
Bør du blokkere eller tillate AI-crawlere? Beslutningsrammeverk
Lær hvordan du tar strategiske beslutninger om blokkering av AI-crawlere. Vurder innholdstype, trafikkilder, inntektsmodeller og konkurranseposisjon med vårt om...
11 min lesing
Lær hvordan du implementerer selektiv blokkering av AI-crawlere for å beskytte innholdet ditt mot treningsroboter, samtidig som du opprettholder synlighet i AI-søkeresultater. Tekniske strategier for utgivere.
Utgivere står i dag overfor et umulig valg: blokkér alle AI-crawlere og mist verdifull søkemotortrafikk, eller tillat dem alle og se innholdet ditt brukes til treningsdatasett uten kompensasjon. Fremveksten av generativ AI har skapt et todelt crawler-økosystem der samme robots.txt-regler brukes ukritisk både for søkemotorer som gir inntekter og treningscrawlere som bare trekker verdi ut. Dette paradokset har tvunget fremoverlente utgivere til å utvikle selektive strategier for crawlere som skiller mellom ulike typer AI-roboter basert på deres faktiske innvirkning på forretningsmessige måltall.
AI-crawlerlandskapet deles inn i to distinkte kategorier med svært ulike formål og forretningsmessige konsekvenser. Treningscrawlere – drevet av selskaper som OpenAI, Anthropic og Google – er laget for å hente inn store mengder tekstdata for å bygge og forbedre store språkmodeller, mens søkecrawlere indekserer innhold for gjenfinning og oppdagelse. Treningsroboter står for omtrent 80 % av all AI-relatert botaktivitet, men de gir ingen direkte inntekter for utgivere, mens søkecrawlere som Googlebot og Bingbot driver millioner av besøk og annonsevisninger årlig. Skillet er viktig fordi en enkelt treningscrawler kan bruke båndbredde tilsvarende tusenvis av menneskelige brukere, mens søkecrawlere er optimalisert for effektivitet og vanligvis respekterer fartgrenser.
| Bot-navn | Operatør | Hovedformål | Trafikkpotensial |
|---|---|---|---|
| GPTBot | OpenAI | Modelltrening | Ingen (datauttrekk) |
| Claude Web Crawler | Anthropic | Modelltrening | Ingen (datauttrekk) |
| Googlebot | Søkeindeksering | 243,8M besøk (april 2025) | |
| Bingbot | Microsoft | Søkeindeksering | 45,2M besøk (april 2025) |
| Perplexity Bot | Perplexity AI | Søk + trening | 12,1M besøk (april 2025) |
Tallene er tydelige: ChatGPTs crawler alene sendte 243,8 millioner besøk til utgivere i april 2025, men disse besøkene genererte null klikk, null annonsevisninger og ingen inntekter. Samtidig ble Googlebots trafikk omgjort til faktisk brukerengasjement og inntektsmuligheter. Å forstå dette skillet er første steg mot å implementere en selektiv blokkeringsstrategi som beskytter innholdet ditt samtidig som du bevarer søkesynligheten.
Generell blokkering av alle AI-crawlere er økonomisk selvdestruktivt for de fleste utgivere. Mens treningscrawlere trekker verdi ut uten kompensasjon, er søkecrawlere fortsatt en av de mest pålitelige trafikkildene i et stadig mer fragmentert digitalt landskap. Det økonomiske grunnlaget for selektiv blokkering bygger på flere viktige faktorer:
Utgivere som implementerer selektive blokkeringsstrategier rapporterer at de opprettholder eller forbedrer søketrafikken samtidig som uautorisert innholdsuttrekk reduseres med opptil 85 %. Den strategiske tilnærmingen anerkjenner at ikke alle AI-crawlere er like, og at en nyansert policy tjener forretningsinteressene langt bedre enn en brent-jord-tilnærming.
