processing), datawarehousing | Realtime analytics, operationele intelligentie |
| Databasevoorbeelden | MySQL, PostgreSQL, Oracle, SQL Server | Vertica, Cassandra, HBase, Parquet | Snowflake, BigQuery, Apache Iceberg |
| Compressie-efficiëntie | Lagere compressieratio door gegevensdiversiteit | Hogere compressieratio voor vergelijkbare kolomwaarden | Geoptimaliseerde compressie voor specifieke patronen |
| Schrijfsnelheid | Snelle write-acties voor complete records | Langzamere write-acties doordat kolommen moeten worden bijgewerkt | Gebalanceerde schrijfsnelheid |
| Schaalbaarheid | Schaalbaar voor transactievolume | Schaalbaar voor gegevensvolume en querycomplexiteit | Schaalbaar op beide dimensies |
In relationele databasebeheersystemen (RDBMS) worden tabellen geïmplementeerd als gestructureerde verzamelingen van rijen waarbij elke rij aan een vooraf gedefinieerd schema voldoet. Het schema bepaalt de structuur van de tabel en specificeert kolomnamen, gegevenstypen, beperkingen en relaties. Wanneer gegevens in een tabel worden ingevoerd, controleert het databasebeheersysteem of elke waarde overeenkomt met het gegevenstype van de kolom en voldoet aan eventuele gedefinieerde regels. Een kolom die bijvoorbeeld als INTEGER is gedefinieerd, zal tekstwaarden weigeren, en een kolom met NOT NULL zal lege invoer weigeren. Indexen worden aangemaakt op veelgebruikte kolommen om gegevens sneller op te halen; ze fungeren als georganiseerde verwijzingen waarmee de database specifieke rijen kan vinden zonder de hele tabel te hoeven scannen. Normalisatie is een ontwerpbeginsel dat tabellen organiseert om gegevensredundantie te minimaliseren en de integriteit te verbeteren door informatie op te splitsen in gerelateerde tabellen die via sleutels zijn verbonden. Moderne databases ondersteunen transacties die ervoor zorgen dat meerdere bewerkingen op tabellen allemaal slagen of allemaal mislukken, zodat de consistentie behouden blijft, zelfs bij systeemstoringen. De query-optimizer in database-engines analyseert SQL-queries en bepaalt de meest efficiënte manier om tabelgegevens te benaderen, rekening houdend met beschikbare indexen en tabelstatistieken.
Tabellen vormen het primaire mechanisme voor het presenteren van gestructureerde gegevens aan gebruikers, zowel digitaal als op papier. In business intelligence- en analyseapplicaties tonen tabellen geaggregeerde statistieken, prestatie-indicatoren en gedetailleerde transactierecords, zodat besluitvormers complexe datasets in één oogopslag kunnen begrijpen. Onderzoek toont aan dat 83% van de zakelijke professionals vertrouwt op datatabellen als hun belangrijkste hulpmiddel voor gegevensanalyse, omdat tabellen nauwkeurige waardevergelijking en patroonherkenning mogelijk maken. HTML-tabellen op websites gebruiken semantische markup met <table>, <tr> (tabelrij), <td> (tabelgegevens), en <th> (tabelkop) om gegevens te structureren voor zowel visuele weergave als programmatische interpretatie. Spreadsheetapplicaties zoals Microsoft Excel, Google Sheets en LibreOffice Calc breiden de basisfunctionaliteit van tabellen uit met formules, voorwaardelijke opmaak en draaitabellen waarmee gebruikers berekeningen kunnen uitvoeren en gegevens dynamisch kunnen herstructureren. Best practices voor datavisualisatie bevelen aan tabellen te gebruiken wanneer nauwkeurige waarden belangrijker zijn dan visuele patronen, wanneer meerdere attributen van individuele records moeten worden vergeleken, of wanneer gebruikers opzoekingen of berekeningen moeten uitvoeren. Het W3C Web Accessibility Initiative benadrukt dat correct gestructureerde tabellen met duidelijke koppen en gepaste markup essentieel zijn om gegevens toegankelijk te maken voor gebruikers met een beperking, met name voor degenen die schermlezers gebruiken.
