Fullstendig referanseguide for AI-crawlere og roboter. Identifiser GPTBot, ClaudeBot, Google-Extended og 20+ andre AI-crawlere med brukeragenter, crawl-frekvenser og blokkeringsstrategier.
Publisert den Jan 3, 2026.Sist endret den Jan 3, 2026 kl. 3:24 am
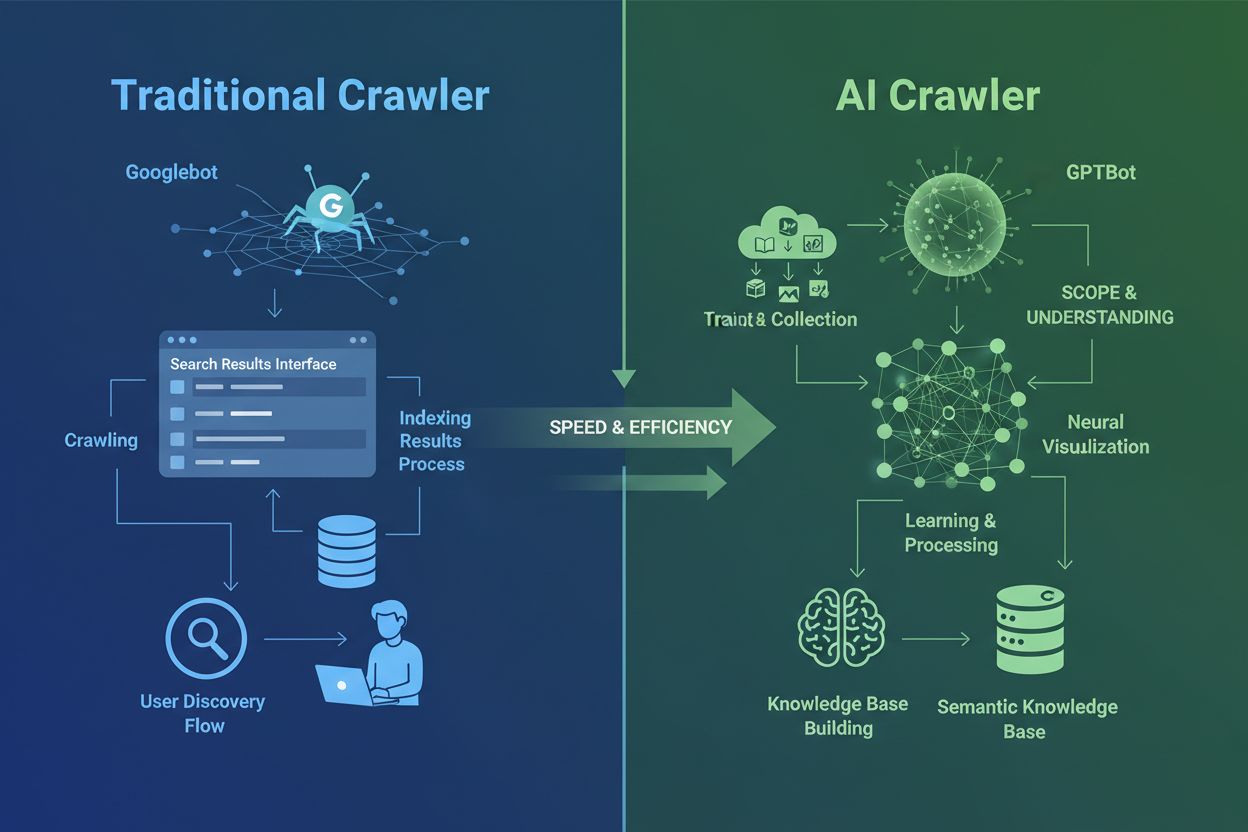
AI-crawlere er fundamentalt forskjellige fra de tradisjonelle søkemotorcrawlerne du har kjent i flere tiår. Mens Googlebot og Bingbot indekserer innhold for å hjelpe brukere å finne informasjon via søkeresultater, samler AI-crawlere som GPTBot og ClaudeBot inn data spesielt for å trene store språkmodeller. Dette skillet er avgjørende: tradisjonelle crawlere skaper veier for menneskelig oppdagelse, mens AI-crawlere mater kunnskapsbasene til kunstige intelligenssystemer. Ifølge nylige data står AI-crawlere nå for nesten 80 % av all bot-trafikk til nettsider, der treningscrawlere forbruker store mengder innhold, men sender minimalt med henvisningstrafikk tilbake til utgivere. I motsetning til tradisjonelle crawlere, som sliter med dynamiske JavaScript-tunge sider, bruker AI-crawlere avansert maskinlæring for å forstå innhold kontekstuelt, omtrent slik en menneskelig leser ville gjort. De kan tolke mening, tone og hensikt uten manuelle konfigurasjonsoppdateringer. Dette representerer et kvantesprang i webindekseringsteknologi og krever at nettstedeiere må revurdere sine strategier for crawlerstyring fullstendig.