Robots.txt-filen forblir det primære verktøyet for å kommunisere tillatelser til crawlere, og den kan faktisk skille mellom ulike bot-typer når den er riktig konfigurert. Denne enkle tekstfilen, plassert i rotmappen på nettstedet ditt, bruker user-agent-direktiver for å spesifisere hvilke crawlere som får tilgang til hvilket innhold. For selektiv AI-crawlerkontroll kan du tillate søkemotorer samtidig som du blokkerer treningscrawlere med kirurgisk presisjon.
Her er et praktisk eksempel som blokkerer treningscrawlere og tillater søkemotorer:
# Blokker OpenAIs GPTBot
User-agent: GPTBot
Disallow: /
# Blokker Anthropics Claude crawler
User-agent: Claude-Web
Disallow: /
# Blokker andre treningscrawlere
User-agent: CCBot
Disallow: /
User-agent: anthropic-ai
Disallow: /
# Tillat søkemotorer
User-agent: Googlebot
Allow: /
User-agent: Bingbot
Allow: /
User-agent: *
Disallow: /admin/
Disallow: /private/
Denne tilnærmingen gir tydelige instrukser til veldisiplinerte crawlere, samtidig som nettstedet ditt forblir synlig i søk. Likevel er robots.txt i utgangspunktet en frivillig standard – den er avhengig av at crawleroperatører respekterer direktivene dine. For utgivere som er opptatt av etterlevelse, trengs det ytterligere håndhevelseslag.
Robots.txt alene kan ikke garantere etterlevelse, fordi omtrent 13 % av AI-crawlere ignorerer robots.txt-direktiver fullstendig – enten på grunn av uaktsomhet eller med vilje. Håndheving på servernivå via webserveren eller applikasjonslaget gir en teknisk barriere som hindrer uautorisert tilgang uansett crawleratferd. Denne tilnærmingen blokkerer forespørsler på HTTP-nivå før de bruker betydelig båndbredde eller ressurser.
Implementering av blokkering på servernivå med Nginx er enkelt og svært effektivt:
# I din Nginx server-blokk
location / {
# Blokker treningscrawlere på servernivå
if ($http_user_agent ~* (GPTBot|Claude-Web|CCBot|anthropic-ai|Omgili)) {
return 403;
}
# Blokker etter IP-områder om nødvendig (for crawlere som forfalsker user agents)
if ($remote_addr ~* "^(192\.0\.2\.|198\.51\.100\.)") {
return 403;
}
# Fortsett normal forespørselshåndtering
proxy_pass http://backend;
}
Denne konfigurasjonen returnerer en 403 Forbidden-respons til blokkerte crawlere, og bruker minimale serverressurser samtidig som den tydelig signaliserer at tilgang er nektet. Kombinert med robots.txt skaper håndheving på servernivå et to-lags forsvar som stopper både kompatible og ikke-kompatible crawlere. 13 %-andelen som omgår robots.txt faller til nær null når slike regler er riktig implementert.
Content Delivery Networks og Web Application Firewalls gir et ekstra håndhevelsesnivå som aktiveres før forespørsler når opprinnelsesserveren din. Tjenester som Cloudflare, Akamai og AWS WAF lar deg lage regler som blokkerer spesifikke user agents eller IP-områder i kanten, og hindrer uønskede crawlere i å bruke infrastrukturressurser. Disse tjenestene vedlikeholder oppdaterte lister over kjente IP-områder og user agents for treningscrawlere, og blokkerer dem automatisk uten manuell konfigurering.
Kontroll på CDN-nivå gir flere fordeler over servernivå: de reduserer belastning på opprinnelsesserveren, gir mulighet for geografisk blokkering og tilbyr sanntidsanalyse av blokkerte forespørsler. Mange CDN-leverandører tilbyr nå AI-spesifikke blokkeringsregler som standard, i erkjennelse av bekymringen for uautorisert datainnhenting. For utgivere som bruker Cloudflare, gir aktivering av “Block AI Crawlers” i sikkerhetsinnstillingene ett-klikks beskyttelse mot store treningscrawlere, samtidig som søkemotorer får tilgang.