In de context van AI-monitoringplatforms zoals AmICited spelen tabellen een essentiële rol bij het organiseren en presenteren van gegevens over hoe content verschijnt in verschillende AI-systemen. Monitoringtabellen volgen statistieken zoals citatiefrequentie, verschijningsdata, AI-platformbronnen (ChatGPT, Perplexity, Google AI Overviews, Claude) en contextuele informatie over hoe domeinen en URL’s worden vermeld. Deze tabellen stellen organisaties in staat hun merkzichtbaarheid in AI-gegenereerde antwoorden te begrijpen en trends te identificeren in hoe verschillende AI-systemen hun content citeren of vermelden. De gestructureerde aard van monitoringtabellen maakt het mogelijk om citatiedata te filteren, sorteren en aggregeren, waardoor vragen als “Welke van onze URL’s komen het vaakst voor in Perplexity-antwoorden?” of “Hoe is ons citatiepercentage de afgelopen maand veranderd?” eenvoudig beantwoord kunnen worden. Gegevenstabellen in monitoringsystemen maken ook vergelijking over meerdere dimensies mogelijk—zoals het vergelijken van citatiepatronen tussen verschillende AI-platforms, het analyseren van citatiegroei in de tijd, of het identificeren van contenttypes die het meest worden genoemd door AI. De mogelijkheid om monitoringsdata uit tabellen te exporteren naar rapporten, dashboards en verdere analysetools maakt tabellen onmisbaar voor organisaties die inzicht willen krijgen in en optimaliseren van hun aanwezigheid in AI-gegenereerde content.
Effectief tabelontwerp vereist zorgvuldige overweging van structuur, naamgevingsconventies en principes voor gegevensorganisatie. Kolomnamen moeten duidelijke, beschrijvende identificaties zijn die de gegevens die ze bevatten accuraat weergeven, waarbij afkortingen die verwarring kunnen veroorzaken bij gebruikers of ontwikkelaars worden vermeden. Gegevenstypekeuze is cruciaal—het kiezen van geschikte typen voorkomt ongeldige gegevensinvoer en maakt correcte sorteervolgorde en vergelijkingsbewerkingen mogelijk. Definitie van primaire sleutels zorgt ervoor dat elke rij uniek identificeerbaar is, wat essentieel is voor gegevensintegriteit en het leggen van relaties met andere tabellen. Normalisatie vermindert gegevensredundantie door informatie te organiseren in gerelateerde tabellen in plaats van dubbele gegevens op meerdere plekken op te slaan. Indexeringsstrategie moet het evenwicht bewaren tussen queryprestaties en de overhead van het bijhouden van indexen bij gegevenswijzigingen. Documentatie van de tabelstructuur, inclusief kolomdefinities, gegevenstypen, beperkingen en relaties, is essentieel voor langetermijnonderhoudbaarheid. Toegangsbeheer moet worden geïmplementeerd om ervoor te zorgen dat gevoelige gegevens in tabellen beschermd zijn tegen ongeautoriseerde toegang. Prestatieoptimalisatie omvat het monitoren van query-uitvoertijden en het aanpassen van tabelstructuren, indexen of queries om de efficiëntie te verbeteren. Back-up- en herstelprocedures moeten worden opgezet om tabelgegevens te beschermen tegen verlies of beschadiging.
De toekomst van op tabellen gebaseerde gegevensorganisatie ontwikkelt zich om te voldoen aan steeds complexere gegevensvereisten, terwijl de fundamentele principes die tabellen effectief maken behouden blijven. Kolomnar opslagformaten zoals Apache Parquet en ORC worden standaard in big data-omgevingen, waarbij tabellen worden geoptimaliseerd voor analytische werklasten en toch een tabulaire structuur behouden. Semi-gestructureerde gegevens in JSON- en XML-formaten worden steeds vaker binnen tabelkolommen opgeslagen, waardoor tabellen zowel gestructureerde als flexibele gegevens kunnen bevatten. Integratie van machine learning stelt databases in staat automatisch tabelstructuren en query-uitvoering te optimaliseren op basis van gebruikspatronen. Realtime analytics-platforms breiden tabellen uit om streaming data en continue updates te ondersteunen, waarmee ze verder gaan dan traditionele batchgerichte tabeloperaties. Cloud-native databases ontwerpen tabelimplementaties opnieuw om gebruik te maken van gedistribueerde computing, waardoor tabellen kunnen schalen over meerdere servers en geografische regio’s. Data governance-raamwerken leggen meer nadruk op tabelmetadata, lineage-tracking en kwaliteitsstatistieken om de betrouwbaarheid van gegevens te waarborgen. De opkomst van AI-gedreven dataplatforms creëert nieuwe mogelijkheden voor tabellen om als gestructureerde bron voor het trainen van machine learning-modellen te dienen, terwijl het ook vragen oproept over hoe tabellen moeten worden ontworpen om hoogwaardige trainingsgegevens te leveren. Naarmate organisaties exponentieel meer gegevens blijven genereren, blijven tabellen de fundamentele structuur voor het organiseren, opvragen en analyseren van informatie, met innovaties die gericht zijn op het verbeteren van prestaties, schaalbaarheid en integratie met moderne datatechnologieën.