Det Store Økosystemet av AI-crawlere
Landskapet for AI-crawlere har blitt stadig mer overfylt etter hvert som store teknologiselskaper konkurrerer om å bygge sine egne store språkmodeller. OpenAI, Anthropic, Google, Meta, Amazon, Apple og Perplexity driver hver flere spesialiserte crawlere med ulike funksjoner i deres respektive AI-økosystemer. Selskapene benytter flere crawlere fordi ulike formål krever ulik atferd: noen crawlere fokuserer på innsamling av store treningsdatasett, andre håndterer sanntids søkeindeksering, og atter andre henter innhold på forespørsel når brukere ber om det. Forståelse av økosystemet krever at du kjenner til tre hovedkategorier av crawlere: treningscrawlere som samler data for modellforbedring, søke- og siteringscrawlere som indekserer innhold for AI-drevne søkeopplevelser, og brukerutløste fetchere som aktiveres når brukere spesifikt ber om innhold via AI-assistenter. Tabellen nedenfor gir en rask oversikt over de viktigste aktørene:
Selskap
Crawler-navn
Hovedformål
Crawl-rate
Treningsdata
OpenAI
GPTBot
Modelltrening
100 sider/time
Ja
OpenAI
ChatGPT-User
Sanntid brukerforespørsler
2400 sider/time
Nei
OpenAI
OAI-SearchBot
Søkeindeksering
150 sider/time
Nei
Anthropic
ClaudeBot
Modelltrening
500 sider/time
Ja
Anthropic
Claude-User
Sanntid nettilgang
<10 sider/time
Nei
Google
Google-Extended
Gemini AI-trening
Variabel
Ja
Google
Gemini-Deep-Research
Forskningsfunksjon
<10 sider/time
Nei
Meta
Meta-ExternalAgent
AI-modelltrening
1100 sider/time
Ja
Amazon
Amazonbot
Tjenesteforbedring
1050 sider/time
Ja
Perplexity
PerplexityBot
Søkeindeksering
150 sider/time
Nei
Apple
Applebot-Extended
AI-trening
<10 sider/time
Ja
Common Crawl
CCBot
Åpent datasett
<10 sider/time
Ja
Ready to Monitor Your AI Visibility?
Track how AI chatbots mention your brand across ChatGPT, Perplexity, and other platforms.
OpenAI opererer tre separate crawlere, hver med spesifikke roller i ChatGPT-økosystemet. Forståelse av disse crawlerne er viktig fordi OpenAI sin GPTBot er en av de mest aggressive og utbredte AI-crawlerne på internett:
GPTBot – OpenAI sin primære treningscrawler som systematisk samler offentlig tilgjengelige data for å trene og forbedre GPT-modellene, inkludert ChatGPT og GPT-4o. Denne crawleren opererer med cirka 100 sider per time og respekterer robots.txt-direktiver. OpenAI publiserer offisielle IP-adresser på https://openai.com/gptbot.json for verifisering.
