
Bør du blokkere eller tillate AI-crawlere? Beslutningsrammeverk
Lær hvordan du tar strategiske beslutninger om blokkering av AI-crawlere. Vurder innholdstype, trafikkilder, inntektsmodeller og konkurranseposisjon med vårt om...
11 min lesing

Omfattende guide til AI-crawlere i 2025. Identifiser GPTBot, ClaudeBot, PerplexityBot og 20+ andre AI-boter. Lær hvordan du blokkerer, tillater eller overvåker crawlere med robots.txt og avanserte teknikker.
AI-crawlere er automatiserte roboter utviklet for systematisk å bla gjennom og samle data fra nettsteder, men formålet deres har fundamentalt endret seg de siste årene. Mens tradisjonelle søkemotorcrawlere som Googlebot fokuserer på å indeksere innhold for søkeresultater, prioriterer moderne AI-crawlere innsamling av treningsdata for store språkmodeller og generative AI-systemer. Ifølge ferske data fra Playwire står AI-crawlere nå for omtrent 80 % av all AI-bottrafikk, noe som representerer en dramatisk økning i volum og mangfold av automatiserte besøkende på nettsteder. Dette skiftet gjenspeiler den bredere transformasjonen i hvordan kunstig intelligens utvikles og trenes, bort fra offentlige datasett og mot sanntidsinnsamling av nettinnhold. Å forstå disse crawlerne har blitt essensielt for nettstedseiere, utgivere og innholdsskapere som må ta informerte valg om sin digitale tilstedeværelse.
AI-crawlere kan klassifiseres i tre distinkte kategorier basert på funksjon, oppførsel og innvirkning på nettstedet ditt. Treningscrawlere utgjør den største delen, omtrent 80 % av AI-bottrafikken, og er utviklet for å samle innhold for å trene maskinlæringsmodeller; disse crawlerne opererer vanligvis med høyt volum og minimal henvisningstrafikk, noe som gjør dem båndbreddekrevende, men lite sannsynlig å drive besøkende tilbake til siden din. Søke- og siteringscrawlere opererer med moderat volum og er spesielt utviklet for å finne og referere til innhold i AI-drevne søkeresultater og applikasjoner; i motsetning til