Een rij is een horizontale rangschikking van gegevens die een enkel record of entiteit vertegenwoordigt, terwijl een kolom een verticale rangschikking is die een specifiek attribuut of veld weergeeft dat door alle records wordt gedeeld. In een databasetabel bevat elke rij volledige informatie over één entiteit (zoals een klant), en bevat elke kolom één type informatie (zoals klantnaam of e-mailadres). Samen creëren rijen en kolommen de tweedimensionale structuur die een tabel definieert.
Tabellen vormen de fundamentele organisatorische structuur in relationele databases, waardoor efficiënte opslag, opvraging en bewerking van gegevens mogelijk is. Ze zorgen ervoor dat databases de gegevensintegriteit behouden via gestructureerde schema's, ondersteunen complexe queries over meerdere dimensies en vergemakkelijken relaties tussen verschillende gegevensentiteiten via primaire en buitenlandse sleutels. Tabellen maken het mogelijk miljoenen records te organiseren op een manier die zowel computationeel efficiënt is als logisch zinvol voor bedrijfsvoering.
Een tabel bestaat uit verschillende essentiële onderdelen: kolommen (velden/attributen) die gegevenstypen en categorieën definiëren, rijen (records/tuples) die individuele gegevensvermeldingen bevatten, kopteksten die elke kolom identificeren, gegevensitems (cellen) die de werkelijke waarden opslaan, primaire sleutels die elke rij uniek identificeren en mogelijk buitenlandse sleutels die relaties met andere tabellen tot stand brengen. Elk onderdeel speelt een cruciale rol bij het behouden van de organisatie en integriteit van gegevens.
In AI-monitoringplatforms zoals AmICited zijn tabellen essentieel voor het organiseren en presenteren van gegevens over AI-modelvermeldingen, citaties en merknamen in verschillende AI-systemen. Tabellen stellen monitoringsystemen in staat om gestructureerde gegevens weer te geven over wanneer en waar inhoud verschijnt in AI-antwoorden, waardoor het eenvoudig wordt om statistieken te volgen, prestaties tussen platforms te vergelijken en trends te identificeren in hoe AI-systemen specifieke domeinen en URL's citeren of vermelden.
Rij-georiënteerde databases (zoals traditionele relationele databases) slaan gegevens per compleet record op, wat ze efficiënt maakt voor transacties waarbij alle informatie over één entiteit nodig is. Kolom-georiënteerde databases slaan gegevens per kolom op, waardoor ze sneller zijn voor analytische queries waarbij specifieke attributen over veel records nodig zijn. De keuze tussen deze benaderingen hangt af van of uw primaire gebruikssituatie transactiebewerkingen of analytische queries betreft.
Toegankelijke tabellen vereisen correcte HTML-markup met semantische elementen zoals `
Tabelkolommen kunnen verschillende gegevenstypen opslaan, waaronder gehele getallen, kommagetallen, strings/tekst, datums en tijden, booleans en steeds complexere typen zoals JSON of XML. Elke kolom heeft een gedefinieerd gegevenstype dat bepaalt welke waarden kunnen worden ingevoerd, wat gegevensconsistentie garandeert en correcte sorteervolgorde en vergelijkingsbewerkingen mogelijk maakt. Sommige databases ondersteunen ook gespecialiseerde typen zoals geografische gegevens, arrays of door de gebruiker gedefinieerde typen.