ChatGPT-User – Denne crawleren vises når en ekte bruker interagerer med ChatGPT og ber den om å besøke en spesifikk nettside. Den opererer med mye høyere hastighet (opptil 2400 sider/time) fordi den utløses av brukerhandlinger fremfor systematisk crawling. Innhold som hentes via ChatGPT-User brukes ikke til modelltrening, noe som gjør det verdifullt for sanntids synlighet i ChatGPT-søkeresultater.
OAI-SearchBot – Designet spesielt for ChatGPTs søkefunksjonalitet, indekserer denne crawleren innhold for sanntids søkeresultater uten å samle treningsdata. Den opererer med ca. 150 sider per time og hjelper innholdet ditt å vises i ChatGPT-søk når brukere stiller relevante spørsmål.
OpenAIs crawlere respekterer robots.txt-direktiver og opererer fra bekreftede IP-intervaller, noe som gjør dem relativt enkle å håndtere sammenlignet med mindre transparente konkurrenter.
Anthropic sine Claude-crawlere
Anthropic, selskapet bak Claude AI, driver flere crawlere med ulike formål og grader av åpenhet. Selskapet har vært mindre åpen om dokumentasjon enn OpenAI, men crawleratferden er godt dokumentert gjennom serverlogganalyse:
ClaudeBot – Anthropics hovedtreningscrawler som samler inn webinnhold for å forbedre Claudes kunnskapsbase og evner. Denne crawleren opererer med ca. 500 sider per time og er hovedmålet dersom du vil hindre innholdet ditt i å bli brukt til Claudes modelltrening. Full brukeragent-streng er Mozilla/5.0 AppleWebKit/537.36 (KHTML, like Gecko; compatible; ClaudeBot/1.0; +claudebot@anthropic.com).
Claude-User – Aktiveres når Claude-brukere ber om sanntidstilgang til nett, og denne crawleren henter innhold på forespørsel med minimal trafikk. Den respekterer autentisering og forsøker ikke å omgå tilgangsbegrensninger, noe som gjør den relativt harmløs med hensyn til ressursbruk.
Claude-SearchBot – Støtter Claudes interne søkemuligheter og hjelper innholdet ditt med å vises i Claudes søkeresultater når brukere spør. Denne crawleren opererer med svært lave volumer og tjener hovedsakelig indekseringsformål heller enn trening.
En kritisk bekymring med Anthropics crawlere er crawl-til-henvisning-forholdet: Cloudflare-data viser at for hver henvisning Anthropic sender tilbake til et nettsted, har crawlerne allerede besøkt omtrent 38 000 til 70 000 sider. Denne store ubalansen betyr at innholdet ditt forbrukes langt mer aggressivt enn det blir sitert, noe som reiser viktige spørsmål om rettferdig kompensasjon for innholdsbruk.
Stay Updated on AI Visibility Trends
Get the latest insights on AI mentions, brand monitoring, and optimization strategies.
Google sine AI-treningscrawlere
Googles tilnærming til AI-crawling skiller seg betydelig fra konkurrentene, fordi selskapet opprettholder et strengt skille mellom søkeindeksering og AI-trening. Google-Extended er den spesifikke crawleren som samler data for å trene Gemini (tidligere Bard) og andre Google AI-produkter, fullstendig adskilt fra tradisjonell Googlebot:
Brukeragent-strengen for Google-Extended er: Mozilla/5.0 AppleWebKit/537.36 (KHTML, like Gecko; compatible; Google-Extended/1.0. Dette skillet er bevisst og gunstig for nettstedeiere fordi du kan blokkere Google-Extended via robots.txt uten at det påvirker synligheten din i Google Search overhodet. Google opplyser offisielt at blokkering av Google-Extended har null innvirkning på søkerangering eller inkludering i AI Overviews, selv om noen webansvarlige har rapportert bekymringer det kan være lurt å følge med på. Gemini-Deep-Research er en annen Google-crawler som støtter Geminis forskningsfunksjon, og opererer med svært lave volumer og minimal påvirkning på serverressurser. En betydelig teknisk fordel med Googles crawlere er deres evne til å kjøre JavaScript og gjengi dynamisk innhold, i motsetning til de fleste konkurrenter. Dette betyr at Google-Extended kan crawle React-, Vue- og Angular-applikasjoner effektivt, mens OpenAIs GPTBot og Anthropics ClaudeBot ikke kan det. For nettstedeiere med JavaScript-tunge applikasjoner, har dette stor betydning for AI-synlighet.