treningscrawlere kan disse botene faktisk sende trafikk til nettstedet ditt når brukere klikker gjennom fra AI-genererte svar. Brukerutløste innhentere utgjør den minste kategorien og opererer på forespørsel når brukere eksplisitt ber om innhenting av innhold via AI-applikasjoner som ChatGPTs nettleserfunksjon; disse crawlerne har lavt volum, men høy relevans for individuelle brukerforespørsler.
| Kategori | Formål | Eksempler |
|---|---|---|
| Treningscrawlere | Samler data for AI-modelltrening | GPTBot, ClaudeBot, Meta-ExternalAgent, Bytespider |
| Søke-/siteringscrawlere | Finner og refererer til innhold i AI-svar | OAI-SearchBot, Claude-SearchBot, PerplexityBot, You.com |
| Brukerutløste innhentere | Henter innhold på forespørsel for brukere | ChatGPT-User, Claude-Web, Gemini-Deep-Research |
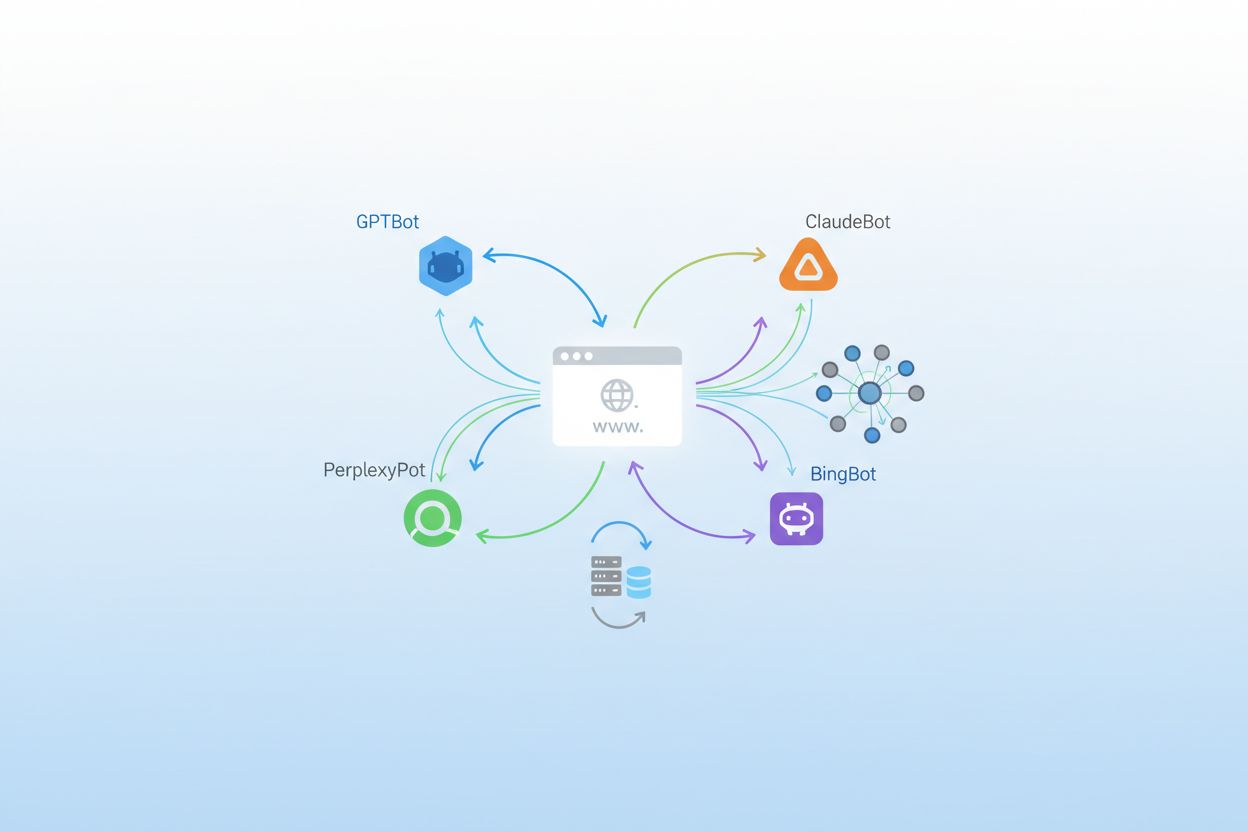
OpenAI opererer det mest mangfoldige og aggressive crawler-økosystemet i AI-landskapet, med flere roboter som tjener ulike formål på tvers av produktsuiten. GPTBot er deres primære treningscrawler, ansvarlig for å samle innhold for å forbedre GPT-4 og fremtidige modeller, og har opplevd en svimlende 305 % vekst i crawlertrafikk ifølge Cloudflare-data; denne boten opererer med et 400:1-forhold mellom innhenting og henvisning, noe som betyr at den laster ned innhold 400 ganger for hver besøkende den sender tilbake til nettstedet ditt. OAI-SearchBot har en helt annen funksjon, med fokus på å finne og sitere innhold for ChatGPTs søkefunksjon uten å bruke innholdet til modelltrening. ChatGPT-User representerer den mest eksplosive vekstkategorien, med en bemerkelsesverdig 2 825 % økning i trafikk, og opererer hver gang brukere aktiverer “Browse with Bing”-funksjonen for å hente sanntidsinnhold på forespørsel. Du kan identifisere disse crawlerne ved deres user-agent-strenger: GPTBot/1.0, OAI-SearchBot/1.0 og ChatGPT-User/1.0, og OpenAI tilbyr IP-verifiseringsmetoder for å bekrefte legitim crawlertrafikk fra deres infrastruktur.