Effektiv selektiv blokkering krever en systematisk tilnærming til klassifisering av crawlere basert på forretningsmessig verdi og pålitelighet. I stedet for å behandle alle AI-crawlere likt, bør utgivere bruke en tre-nivå ramme som reflekterer den faktiske verdien og risikoen hver crawler utgjør. Dette muliggjør nyanserte beslutninger som balanserer innholdsbeskyttelse mot forretningsmuligheter.
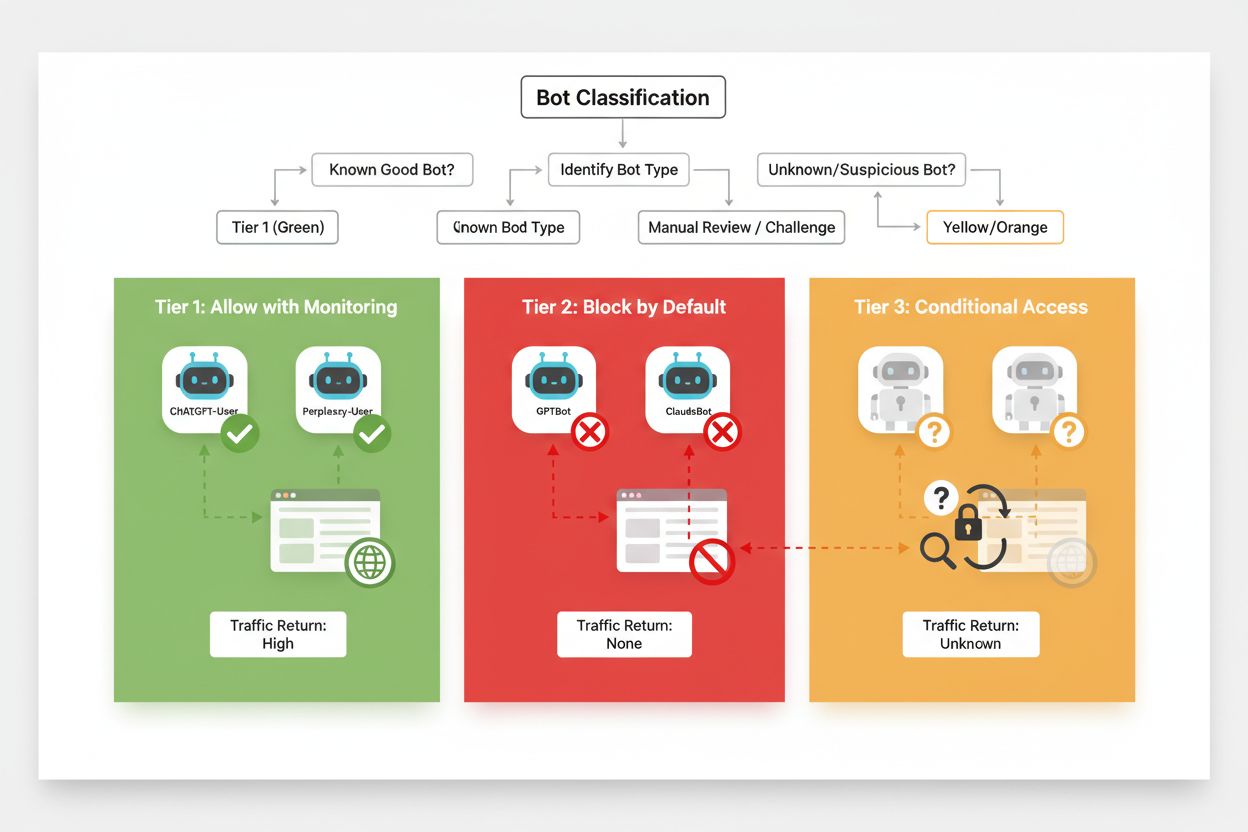
| Nivå | Klassifisering | Eksempler | Tiltak |
|---|---|---|---|
| Nivå 1: Inntektsgeneratorer | Søkemotorer og høytrafikkerte henvisningskilder | Googlebot, Bingbot, Perplexity Bot | Tillat full tilgang; optimaliser for crawling |
| Nivå 2: Nøytral/Uprøvd | Nye eller fremvoksende crawlere med uklar hensikt | Mindre AI-startups, forskningsroboter | Overvåk nøye; tillat med fartsgrenser |
| Nivå 3: Verdiekstraktører | Treningscrawlere uten direkte fordel | GPTBot, Claude-Web, CCBot | Blokker fullstendig; håndhev på flere nivåer |
Implementering av denne rammen krever kontinuerlig research på nye crawlere og deres forretningsmodeller. Utgivere bør regelmessig revidere tilgangslogger for å identifisere nye roboter, undersøke operatørenes bruksvilkår og kompensasjonsordninger, og justere klassifiseringen deretter. En crawler som starter som Nivå 3 kan flyttes til Nivå 2 hvis operatøren tilbyr inntektsdeling, mens en tidligere pålitelig crawler kan falle til Nivå 3 om den bryter fartsgrenser eller robots.txt.