Andre Store AI-crawlere
I tillegg til teknologigigantene opererer flere andre organisasjoner AI-crawlere det er verdt å merke seg. Meta-ExternalAgent, stille lansert i juli 2024, samler nettinnhold for å trene Metas AI-modeller og forbedre produkter på tvers av Facebook, Instagram og WhatsApp. Denne crawleren opererer med omtrent 1100 sider per time og har fått mindre offentlig oppmerksomhet enn konkurrentene til tross for sin aggressive crawlingatferd. Bytespider, drevet av ByteDance (TikToks morselskap), har blitt en av de mest aggressive crawlerne på internett siden lanseringen i april 2024. Tredjepartsanalyse tyder på at Bytespider crawler langt mer aggressivt enn GPTBot eller ClaudeBot, selv om nøyaktige multiplikatorer varierer. Noen rapporter indikerer at den ikke alltid respekterer robots.txt-direktiver, noe som gjør IP-basert blokkering mer pålitelig.
Perplexity sine crawlere inkluderer PerplexityBot for søkeindeksering og Perplexity-User for sanntidshenting av innhold. Perplexity har fått anekdotiske rapporter om å ignorere robots.txt-direktiver, selv om selskapet hevder å følge dem. Amazonbot driver Alexas spørsmålsbesvarende funksjoner og respekterer robots.txt-protokollen, og opererer med cirka 1050 sider per time. Applebot-Extended, introdusert i juni 2024, avgjør hvordan innhold som allerede er indeksert av Applebot, skal brukes til Apples AI-trening, selv om den ikke direkte crawler nettsider. CCBot, drevet av Common Crawl (en ideell organisasjon), bygger åpne nettarkiver som brukes av flere AI-selskaper, inkludert OpenAI, Google, Meta og Hugging Face. Nye crawlere fra selskaper som xAI (Grok), Mistral og DeepSeek begynner å dukke opp i serverlogger, noe som signaliserer fortsatt ekspansjon av AI-crawler-økosystemet.
Fullstendig AI Crawler Referansetabell
Nedenfor er en omfattende referansetabell over verifiserte AI-crawlere, deres formål, brukeragent-strenger og robots.txt-blokkeringssyntaks. Denne tabellen oppdateres regelmessig basert på serverlogganalyse og offisiell dokumentasjon. Hver oppføring er verifisert mot offisielle IP-lister når tilgjengelig:
Crawler-navn
Selskap
Formål
Brukeragent
Crawl-rate
IP-verifisering
Robots.txt-syntaks
GPTBot
OpenAI
Innsamling av treningsdata
Mozilla/5.0 AppleWebKit/537.36 (KHTML, like Gecko; compatible; GPTBot/1.3; +https://openai.com/gptbot)
100/t
✓ Offisiell
User-agent: GPTBot Disallow: /
ChatGPT-User
OpenAI
Sanntid brukerforespørsler
Mozilla/5.0 AppleWebKit/537.36 (KHTML, like Gecko); compatible; ChatGPT-User/1.0
2400/t
✓ Offisiell
User-agent: ChatGPT-User Disallow: /
OAI-SearchBot
OpenAI
Søkeindeksering
Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36; compatible; OAI-SearchBot/1.3
150/t
✓ Offisiell
User-agent: OAI-SearchBot Disallow: /