Anthropic, selskapet bak Claude, driver en av de mest selektive, men intensive crawler-operasjonene i bransjen. ClaudeBot er deres primære treningscrawler og opererer med et ekstraordinært 38 000:1-forhold mellom innhenting og henvisning, noe som betyr at den laster ned innhold langt mer aggressivt enn OpenAIs roboter i forhold til trafikken som sendes tilbake; dette ekstreme forholdet gjenspeiler Anthropics fokus på omfattende datainnsamling for modelltrening. Claude-Web og Claude-SearchBot har ulike formål, hvor førstnevnte håndterer brukerutløst innhenting av innhold og sistnevnte fokuserer på søke- og siteringsfunksjonalitet. Google har tilpasset sin crawlerstrategi for AI-tiden ved å introdusere Google-Extended, et spesielt token som lar nettsteder velge å delta i AI-trening samtidig som de blokkerer tradisjonell Googlebot-indeksering, samt Gemini-Deep-Research, som utfører dyptgående forskningsforespørsler for brukere av Googles AI-produkter. Mange nettstedseiere diskuterer om de skal blokkere Google-Extended siden den kommer fra samme selskap som kontrollerer søketrafikk, noe som gjør avgjørelsen mer kompleks enn med tredjeparts AI-crawlere.
Meta har blitt en betydelig aktør i AI-crawlerrommet med Meta-ExternalAgent, som står for omtrent 19 % av AI-crawlertrafikken og brukes til å trene deres AI-modeller og drive funksjoner på tvers av Facebook, Instagram og WhatsApp. Meta-WebIndexer har en komplementær funksjon, med fokus på webindeksering for AI-drevne funksjoner og anbefalinger. Apple introduserte Applebot-Extended for å støtte Apple Intelligence, deres AI-funksjoner på enheten, og denne crawleren har vokst jevnt ettersom selskapet utvider AI-kapasitetene sine på iPhone, iPad og Mac-enheter. Amazon driver Amazonbot til å drive Alexa og Rufus, deres AI-shoppingassistent, noe som gjør den relevant for e-handelssider og produktfokusert innhold. PerplexityBot representerer en av de mest dramatiske veksthistoriene i crawlerlandskapet, med en forbløffende 157 490 % økning i trafikk, noe som gjenspeiler den eksplosive veksten til Perplexity AI som et søkealternativ; til tross for denne massive veksten utgjør Perplexity fortsatt et lavere absolutt volum sammenlignet med OpenAI og Google, men utviklingen indikerer raskt økende betydning.
Utover de store aktørene er det en rekke fremvoksende og spesialiserte AI-crawlere som aktivt samler inn data fra nettsteder over hele internett. Bytespider, drevet av ByteDance (morselskapet til TikTok), opplevde et dramatisk 85 % fall i crawlertrafikk, noe som tyder på enten et strategiskifte eller redusert behov for treningsdata. Cohere, Diffbot og Common Crawl’s CCBot representerer spesialiserte crawlere som fokuserer på spesifikke bruksområder, fra språkmodelltrening til strukturert datauttrekk. You.com, Mistral og DuckDuckGo har hver sin crawler for å støtte sine AI-drevne søke- og assistentfunksjoner, noe som bidrar til den økende kompleksiteten i crawlerlandskapet. Nye crawlere oppstår jevnlig, med både oppstartsbedrifter og etablerte selskaper som stadig lanserer AI-produkter som krever innsamling av nettdata. Å holde seg oppdatert på disse fremvoksende crawlerne er avgjørende fordi blokkering eller tillatelse av dem kan ha stor innvirkning på synligheten din i nye AI-drevne oppdagelsesplattformer og applikasjoner.