Begin met het volgen van hoe AI-chatbots uw merk vermelden op ChatGPT, Perplexity en andere platforms. Krijg bruikbare inzichten om uw AI-aanwezigheid te verbeteren.
Leer wat grafieken zijn, hun typen en hoe ze ruwe data omzetten in bruikbare inzichten. Essentiële gids voor gegevensvisualisatieformaten voor analyse en rappor...
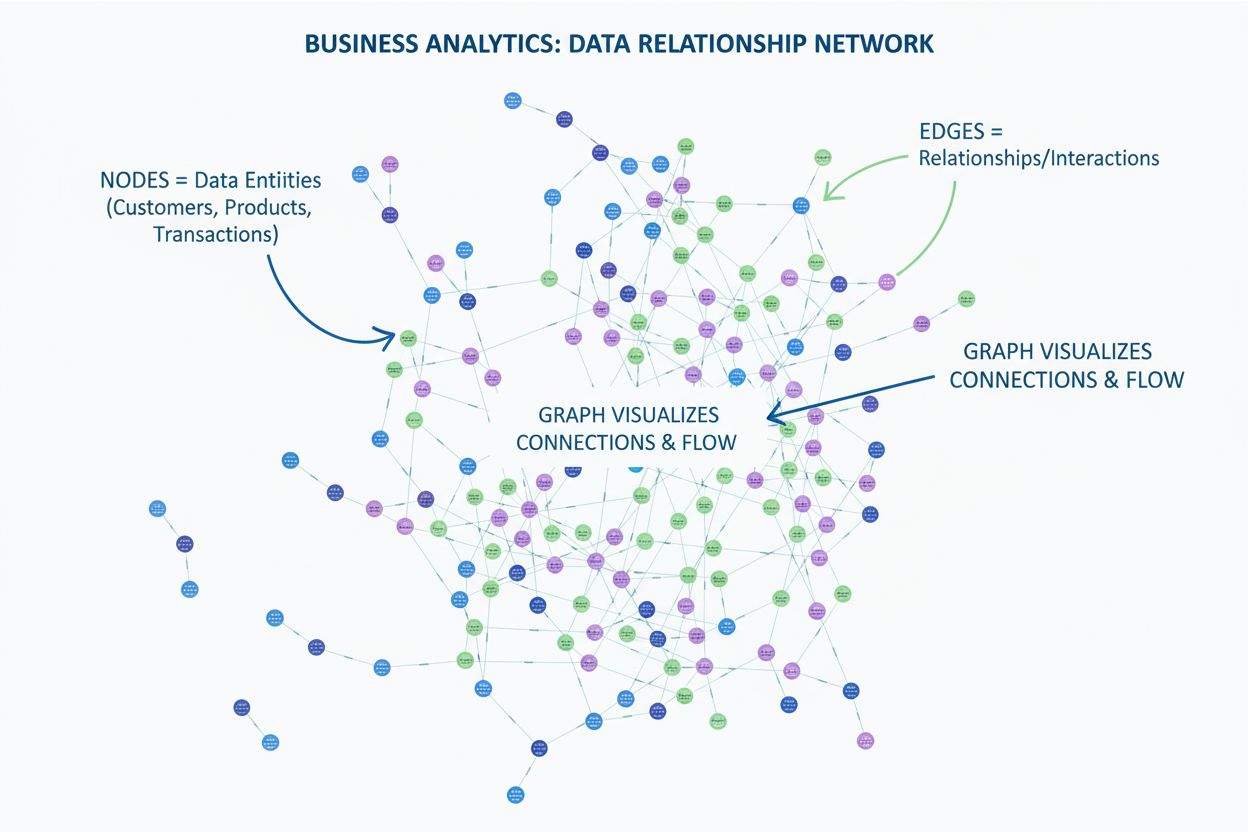
Ontdek wat een grafiek is in datavisualisatie. Ontdek hoe grafieken relaties tussen gegevens weergeven met knooppunten en randen, en waarom ze essentieel zijn v...
Gestructureerde gegevens zijn gestandaardiseerde opmaak die zoekmachines helpt om de inhoud van webpagina's te begrijpen. Ontdek hoe JSON-LD, schema.org en micr...