ClaudeBot
Anthropic
Innsamling av treningsdata
Mozilla/5.0 AppleWebKit/537.36 (KHTML, like Gecko; compatible; ClaudeBot/1.0; +claudebot@anthropic.com)
500/t
✓ Offisiell
User-agent: ClaudeBot Disallow: /
Claude-User
Anthropic
Sanntid nettilgang
Mozilla/5.0 AppleWebKit/537.36 (KHTML, like Gecko; compatible; Claude-User/1.0)
<10/t
✗ Ikke tilgjengelig
User-agent: Claude-User Disallow: /
Claude-SearchBot
Anthropic
Søkeindeksering
Mozilla/5.0 AppleWebKit/537.36 (KHTML, like Gecko; compatible; Claude-SearchBot/1.0)
<10/t
✗ Ikke tilgjengelig
User-agent: Claude-SearchBot Disallow: /
Google-Extended
Google
Gemini AI-trening
Mozilla/5.0 AppleWebKit/537.36 (KHTML, like Gecko; compatible; Google-Extended/1.0)
Variabel
✓ Offisiell
User-agent: Google-Extended Disallow: /
Gemini-Deep-Research
Google
Forskningsfunksjon
Mozilla/5.0 AppleWebKit/537.36 (KHTML, like Gecko; compatible; Gemini-Deep-Research)
<10/t
✓ Offisiell
User-agent: Gemini-Deep-Research Disallow: /
Bingbot
Microsoft
Bing-søk & Copilot
Mozilla/5.0 AppleWebKit/537.36 (KHTML, like Gecko; compatible; bingbot/2.0)
Ikke alle AI-crawlere tjener samme formål, og forståelsen av disse forskjellene er viktig for å ta informerte blokkeringsbeslutninger. Treningscrawlere utgjør omtrent 80 % av all AI-bottrafikk og samler innhold spesielt for å bygge datasett til utvikling av store språkmodeller. Når innholdet ditt først er kommet inn i et treningsdatasett, blir det en permanent del av modellens kunnskapsbase, og dette kan redusere behovet for at brukere besøker nettsiden din for svar. Treningscrawlere som GPTBot, ClaudeBot og Meta-ExternalAgent opererer med høy frekvens og systematiske mønstre, og gir minimalt eller ingen henvisningstrafikk tilbake til utgivere.
Søke- og siteringscrawlere indekserer innhold for AI-drevne søkeopplevelser og kan faktisk sende noe trafikk tilbake til utgiverne gjennom siteringer. Når brukere stiller spørsmål i ChatGPT eller Perplexity, hjelper disse crawlerne til med å finne relevante kilder. I motsetning til treningscrawlere opererer søkecrawlere som OAI-SearchBot og PerplexityBot med moderat volum og henter innhold hovedsakelig for oppslag og kan gi attribusjon og lenker. Brukerutløste fetchere aktiveres kun når brukere spesifikt ber om innhold via AI-assistenter. Når noen limer inn en URL i ChatGPT eller ber Perplexity om å analysere en spesifikk side, henter disse fetcherne innholdet på forespørsel. Brukerutløste fetchere opererer med svært lavt volum med enkeltforespørsler, og de fleste AI-selskaper bekrefter at disse ikke brukes til modelltrening. Å forstå disse kategoriene hjelper deg å ta strategiske valg om hvilke crawlere du vil tillate og hvilke du vil blokkere ut fra dine forretningsprioriteringer.