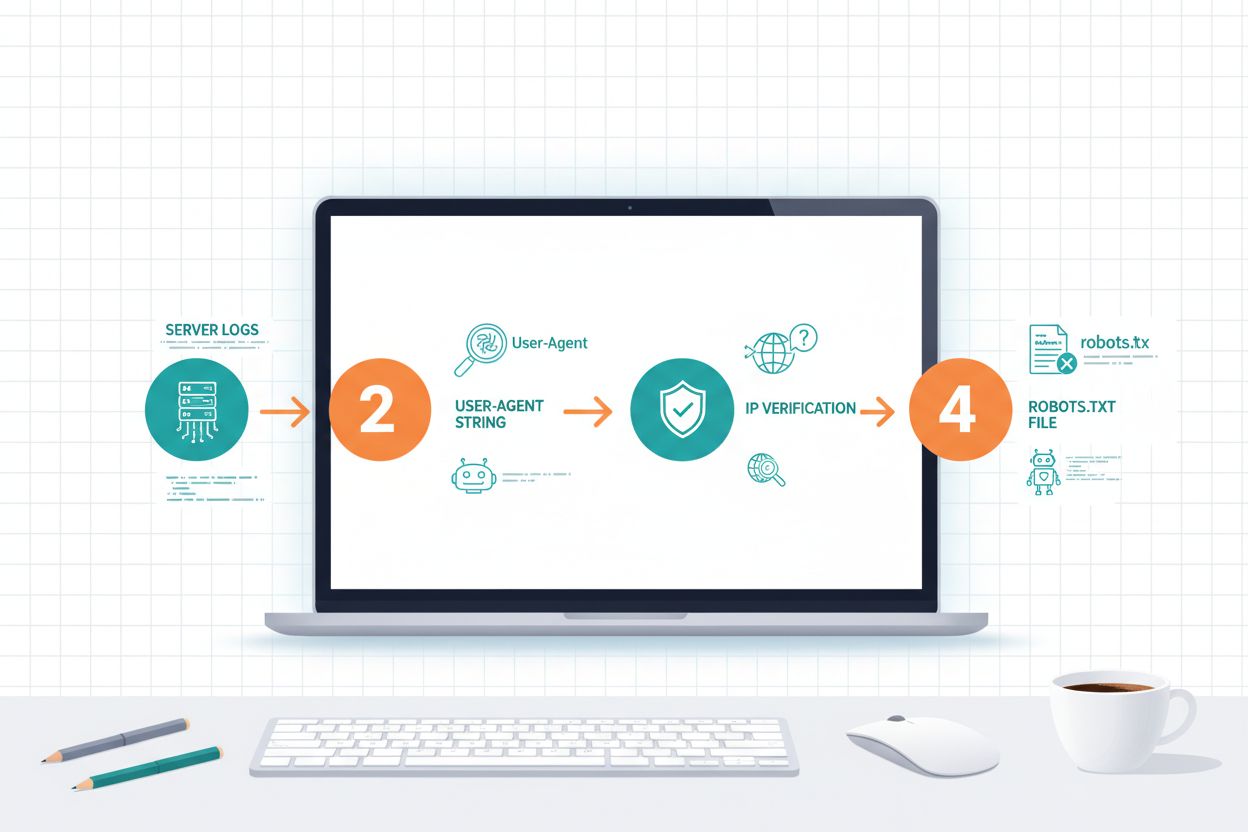
Identifisering av AI-crawlere krever forståelse for hvordan de identifiserer seg selv og analyse av trafikkmønstrene på serveren din. User-agent-strenger er hovedmetoden for identifisering, ettersom hver crawler annonserer seg med en spesifikk identifikator i HTTP-forespørsler; for eksempel bruker GPTBot GPTBot/1.0, ClaudeBot bruker Claude-Web/1.0, og PerplexityBot bruker PerplexityBot/1.0. Analyse av serverlogger (vanligvis funnet i /var/log/apache2/access.log på Linux-servere eller IIS-logger på Windows) lar deg se hvilke crawlere som besøker siden din og hvor ofte. IP-verifisering er en annen viktig teknikk, hvor du kan bekrefte at en crawler som utgir seg for å være fra OpenAI eller Anthropic faktisk kommer fra deres legitime IP-intervaller, som disse selskapene publiserer av sikkerhetshensyn. Gjennomgang av robots.txt-filen din viser hvilke crawlere du eksplisitt har tillatt eller blokkert, og sammenligning med faktisk trafikk viser om crawlerne respekterer direktivene dine. Verktøy som Cloudflare Radar gir sanntidsinnsyn i crawlertrafikkmønstre og kan hjelpe deg å identifisere hvilke roboter som er mest aktive på nettstedet ditt. Praktiske identifikasjonstrinn inkluderer: å sjekke analyseplattformen din for bottrafikk, gjennomgå rå serverlogger for user-agent-mønstre, kryssreferere IP-adresser med publiserte crawler-IP-intervaller, og bruke online crawler-verifiseringsverktøy for å bekrefte mistenkelige trafikkilder.