Selektiv blokkering er ikke en konfigurasjon du kan glemme – den krever løpende overvåking og justering ettersom crawler-landskapet utvikler seg. Utgivere bør implementere omfattende logging og analyser for å spore hvilke crawlere som får tilgang til innholdet, hvor mye båndbredde de bruker, og om de respekterer oppsatte restriksjoner. Disse dataene gir grunnlag for strategiske beslutninger om hvilke crawlere man skal tillate, blokkere eller fartsbegrense.
Analyse av tilgangsloggene dine avslører crawler-atferd som gir grunnlag for policyendringer:
# Identifiser alle AI-crawlere som besøker nettstedet ditt
grep -i "bot\|crawler" /var/log/nginx/access.log | \
awk '{print $12}' | sort | uniq -c | sort -rn | head -20
# Beregn båndbredde brukt av spesifikke crawlere
grep "GPTBot" /var/log/nginx/access.log | \
awk '{sum+=$10} END {print "GPTBot båndbredde: " sum/1024/1024 " MB"}'
# Overvåk 403-responser til blokkerte crawlere
grep " 403 " /var/log/nginx/access.log | grep -i "bot" | wc -l
Regelmessig analyse av disse dataene – helst ukentlig eller månedlig – avslører om blokkeringsstrategien fungerer som tiltenkt, om nye crawlere har dukket opp, og om tidligere blokkerte crawlere har endret atferd. Denne informasjonen mates tilbake inn i klassifiseringsrammen, slik at policyen forblir tilpasset forretningsmål og teknisk virkelighet.
Utgivere som innfører selektiv blokkering av crawlere gjør ofte feil som undergraver strategien eller gir utilsiktede konsekvenser. Å kjenne til disse fallgruvene hjelper deg å unngå kostbare feil og implementere en mer effektiv policy fra starten av.
Fremtiden for forholdet mellom utgiver og AI-crawlere vil sannsynligvis innebære mer avanserte forhandlinger og kompensasjonsmodeller i stedet for enkel blokkering. Inntil bransjestandarder etableres, forblir selektiv crawlerkontroll den mest praktiske tilnærmingen for å beskytte innholdet og opprettholde søkesynlighet. Utgivere bør se på blokkeringsstrategien sin som en dynamisk policy som utvikles i takt med crawler-økosystemet, og regelmessig vurdere hvilke crawlere som fortjener tilgang basert på forretningsverdi og tillit.
De mest suksessrike utgiverne er de som implementerer lagdelte forsvar – og kombinerer robots.txt-direktiver, håndheving på servernivå, CDN-kontroller og løpende overvåking i en helhetlig strategi. Denne tilnærmingen beskytter mot både kompatible og ikke-kompatible crawlere, samtidig som søkemotortrafikken som gir inntekt og brukerengasjement bevares. Etter hvert som AI-selskapene i økende grad anerkjenner verdien av utgiverinnhold og begynner å tilby kompensasjon eller lisensieringsavtaler, vil rammene du bygger i dag enkelt kunne tilpasses nye forretningsmodeller og samtidig bevare kontrollen over dine digitale eiendeler.