Hvordan Identifisere Crawlere på Nettstedet Ditt
Første steg i å håndtere AI-crawlere er å forstå hvilke som faktisk besøker nettstedet ditt. Serverens tilgangslogger inneholder detaljerte registreringer av alle forespørsler, inkludert brukeragent-strengen som identifiserer crawleren. De fleste kontrollpaneler på webhotell tilbyr logganalyseverktøy, men du kan også få tilgang til rå logger direkte. For Apache-servere ligger logger vanligvis på /var/log/apache2/access.log, mens Nginx-logger er på /var/log/nginx/access.log. Du kan filtrere disse loggene med grep for å finne crawleraktivitet:
grep -i "gptbot\|claudebot\|google-extended\|bytespider" /var/log/apache2/access.log | head -20
Denne kommandoen viser de 20 siste forespørslene fra store AI-crawlere. Google Search Console gir crawlerstatistikk for Googles roboter, selv om det bare vises Google sine crawlere. Cloudflare Radar gir globale innsikter i AI-bottrafikkmønstre og kan hjelpe deg å identifisere hvilke crawlere som er mest aktive. For å sjekke om en crawler er legitim eller forfalsket, sammenlign forespørsels-IP-adressen med offisielle IP-lister publisert av de store selskapene. OpenAI publiserer bekreftede IP-er på https://openai.com/gptbot.json, Amazon på https://developer.amazon.com/amazonbot/ip-addresses/, og andre har lignende lister. En falsk crawler som forfalsker en legitim brukeragent fra en uverifisert IP-adresse bør blokkeres umiddelbart, da det sannsynligvis er ondsinnet scraping.
Robots.txt Implementeringsguide
Robots.txt-filen er ditt hovedverktøy for å kontrollere crawler-tilgang. Denne enkle tekstfilen, plassert i rotmappen for nettstedet ditt, forteller crawlere hvilke deler av siden de kan få tilgang til. For å blokkere spesifikke AI-crawlere, legg til slike oppføringer:
Dette forteller GPTBot å vente 10 sekunder mellom forespørsler og holde seg unna din private mappe. For en balansert tilnærming som tillater søkecrawlere, men blokkerer treningscrawlere:
De fleste anerkjente AI-crawlere respekterer robots.txt-direktiver, selv om noen aggressive crawlere ignorerer dem fullstendig. Derfor er robots.txt alene utilstrekkelig for full beskyttelse.
Avanserte Blokkeringsstrategier
Robots.txt er rådgivende og ikke håndhevbar, noe som betyr at crawlere kan ignorere direktivene hvis de vil. For sterkere beskyttelse mot crawlere som ikke respekterer robots.txt, implementer IP-basert blokkering på servernivå. Denne tilnærmingen er mer pålitelig fordi det er vanskeligere å forfalske en IP-adresse enn en brukeragentstreng. Du kan hviteliste bekreftede IP-er fra offisielle kilder og blokkere alle andre forespørsler som hevder å være AI-crawlere.
For Apache-servere kan du bruke .htaccess-regler for å blokkere crawlere på servernivå:
Dette gir et 403 Forbidden-svar til matchende brukeragenter, uavhengig av robots.txt-innstillinger. Brannmurregler gir et annet lag med beskyttelse ved å hviteliste bekreftede IP-intervaller fra offisielle kilder. De fleste webapplikasjonsbrannmurer og hosting-leverandører lar deg lage regler som tillater forespørsler fra verifiserte IP-er og blokkerer andre som hevder å være AI-crawlere. HTML meta-tags gir granulær sidekontroll. Amazon og noen andre crawlere respekterer noarchive-direktivet:
<metaname="robots"content="noarchive">
Dette forteller crawlere å ikke bruke siden til modelltrening, samtidig som annen indeksering kan tillates. Velg blokkeringsmetode basert på dine tekniske forutsetninger og hvilke crawlere du ønsker å målrette. IP-basert blokkering er mest pålitelig, men krever mer teknisk oppsett, mens robots.txt er lettest å implementere, men mindre effektiv mot ikke-kompatible crawlere.
Overvåking og Verifikasjon
Å implementere crawler-blokkering er bare halve jobben – du må verifisere at de faktisk fungerer. Regelmessig overvåking hjelper deg å oppdage problemer tidlig og identifisere nye crawlere du ikke har sett før. Sjekk serverloggene dine ukentlig for uvanlig botaktivitet, og se etter brukeragent-strenger som inneholder “bot”, “crawler”, “spider” eller firmanavn som “GPT”, “Claude” eller “Perplexity”. Sett opp varsler for plutselige økninger i bottrafikk som kan indikere nye crawlere eller aggressiv atferd fra eksisterende. Google Search Console viser crawlstatistikk for Googles roboter, og hjelper deg å overvåke Googlebot- og Google-Extended-aktivitet. Cloudflare Radar gir globale innsikter i AI-crawler-trafikkmønstre og kan hjelpe med å identifisere nye crawlere på nettstedet ditt.