Å bestemme om du skal tillate eller blokkere AI-crawlere innebærer å veie flere konkurrerende forretningshensyn som ikke har et universelt svar. De viktigste avveiningene inkluderer:
Ettersom 80 % av AI-bottrafikken kommer fra treningscrawlere med minimal henvisningspotensial, velger mange utgivere å blokkere treningscrawlere, men tillate søke- og siteringscrawlere. Denne avgjørelsen avhenger til syvende og sist av forretningsmodellen din, innholdstype og strategiske prioriteringer med hensyn til AI-synlighet versus ressursforbruk.
Robots.txt-filen er ditt primære verktøy for å kommunisere crawler-policyer til AI-roboter, selv om det er viktig å forstå at samsvar er frivillig og ikke teknisk håndhevbar. Robots.txt bruker user-agent-matching for å rette ulike regler mot spesifikke crawlere, slik at du kan lage ulike regler for forskjellige roboter; for eksempel kan du blokkere GPTBot mens du tillater OAI-SearchBot, eller blokkere alle treningscrawlere mens du tillater søkecrawlere. Ifølge nylig forskning har kun 14 % av de 10 000 største domenene implementert AI-spesifikke robots.txt-regler, noe som indikerer at de fleste nettsteder ennå ikke har optimalisert sine crawler-policyer for AI-tiden. Filen bruker enkel syntaks hvor du spesifiserer et user-agent-navn etterfulgt av disallow- eller allow-direktiver, og du kan bruke jokertegn for å matche flere crawlere med lignende navnemønstre.
Her er tre praktiske robots.txt-konfigurasjonsscenarier:
# Scenario 1: Blokker alle AI-treningscrawlere, tillat søkecrawlere
User-agent: GPTBot
Disallow: /
User-agent: ClaudeBot
Disallow: /
User-agent: Meta-ExternalAgent
Disallow: /
User-agent: Amazonbot
Disallow: /
User-agent: Bytespider
Disallow: /
User-agent: OAI-SearchBot
Allow: /
User-agent: PerplexityBot
Allow: /
# Scenario 2: Blokker alle AI-crawlere fullstendig
User-agent: GPTBot
Disallow: /
User-agent: ClaudeBot
Disallow: /
User-agent: Meta-ExternalAgent
Disallow: /
User-agent: Amazonbot
Disallow: /
User-agent: Bytespider
Disallow: /
User-agent: OAI-SearchBot
Disallow: /
User-agent: PerplexityBot
Disallow: /
User-agent: Applebot-Extended
Disallow: /
# Scenario 3: Selektiv blokkering per katalog
User-agent: GPTBot
Disallow: /private/
Disallow: /admin/
Allow: /public/
User-agent: ClaudeBot
Disallow: /
User-agent: OAI-SearchBot
Allow: /
Husk at robots.txt kun er veiledende, og ondsinnede eller ikke-kompatible crawlere kan ignorere direktivene dine fullstendig. User-agent-matching er ikke skille mellom store og små bokstaver, så gptbot, GPTBot og GPTBOT refererer alle til samme crawler, og du kan bruke User-agent: * for å lage regler som gjelder for alle crawlere.