Treningscrawlere som GPTBot og ClaudeBot samler data for å bygge AI-modeller uten å returnere trafikk til nettstedet ditt. Søkecrawlere som OAI-SearchBot og PerplexityBot indekserer innhold for AI-søkemotorer og kan generere betydelig henvisningstrafikk tilbake til nettstedet ditt. Å forstå dette skillet er avgjørende for å implementere en effektiv selektiv blokkeringsstrategi.
Ja, dette er kjernestrategien for selektiv kontroll av crawlere. Du kan bruke robots.txt for å nekte tilgang for treningsroboter, men tillate søkeroboter, og deretter håndheve dette med server-nivå kontroll for roboter som ignorerer robots.txt. Denne tilnærmingen beskytter innholdet ditt mot uautorisert trening, samtidig som du opprettholder synlighet i AI-søkeresultater.
De fleste store AI-selskaper hevder å respektere robots.txt, men overholdelse er frivillig. Forskning viser at omtrent 13 % av AI-robotene ignorerer robots.txt-direktiver fullstendig. Derfor er håndhevelse på servernivå avgjørende for utgivere som er seriøse med å beskytte innholdet sitt mot ikke-kompatible crawlere.
Betydelig og økende. ChatGPT sendte 243,8 millioner besøk til 250 nyhets- og medienettsteder i april 2025, opp 98 % fra januar. Å blokkere disse crawlerne betyr å miste denne nye trafikkilden. For mange utgivere utgjør AI-søk nå 5-15 % av den totale henvisningstrafikken.
Analyser serverloggene dine regelmessig ved hjelp av grep-kommandoer for å identifisere brukeragenter til roboter, spore frekvensen av crawling og overvåke om de overholder robots.txt-reglene dine. Gå gjennom loggene minst månedlig for å identifisere nye roboter, uvanlige atferdsmønstre og om blokkerte roboter faktisk holder seg borte. Disse dataene gir grunnlag for strategiske beslutninger om crawler-politikken din.
Du beskytter innholdet ditt mot uautorisert trening, men mister synlighet i AI-søkeresultater, går glipp av nye trafikkilder og reduserer potensielt omtale av merkevaren i AI-genererte svar. Utgivere som innfører generell blokkering opplever ofte 40-60 % reduksjon i søkesynlighet og går glipp av muligheter for merkevareoppdagelse gjennom AI-plattformer.
Minst månedlig, siden nye roboter stadig dukker opp og eksisterende roboter endrer atferd. Landskapet for AI-crawlere endrer seg raskt, med nye aktører som lanserer crawlere og eksisterende som slår seg sammen eller gir robotene nye navn. Regelmessige gjennomganger sikrer at policyen din forblir tilpasset forretningsmål og teknisk virkelighet.
Det er forholdet mellom antall sider crawlet og besøkende sendt tilbake til nettstedet ditt. Anthropic crawler 38 000 sider for hver besøkende som sendes tilbake, mens OpenAI har et forhold på 1 091:1, og Perplexity ligger på 194:1. Lavere forhold indikerer bedre verdi for å tillate crawleren. Denne målingen hjelper deg med å avgjøre hvilke crawlere som fortjener tilgang basert på faktisk forretningsmessig påvirkning.
AmICited sporer hvilke AI-plattformer som siterer din merkevare og ditt innhold. Få innsikt i din AI-synlighet og sikre korrekt attribusjon på tvers av ChatGPT, Perplexity, Google AI Overviews og flere.
Lær hvordan du tar strategiske beslutninger om blokkering av AI-crawlere. Vurder innholdstype, trafikkilder, inntektsmodeller og konkurranseposisjon med vårt om...

Lær hvordan du blokkerer eller tillater AI-crawlere som GPTBot og ClaudeBot ved hjelp av robots.txt, blokkering på servernivå og avanserte beskyttelsesmetoder. ...

Lær hvilke AI-crawlere du bør tillate eller blokkere i robots.txt-filen din. Omfattende guide som dekker GPTBot, ClaudeBot, PerplexityBot og 25+ AI-crawlere med...