For å verifisere at robots.txt-blokkeringene virker, gå til robots.txt-filen din direkte på dittnettsted.com/robots.txt og kontroller at alle brukeragenter og direktiver vises riktig. For blokkeringer på servernivå, overvåk tilgangsloggene dine for forespørsler fra blokkerte crawlere. Hvis du ser forespørsler fra crawlere du har blokkert, ignorerer de enten direktivene dine eller forfalsker brukeragenten. Test implementeringen din ved å sjekke crawler-tilgang i analyseverktøy og serverlogger. Kvartalsvise gjennomganger er essensielt fordi AI-crawler-landskapet endres raskt. Nye crawlere dukker opp jevnlig, eksisterende crawlere oppdaterer brukeragentene sine, og selskaper introduserer nye roboter uten forvarsel. Sett av tid til regelmessige gjennomganger av blokklisten for å fange opp nyheter og sikre at implementeringen er oppdatert.
Spor AI-siteringer med AmICited.com
Selv om det er viktig å håndtere crawler-tilgang, er det like viktig å forstå hvordan AI-systemer faktisk siterer og refererer til innholdet ditt. AmICited.com gir omfattende overvåking av hvordan merkevaren og innholdet ditt dukker opp i AI-genererte svar på ChatGPT, Perplexity, Google Gemini og andre AI-plattformer. I stedet for bare å blokkere crawlere hjelper AmICited.com deg med å forstå den reelle effekten AI-crawlere har på synligheten og autoriteten din. Plattformen sporer hvilke AI-systemer som siterer innholdet ditt, hvor ofte merkevaren din dukker opp i AI-svar, og hvordan denne synligheten oversettes til trafikk og autoritet. Ved å overvåke AI-siteringer kan du ta informerte valg om hvilke crawlere du vil tillate basert på faktisk synlighetsdata, ikke antakelser. AmICited.com integreres med din overordnede innholdsstrategi og viser deg hvilke temaer og innholdstyper som genererer flest AI-siteringer. Denne datadrevne tilnærmingen hjelper deg å optimalisere innholdet ditt for AI-oppdagelse samtidig som du beskytter dine mest verdifulle immaterielle rettigheter. Å forstå
Vanlige spørsmål
Hva er forskjellen mellom AI-crawlere og søkemotorcrawlere?
AI-crawlere som GPTBot og ClaudeBot samler innhold spesielt for å trene store språkmodeller, mens søkemotorcrawlere som Googlebot indekserer innhold slik at folk kan finne det via søkeresultater. AI-crawlere mater kunnskapsbasene til AI-systemer, mens søkecrawlere hjelper brukere med å oppdage innholdet ditt. Den viktigste forskjellen er formålet: trening versus gjenfinning.
Vil blokkering av AI-crawlere skade rangeringen min i søkemotorer?
Nei, blokkering av AI-crawlere vil ikke skade tradisjonelle søkerangeringer. AI-crawlere som GPTBot og ClaudeBot er fullstendig adskilt fra søkemotorcrawlere som Googlebot. Du kan blokkere Google-Extended (for AI-trening) og likevel tillate Googlebot (for søk). Hver crawler har sitt eget formål, og blokkering av én påvirker ikke de andre.
Hvordan vet jeg hvilke AI-crawlere som besøker nettsiden min?
Sjekk serverens tilgangslogger for å se hvilke brukeragenter som besøker siden din. Se etter bot-navn som GPTBot, ClaudeBot, CCBot og Bytespider i brukeragent-strengene. De fleste kontrollpaneler for webhotell tilbyr verktøy for logganalyse. Du kan også bruke Google Search Console for å overvåke crawl-aktivitet, men den viser kun Googles crawlere.