Utover robots.txt finnes det flere avanserte metoder som gir sterkere beskyttelse mot uønskede AI-crawlere, selv om hver har ulik effektivitet og implementeringskompleksitet. IP-verifisering og brannmurregler lar deg blokkere trafikk fra spesifikke IP-intervaller knyttet til AI-crawlere; du kan hente disse intervallene fra crawler-operatørenes dokumentasjon og konfigurere brannmuren eller Web Application Firewall (WAF) til å avvise forespørsler fra disse IP-ene, men dette krever løpende vedlikehold ettersom IP-intervaller endres. .htaccess-blokkering på servernivå gir Apache-serverbeskyttelse ved å sjekke user-agent-strenger og IP-adresser før innhold serveres, og gir mer pålitelig håndheving enn robots.txt, siden det opererer på servernivå og ikke er avhengig av crawler-samsvar.
Her er et praktisk .htaccess-eksempel for avansert blokkering av crawlere:
# Blokker AI-treningscrawlere på servernivå
<IfModule mod_rewrite.c>
RewriteEngine On
# Blokker etter user-agent-streng
RewriteCond %{HTTP_USER_AGENT} (GPTBot|ClaudeBot|Meta-ExternalAgent|Amazonbot|Bytespider) [NC]
RewriteRule ^.*$ - [F,L]
# Blokker etter IP-adresse (eksempel-IP-er – erstatt med faktiske crawler-IP-er)
RewriteCond %{REMOTE_ADDR} ^192\.0\.2\.0$ [OR]
RewriteCond %{REMOTE_ADDR} ^198\.51\.100\.0$
RewriteRule ^.*$ - [F,L]
# Tillat spesifikke crawlere, blokker andre
RewriteCond %{HTTP_USER_AGENT} !OAI-SearchBot [NC]
RewriteCond %{HTTP_USER_AGENT} (GPTBot|ClaudeBot) [NC]
RewriteRule ^.*$ - [F,L]
</IfModule>
# HTML meta tag-tilnærming (legg til i sidehodet)
# <meta name="robots" content="noarchive, noimageindex">
# <meta name="googlebot" content="noindex, nofollow">
HTML-meta-tagger som <meta name="robots" content="noarchive"> og <meta name="googlebot" content="noindex"> gir kontroll på sidenivå, men de er mindre pålitelige enn blokkering på servernivå, siden crawlere må tolke HTML-en for å se dem. Det er viktig å merke seg at IP-forfalskning er teknisk mulig, noe som betyr at sofistikerte aktører kan utgi seg for å være legitime crawler-IP-er, så det å kombinere flere metoder gir bedre beskyttelse enn å stole på én enkelt tilnærming. Hver metode har ulike fordeler: robots.txt er lett å implementere, men ikke håndhevet, IP-blokkering er pålitelig, men krever vedlikehold, .htaccess gir håndheving på servernivå, og meta-tagger gir granularitet på sidenivå.
Å implementere crawler-policyer er bare halve jobben; du må aktivt overvåke om crawlerne respekterer direktivene dine og justere strategien basert på faktiske trafikkmønstre. Serverlogger er hovedkilden til data, vanligvis lokalisert på /var/log/apache2/access.log på Linux-servere eller i IIS-loggmappen på Windows-servere, hvor du kan søke etter spesifikke user-agent-strenger for å se hvilke crawlere som besøker nettstedet ditt og hvor ofte. Analyseplattformer som Google Analytics, Matomo eller Plausible kan konfigureres til å spore bottrafikk separat fra menneskelige besøkende, slik at du kan se volum og oppførsel til ulike crawlere over tid. Cloudflare Radar gir sanntidsinnsikt i crawlertrafikkmønstre over hele internett og kan vise deg hvordan crawlertrafikken på nettstedet ditt sammenlignes med bransjegjennomsnittet. For å verifisere at crawlere respekterer blokkeringene dine, kan du bruke nettbaserte verktøy for å sjekke robots.txt-filen, gjennomgå serverlogger for blokkerte user-agents, og kryssreferere IP-adresser med publiserte crawler-IP-intervaller for å bekrefte at trafikken faktisk kommer fra legitime kilder. Praktiske overvåkingssteg inkluderer: å sette opp ukentlig logganalyse for å spore crawlervolum, konfigurere varsler for uvanlig crawleraktivitet, gjennomgå analysetavlen månedlig for trender i bottrafikk, og gjennomføre kvartalsvise vurderinger av crawler-policyene dine for å sikre at de fortsatt samsvarer med forretningsmålene. Regelmessig overvåking hjelper deg å identifisere nye crawlere, oppdage policybrudd og ta datadrevne beslutninger om hvilke crawlere du skal tillate eller blokkere.