Følger alle AI-crawlere robots.txt-direktiver?
Ikke alle AI-crawlere respekterer robots.txt like mye. OpenAI's GPTBot, Anthropic's ClaudeBot og Google-Extended følger vanligvis robots.txt-regler. Bytespider og PerplexityBot har fått rapporter som antyder at de kanskje ikke alltid respekterer robots.txt-direktiver. For crawlere som ikke følger robots.txt, må du implementere IP-basert blokkering på servernivå via brannmur eller .htaccess-fil.
Bør jeg blokkere alle AI-crawlere eller bare treningscrawlere?
Avgjørelsen avhenger av dine mål. Blokker treningscrawlere hvis du har proprietært innhold eller begrensede serverressurser. Tillat søkecrawlere hvis du ønsker synlighet i AI-drevne søkeresultater og chatboter, som kan generere trafikk og etablere autoritet. Mange virksomheter velger en selektiv tilnærming der de tillater spesifikke crawlere og blokkerer aggressive som Bytespider.
Hvor ofte bør jeg oppdatere blokkeringslisten min for AI-crawlere?
Nye AI-crawlere dukker opp jevnlig, så gå gjennom og oppdater blokklisten minst kvartalsvis. Følg ressurser som ai.robots.txt-prosjektet på GitHub for fellesskapsvedlikeholdte lister. Sjekk serverlogger månedlig for å identifisere nye crawlere som besøker siden din og som ikke er i nåværende konfigurasjon. Landskapet for AI-crawlere utvikler seg raskt, og strategien din bør utvikles i takt med det.
Kan jeg verifisere om en crawler er legitim eller forfalsket?
Ja, sjekk forespørsels-IP-adressen mot offisielle IP-lister publisert av de store selskapene. OpenAI publiserer verifiserte IP-er på https://openai.com/gptbot.json, Amazon på https://developer.amazon.com/amazonbot/ip-addresses/, og andre har lignende lister. En crawler som forfalsker en legitim brukeragent fra en uverifisert IP-adresse bør blokkeres umiddelbart, da det sannsynligvis dreier seg om ondsinnet scraping.
Hva er virkningen av AI-crawlere på ytelsen til nettsiden min?
AI-crawlere kan bruke betydelig båndbredde og serverressurser. Bytespider og Meta-ExternalAgent er blant de mest aggressive crawlerne. Noen utgivere har rapportert at de har redusert båndbreddeforbruket fra 800 GB til 200 GB daglig ved å blokkere AI-crawlere, og sparer omtrent 15 000 kr per måned. Overvåk serverressursene dine under perioder med mye crawling og innfør raterestriksjoner for aggressive roboter om nødvendig.
Ta Kontroll Over Din AI-synlighet
Følg med på hvilke AI-crawlere som siterer innholdet ditt og optimaliser synligheten din på ChatGPT, Perplexity, Google Gemini og flere.
Slik lar du AI-boter crawle nettstedet ditt: Komplett robots.txt- og llms.txt-guide
Lær hvordan du lar AI-boter som GPTBot, PerplexityBot og ClaudeBot crawle nettstedet ditt. Konfigurer robots.txt, sett opp llms.txt, og optimaliser for AI-synli...
Bør du blokkere eller tillate AI-crawlere? Beslutningsrammeverk
Lær hvordan du tar strategiske beslutninger om blokkering av AI-crawlere. Vurder innholdstype, trafikkilder, inntektsmodeller og konkurranseposisjon med vårt om...
Hvilke AI-crawlere bør jeg gi tilgang? Komplett guide for 2025
Lær hvilke AI-crawlere du bør tillate eller blokkere i robots.txt-filen din. Omfattende guide som dekker GPTBot, ClaudeBot, PerplexityBot og 25+ AI-crawlere med...
10 min lesing
Informasjonskapselsamtykke Vi bruker informasjonskapsler for å forbedre din surfeopplevelse og analysere vår trafikk. See our privacy policy.