AI-crawlerlandskapet fortsetter å utvikle seg raskt, med nye aktører som kommer på markedet og eksisterende crawlere som utvider kapasitetene sine i uventede retninger. Fremvoksende crawlere fra selskaper som xAI (Grok), Mistral og DeepSeek begynner å samle nettdata i stor skala, og hver nye AI-oppstart vil sannsynligvis introdusere sin egen crawler for å støtte modelltrening og produktfunksjoner. Agentiske nettlesere representerer en ny grense innen crawlerteknologi, med systemer som ChatGPT Operator og Comet som kan interagere med nettsteder som menneskelige brukere, klikke på knapper, fylle ut skjemaer og navigere i komplekse grensesnitt; disse nettleserbaserte agentene gir unike utfordringer fordi de er vanskeligere å identifisere og blokkere med tradisjonelle metoder. Utfordringen med nettleserbaserte agenter er at de kanskje ikke identifiserer seg tydelig i user-agent-strenger og potensielt kan omgå IP-basert blokkering ved å bruke boligproxies eller distribuert infrastruktur. Nye crawlere dukker opp jevnlig, noen ganger uten forvarsel, noe som gjør det essensielt å holde seg informert om utviklingen i AI-rommet og justere policyene dine deretter. Utviklingen tyder på at crawlertrafikken vil fortsette å vokse, med Cloudflare som rapporterer en 18 % økning totalt i crawlertrafikk fra mai 2024 til mai 2025, og denne veksten vil sannsynligvis akselerere etter hvert som flere AI-applikasjoner når mainstream. Nettstedseiere og utgivere må forbli årvåkne og tilpasningsdyktige, regelmessig gjennomgå crawler-policyene sine og overvåke nye utviklinger for å sikre at strategiene forblir effektive i dette raskt skiftende landskapet.
Selv om det er viktig å administrere crawlertilgang til nettstedet ditt, er det like kritisk å forstå hvordan innholdet ditt blir brukt og sitert i AI-genererte svar. AmICited.com er en spesialisert plattform utviklet for å løse dette problemet ved å spore hvordan AI-crawlere samler inn innholdet ditt og overvåke om merkevaren og innholdet ditt blir korrekt sitert i AI-drevne applikasjoner. Plattformen hjelper deg å forstå hvilke AI-systemer som bruker innholdet ditt, hvor ofte informasjonen din vises i AI-svar, og om korrekt attribusjon gis til dine originale kilder. For utgivere og innholdsskapere gir AmICited.com verdifull innsikt i synligheten din innen AI-økosystemet, slik at du kan måle effekten av valget om å tillate eller blokkere crawlere og forstå den faktiske verdien du får fra AI-drevet oppdagelse. Ved å overvåke siteringene dine på tvers av flere AI-plattformer kan du ta mer informerte beslutninger om crawler-policyene dine, identifisere muligheter for å forbedre innholdets synlighet i AI-svar, og sikre at din immaterielle eiendom blir korrekt kreditert. Hvis du er seriøs med å forstå merkevarens tilstedeværelse på det AI-drevne nettet, gir AmICited.com den åpenheten og overvåkingskapasiteten du trenger for å holde deg informert og beskytte innholdets verdi i denne nye æraen av AI-drevet oppdagelse.
Treningscrawlere som GPTBot og ClaudeBot samler innhold for å bygge datasett til store språkmodellutviklinger, og blir en del av AI-ens kunnskapsbase. Søke-crawlere som OAI-SearchBot og PerplexityBot indekserer innhold for AI-drevne søkeopplevelser og kan sende henvisningstrafikk tilbake til utgivere gjennom siteringer.
Dette avhenger av dine forretningsprioriteringer. Å blokkere treningscrawlere beskytter innholdet ditt fra å bli inkorporert i AI-modeller. Blokkering av søke-crawlere kan redusere synligheten din i AI-drevne oppdagelsesplattformer som ChatGPT-søk eller Perplexity. Mange utgivere velger selektiv blokkering som retter seg mot treningscrawlere, mens de tillater søke- og siteringscrawlere.
Den mest pålitelige verifiseringsmetoden er å sjekke forespørsels-IP-en mot offisielt publiserte IP-intervaller fra crawler-operatører. Store selskaper som OpenAI, Anthropic og Amazon publiserer sine crawler-IP-adresser. Du kan også bruke brannmurregler for å hviteliste bekreftede IP-er og blokkere forespørsler fra ubekreftede kilder som utgir seg for å være AI-crawlere.
Google sier offisielt at blokkering av Google-Extended ikke påvirker søkerangeringer eller inkludering i AI Overviews. Imidlertid har noen nettredaktører rapportert bekymringer, så overvåk søkeytelsen etter å ha implementert blokkering. AI Overviews i Google Søk følger vanlige Googlebot-regler, ikke Google-Extended.
Nye AI-crawlere dukker jevnlig opp, så gjennomgå og oppdater blokkeringslisten din minst kvartalsvis. Følg ressurser som ai.robots.txt-prosjektet på GitHub for fellesskapsvedlikeholdte lister. Sjekk serverloggene månedlig for å identifisere nye crawlere som besøker nettstedet ditt og som ikke er i din nåværende konfigurasjon.
Ja, robots.txt er veiledende og ikke håndhevbar. Veloppdragne crawlere fra store selskaper respekterer vanligvis robots.txt-direktiver, men noen crawlere ignorerer dem. For sterkere beskyttelse, implementer blokkering på servernivå via .htaccess eller brannmurregler, og verifiser legitime crawlere ved hjelp av publiserte IP-adresseintervaller.
AI-crawlere kan generere betydelig serverbelastning og båndbreddeforbruk. Noen infrastrukturrapporter har vist at blokkering av AI-crawlere reduserte båndbreddeforbruket fra 800 GB til 200 GB daglig, og sparte cirka 1 500 dollar per måned. Utgivere med mye trafikk kan oppleve vesentlige kostnadsreduksjoner ved selektiv blokkering.
Sjekk serverloggene dine (vanligvis på /var/log/apache2/access.log på Linux) etter user-agent-strenger som matcher kjente crawlere. Bruk analyseplattformer som Google Analytics eller Cloudflare Radar for å spore robottrafikk separat. Sett opp varsler for uvanlig crawleraktivitet og gjennomfør kvartalsvise gjennomganger av crawler-policyene dine.
Følg med på hvordan AI-plattformer som ChatGPT, Perplexity og Google AI Overviews refererer til innholdet ditt. Få varsler i sanntid når merkevaren din nevnes i AI-genererte svar.
Lær hvordan du tar strategiske beslutninger om blokkering av AI-crawlere. Vurder innholdstype, trafikkilder, inntektsmodeller og konkurranseposisjon med vårt om...

Lær hvilke AI-crawlere du bør tillate eller blokkere i robots.txt-filen din. Omfattende guide som dekker GPTBot, ClaudeBot, PerplexityBot og 25+ AI-crawlere med...
Lær hvordan du lar AI-boter som GPTBot, PerplexityBot og ClaudeBot crawle nettstedet ditt. Konfigurer robots.txt, sett opp llms.txt, og optimaliser for AI-synli...